 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGencer Sumbul
A Novel Graph-Theoretic Deep Representation Learning Method for Multi-Label Remote Sensing Image Retrieval
Jun 01, 2021
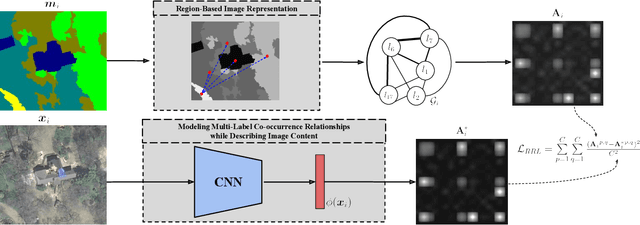
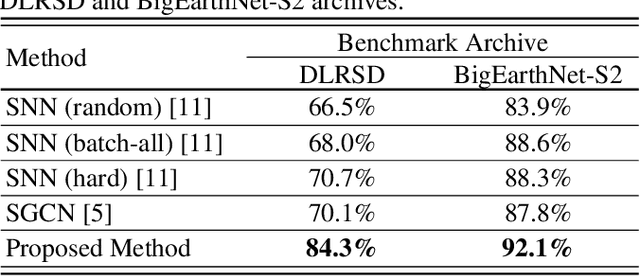
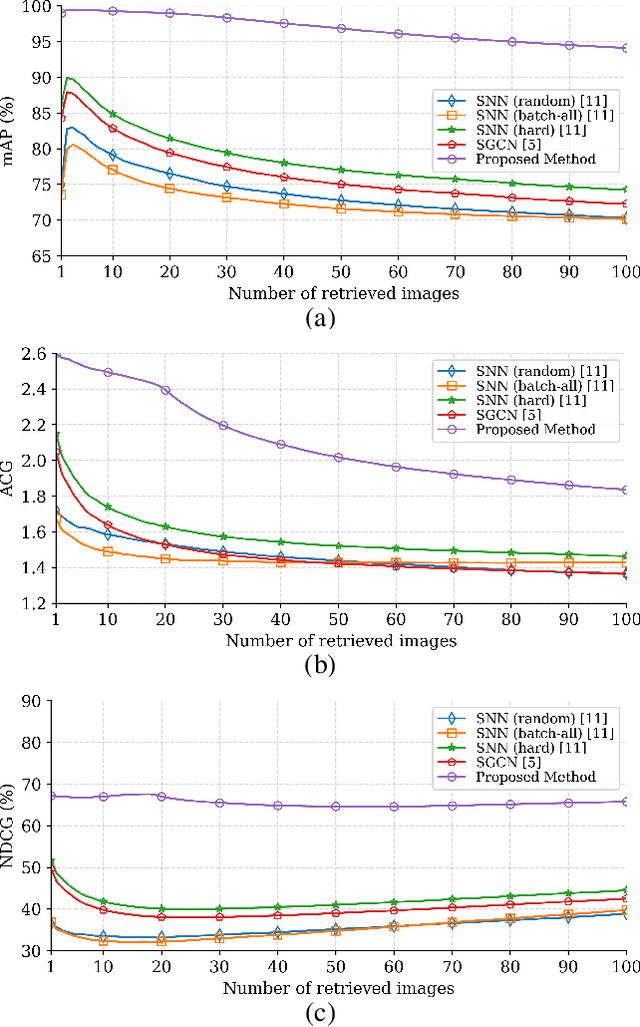
This paper presents a novel graph-theoretic deep representation learning method in the framework of multi-label remote sensing (RS) image retrieval problems. The proposed method aims to extract and exploit multi-label co-occurrence relationships associated to each RS image in the archive. To this end, each training image is initially represented with a graph structure that provides region-based image representation combining both local information and the related spatial organization. Unlike the other graph-based methods, the proposed method contains a novel learning strategy to train a deep neural network for automatically predicting a graph structure of each RS image in the archive. This strategy employs a region representation learning loss function to characterize the image content based on its multi-label co-occurrence relationship. Experimental results show the effectiveness of the proposed method for retrieval problems in RS compared to state-of-the-art deep representation learning methods. The code of the proposed method is publicly available at https://git.tu-berlin.de/rsim/GT-DRL-CBIR .
BigEarthNet-MM: A Large Scale Multi-Modal Multi-Label Benchmark Archive for Remote Sensing Image Classification and Retrieval
May 17, 2021
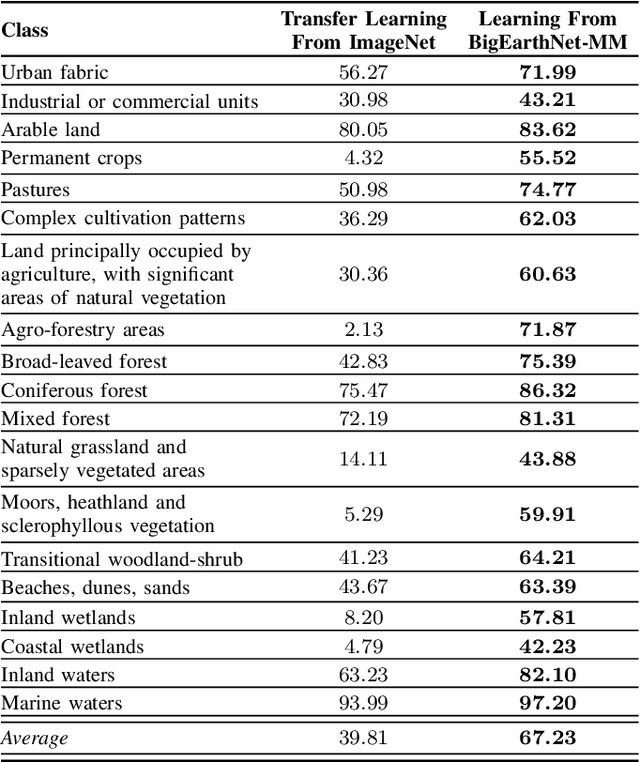
This paper presents the multi-modal BigEarthNet (BigEarthNet-MM) benchmark archive made up of 590,326 pairs of Sentinel-1 and Sentinel-2 image patches to support the deep learning (DL) studies in multi-modal multi-label remote sensing (RS) image retrieval and classification. Each pair of patches in BigEarthNet-MM is annotated with multi-labels provided by the CORINE Land Cover (CLC) map of 2018 based on its thematically most detailed Level-3 class nomenclature. Our initial research demonstrates that some CLC classes are challenging to be accurately described by only considering (single-date) BigEarthNet-MM images. In this paper, we also introduce an alternative class-nomenclature as an evolution of the original CLC labels to address this problem. This is achieved by interpreting and arranging the CLC Level-3 nomenclature based on the properties of BigEarthNet-MM images in a new nomenclature of 19 classes. In our experiments, we show the potential of BigEarthNet-MM for multi-modal multi-label image retrieval and classification problems by considering several state-of-the-art DL models. We also demonstrate that the DL models trained from scratch on BigEarthNet-MM outperform those pre-trained on ImageNet, especially in relation to some complex classes, including agriculture and other vegetated and natural environments. We make all the data and the DL models publicly available at https://bigearth.net, offering an important resource to support studies on multi-modal image scene classification and retrieval problems in RS.
A Comparative Study of Deep Learning Loss Functions for Multi-Label Remote Sensing Image Classification
Sep 29, 2020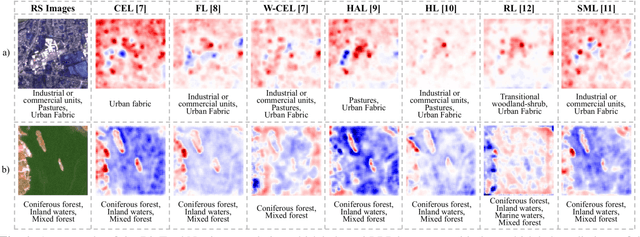
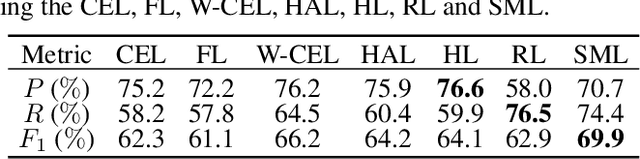
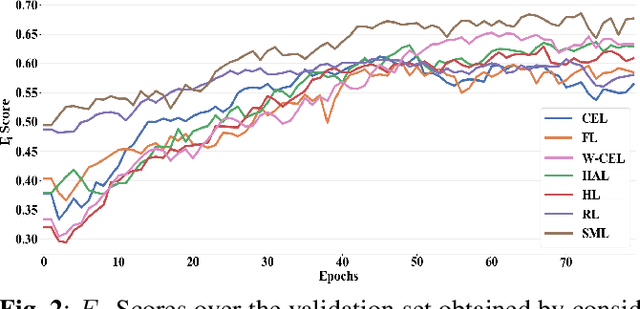
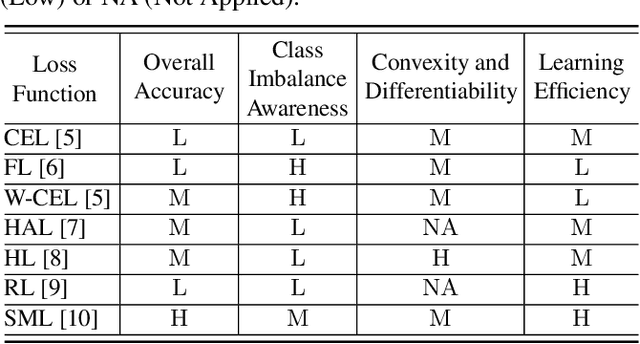
This paper analyzes and compares different deep learning loss functions in the framework of multi-label remote sensing (RS) image scene classification problems. We consider seven loss functions: 1) cross-entropy loss; 2) focal loss; 3) weighted cross-entropy loss; 4) Hamming loss; 5) Huber loss; 6) ranking loss; and 7) sparseMax loss. All the considered loss functions are analyzed for the first time in RS. After a theoretical analysis, an experimental analysis is carried out to compare the considered loss functions in terms of their: 1) overall accuracy; 2) class imbalance awareness (for which the number of samples associated to each class significantly varies); 3) convexibility and differentiability; and 4) learning efficiency (i.e., convergence speed). On the basis of our analysis, some guidelines are derived for a proper selection of a loss function in multi-label RS scene classification problems.
Remote Sensing Image Scene Classification with Deep Neural Networks in JPEG 2000 Compressed Domain
Jun 20, 2020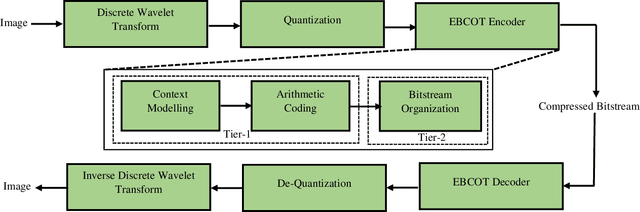
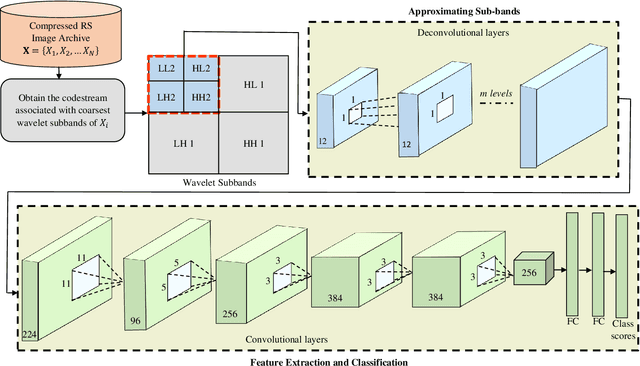
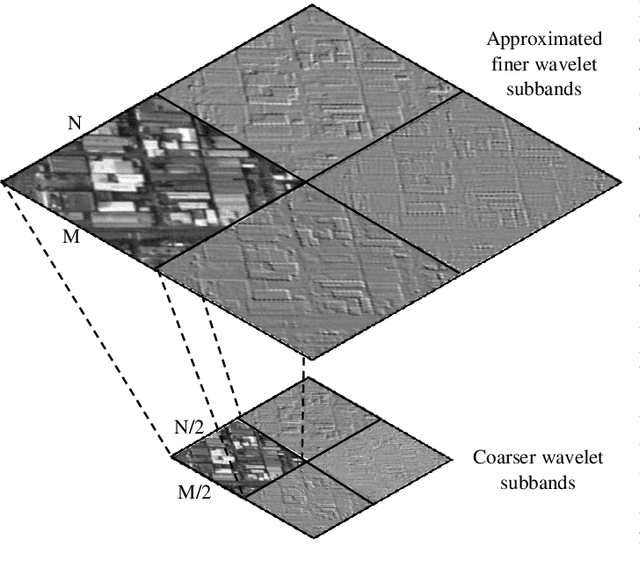
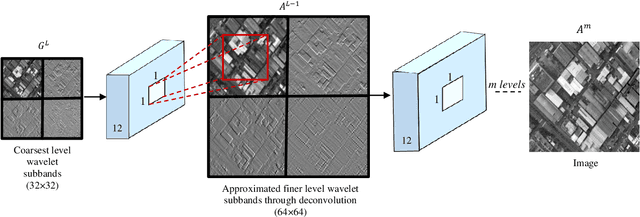
To reduce the storage requirements, remote sensing (RS) images are usually stored in compressed format. Existing scene classification approaches using deep neural networks (DNNs) require to fully decompress the images, which is a computationally demanding task in operational applications. To address this issue, in this paper we propose a novel approach to achieve scene classification in JPEG 2000 compressed RS images. The proposed approach consists of two main steps: i) approximation of the finer resolution sub-bands of reversible biorthogonal wavelet filters used in JPEG 2000; and ii) characterization of the high-level semantic content of approximated wavelet sub-bands and scene classification based on the learnt descriptors. This is achieved by taking codestreams associated with the coarsest resolution wavelet sub-band as input to approximate finer resolution sub-bands using a number of transposed convolutional layers. Then, a series of convolutional layers models the high-level semantic content of the approximated wavelet sub-band. Thus, the proposed approach models the multiresolution paradigm given in the JPEG 2000 compression algorithm in an end-to-end trainable unified neural network. In the classification stage, the proposed approach takes only the coarsest resolution wavelet sub-bands as input, thereby reducing the time required to apply decoding. Experimental results performed on two benchmark aerial image archives demonstrate that the proposed approach significantly reduces the computational time with similar classification accuracies when compared to traditional RS scene classification approaches (which requires full image decompression).
SD-RSIC: Summarization Driven Deep Remote Sensing Image Captioning
Jun 15, 2020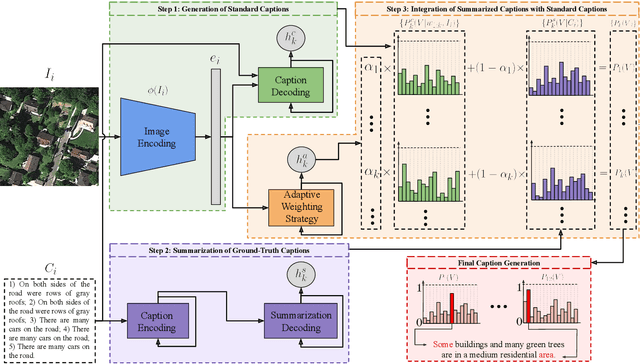
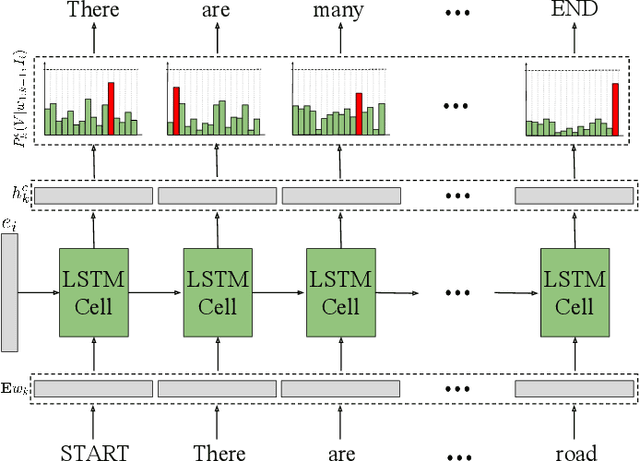


Deep neural networks (DNNs) have been recently found popular for image captioning problems in remote sensing (RS). Existing DNN based approaches rely on the availability of a training set made up of a high number of RS images with their captions. However, captions of training images may contain redundant information (they can be repetitive or semantically similar to each other), resulting in information deficiency while learning a mapping from image domain to language domain. To overcome this limitation, in this paper we present a novel Summarization Driven Remote Sensing Image Captioning (SD-RSIC) approach. The proposed approach consists of three main steps. The first step obtains the standard image captions by jointly exploiting convolutional neural networks (CNNs) with long short-term memory (LSTM) networks. The second step, unlike the existing RS image captioning methods, summarizes the ground-truth captions of each training image into a single caption by exploiting sequence to sequence neural networks and eliminates the redundancy present in the training set. The third step automatically defines the adaptive weights associated to each RS image to combine the standard captions with the summarized captions based on the semantic content of the image. This is achieved by a novel adaptive weighting strategy defined in the context of LSTM networks. Experimental results obtained on the RSCID, UCM-Captions and Sydney-Captions datasets show the effectiveness of the proposed approach compared to the state-of-the-art RS image captioning approaches.
Deep Learning for Image Search and Retrieval in Large Remote Sensing Archives
Apr 03, 2020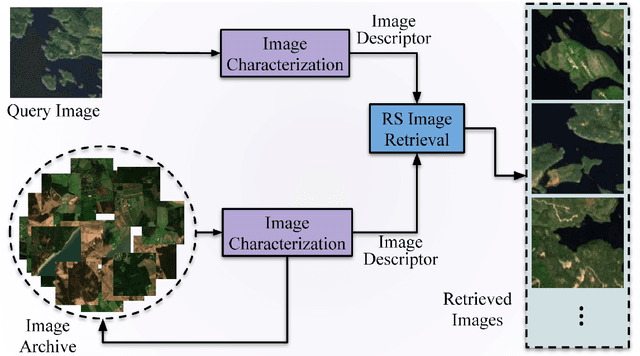
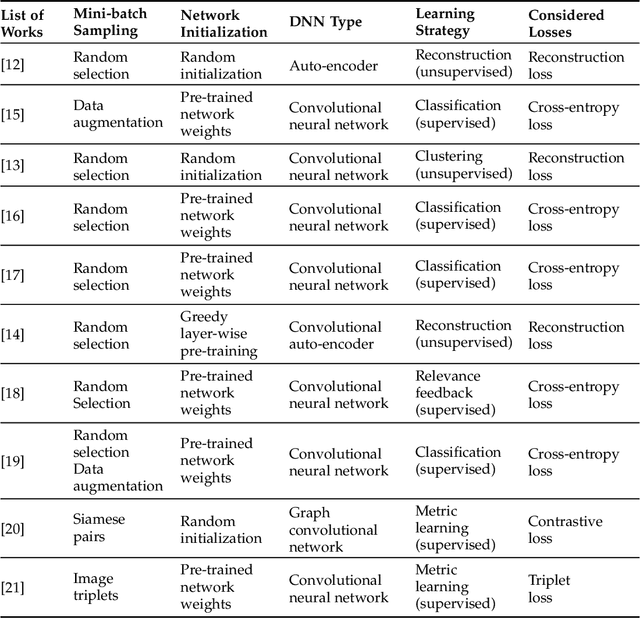
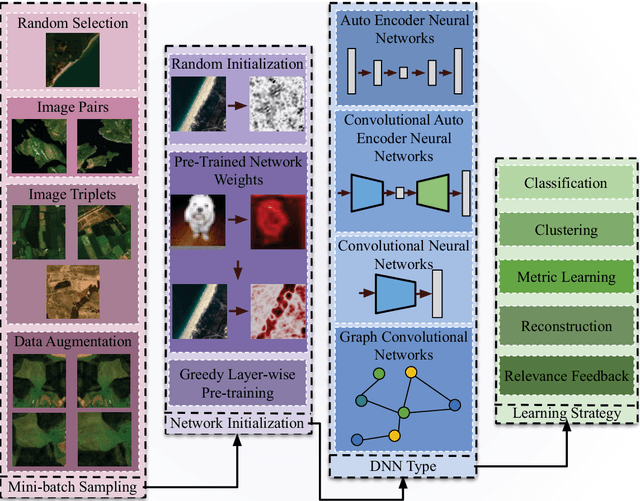
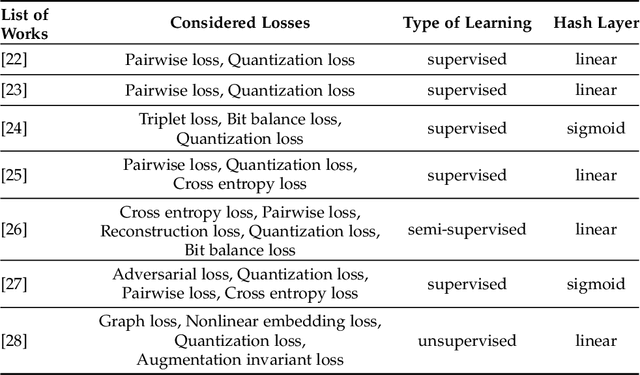
This chapter presents recent advances in content based image search and retrieval (CBIR) systems in remote sensing (RS) for fast and accurate information discovery from massive data archives. Initially, we analyze the limitations of the traditional CBIR systems that rely on the hand-crafted RS image descriptors applied to exhaustive search and retrieval problems. Then, we focus our attention on the advances in RS CBIR systems for which the deep learning (DL) models are at the forefront. In particular, we present the theoretical properties of the most recent DL based CBIR systems for the characterization of the complex semantic content of RS images. After discussing their strengths and limitations, we present the deep hashing based CBIR systems that have high time-efficient search capability within huge data archives. Finally, the most promising research directions in RS CBIR are discussed.
BigEarthNet Dataset with A New Class-Nomenclature for Remote Sensing Image Understanding
Feb 18, 2020


This paper presents BigEarthNet that is a large-scale Sentinel-2 multispectral image dataset with a new class nomenclature to advance deep learning (DL) studies in remote sensing (RS). BigEarthNet is made up of 590,326 image patches annotated with multi-labels provided by the CORINE Land Cover (CLC) map of 2018 based on its most thematic detailed Level-3 class nomenclature. Initial research demonstrates that some CLC classes are challenging to be accurately described by considering only Sentinel-2 images. To increase the effectiveness of BigEarthNet, in this paper we introduce an alternative class-nomenclature to allow DL models for better learning and describing the complex spatial and spectral information content of the Sentinel-2 images. This is achieved by interpreting and arranging the CLC Level-3 nomenclature based on the properties of Sentinel-2 images in a new nomenclature of 19 classes. Then, the new class-nomenclature of BigEarthNet is used within state-of-the-art DL models in the context of multi-label classification. Results show that the models trained from scratch on BigEarthNet outperform those pre-trained on ImageNet, especially in relation to some complex classes including agriculture, other vegetated and natural environments. All DL models are made publicly available at http://bigearth.net/#downloads, offering an important resource to guide future progress on RS image analysis.
An Approach to Super-Resolution of Sentinel-2 Images Based on Generative Adversarial Networks
Feb 07, 2020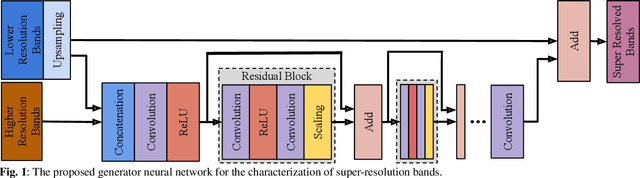
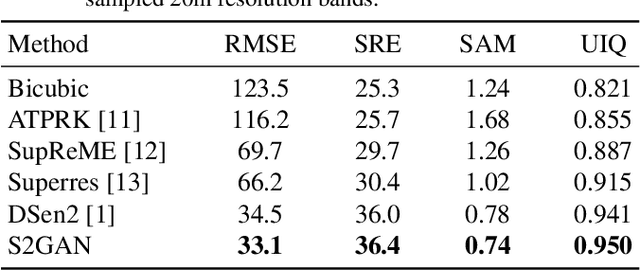
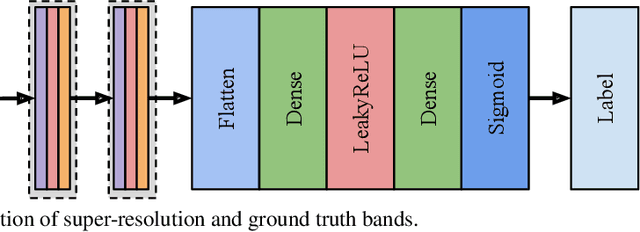
This paper presents a generative adversarial network based super-resolution (SR) approach (which is called as S2GAN) to enhance the spatial resolution of Sentinel-2 spectral bands. The proposed approach consists of two main steps. The first step aims to increase the spatial resolution of the bands with 20m and 60m spatial resolutions by the scaling factors of 2 and 6, respectively. To this end, we introduce a generator network that performs SR on the lower resolution bands with the guidance of the bands associated to 10m spatial resolution by utilizing the convolutional layers with residual connections and a long skip-connection between inputs and outputs. The second step aims to distinguish SR bands from their ground truth bands. This is achieved by the proposed discriminator network, which alternately characterizes the high level features of the two sets of bands and applying binary classification on the extracted features. Then, we formulate the adversarial learning of the generator and discriminator networks as a min-max game. In this learning procedure, the generator aims to produce realistic SR bands as much as possible so that the discriminator incorrectly classifies SR bands. Experimental results obtained on different Sentinel-2 images show the effectiveness of the proposed approach compared to both conventional and deep learning based SR approaches.
BigEarthNet Deep Learning Models with A New Class-Nomenclature for Remote Sensing Image Understanding
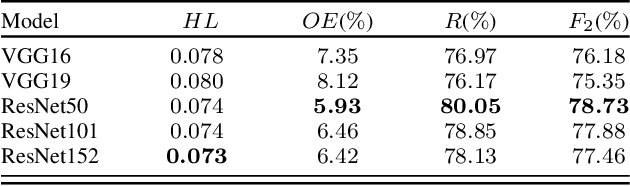
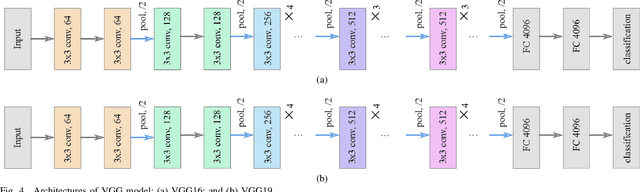
Jan 17, 2020Success of deep neural networks in the framework of remote sensing (RS) image analysis depends on the availability of a high number of annotated images. BigEarthNet is a new large-scale Sentinel-2 benchmark archive that has been recently introduced in RS to advance deep learning (DL) studies. Each image patch in BigEarthNet is annotated with multi-labels provided by the CORINE Land Cover (CLC) map of 2018 based on its most thematic detailed Level-3 class nomenclature. BigEarthNet has enabled data-hungry DL algorithms to reach high performance in the context of multi-label RS image retrieval and classification. However, initial research demonstrates that some CLC classes are challenging to be accurately described by considering only (single-date) Sentinel-2 images. To further increase the effectiveness of BigEarthNet, in this paper we introduce an alternative class-nomenclature to allow DL models for better learning and describing the complex spatial and spectral information content of the Sentinel-2 images. This is achieved by interpreting and arranging the CLC Level-3 nomenclature based on the properties of Sentinel-2 images in a new nomenclature of 19 classes. Then, the new class-nomenclature of BigEarthNet is used within state-of-the-art DL models (namely VGG model at the depth of 16 and 19 layers [VGG16 and VGG19] and ResNet model at the depth of 50, 101 and 152 layers [ResNet50, ResNet101, ResNet152] as well as K-Branch CNN model) in the context of multi-label classification. Experimental results show that the models trained from scratch on BigEarthNet outperform those pre-trained on ImageNet, especially in relation to some complex classes including agriculture and other vegetated and natural environments. All DL models are made publicly available, offering an important resource to guide future progress on content based image retrieval and scene classification problems in RS.