 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRENCH-YMCA: A FRENCH Corpus meeting the language needs of Youth, froM Children to Adolescents
Apr 07, 2026In this paper, we introduce the French-YMCA corpus, a new linguistic resource specifically tailored for children and adolescents. The motivation for building this corpus is clear: children have unique language requirements, as their language skills are in constant evolution and differ from those of adults. With an extensive collection of 39,200 text files, the French-YMCA corpus encompasses a total of 22,471,898 words. It distinguishes itself through its diverse sources, consistent grammar and spelling, and the commitment to providing open online accessibility for all. Such corpus can serve as the foundation for training language models that understand and anticipate youth's language, thereby enhancing the quality of digital interactions and ensuring that responses and suggestions are age-appropriate and adapted to the comprehension level of users of this age.
CNN training with graph-based sample preselection: application to handwritten character recognition
Mar 06, 2018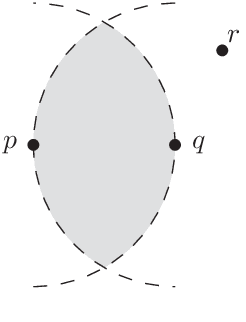
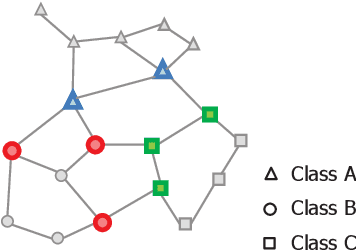
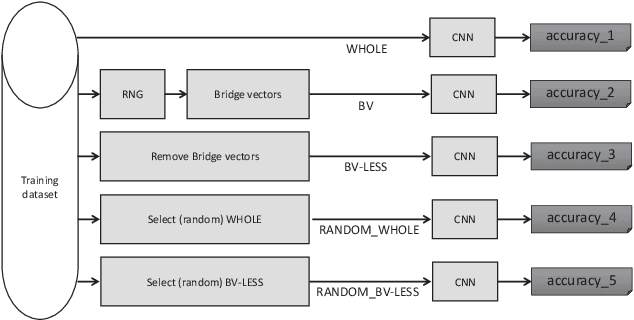
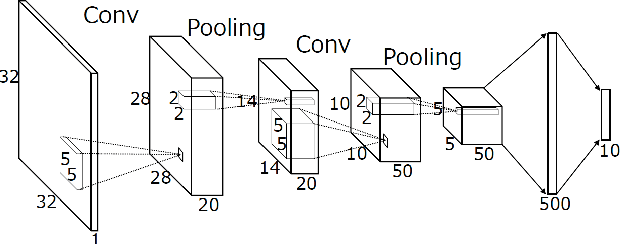
In this paper, we present a study on sample preselection in large training data set for CNN-based classification. To do so, we structure the input data set in a network representation, namely the Relative Neighbourhood Graph, and then extract some vectors of interest. The proposed preselection method is evaluated in the context of handwritten character recognition, by using two data sets, up to several hundred thousands of images. It is shown that the graph-based preselection can reduce the training data set without degrading the recognition accuracy of a non pretrained CNN shallow model.
ImageNet MPEG-7 Visual Descriptors - Technical Report
Feb 01, 2017

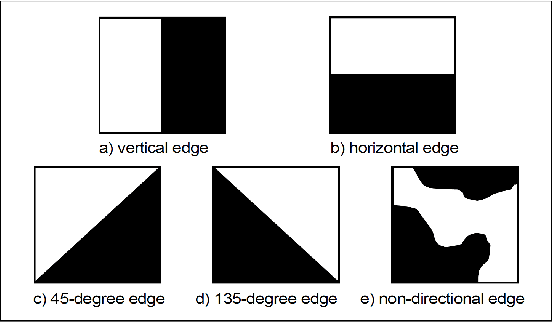
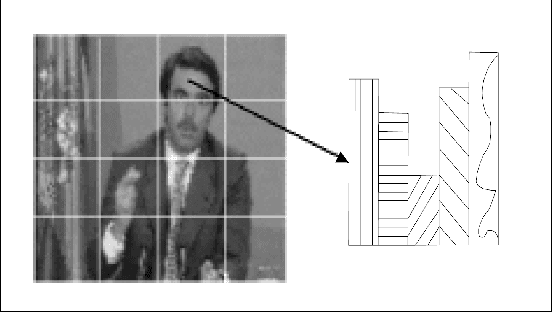
ImageNet is a large scale and publicly available image database. It currently offers more than 14 millions of images, organised according to the WordNet hierarchy. One of the main objective of the creators is to provide to the research community a relevant database for visual recognition applications such as object recognition, image classification or object localisation. However, only a few visual descriptors of the images are available to be used by the researchers. Only SIFT-based features have been extracted from a subset of the collection. This technical report presents the extraction of some MPEG-7 visual descriptors from the ImageNet database. These descriptors are made publicly available in an effort towards open research.