 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT for Sentiment Analysis: Pre-trained and Fine-Tuned Alternatives
Jan 10, 2022
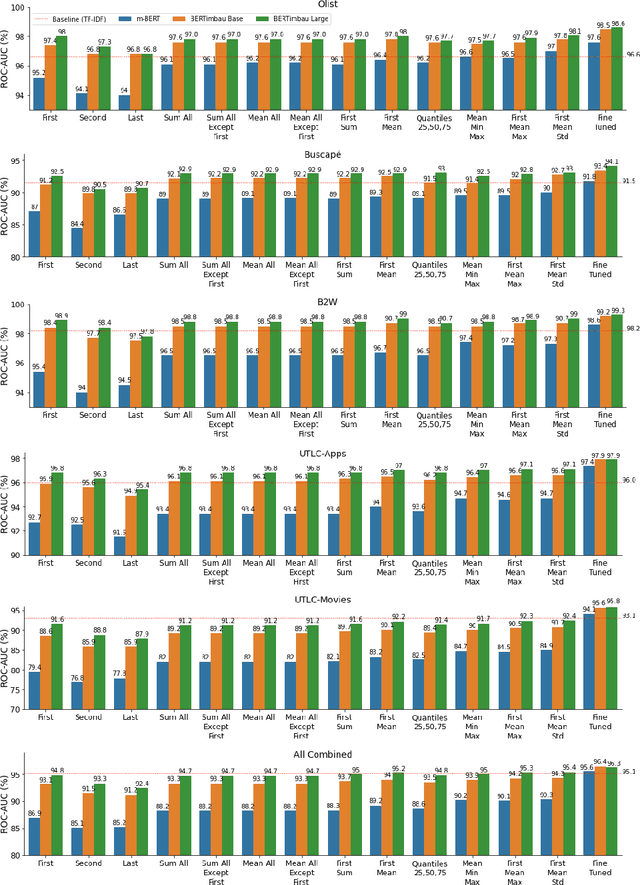
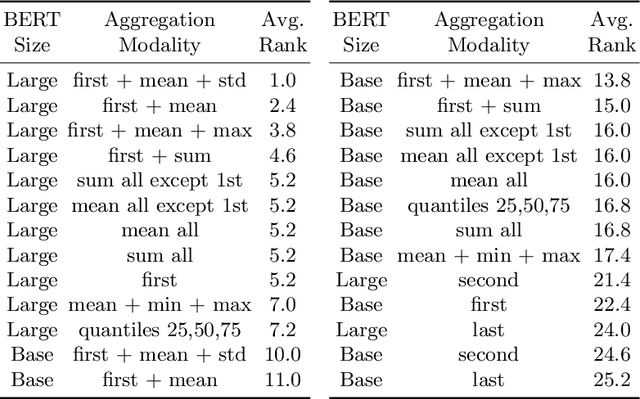
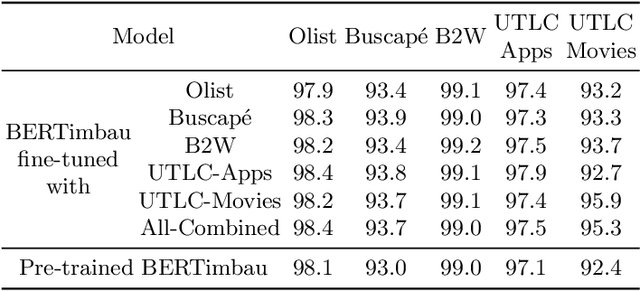
BERT has revolutionized the NLP field by enabling transfer learning with large language models that can capture complex textual patterns, reaching the state-of-the-art for an expressive number of NLP applications. For text classification tasks, BERT has already been extensively explored. However, aspects like how to better cope with the different embeddings provided by the BERT output layer and the usage of language-specific instead of multilingual models are not well studied in the literature, especially for the Brazilian Portuguese language. The purpose of this article is to conduct an extensive experimental study regarding different strategies for aggregating the features produced in the BERT output layer, with a focus on the sentiment analysis task. The experiments include BERT models trained with Brazilian Portuguese corpora and the multilingual version, contemplating multiple aggregation strategies and open-source datasets with predefined training, validation, and test partitions to facilitate the reproducibility of the results. BERT achieved the highest ROC-AUC values for the majority of cases as compared to TF-IDF. Nonetheless, TF-IDF represents a good trade-off between the predictive performance and computational cost.
Sentiment Analysis on Brazilian Portuguese User Reviews
Dec 10, 2021
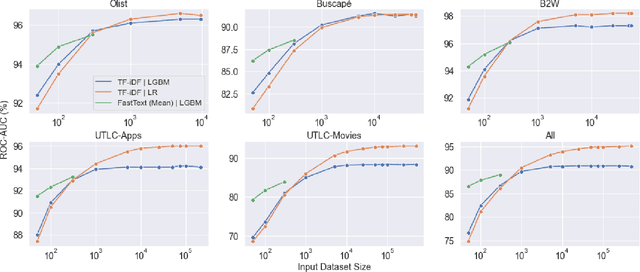
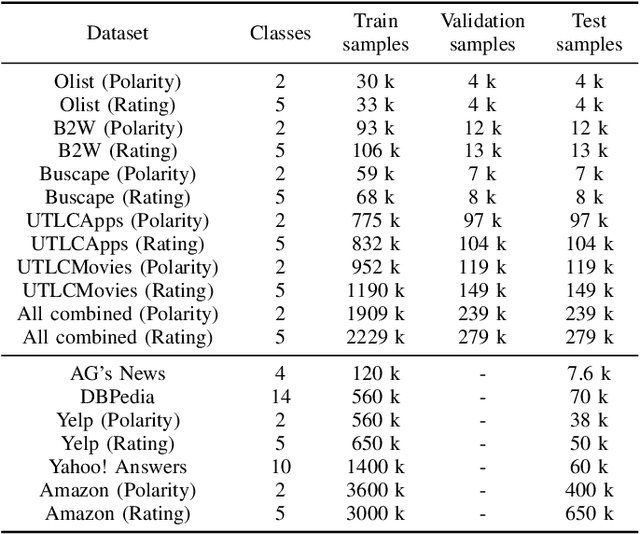
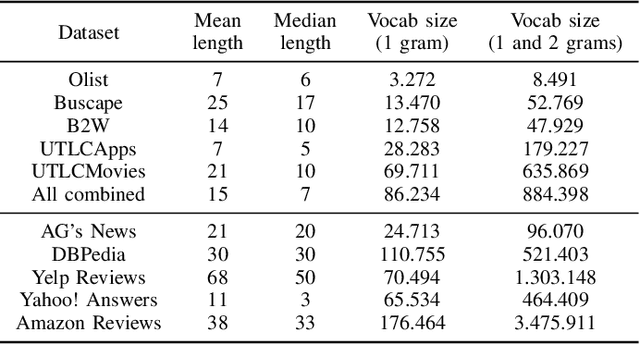
Sentiment Analysis is one of the most classical and primarily studied natural language processing tasks. This problem had a notable advance with the proposition of more complex and scalable machine learning models. Despite this progress, the Brazilian Portuguese language still disposes only of limited linguistic resources, such as datasets dedicated to sentiment classification, especially when considering the existence of predefined partitions in training, testing, and validation sets that would allow a more fair comparison of different algorithm alternatives. Motivated by these issues, this work analyzes the predictive performance of a range of document embedding strategies, assuming the polarity as the system outcome. This analysis includes five sentiment analysis datasets in Brazilian Portuguese, unified in a single dataset, and a reference partitioning in training, testing, and validation sets, both made publicly available through a digital repository. A cross-evaluation of dataset-specific models over different contexts is conducted to evaluate their generalization capabilities and the feasibility of adopting a unique model for addressing all scenarios.