 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Convolutional Neural Networks for Pairwise Causality
Jan 03, 2017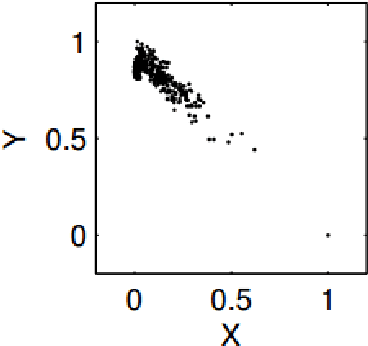



Discovering causal models from observational and interventional data is an important first step preceding what-if analysis or counterfactual reasoning. As has been shown before, the direction of pairwise causal relations can, under certain conditions, be inferred from observational data via standard gradient-boosted classifiers (GBC) using carefully engineered statistical features. In this paper we apply deep convolutional neural networks (CNNs) to this problem by plotting attribute pairs as 2-D scatter plots that are fed to the CNN as images. We evaluate our approach on the 'Cause- Effect Pairs' NIPS 2013 Data Challenge. We observe that a weighted ensemble of CNN with the earlier GBC approach yields significant improvement. Further, we observe that when less training data is available, our approach performs better than the GBC based approach suggesting that CNN models pre-trained to determine the direction of pairwise causal direction could have wider applicability in causal discovery and enabling what-if or counterfactual analysis.
Neuro-symbolic EDA-based Optimisation using ILP-enhanced DBNs
Dec 20, 2016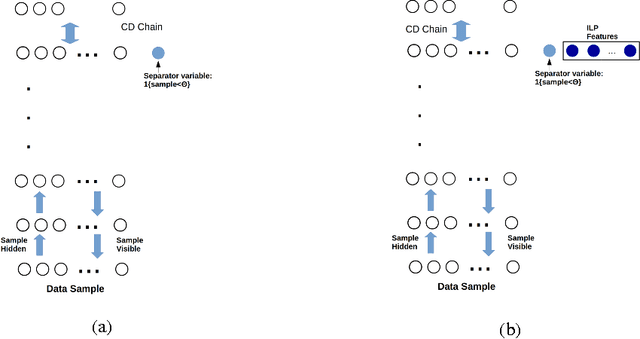
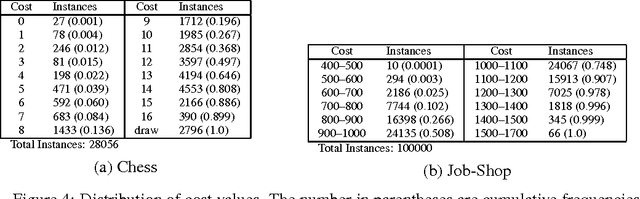
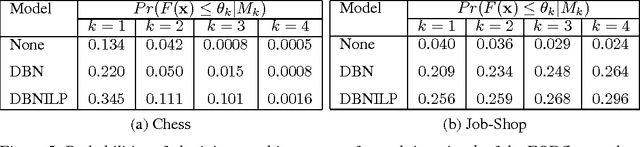
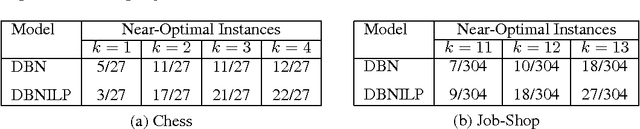
We investigate solving discrete optimisation problems using the estimation of distribution (EDA) approach via a novel combination of deep belief networks(DBN) and inductive logic programming (ILP).While DBNs are used to learn the structure of successively better feasible solutions,ILP enables the incorporation of domain-based background knowledge related to the goodness of solutions.Recent work showed that ILP could be an effective way to use domain knowledge in an EDA scenario.However,in a purely ILP-based EDA,sampling successive populations is either inefficient or not straightforward.In our Neuro-symbolic EDA,an ILP engine is used to construct a model for good solutions using domain-based background knowledge.These rules are introduced as Boolean features in the last hidden layer of DBNs used for EDA-based optimization.This incorporation of logical ILP features requires some changes while training and sampling from DBNs: (a)our DBNs need to be trained with data for units at the input layer as well as some units in an otherwise hidden layer, and (b)we would like the samples generated to be drawn from instances entailed by the logical model.We demonstrate the viability of our approach on instances of two optimisation problems: predicting optimal depth-of-win for the KRK endgame,and jobshop scheduling.Our results are promising: (i)On each iteration of distribution estimation,samples obtained with an ILP-assisted DBN have a substantially greater proportion of good solutions than samples generated using a DBN without ILP features, and (ii)On termination of distribution estimation,samples obtained using an ILP-assisted DBN contain more near-optimal samples than samples from a DBN without ILP features.These results suggest that the use of ILP-constructed theories could be useful for incorporating complex domain-knowledge into deep models for estimation of distribution based procedures.
Generation of Near-Optimal Solutions Using ILP-Guided Sampling
Nov 11, 2016


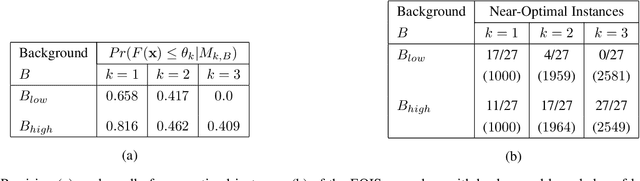
Our interest in this paper is in optimisation problems that are intractable to solve by direct numerical optimisation, but nevertheless have significant amounts of relevant domain-specific knowledge. The category of heuristic search techniques known as estimation of distribution algorithms (EDAs) seek to incrementally sample from probability distributions in which optimal (or near-optimal) solutions have increasingly higher probabilities. Can we use domain knowledge to assist the estimation of these distributions? To answer this in the affirmative, we need: (a)a general-purpose technique for the incorporation of domain knowledge when constructing models for optimal values; and (b)a way of using these models to generate new data samples. Here we investigate a combination of the use of Inductive Logic Programming (ILP) for (a), and standard logic-programming machinery to generate new samples for (b). Specifically, on each iteration of distribution estimation, an ILP engine is used to construct a model for good solutions. The resulting theory is then used to guide the generation of new data instances, which are now restricted to those derivable using the ILP model in conjunction with the background knowledge). We demonstrate the approach on two optimisation problems (predicting optimal depth-of-win for the KRK endgame, and job-shop scheduling). Our results are promising: (a)On each iteration of distribution estimation, samples obtained with an ILP theory have a substantially greater proportion of good solutions than samples without a theory; and (b)On termination of distribution estimation, samples obtained with an ILP theory contain more near-optimal samples than samples without a theory. Taken together, these results suggest that the use of ILP-constructed theories could be a useful technique for incorporating complex domain-knowledge into estimation distribution procedures.
Multi-Sensor Prognostics using an Unsupervised Health Index based on LSTM Encoder-Decoder
Aug 22, 2016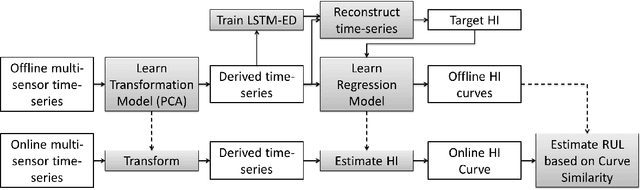
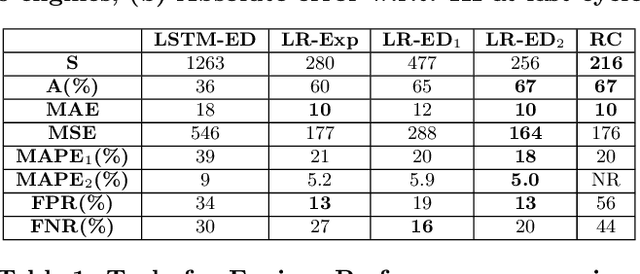
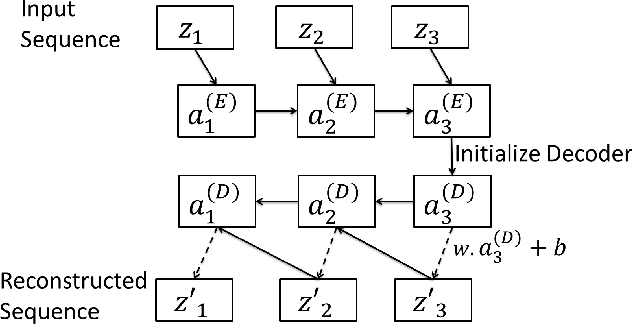
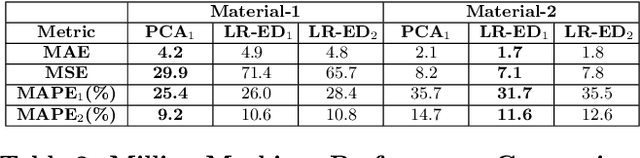
Many approaches for estimation of Remaining Useful Life (RUL) of a machine, using its operational sensor data, make assumptions about how a system degrades or a fault evolves, e.g., exponential degradation. However, in many domains degradation may not follow a pattern. We propose a Long Short Term Memory based Encoder-Decoder (LSTM-ED) scheme to obtain an unsupervised health index (HI) for a system using multi-sensor time-series data. LSTM-ED is trained to reconstruct the time-series corresponding to healthy state of a system. The reconstruction error is used to compute HI which is then used for RUL estimation. We evaluate our approach on publicly available Turbofan Engine and Milling Machine datasets. We also present results on a real-world industry dataset from a pulverizer mill where we find significant correlation between LSTM-ED based HI and maintenance costs.
LSTM-based Encoder-Decoder for Multi-sensor Anomaly Detection
Jul 11, 2016
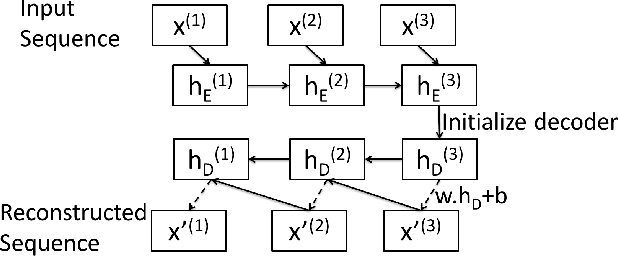
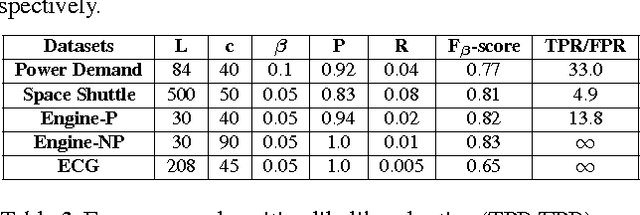
Mechanical devices such as engines, vehicles, aircrafts, etc., are typically instrumented with numerous sensors to capture the behavior and health of the machine. However, there are often external factors or variables which are not captured by sensors leading to time-series which are inherently unpredictable. For instance, manual controls and/or unmonitored environmental conditions or load may lead to inherently unpredictable time-series. Detecting anomalies in such scenarios becomes challenging using standard approaches based on mathematical models that rely on stationarity, or prediction models that utilize prediction errors to detect anomalies. We propose a Long Short Term Memory Networks based Encoder-Decoder scheme for Anomaly Detection (EncDec-AD) that learns to reconstruct 'normal' time-series behavior, and thereafter uses reconstruction error to detect anomalies. We experiment with three publicly available quasi predictable time-series datasets: power demand, space shuttle, and ECG, and two real-world engine datasets with both predictive and unpredictable behavior. We show that EncDec-AD is robust and can detect anomalies from predictable, unpredictable, periodic, aperiodic, and quasi-periodic time-series. Further, we show that EncDec-AD is able to detect anomalies from short time-series (length as small as 30) as well as long time-series (length as large as 500).
ODE - Augmented Training Improves Anomaly Detection in Sensor Data from Machines
May 05, 2016
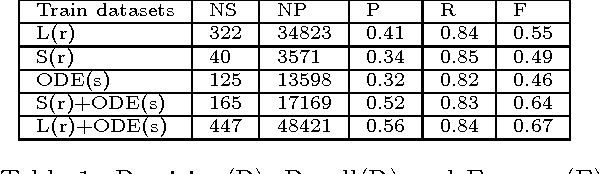
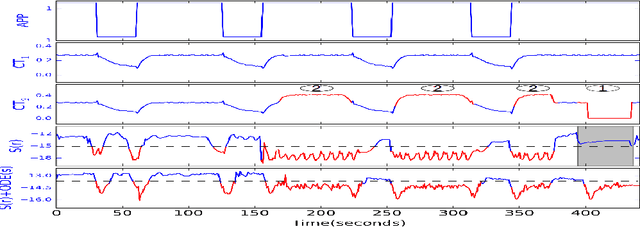

Machines of all kinds from vehicles to industrial equipment are increasingly instrumented with hundreds of sensors. Using such data to detect anomalous behaviour is critical for safety and efficient maintenance. However, anomalies occur rarely and with great variety in such systems, so there is often insufficient anomalous data to build reliable detectors. A standard approach to mitigate this problem is to use one class methods relying only on data from normal behaviour. Unfortunately, even these approaches are more likely to fail in the scenario of a dynamical system with manual control input(s). Normal behaviour in response to novel control input(s) might look very different to the learned detector which may be incorrectly detected as anomalous. In this paper, we address this issue by modelling time-series via Ordinary Differential Equations (ODE) and utilising such an ODE model to simulate the behaviour of dynamical systems under varying control inputs. The available data is then augmented with data generated from the ODE, and the anomaly detector is retrained on this augmented dataset. Experiments demonstrate that ODE-augmented training data allows better coverage of possible control input(s) and results in learning more accurate distinctions between normal and anomalous behaviour in time-series.
Efficiently Discovering Frequent Motifs in Large-scale Sensor Data
Jan 02, 2015
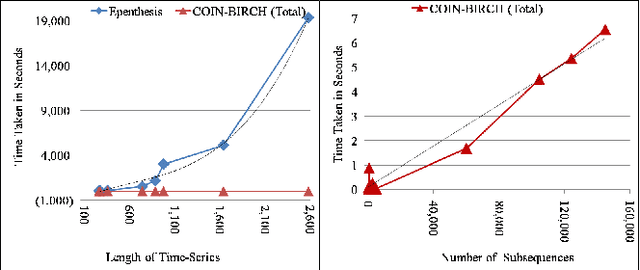
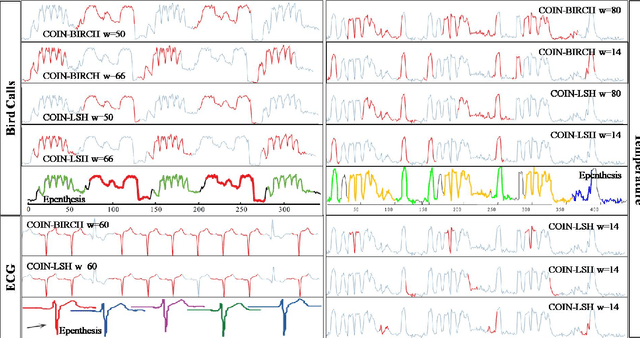

While analyzing vehicular sensor data, we found that frequently occurring waveforms could serve as features for further analysis, such as rule mining, classification, and anomaly detection. The discovery of waveform patterns, also known as time-series motifs, has been studied extensively; however, available techniques for discovering frequently occurring time-series motifs were found lacking in either efficiency or quality: Standard subsequence clustering results in poor quality, to the extent that it has even been termed 'meaningless'. Variants of hierarchical clustering using techniques for efficient discovery of 'exact pair motifs' find high-quality frequent motifs, but at the cost of high computational complexity, making such techniques unusable for our voluminous vehicular sensor data. We show that good quality frequent motifs can be discovered using bounded spherical clustering of time-series subsequences, which we refer to as COIN clustering, with near linear complexity in time-series size. COIN clustering addresses many of the challenges that previously led to subsequence clustering being viewed as meaningless. We describe an end-to-end motif-discovery procedure using a sequence of pre and post-processing techniques that remove trivial-matches and shifted-motifs, which also plagued previous subsequence-clustering approaches. We demonstrate that our technique efficiently discovers frequent motifs in voluminous vehicular sensor data as well as in publicly available data sets.
Warranty Cost Estimation Using Bayesian Network
Nov 11, 2014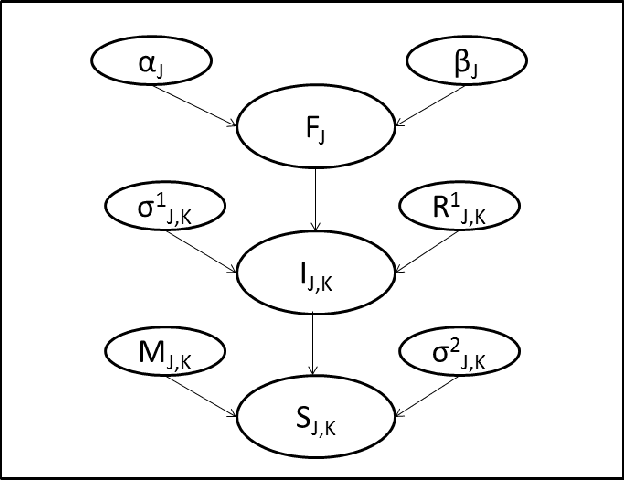



All multi-component product manufacturing companies face the problem of warranty cost estimation. Failure rate analysis of components plays a key role in this problem. Data source used for failure rate analysis has traditionally been past failure data of components. However, failure rate analysis can be improved by means of fusion of additional information, such as symptoms observed during after-sale service of the product, geographical information (hilly or plains areas), and information from tele-diagnostic analytics. In this paper, we propose an approach, which learns dependency between part-failures and symptoms gleaned from such diverse sources of information, to predict expected number of failures with better accuracy. We also indicate how the optimum warranty period can be computed. We demonstrate, through empirical results, that our method can improve the warranty cost estimates significantly.
Multi-Sensor Event Detection using Shape Histograms
Aug 16, 2014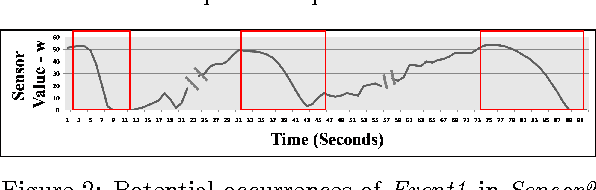
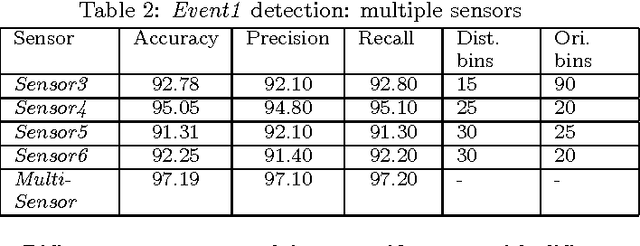
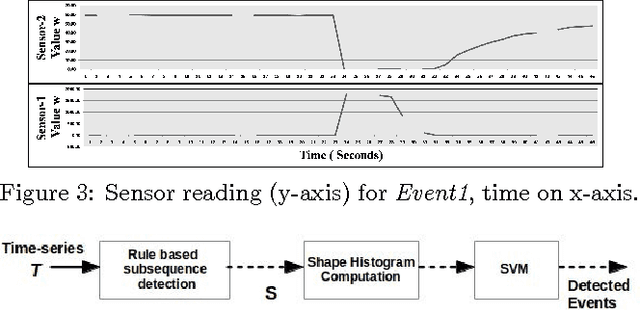
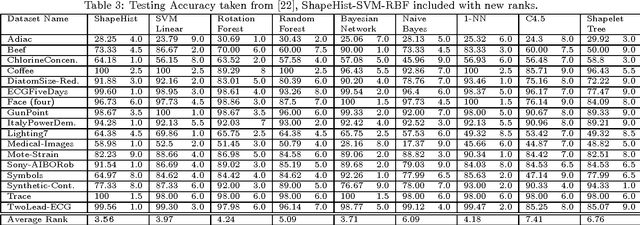
Vehicular sensor data consists of multiple time-series arising from a number of sensors. Using such multi-sensor data we would like to detect occurrences of specific events that vehicles encounter, e.g., corresponding to particular maneuvers that a vehicle makes or conditions that it encounters. Events are characterized by similar waveform patterns re-appearing within one or more sensors. Further such patterns can be of variable duration. In this work, we propose a method for detecting such events in time-series data using a novel feature descriptor motivated by similar ideas in image processing. We define the shape histogram: a constant dimension descriptor that nevertheless captures patterns of variable duration. We demonstrate the efficacy of using shape histograms as features to detect events in an SVM-based, multi-sensor, supervised learning scenario, i.e., multiple time-series are used to detect an event. We present results on real-life vehicular sensor data and show that our technique performs better than available pattern detection implementations on our data, and that it can also be used to combine features from multiple sensors resulting in better accuracy than using any single sensor. Since previous work on pattern detection in time-series has been in the single series context, we also present results using our technique on multiple standard time-series datasets and show that it is the most versatile in terms of how it ranks compared to other published results.