 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeorgios B. Giannakis
Minimum Uncertainty Based Detection of Adversaries in Deep Neural Networks
Apr 05, 2019
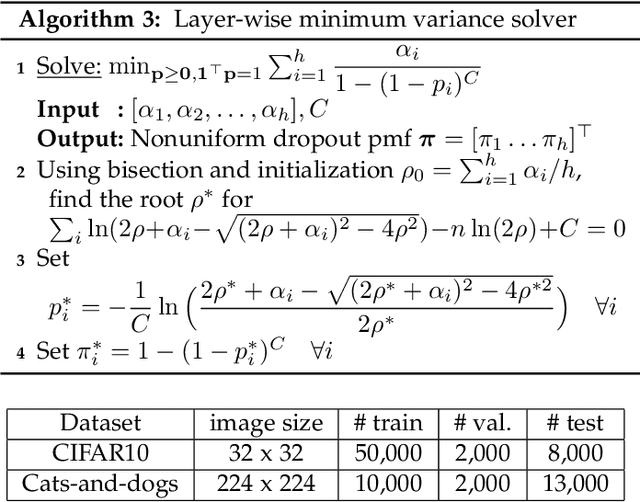
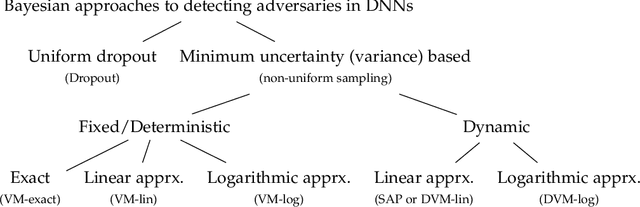
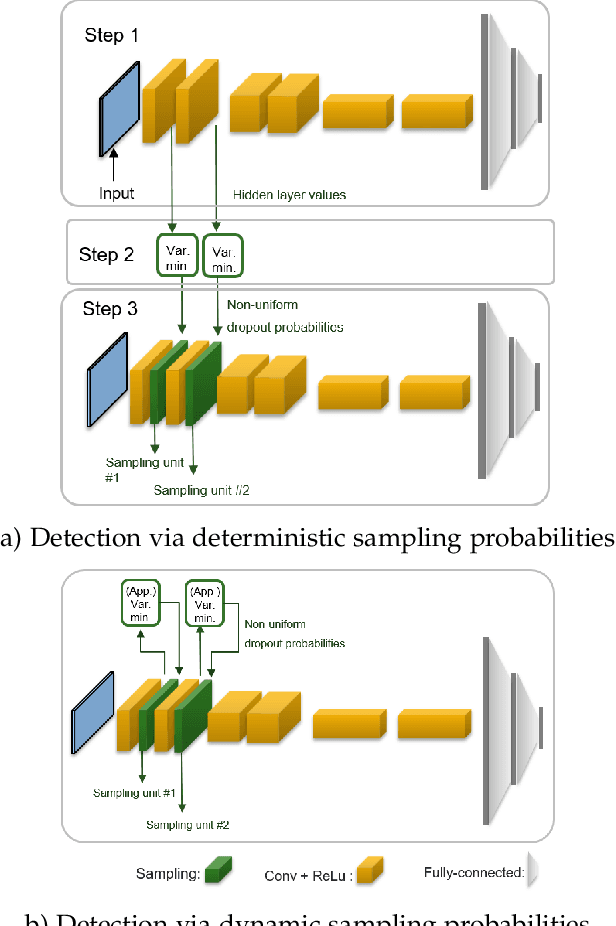
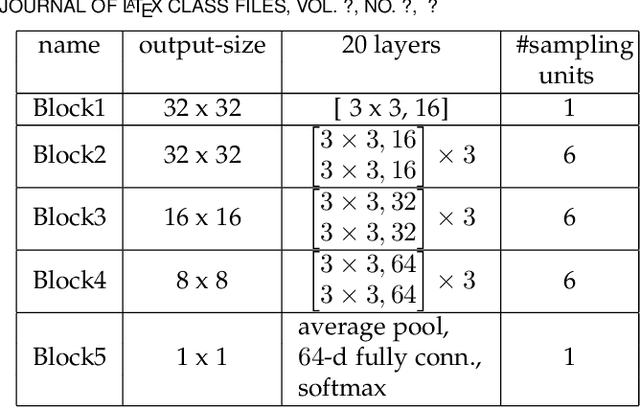
Despite their unprecedented performance in various domains, utilization of Deep Neural Networks (DNNs) in safety-critical environments is severely limited in the presence of even small adversarial perturbations. The present work develops a randomized approach to detecting such perturbations based on minimum uncertainty metrics that rely on sampling at the hidden layers during the DNN inference stage. The sampling probabilities are designed for effective detection of the adversarially corrupted inputs. Being modular, the novel detector of adversaries can be conveniently employed by any pre-trained DNN at no extra training overhead. Selecting which units to sample per hidden layer entails quantifying the amount of DNN output uncertainty from the viewpoint of Bayesian neural networks, where the overall uncertainty is expressed in terms of its layer-wise components - what also promotes scalability. Sampling probabilities are then sought by minimizing uncertainty measures layer-by-layer, leading to a novel convex optimization problem that admits an exact solver with superlinear convergence rate. By simplifying the objective function, low-complexity approximate solvers are also developed. In addition to valuable insights, these approximations link the novel approach with state-of-the-art randomized adversarial detectors. The effectiveness of the novel detectors in the context of competing alternatives is highlighted through extensive tests for various types of adversarial attacks with variable levels of strength.
Adaptive Caching via Deep Reinforcement Learning
Feb 27, 2019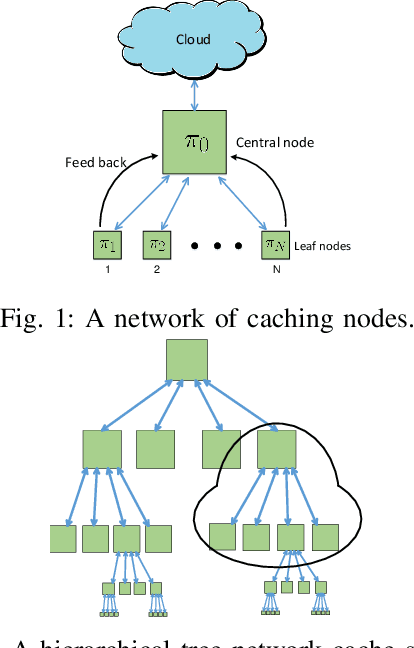

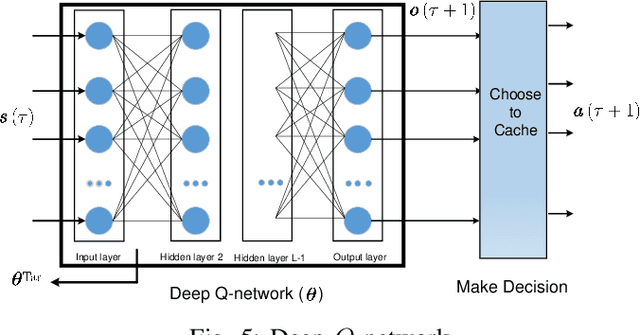
Caching is envisioned to play a critical role in next-generation content delivery infrastructure, cellular networks, and Internet architectures. By smartly storing the most popular contents at the storage-enabled network entities during off-peak demand instances, caching can benefit both network infrastructure as well as end users, during on-peak periods. In this context, distributing the limited storage capacity across network entities calls for decentralized caching schemes. Many practical caching systems involve a parent caching node connected to multiple leaf nodes to serve user file requests. To model the two-way interactive influence between caching decisions at the parent and leaf nodes, a reinforcement learning framework is put forth. To handle the large continuous state space, a scalable deep reinforcement learning approach is pursued. The novel approach relies on a deep Q-network to learn the Q-function, and thus the optimal caching policy, in an online fashion. Reinforcing the parent node with ability to learn-and-adapt to unknown policies of leaf nodes as well as spatio-temporal dynamic evolution of file requests, results in remarkable caching performance, as corroborated through numerical tests.
Communication-Efficient Distributed Reinforcement Learning
Jan 03, 2019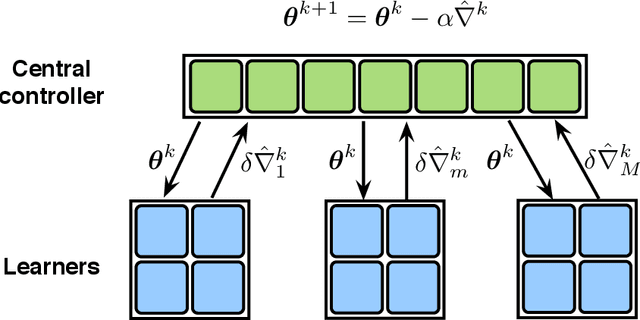

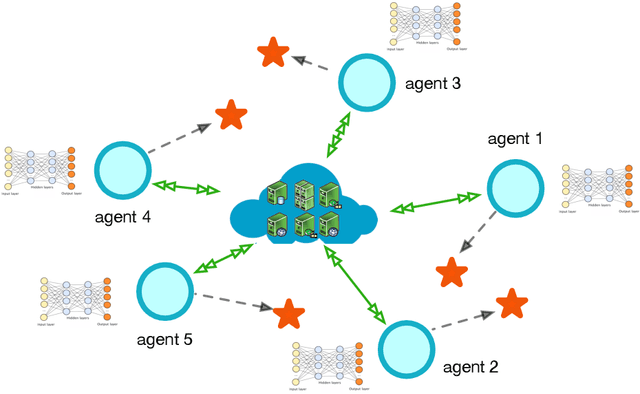
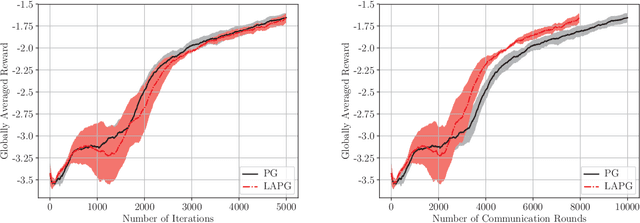
This paper deals with distributed reinforcement learning (DRL), which involves a central controller and a group of learners. In particular, two DRL settings encountered in several applications are considered: multi-agent reinforcement learning (RL) and parallel RL, where frequent information exchanges between the learners and the controller are required. For many practical distributed systems, however, such as those involving parallel machines for training deep RL algorithms, and multi-robot systems for learning the optimal coordination strategies, the overhead caused by these frequent communication exchanges is considerable, and becomes the bottleneck of the overall performance. To address this challenge, a novel policy gradient method is developed here to cope with such communication-constrained DRL settings. The proposed approach reduces the communication overhead without degrading learning performance by adaptively skipping the policy gradient communication during iterations. It is established analytically that i) the novel algorithm has convergence rate identical to that of the plain-vanilla policy gradient for DRL; while ii) if the distributed computing units are heterogeneous in terms of their reward functions and initial state distributions, the number of communication rounds needed to achieve a desirable learning accuracy is markedly reduced. Numerical experiments on a popular multi-agent RL benchmark corroborate the significant communication reduction attained by the novel algorithm compared to alternatives.
Reinforcement Learning for Adaptive Caching with Dynamic Storage Pricing
Dec 21, 2018
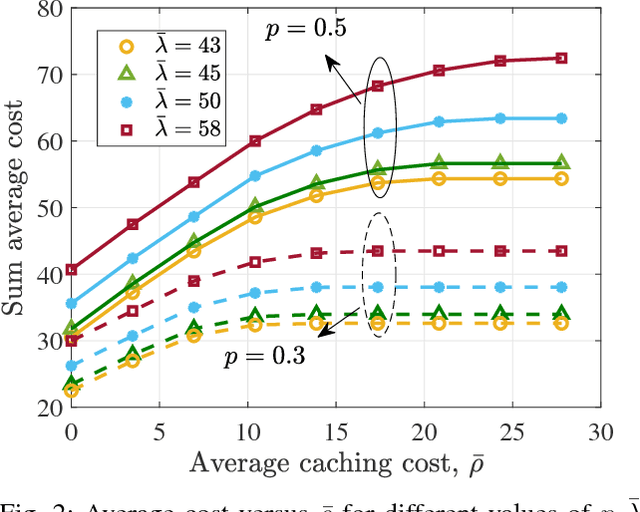
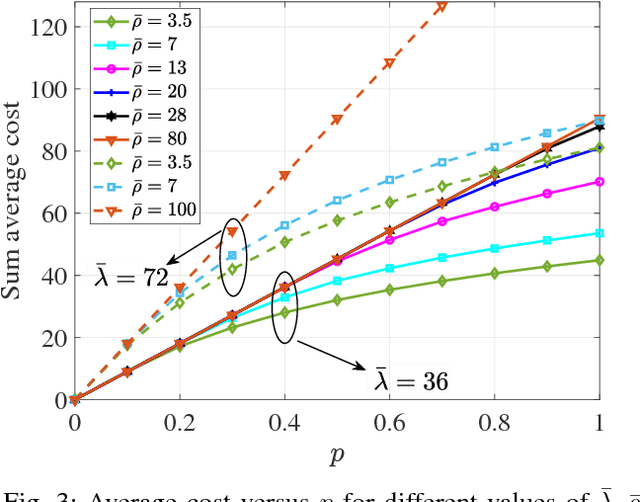
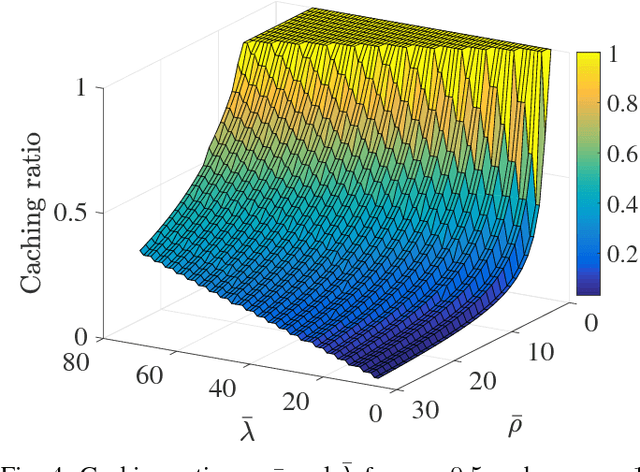
Small base stations (SBs) of fifth-generation (5G) cellular networks are envisioned to have storage devices to locally serve requests for reusable and popular contents by \emph{caching} them at the edge of the network, close to the end users. The ultimate goal is to shift part of the predictable load on the back-haul links, from on-peak to off-peak periods, contributing to a better overall network performance and service experience. To enable the SBs with efficient \textit{fetch-cache} decision-making schemes operating in dynamic settings, this paper introduces simple but flexible generic time-varying fetching and caching costs, which are then used to formulate a constrained minimization of the aggregate cost across files and time. Since caching decisions per time slot influence the content availability in future slots, the novel formulation for optimal fetch-cache decisions falls into the class of dynamic programming. Under this generic formulation, first by considering stationary distributions for the costs and file popularities, an efficient reinforcement learning-based solver known as value iteration algorithm can be used to solve the emerging optimization problem. Later, it is shown that practical limitations on cache capacity can be handled using a particular instance of the generic dynamic pricing formulation. Under this setting, to provide a light-weight online solver for the corresponding optimization, the well-known reinforcement learning algorithm, $Q$-learning, is employed to find optimal fetch-cache decisions. Numerical tests corroborating the merits of the proposed approach wrap up the paper.
Node Embedding with Adaptive Similarities for Scalable Learning over Graphs
Dec 03, 2018
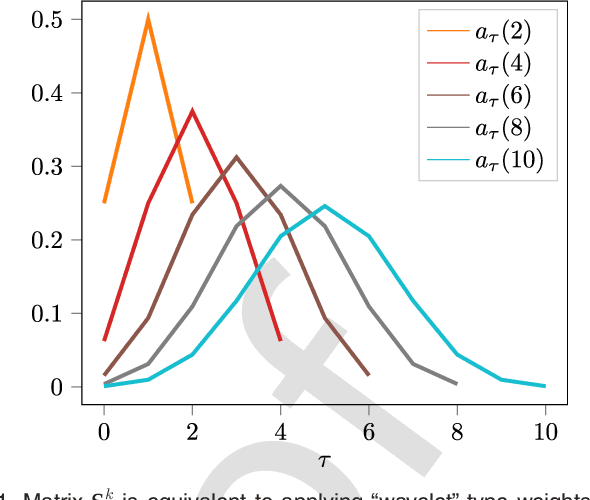
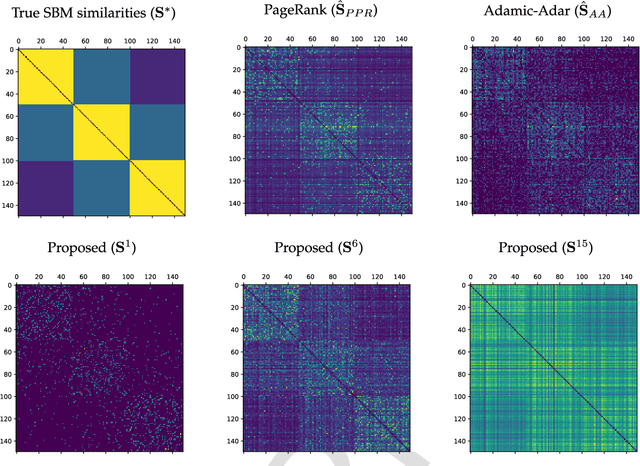
Node embedding is the task of extracting informative and descriptive features over the nodes of a graph. The importance of node embeddings for graph analytics, as well as learning tasks such as node classification, link prediction and community detection, has led to increased interest on the problem leading to a number of recent advances. Much like PCA in the feature domain, node embedding is an inherently \emph{unsupervised} task; in lack of metadata used for validation, practical methods may require standardization and limiting the use of tunable hyperparameters. Finally, node embedding methods are faced with maintaining scalability in the face of large-scale real-world graphs of ever-increasing sizes. In the present work, we propose an adaptive node embedding framework that adjusts the embedding process to a given underlying graph, in a fully unsupervised manner. To achieve this, we adopt the notion of a tunable node similarity matrix that assigns weights on paths of different length. The design of the multilength similarities ensures that the resulting embeddings also inherit interpretable spectral properties. The proposed model is carefully studied, interpreted, and numerically evaluated using stochastic block models. Moreover, an algorithmic scheme is proposed for training the model parameters effieciently and in an unsupervised manner. We perform extensive node classification, link prediction, and clustering experiments on many real world graphs from various domains, and compare with state-of-the-art scalable and unsupervised node embedding alternatives. The proposed method enjoys superior performance in many cases, while also yielding interpretable information on the underlying structure of the graph.
Online Graph-Adaptive Learning with Scalability and Privacy
Dec 03, 2018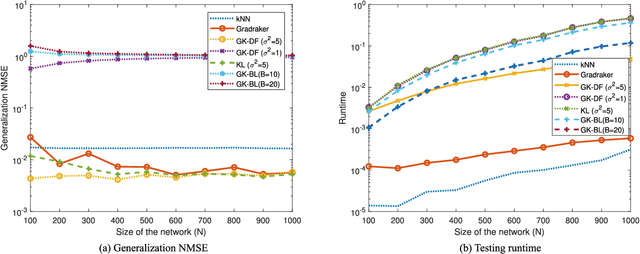
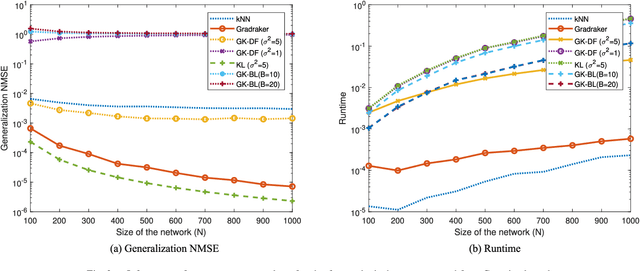
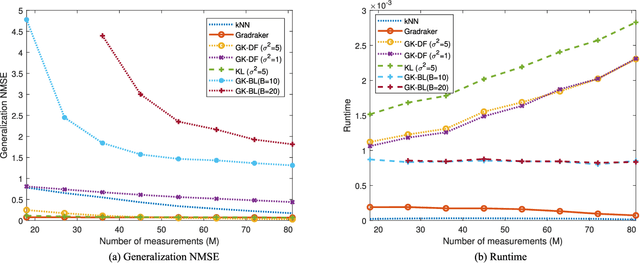
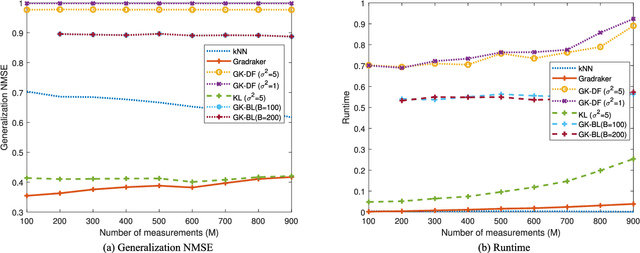
Graphs are widely adopted for modeling complex systems, including financial, biological, and social networks. Nodes in networks usually entail attributes, such as the age or gender of users in a social network. However, real-world networks can have very large size, and nodal attributes can be unavailable to a number of nodes, e.g., due to privacy concerns. Moreover, new nodes can emerge over time, which can necessitate real-time evaluation of their nodal attributes. In this context, the present paper deals with scalable learning of nodal attributes by estimating a nodal function based on noisy observations at a subset of nodes. A multikernel-based approach is developed which is scalable to large-size networks. Unlike most existing methods that re-solve the function estimation problem over all existing nodes whenever a new node joins the network, the novel method is capable of providing real-time evaluation of the function values on newly-joining nodes without resorting to a batch solver. Interestingly, the novel scheme only relies on an encrypted version of each node's connectivity in order to learn the nodal attributes, which promotes privacy. Experiments on both synthetic and real datasets corroborate the effectiveness of the proposed methods.
Graph Multiview Canonical Correlation Analysis
Nov 30, 2018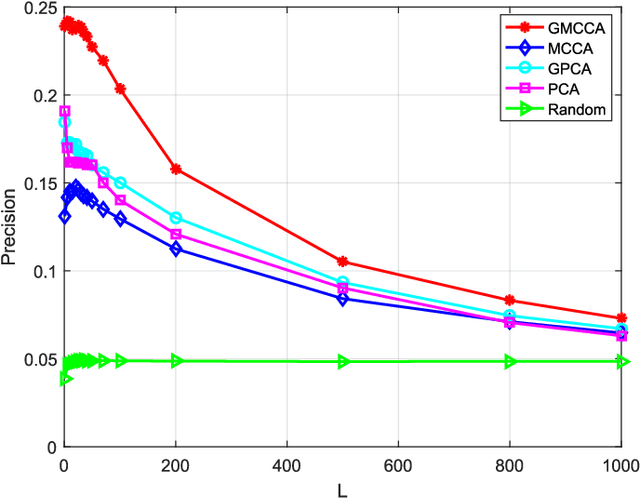
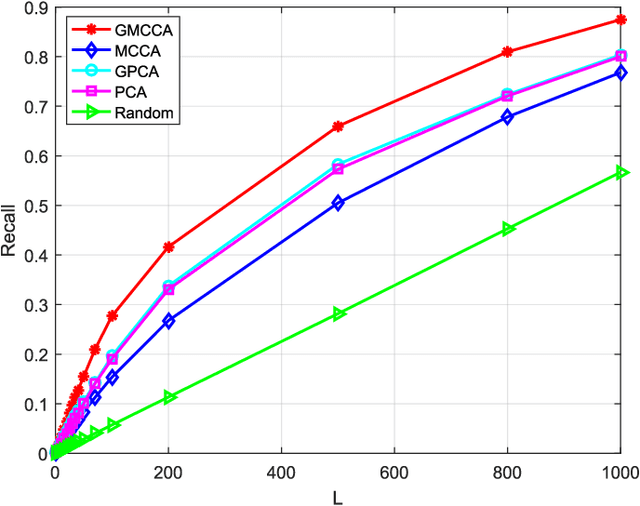
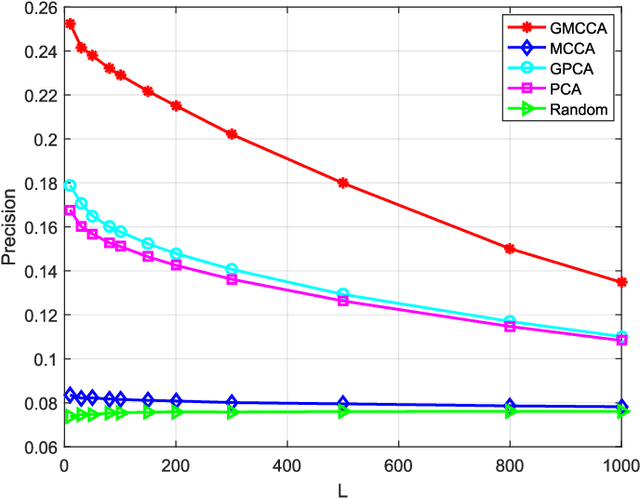
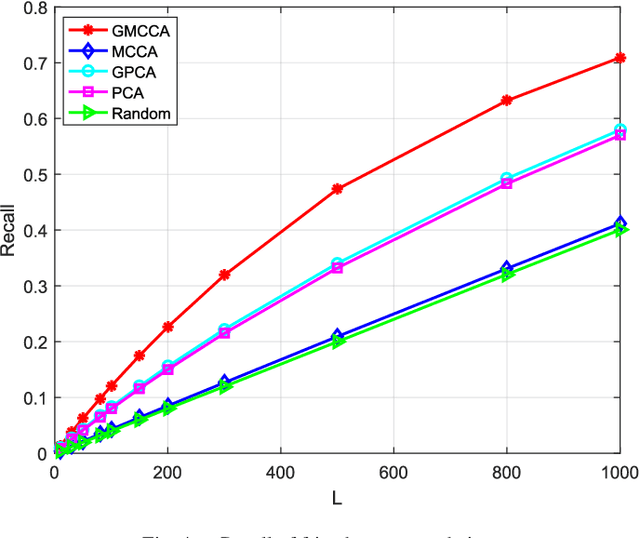
Multiview canonical correlation analysis (MCCA) seeks latent low-dimensional representations encountered with multiview data of shared entities (a.k.a. common sources). However, existing MCCA approaches do not exploit the geometry of the common sources, which may be available \emph{a priori}, or can be constructed using certain domain knowledge. This prior information about the common sources can be encoded by a graph, and be invoked as a regularizer to enrich the maximum variance MCCA framework. In this context, the present paper's novel graph-regularized (G) MCCA approach minimizes the distance between the wanted canonical variables and the common low-dimensional representations, while accounting for graph-induced knowledge of the common sources. Relying on a function capturing the extent low-dimensional representations of the multiple views are similar, a generalization bound of GMCCA is established based on Rademacher's complexity. Tailored for setups where the number of data pairs is smaller than the data vector dimensions, a graph-regularized dual MCCA approach is also developed. To further deal with nonlinearities present in the data, graph-regularized kernel MCCA variants are put forward too. Interestingly, solutions of the graph-regularized linear, dual, and kernel MCCA, are all provided in terms of generalized eigenvalue decomposition. Several corroborating numerical tests using real datasets are provided to showcase the merits of the graph-regularized MCCA variants relative to several competing alternatives including MCCA, Laplacian-regularized MCCA, and (graph-regularized) PCA.
Real-time Power System State Estimation and Forecasting via Deep Neural Networks
Nov 30, 2018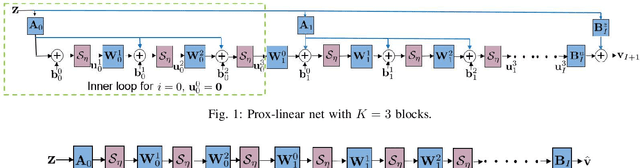
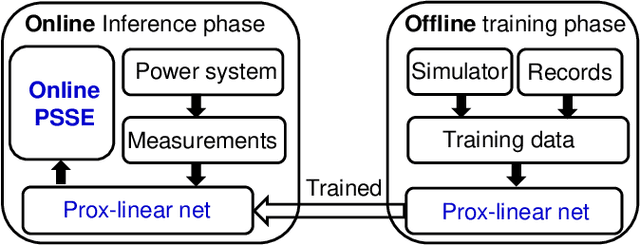
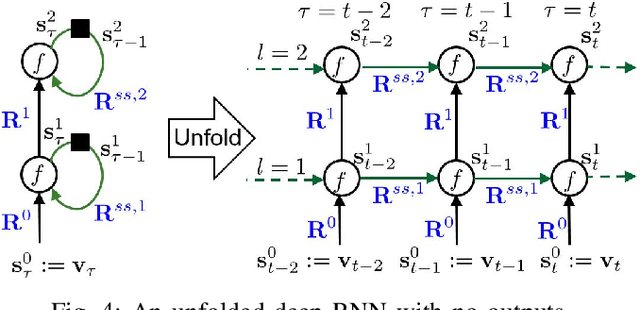
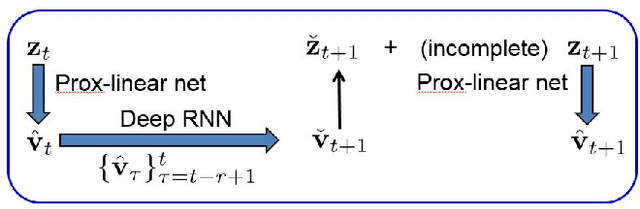
Contemporary power grids are being challenged by rapid voltage fluctuations that are caused by large-scale deployment of renewable generation, electric vehicles, and demand response programs. In this context, monitoring the grid's operating conditions in real time becomes increasingly critical. With the emergent large scale and nonconvexity however, the existing power system state estimation (PSSE) schemes become computationally expensive or yield suboptimal performance. To bypass these hurdles, this paper advocates deep neural networks (DNNs) for real-time power system monitoring. By unrolling an iterative physics-based prox-linear solver, a novel model-specific DNN is developed for real-time PSSE with affordable training and minimal tuning effort. To further enable system awareness even ahead of the time horizon, as well as to endow the DNN-based estimator with resilience, deep recurrent neural networks (RNNs) are also pursued for power system state forecasting. Deep RNNs leverage the long-term nonlinear dependencies present in the historical voltage time series to enable forecasting, and they are easy to implement. Numerical tests showcase improved performance of the proposed DNN-based estimation and forecasting approaches compared with existing alternatives. In real load data experiments on the IEEE 118-bus benchmark system, the novel model-specific DNN-based PSSE scheme outperforms nearly by an order-of-magnitude the competing alternatives, including the widely adopted Gauss-Newton PSSE solver.
A Recurrent Graph Neural Network for Multi-Relational Data
Nov 19, 2018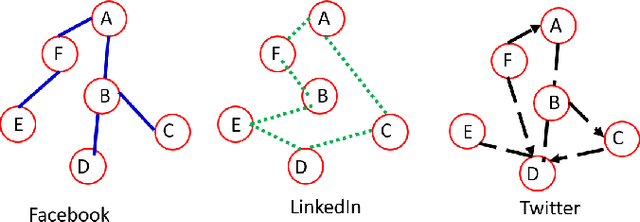
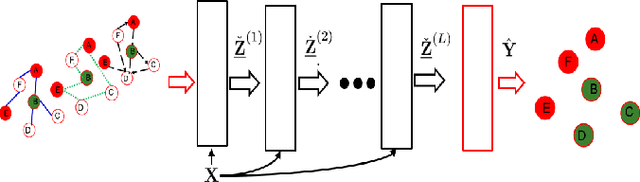
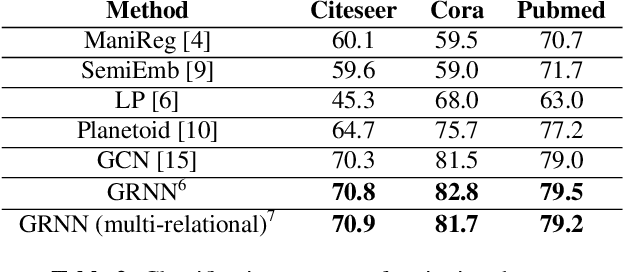
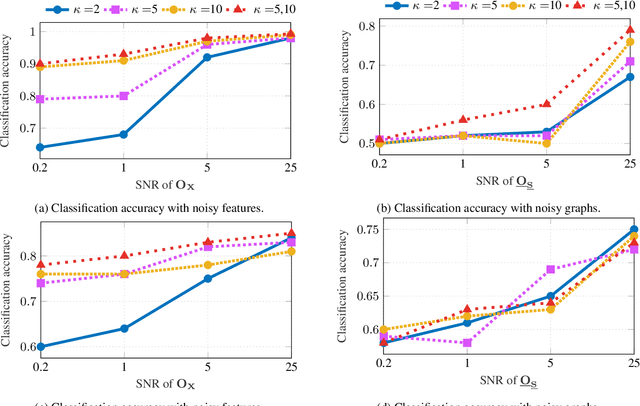
The era of data deluge has sparked the interest in graph-based learning methods in a number of disciplines such as sociology, biology, neuroscience, or engineering. In this paper, we introduce a graph recurrent neural network (GRNN) for scalable semi-supervised learning from multi-relational data. Key aspects of the novel GRNN architecture are the use of multi-relational graphs, the dynamic adaptation to the different relations via learnable weights, and the consideration of graph-based regularizers to promote smoothness and alleviate over-parametrization. Our ultimate goal is to design a powerful learning architecture able to: discover complex and highly non-linear data associations, combine (and select) multiple types of relations, and scale gracefully with respect to the size of the graph. Numerical tests with real data sets corroborate the design goals and illustrate the performance gains relative to competing alternatives.