 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrederick Tung
Pretext Training Algorithms for Event Sequence Data
Feb 16, 2024
Pretext training followed by task-specific fine-tuning has been a successful approach in vision and language domains. This paper proposes a self-supervised pretext training framework tailored to event sequence data. We introduce a novel alignment verification task that is specialized to event sequences, building on good practices in masked reconstruction and contrastive learning. Our pretext tasks unlock foundational representations that are generalizable across different down-stream tasks, including next-event prediction for temporal point process models, event sequence classification, and missing event interpolation. Experiments on popular public benchmarks demonstrate the potential of the proposed method across different tasks and data domains.
AdaFlood: Adaptive Flood Regularization
Nov 06, 2023Although neural networks are conventionally optimized towards zero training loss, it has been recently learned that targeting a non-zero training loss threshold, referred to as a flood level, often enables better test time generalization. Current approaches, however, apply the same constant flood level to all training samples, which inherently assumes all the samples have the same difficulty. We present AdaFlood, a novel flood regularization method that adapts the flood level of each training sample according to the difficulty of the sample. Intuitively, since training samples are not equal in difficulty, the target training loss should be conditioned on the instance. Experiments on datasets covering four diverse input modalities - text, images, asynchronous event sequences, and tabular - demonstrate the versatility of AdaFlood across data domains and noise levels.
Prompting-based Efficient Temporal Domain Generalization
Oct 03, 2023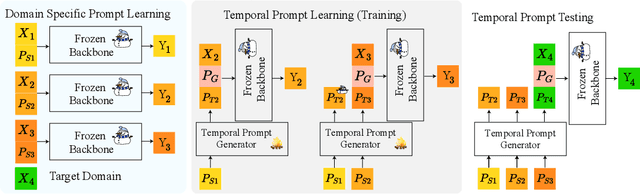
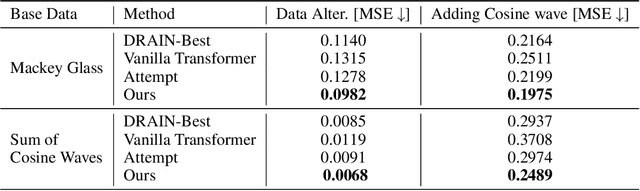
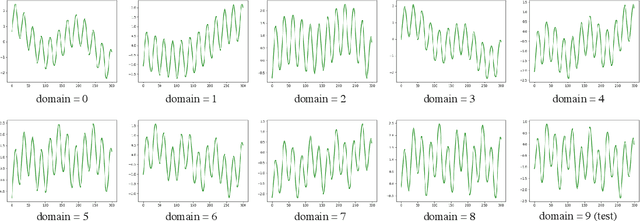
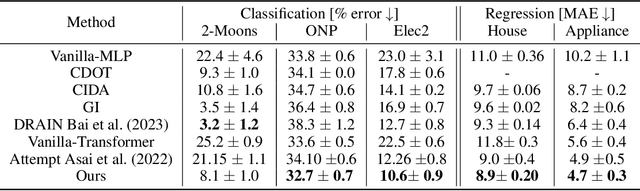
Machine learning traditionally assumes that training and testing data are distributed independently and identically. However, in many real-world settings, the data distribution can shift over time, leading to poor generalization of trained models in future time periods. Our paper presents a novel prompting-based approach to temporal domain generalization that is parameter-efficient, time-efficient, and does not require access to the target domain data (i.e., unseen future time periods) during training. Our method adapts a target pre-trained model to temporal drift by learning global prompts, domain-specific prompts, and drift-aware prompts that capture underlying temporal dynamics. It is compatible across diverse tasks, such as classification, regression, and time series forecasting, and sets a new state-of-the-art benchmark in temporal domain generalization. The code repository will be publicly shared.
Tree Cross Attention
Sep 29, 2023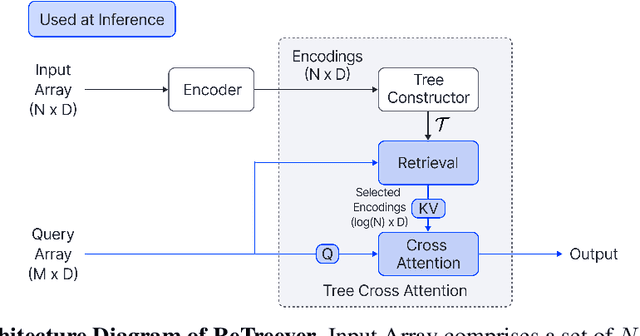
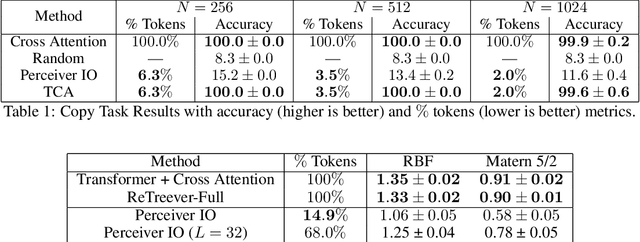
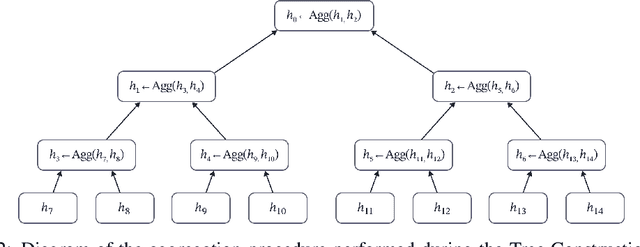
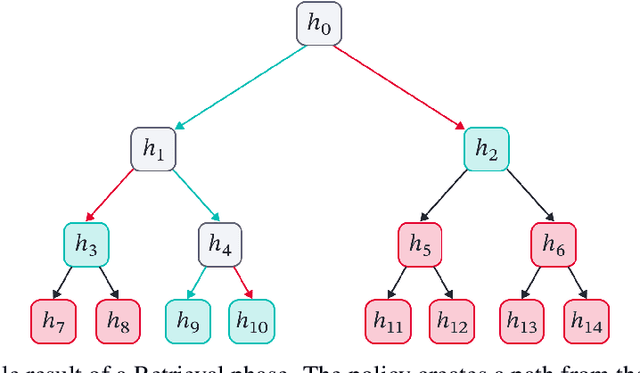
Cross Attention is a popular method for retrieving information from a set of context tokens for making predictions. At inference time, for each prediction, Cross Attention scans the full set of $\mathcal{O}(N)$ tokens. In practice, however, often only a small subset of tokens are required for good performance. Methods such as Perceiver IO are cheap at inference as they distill the information to a smaller-sized set of latent tokens $L < N$ on which cross attention is then applied, resulting in only $\mathcal{O}(L)$ complexity. However, in practice, as the number of input tokens and the amount of information to distill increases, the number of latent tokens needed also increases significantly. In this work, we propose Tree Cross Attention (TCA) - a module based on Cross Attention that only retrieves information from a logarithmic $\mathcal{O}(\log(N))$ number of tokens for performing inference. TCA organizes the data in a tree structure and performs a tree search at inference time to retrieve the relevant tokens for prediction. Leveraging TCA, we introduce ReTreever, a flexible architecture for token-efficient inference. We show empirically that Tree Cross Attention (TCA) performs comparable to Cross Attention across various classification and uncertainty regression tasks while being significantly more token-efficient. Furthermore, we compare ReTreever against Perceiver IO, showing significant gains while using the same number of tokens for inference.
Constant Memory Attention Block
Jun 21, 2023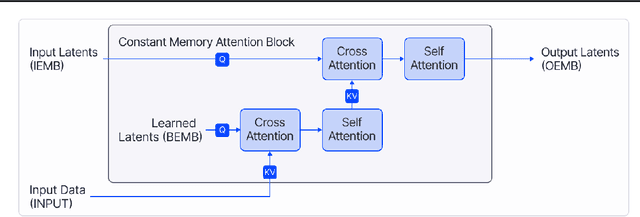
Modern foundation model architectures rely on attention mechanisms to effectively capture context. However, these methods require linear or quadratic memory in terms of the number of inputs/datapoints, limiting their applicability in low-compute domains. In this work, we propose Constant Memory Attention Block (CMAB), a novel general-purpose attention block that computes its output in constant memory and performs updates in constant computation. Highlighting CMABs efficacy, we introduce methods for Neural Processes and Temporal Point Processes. Empirically, we show our proposed methods achieve results competitive with state-of-the-art while being significantly more memory efficient.
DynaShare: Task and Instance Conditioned Parameter Sharing for Multi-Task Learning
May 26, 2023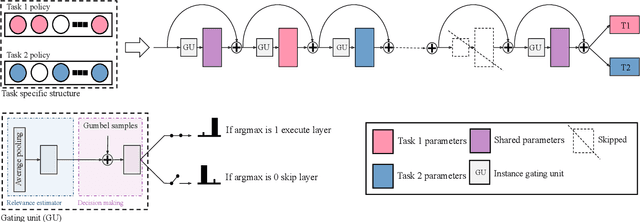
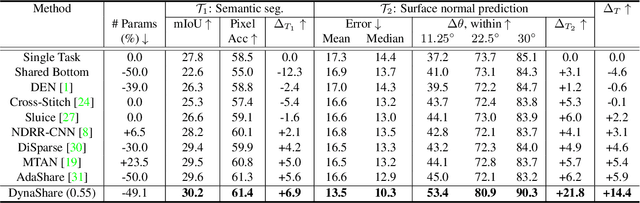
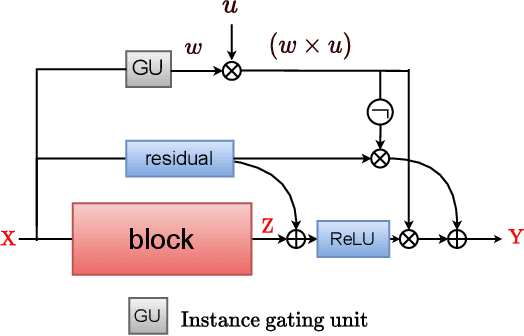
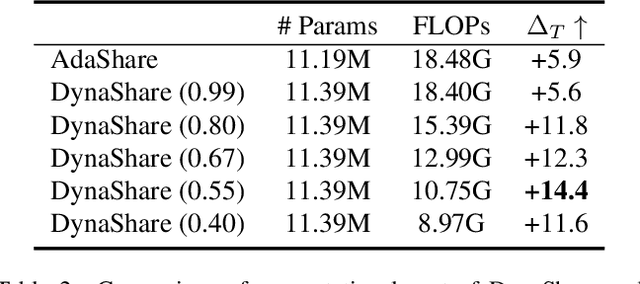
Multi-task networks rely on effective parameter sharing to achieve robust generalization across tasks. In this paper, we present a novel parameter sharing method for multi-task learning that conditions parameter sharing on both the task and the intermediate feature representations at inference time. In contrast to traditional parameter sharing approaches, which fix or learn a deterministic sharing pattern during training and apply the same pattern to all examples during inference, we propose to dynamically decide which parts of the network to activate based on both the task and the input instance. Our approach learns a hierarchical gating policy consisting of a task-specific policy for coarse layer selection and gating units for individual input instances, which work together to determine the execution path at inference time. Experiments on the NYU v2, Cityscapes and MIMIC-III datasets demonstrate the potential of the proposed approach and its applicability across problem domains.
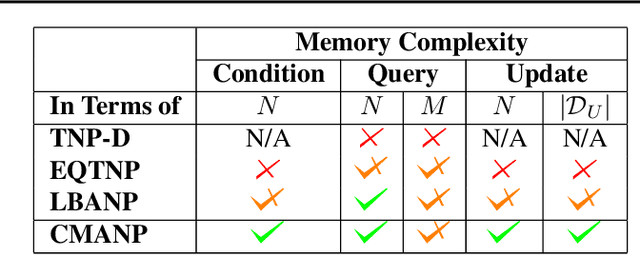
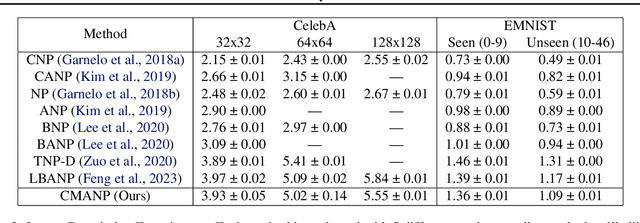
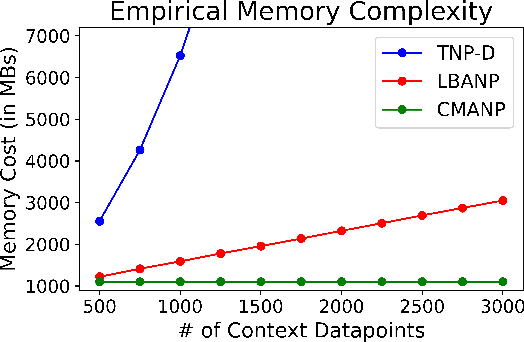
Constant Memory Attentive Neural Processes
May 23, 2023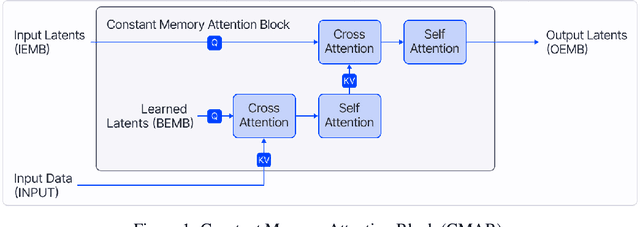

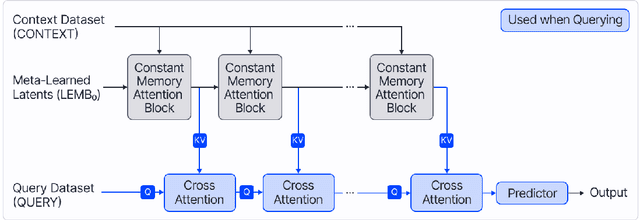
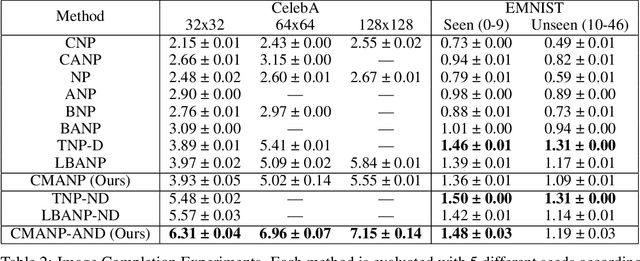
Neural Processes (NPs) are efficient methods for estimating predictive uncertainties. NPs comprise of a conditioning phase where a context dataset is encoded, a querying phase where the model makes predictions using the context dataset encoding, and an updating phase where the model updates its encoding with newly received datapoints. However, state-of-the-art methods require additional memory which scales linearly or quadratically with the size of the dataset, limiting their applications, particularly in low-resource settings. In this work, we propose Constant Memory Attentive Neural Processes (CMANPs), an NP variant which only requires constant memory for the conditioning, querying, and updating phases. In building CMANPs, we propose Constant Memory Attention Block (CMAB), a novel general-purpose attention block that can compute its output in constant memory and perform updates in constant computation. Empirically, we show CMANPs achieve state-of-the-art results on meta-regression and image completion tasks while being (1) significantly more memory efficient than prior methods and (2) more scalable to harder settings.
Ranking Regularization for Critical Rare Classes: Minimizing False Positives at a High True Positive Rate
Mar 31, 2023

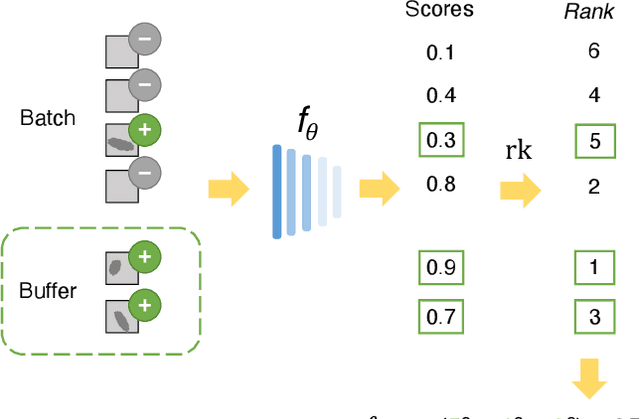
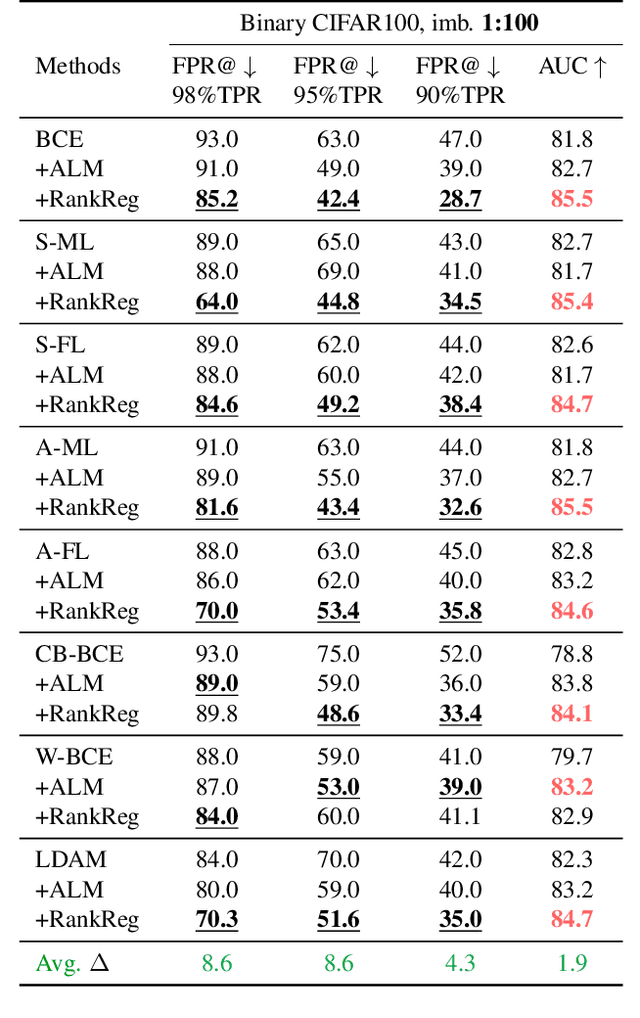
In many real-world settings, the critical class is rare and a missed detection carries a disproportionately high cost. For example, tumors are rare and a false negative diagnosis could have severe consequences on treatment outcomes; fraudulent banking transactions are rare and an undetected occurrence could result in significant losses or legal penalties. In such contexts, systems are often operated at a high true positive rate, which may require tolerating high false positives. In this paper, we present a novel approach to address the challenge of minimizing false positives for systems that need to operate at a high true positive rate. We propose a ranking-based regularization (RankReg) approach that is easy to implement, and show empirically that it not only effectively reduces false positives, but also complements conventional imbalanced learning losses. With this novel technique in hand, we conduct a series of experiments on three broadly explored datasets (CIFAR-10&100 and Melanoma) and show that our approach lifts the previous state-of-the-art performance by notable margins.
Meta Temporal Point Processes
Jan 27, 2023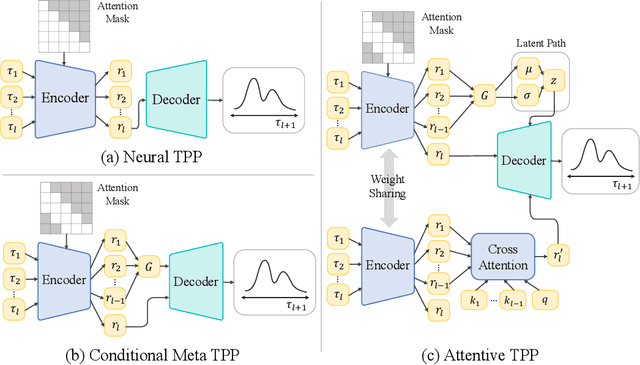
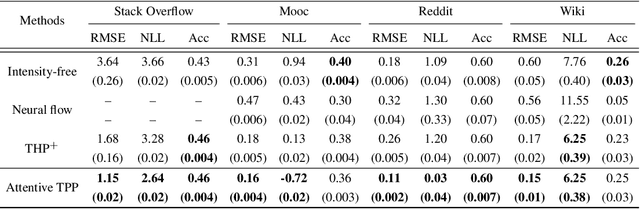
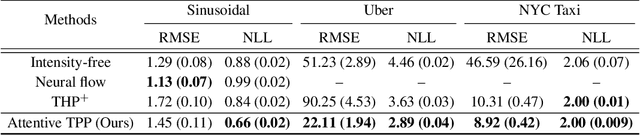
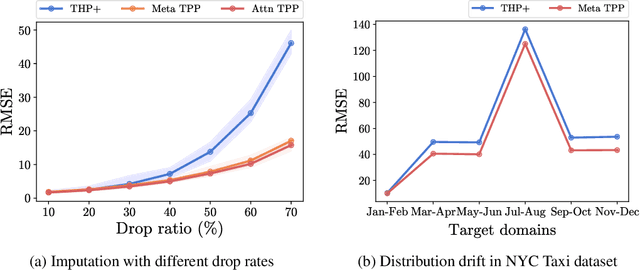
A temporal point process (TPP) is a stochastic process where its realization is a sequence of discrete events in time. Recent work in TPPs model the process using a neural network in a supervised learning framework, where a training set is a collection of all the sequences. In this work, we propose to train TPPs in a meta learning framework, where each sequence is treated as a different task, via a novel framing of TPPs as neural processes (NPs). We introduce context sets to model TPPs as an instantiation of NPs. Motivated by attentive NP, we also introduce local history matching to help learn more informative features. We demonstrate the potential of the proposed method on popular public benchmark datasets and tasks, and compare with state-of-the-art TPP methods.
Gumbel-Softmax Selective Networks
Nov 19, 2022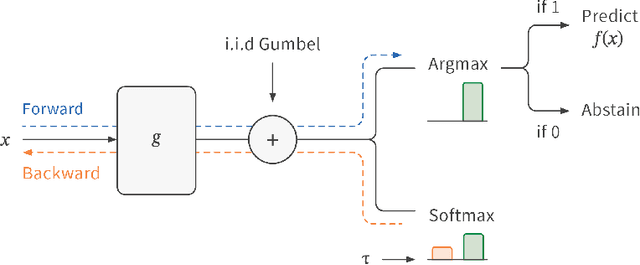
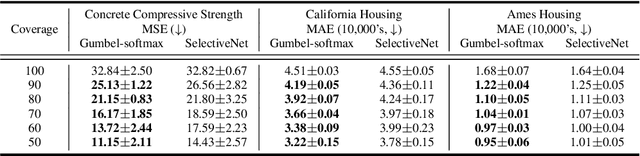

ML models often operate within the context of a larger system that can adapt its response when the ML model is uncertain, such as falling back on safe defaults or a human in the loop. This commonly encountered operational context calls for principled techniques for training ML models with the option to abstain from predicting when uncertain. Selective neural networks are trained with an integrated option to abstain, allowing them to learn to recognize and optimize for the subset of the data distribution for which confident predictions can be made. However, optimizing selective networks is challenging due to the non-differentiability of the binary selection function (the discrete decision of whether to predict or abstain). This paper presents a general method for training selective networks that leverages the Gumbel-softmax reparameterization trick to enable selection within an end-to-end differentiable training framework. Experiments on public datasets demonstrate the potential of Gumbel-softmax selective networks for selective regression and classification.