 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeiyue Huang
Fast and Accurate Neural Word Segmentation for Chinese
Apr 24, 2017
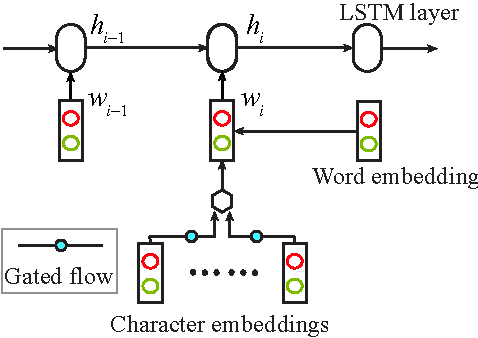

Neural models with minimal feature engineering have achieved competitive performance against traditional methods for the task of Chinese word segmentation. However, both training and working procedures of the current neural models are computationally inefficient. This paper presents a greedy neural word segmenter with balanced word and character embedding inputs to alleviate the existing drawbacks. Our segmenter is truly end-to-end, capable of performing segmentation much faster and even more accurate than state-of-the-art neural models on Chinese benchmark datasets.
Ordinal Constrained Binary Code Learning for Nearest Neighbor Search
Nov 19, 2016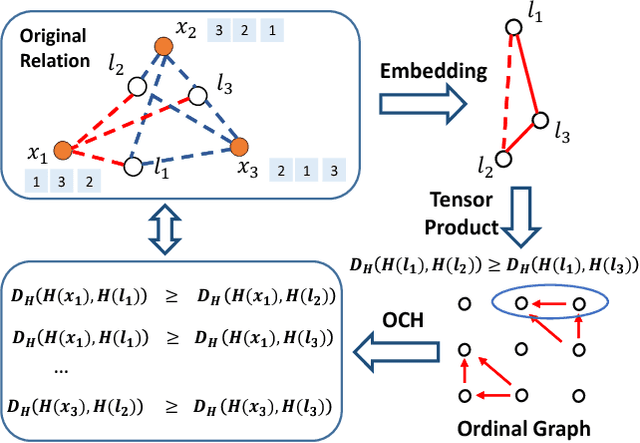
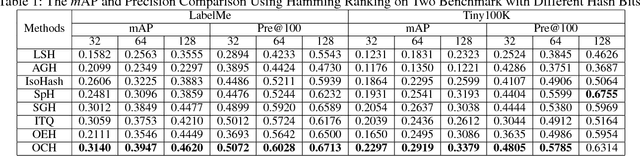
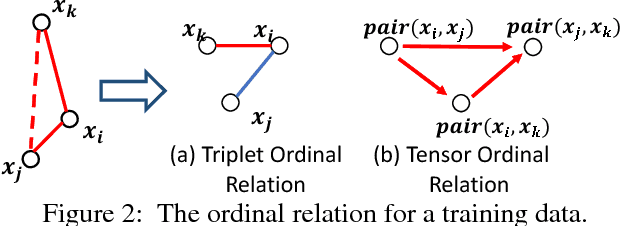
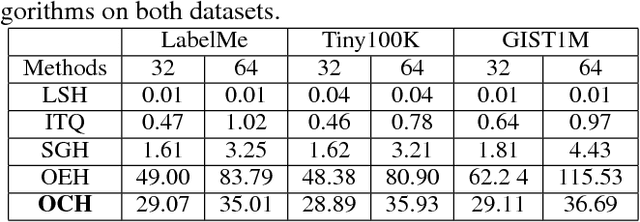
Recent years have witnessed extensive attention in binary code learning, a.k.a. hashing, for nearest neighbor search problems. It has been seen that high-dimensional data points can be quantized into binary codes to give an efficient similarity approximation via Hamming distance. Among existing schemes, ranking-based hashing is recent promising that targets at preserving ordinal relations of ranking in the Hamming space to minimize retrieval loss. However, the size of the ranking tuples, which shows the ordinal relations, is quadratic or cubic to the size of training samples. By given a large-scale training data set, it is very expensive to embed such ranking tuples in binary code learning. Besides, it remains a dificulty to build ranking tuples efficiently for most ranking-preserving hashing, which are deployed over an ordinal graph-based setting. To handle these problems, we propose a novel ranking-preserving hashing method, dubbed Ordinal Constraint Hashing (OCH), which efficiently learns the optimal hashing functions with a graph-based approximation to embed the ordinal relations. The core idea is to reduce the size of ordinal graph with ordinal constraint projection, which preserves the ordinal relations through a small data set (such as clusters or random samples). In particular, to learn such hash functions effectively, we further relax the discrete constraints and design a specific stochastic gradient decent algorithm for optimization. Experimental results on three large-scale visual search benchmark datasets, i.e. LabelMe, Tiny100K and GIST1M, show that the proposed OCH method can achieve superior performance over the state-of-the-arts approaches.
Automatic Script Identification in the Wild
May 12, 2015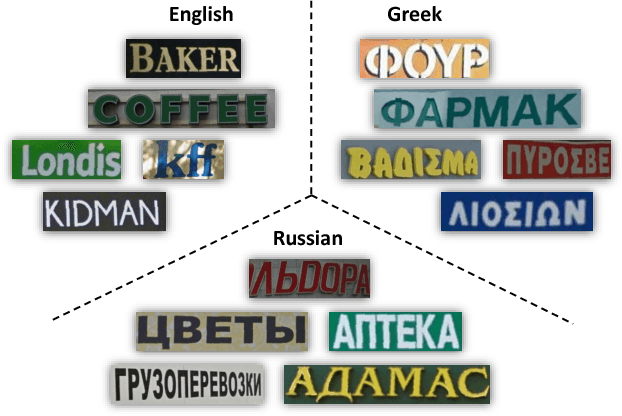


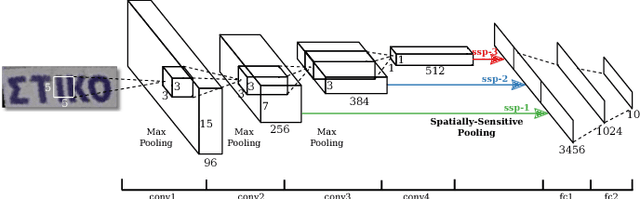
With the rapid increase of transnational communication and cooperation, people frequently encounter multilingual scenarios in various situations. In this paper, we are concerned with a relatively new problem: script identification at word or line levels in natural scenes. A large-scale dataset with a great quantity of natural images and 10 types of widely used languages is constructed and released. In allusion to the challenges in script identification in real-world scenarios, a deep learning based algorithm is proposed. The experiments on the proposed dataset demonstrate that our algorithm achieves superior performance, compared with conventional image classification methods, such as the original CNN architecture and LLC.