 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuzzy Attention Neural Network to Tackle Discontinuity in Airway Segmentation
Sep 09, 2022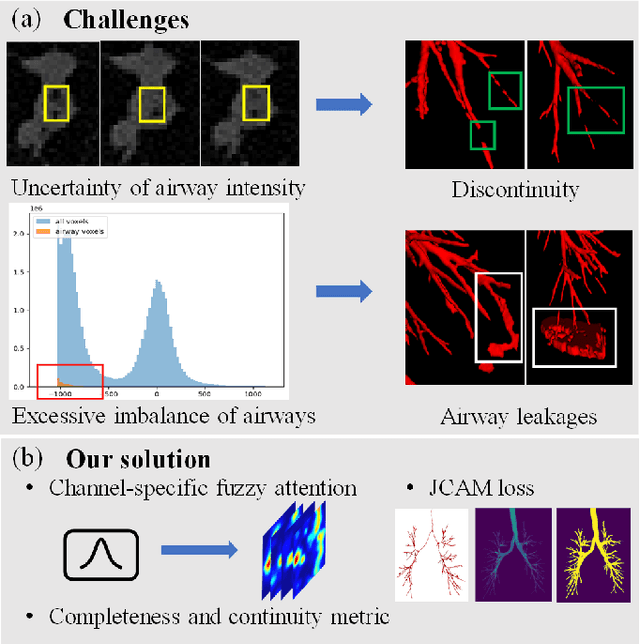
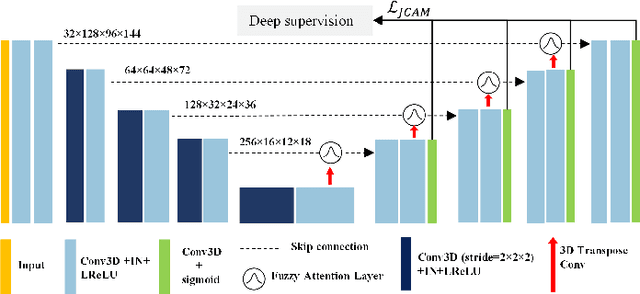
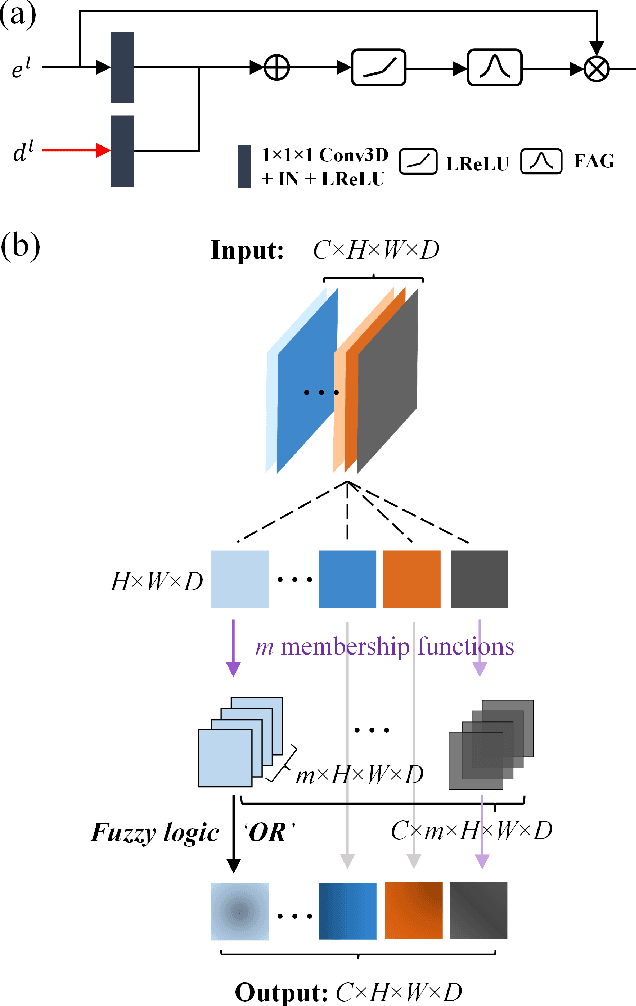
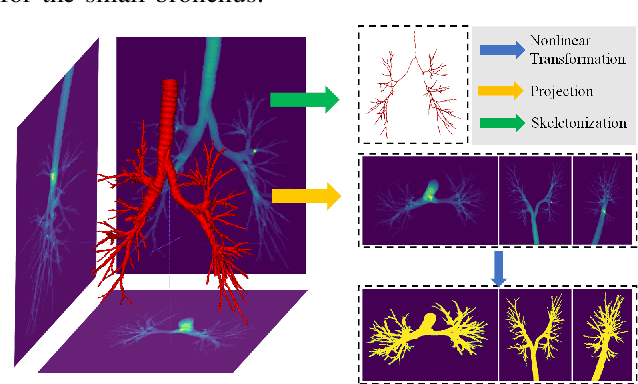
Airway segmentation is crucial for the examination, diagnosis, and prognosis of lung diseases, while its manual delineation is unduly burdensome. To alleviate this time-consuming and potentially subjective manual procedure, researchers have proposed methods to automatically segment airways from computerized tomography (CT) images. However, some small-sized airway branches (e.g., bronchus and terminal bronchioles) significantly aggravate the difficulty of automatic segmentation by machine learning models. In particular, the variance of voxel values and the severe data imbalance in airway branches make the computational module prone to discontinuous and false-negative predictions. especially for cohorts with different lung diseases. Attention mechanism has shown the capacity to segment complex structures, while fuzzy logic can reduce the uncertainty in feature representations. Therefore, the integration of deep attention networks and fuzzy theory, given by the fuzzy attention layer, should be an escalated solution for better generalization and robustness. This paper presents an efficient method for airway segmentation, comprising a novel fuzzy attention neural network and a comprehensive loss function to enhance the spatial continuity of airway segmentation. The deep fuzzy set is formulated by a set of voxels in the feature map and a learnable Gaussian membership function. Different from the existing attention mechanism, the proposed channel-specific fuzzy attention addresses the issue of heterogeneous features in different channels. Furthermore, a novel evaluation metric is proposed to assess both the continuity and completeness of airway structures. The efficiency, generalization and robustness of the proposed method have been proved by training on normal lung disease while testing on datasets of lung cancer, COVID-19 and pulmonary fibrosis.
TSFEDL: A Python Library for Time Series Spatio-Temporal Feature Extraction and Prediction using Deep Learning
Jun 08, 2022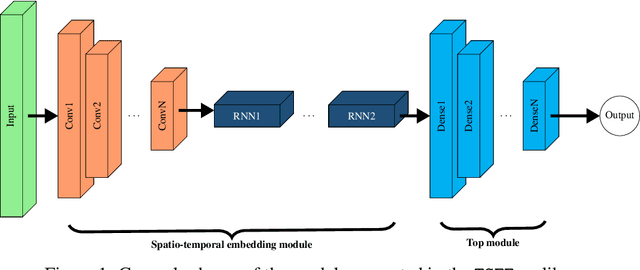
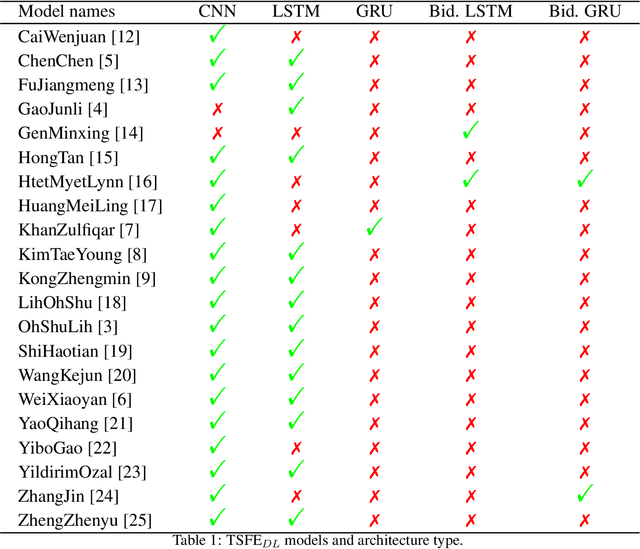
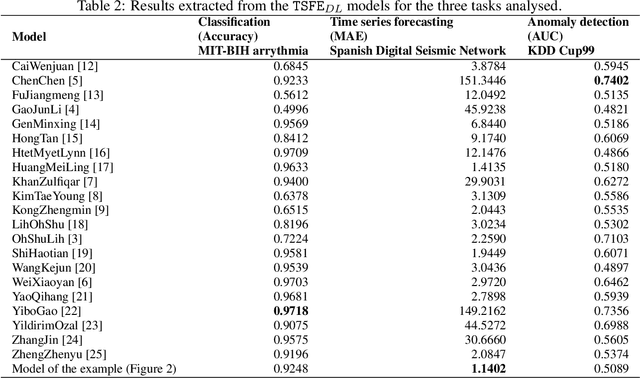
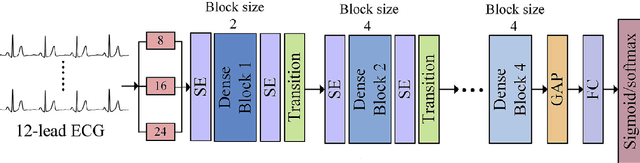
The combination of convolutional and recurrent neural networks is a promising framework that allows the extraction of high-quality spatio-temporal features together with its temporal dependencies, which is key for time series prediction problems such as forecasting, classification or anomaly detection, amongst others. In this paper, the TSFEDL library is introduced. It compiles 20 state-of-the-art methods for both time series feature extraction and prediction, employing convolutional and recurrent deep neural networks for its use in several data mining tasks. The library is built upon a set of Tensorflow+Keras and PyTorch modules under the AGPLv3 license. The performance validation of the architectures included in this proposal confirms the usefulness of this Python package.
Exploring the Trade-off between Plausibility, Change Intensity and Adversarial Power in Counterfactual Explanations using Multi-objective Optimization
May 20, 2022
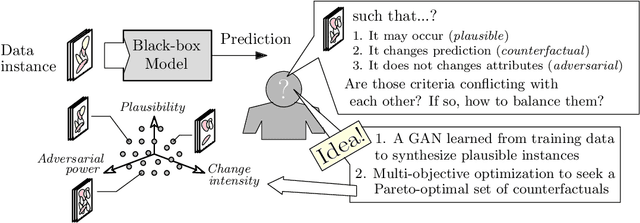
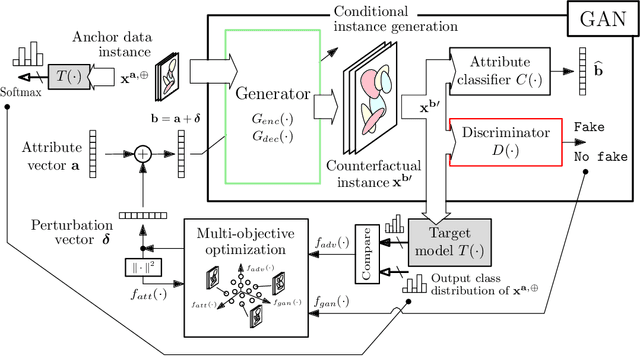
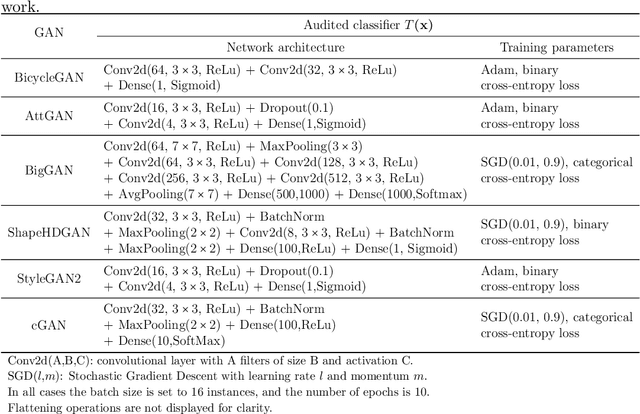
There is a broad consensus on the importance of deep learning models in tasks involving complex data. Often, an adequate understanding of these models is required when focusing on the transparency of decisions in human-critical applications. Besides other explainability techniques, trustworthiness can be achieved by using counterfactuals, like the way a human becomes familiar with an unknown process: by understanding the hypothetical circumstances under which the output changes. In this work we argue that automated counterfactual generation should regard several aspects of the produced adversarial instances, not only their adversarial capability. To this end, we present a novel framework for the generation of counterfactual examples which formulates its goal as a multi-objective optimization problem balancing three different objectives: 1) plausibility, i.e., the likeliness of the counterfactual of being possible as per the distribution of the input data; 2) intensity of the changes to the original input; and 3) adversarial power, namely, the variability of the model's output induced by the counterfactual. The framework departs from a target model to be audited and uses a Generative Adversarial Network to model the distribution of input data, together with a multi-objective solver for the discovery of counterfactuals balancing among these objectives. The utility of the framework is showcased over six classification tasks comprising image and three-dimensional data. The experiments verify that the framework unveils counterfactuals that comply with intuition, increasing the trustworthiness of the user, and leading to further insights, such as the detection of bias and data misrepresentation.
Handling Imbalanced Classification Problems With Support Vector Machines via Evolutionary Bilevel Optimization
Apr 21, 2022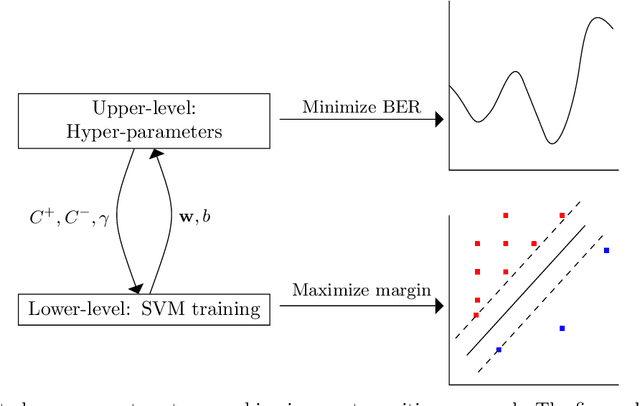
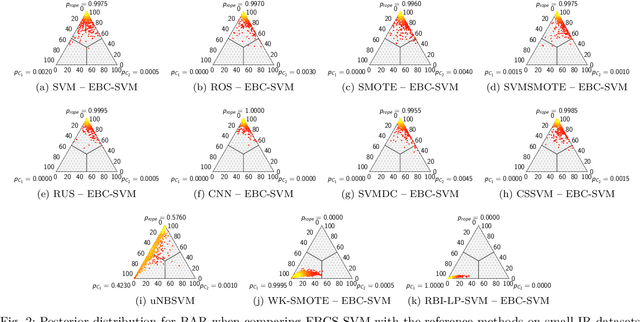
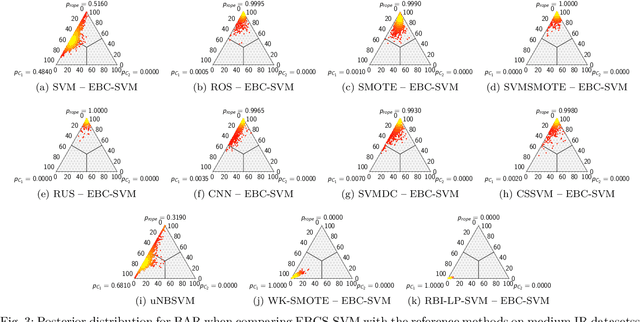
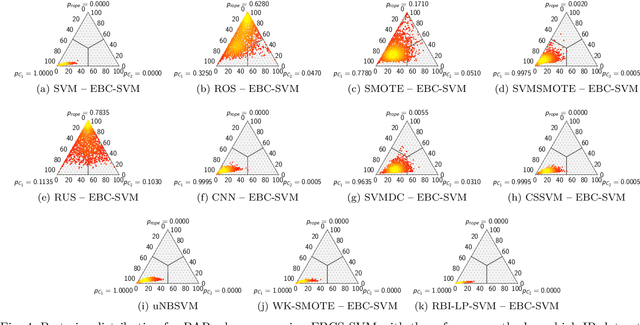
Support vector machines (SVMs) are popular learning algorithms to deal with binary classification problems. They traditionally assume equal misclassification costs for each class; however, real-world problems may have an uneven class distribution. This article introduces EBCS-SVM: evolutionary bilevel cost-sensitive SVMs. EBCS-SVM handles imbalanced classification problems by simultaneously learning the support vectors and optimizing the SVM hyperparameters, which comprise the kernel parameter and misclassification costs. The resulting optimization problem is a bilevel problem, where the lower level determines the support vectors and the upper level the hyperparameters. This optimization problem is solved using an evolutionary algorithm (EA) at the upper level and sequential minimal optimization (SMO) at the lower level. These two methods work in a nested fashion, that is, the optimal support vectors help guide the search of the hyperparameters, and the lower level is initialized based on previous successful solutions. The proposed method is assessed using 70 datasets of imbalanced classification and compared with several state-of-the-art methods. The experimental results, supported by a Bayesian test, provided evidence of the effectiveness of EBCS-SVM when working with highly imbalanced datasets.
* Copyright 2022 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
EvoPruneDeepTL: An Evolutionary Pruning Model for Transfer Learning based Deep Neural Networks
Feb 08, 2022



In recent years, Deep Learning models have shown a great performance in complex optimization problems. They generally require large training datasets, which is a limitation in most practical cases. Transfer learning allows importing the first layers of a pre-trained architecture and connecting them to fully-connected layers to adapt them to a new problem. Consequently, the configuration of the these layers becomes crucial for the performance of the model. Unfortunately, the optimization of these models is usually a computationally demanding task. One strategy to optimize Deep Learning models is the pruning scheme. Pruning methods are focused on reducing the complexity of the network, assuming an expected performance penalty of the model once pruned. However, the pruning could potentially be used to improve the performance, using an optimization algorithm to identify and eventually remove unnecessary connections among neurons. This work proposes EvoPruneDeepTL, an evolutionary pruning model for Transfer Learning based Deep Neural Networks which replaces the last fully-connected layers with sparse layers optimized by a genetic algorithm. Depending on its solution encoding strategy, our proposed model can either perform optimized pruning or feature selection over the densely connected part of the neural network. We carry out different experiments with several datasets to assess the benefits of our proposal. Results show the contribution of EvoPruneDeepTL and feature selection to the overall computational efficiency of the network as a result of the optimization process. In particular, the accuracy is improved reducing at the same time the number of active neurons in the final layers.
Survey on Federated Learning Threats: concepts, taxonomy on attacks and defences, experimental study and challenges
Jan 20, 2022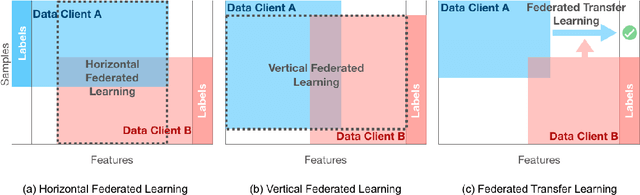
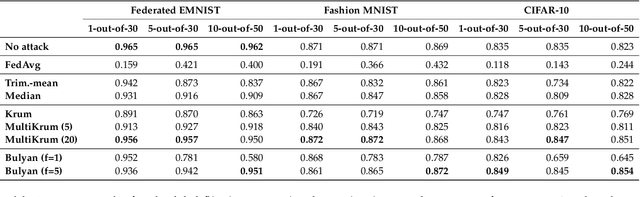
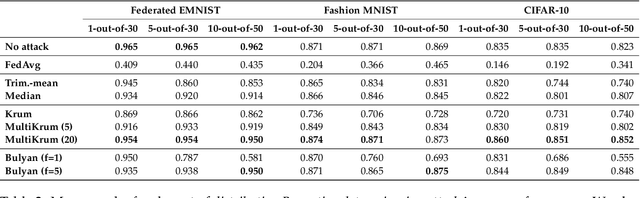
Federated learning is a machine learning paradigm that emerges as a solution to the privacy-preservation demands in artificial intelligence. As machine learning, federated learning is threatened by adversarial attacks against the integrity of the learning model and the privacy of data via a distributed approach to tackle local and global learning. This weak point is exacerbated by the inaccessibility of data in federated learning, which makes harder the protection against adversarial attacks and evidences the need to furtherance the research on defence methods to make federated learning a real solution for safeguarding data privacy. In this paper, we present an extensive review of the threats of federated learning, as well as as their corresponding countermeasures, attacks versus defences. This survey provides a taxonomy of adversarial attacks and a taxonomy of defence methods that depict a general picture of this vulnerability of federated learning and how to overcome it. Likewise, we expound guidelines for selecting the most adequate defence method according to the category of the adversarial attack. Besides, we carry out an extensive experimental study from which we draw further conclusions about the behaviour of attacks and defences and the guidelines for selecting the most adequate defence method according to the category of the adversarial attack. This study is finished leading to meditated learned lessons and challenges.
Data Harmonisation for Information Fusion in Digital Healthcare: A State-of-the-Art Systematic Review, Meta-Analysis and Future Research Directions
Jan 17, 2022


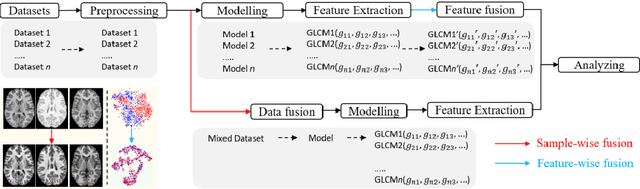
Removing the bias and variance of multicentre data has always been a challenge in large scale digital healthcare studies, which requires the ability to integrate clinical features extracted from data acquired by different scanners and protocols to improve stability and robustness. Previous studies have described various computational approaches to fuse single modality multicentre datasets. However, these surveys rarely focused on evaluation metrics and lacked a checklist for computational data harmonisation studies. In this systematic review, we summarise the computational data harmonisation approaches for multi-modality data in the digital healthcare field, including harmonisation strategies and evaluation metrics based on different theories. In addition, a comprehensive checklist that summarises common practices for data harmonisation studies is proposed to guide researchers to report their research findings more effectively. Last but not least, flowcharts presenting possible ways for methodology and metric selection are proposed and the limitations of different methods have been surveyed for future research.
Reducing Data Complexity using Autoencoders with Class-informed Loss Functions
Nov 11, 2021

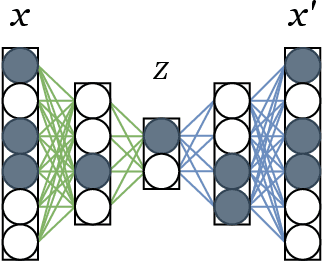
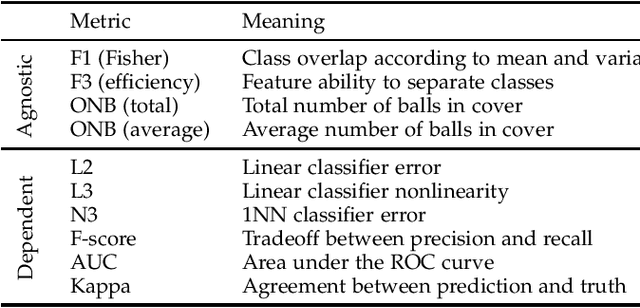
Available data in machine learning applications is becoming increasingly complex, due to higher dimensionality and difficult classes. There exists a wide variety of approaches to measuring complexity of labeled data, according to class overlap, separability or boundary shapes, as well as group morphology. Many techniques can transform the data in order to find better features, but few focus on specifically reducing data complexity. Most data transformation methods mainly treat the dimensionality aspect, leaving aside the available information within class labels which can be useful when classes are somehow complex. This paper proposes an autoencoder-based approach to complexity reduction, using class labels in order to inform the loss function about the adequacy of the generated variables. This leads to three different new feature learners, Scorer, Skaler and Slicer. They are based on Fisher's discriminant ratio, the Kullback-Leibler divergence and least-squares support vector machines, respectively. They can be applied as a preprocessing stage for a binary classification problem. A thorough experimentation across a collection of 27 datasets and a range of complexity and classification metrics shows that class-informed autoencoders perform better than 4 other popular unsupervised feature extraction techniques, especially when the final objective is using the data for a classification task.
A robust approach for deep neural networks in presence of label noise: relabelling and filtering instances during training
Sep 08, 2021
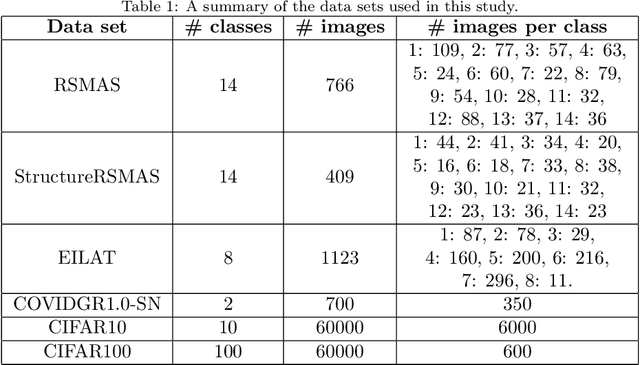
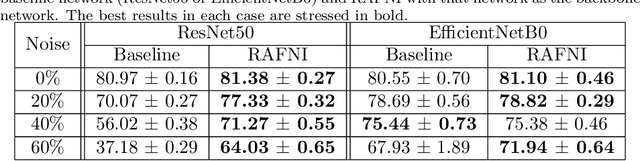

Deep learning has outperformed other machine learning algorithms in a variety of tasks, and as a result, it has become more and more popular and used. However, as other machine learning algorithms, deep learning, and convolutional neural networks (CNNs) in particular, perform worse when the data sets present label noise. Therefore, it is important to develop algorithms that help the training of deep networks and their generalization to noise-free test sets. In this paper, we propose a robust training strategy against label noise, called RAFNI, that can be used with any CNN. This algorithm filters and relabels instances of the training set based on the predictions and their probabilities made by the backbone neural network during the training process. That way, this algorithm improves the generalization ability of the CNN on its own. RAFNI consists of three mechanisms: two mechanisms that filter instances and one mechanism that relabels instances. In addition, it does not suppose that the noise rate is known nor does it need to be estimated. We evaluated our algorithm using different data sets of several sizes and characteristics. We also compared it with state-of-the-art models using the CIFAR10 and CIFAR100 benchmarks under different types and rates of label noise and found that RAFNI achieves better results in most cases.
Anomaly Detection in Predictive Maintenance: A New Evaluation Framework for Temporal Unsupervised Anomaly Detection Algorithms
May 26, 2021
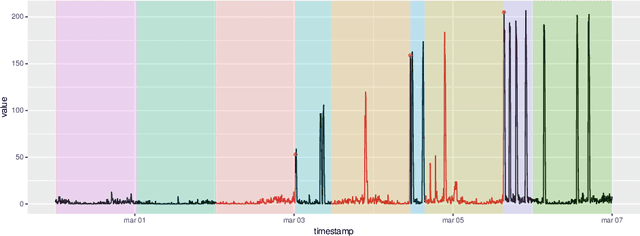
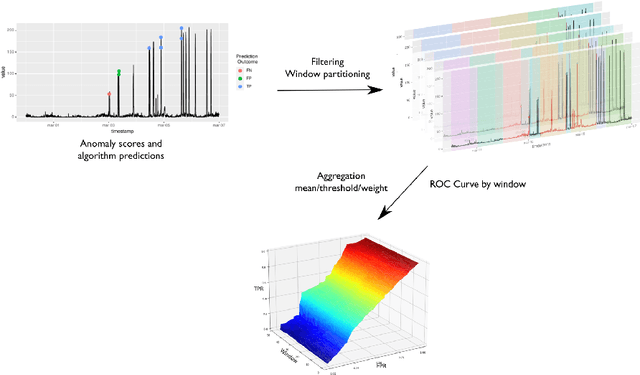

The research in anomaly detection lacks a unified definition of what represents an anomalous instance. Discrepancies in the nature itself of an anomaly lead to multiple paradigms of algorithms design and experimentation. Predictive maintenance is a special case, where the anomaly represents a failure that must be prevented. Related time-series research as outlier and novelty detection or time-series classification does not apply to the concept of an anomaly in this field, because they are not single points which have not been seen previously and may not be precisely annotated. Moreover, due to the lack of annotated anomalous data, many benchmarks are adapted from supervised scenarios. To address these issues, we generalise the concept of positive and negative instances to intervals to be able to evaluate unsupervised anomaly detection algorithms. We also preserve the imbalance scheme for evaluation through the proposal of the Preceding Window ROC, a generalisation for the calculation of ROC curves for time-series scenarios. We also adapt the mechanism from a established time-series anomaly detection benchmark to the proposed generalisations to reward early detection. Therefore, the proposal represents a flexible evaluation framework for the different scenarios. To show the usefulness of this definition, we include a case study of Big Data algorithms with a real-world time-series problem provided by the company ArcelorMittal, and compare the proposal with an evaluation method.