 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Compensated, Bias-Corrected Diffusion Weighted Endorectal Magnetic Resonance Imaging via a Stochastically Fully-Connected Joint Conditional Random Field Model
Jul 05, 2016
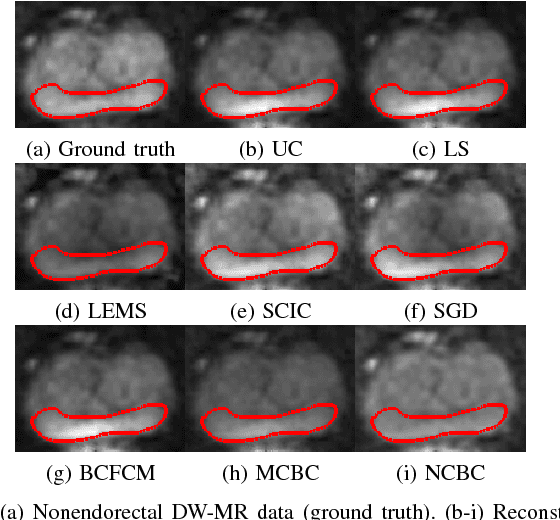
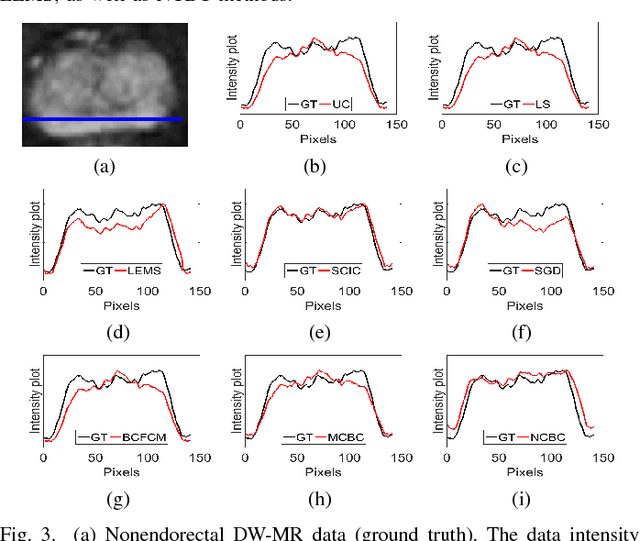
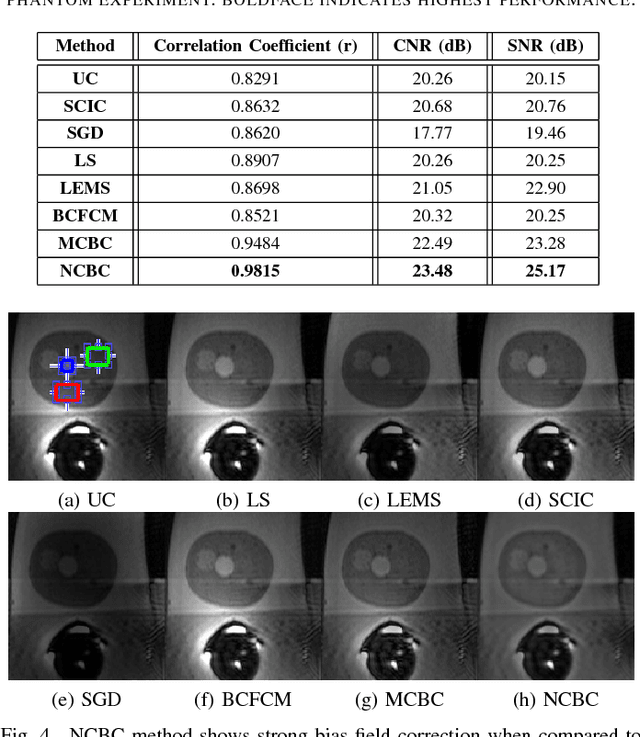
Diffusion weighted magnetic resonance imaging (DW-MR) is a powerful tool in imaging-based prostate cancer screening and detection. Endorectal coils are commonly used in DW-MR imaging to improve the signal-to-noise ratio (SNR) of the acquisition, at the expense of significant intensity inhomogeneities (bias field) that worsens as we move away from the endorectal coil. The presence of bias field can have a significant negative impact on the accuracy of different image analysis tasks, as well as prostate tumor localization, thus leading to increased inter- and intra-observer variability. Retrospective bias correction approaches are introduced as a more efficient way of bias correction compared to the prospective methods such that they correct for both of the scanner and anatomy-related bias fields in MR imaging. Previously proposed retrospective bias field correction methods suffer from undesired noise amplification that can reduce the quality of bias-corrected DW-MR image. Here, we propose a unified data reconstruction approach that enables joint compensation of bias field as well as data noise in DW-MR imaging. The proposed noise-compensated, bias-corrected (NCBC) data reconstruction method takes advantage of a novel stochastically fully connected joint conditional random field (SFC-JCRF) model to mitigate the effects of data noise and bias field in the reconstructed MR data. The proposed NCBC reconstruction method was tested on synthetic DW-MR data, physical DW-phantom as well as real DW-MR data all acquired using endorectal MR coil. Both qualitative and quantitative analysis illustrated that the proposed NCBC method can achieve improved image quality when compared to other tested bias correction methods. As such, the proposed NCBC method may have potential as a useful retrospective approach for improving the consistency of image interpretations.
Sparse Reconstruction of Compressive Sensing MRI using Cross-Domain Stochastically Fully Connected Conditional Random Fields
Dec 25, 2015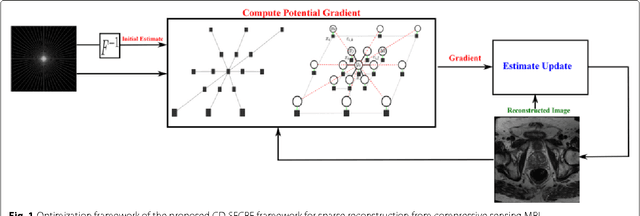



Magnetic Resonance Imaging (MRI) is a crucial medical imaging technology for the screening and diagnosis of frequently occurring cancers. However image quality may suffer by long acquisition times for MRIs due to patient motion, as well as result in great patient discomfort. Reducing MRI acquisition time can reduce patient discomfort and as a result reduces motion artifacts from the acquisition process. Compressive sensing strategies, when applied to MRI, have been demonstrated to be effective at decreasing acquisition times significantly by sparsely sampling the \emph{k}-space during the acquisition process. However, such a strategy requires advanced reconstruction algorithms to produce high quality and reliable images from compressive sensing MRI. This paper proposes a new reconstruction approach based on cross-domain stochastically fully connected conditional random fields (CD-SFCRF) for compressive sensing MRI. The CD-SFCRF introduces constraints in both \emph{k}-space and spatial domains within a stochastically fully connected graphical model to produce improved MRI reconstruction. Experimental results using T2-weighted (T2w) imaging and diffusion-weighted imaging (DWI) of the prostate show strong performance in preserving fine details and tissue structures in the reconstructed images when compared to other tested methods even at low sampling rates.
Discovery Radiomics via StochasticNet Sequencers for Cancer Detection
Nov 11, 2015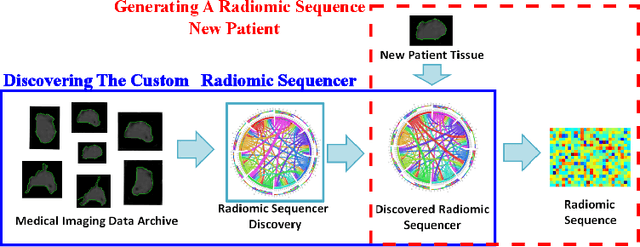
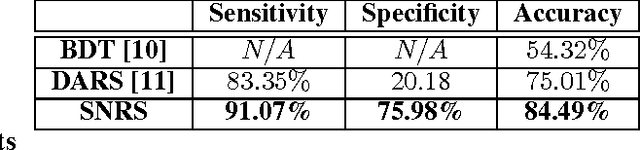
Radiomics has proven to be a powerful prognostic tool for cancer detection, and has previously been applied in lung, breast, prostate, and head-and-neck cancer studies with great success. However, these radiomics-driven methods rely on pre-defined, hand-crafted radiomic feature sets that can limit their ability to characterize unique cancer traits. In this study, we introduce a novel discovery radiomics framework where we directly discover custom radiomic features from the wealth of available medical imaging data. In particular, we leverage novel StochasticNet radiomic sequencers for extracting custom radiomic features tailored for characterizing unique cancer tissue phenotype. Using StochasticNet radiomic sequencers discovered using a wealth of lung CT data, we perform binary classification on 42,340 lung lesions obtained from the CT scans of 93 patients in the LIDC-IDRI dataset. Preliminary results show significant improvement over previous state-of-the-art methods, indicating the potential of the proposed discovery radiomics framework for improving cancer screening and diagnosis.
Discovery Radiomics for Multi-Parametric MRI Prostate Cancer Detection
Oct 20, 2015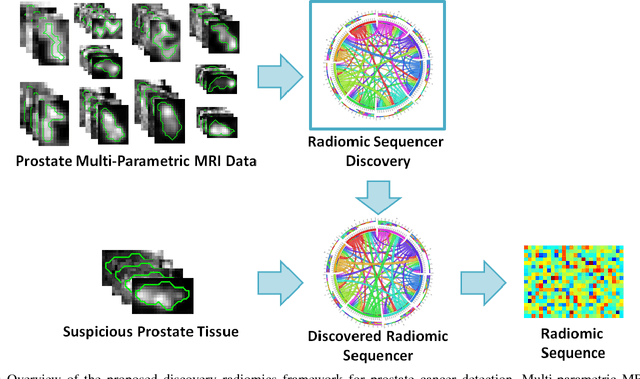
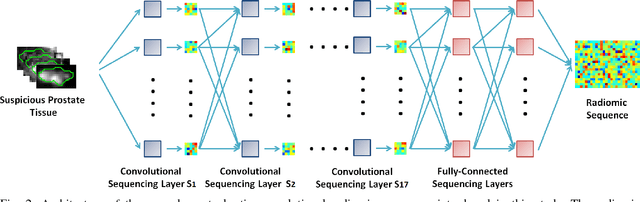
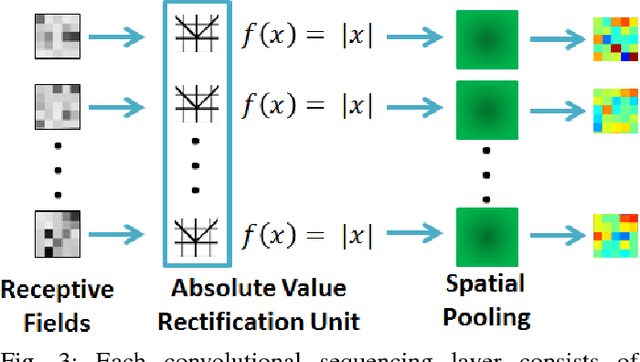

Prostate cancer is the most diagnosed form of cancer in Canadian men, and is the third leading cause of cancer death. Despite these statistics, prognosis is relatively good with a sufficiently early diagnosis, making fast and reliable prostate cancer detection crucial. As imaging-based prostate cancer screening, such as magnetic resonance imaging (MRI), requires an experienced medical professional to extensively review the data and perform a diagnosis, radiomics-driven methods help streamline the process and has the potential to significantly improve diagnostic accuracy and efficiency, and thus improving patient survival rates. These radiomics-driven methods currently rely on hand-crafted sets of quantitative imaging-based features, which are selected manually and can limit their ability to fully characterize unique prostate cancer tumour phenotype. In this study, we propose a novel \textit{discovery radiomics} framework for generating custom radiomic sequences tailored for prostate cancer detection. Discovery radiomics aims to uncover abstract imaging-based features that capture highly unique tumour traits and characteristics beyond what can be captured using predefined feature models. In this paper, we discover new custom radiomic sequencers for generating new prostate radiomic sequences using multi-parametric MRI data. We evaluated the performance of the discovered radiomic sequencer against a state-of-the-art hand-crafted radiomic sequencer for computer-aided prostate cancer detection with a feedforward neural network using real clinical prostate multi-parametric MRI data. Results for the discovered radiomic sequencer demonstrate good performance in prostate cancer detection and clinical decision support relative to the hand-crafted radiomic sequencer. The use of discovery radiomics shows potential for more efficient and reliable automatic prostate cancer detection.
Medical Image Classification via SVM using LBP Features from Saliency-Based Folded Data
Sep 15, 2015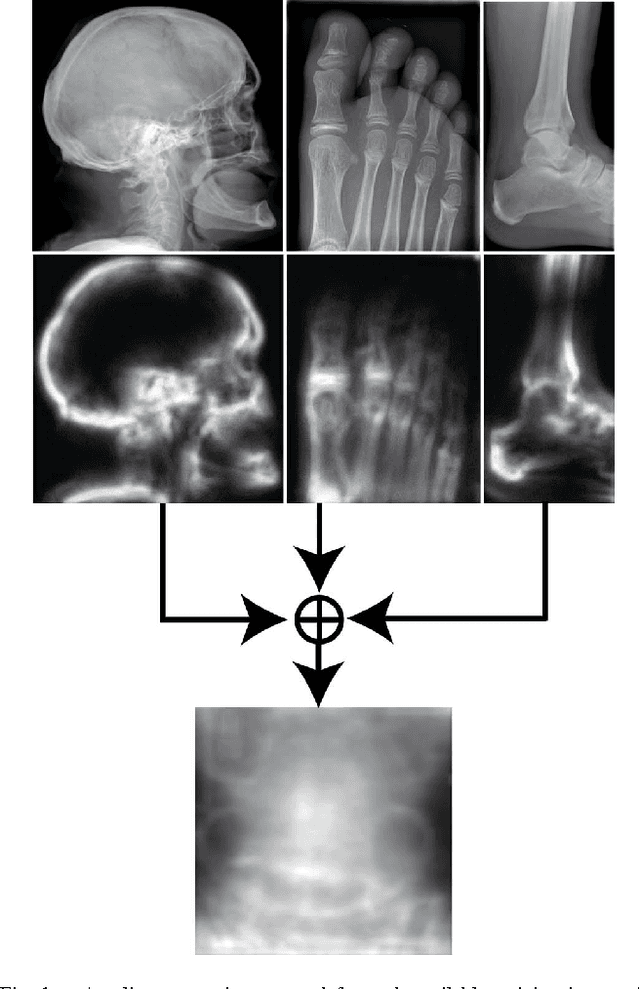
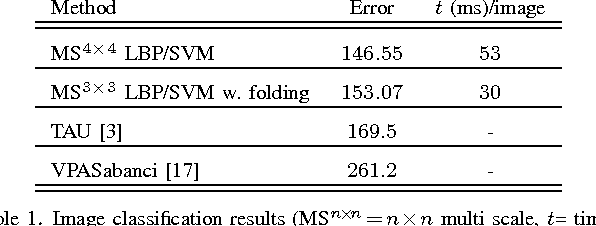
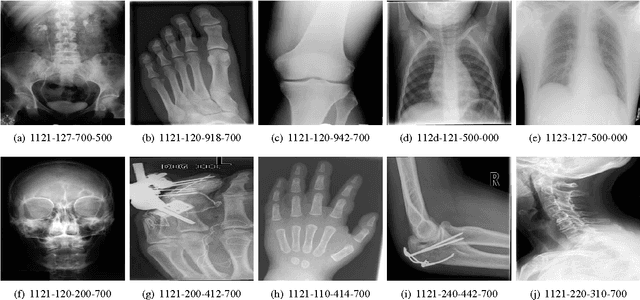
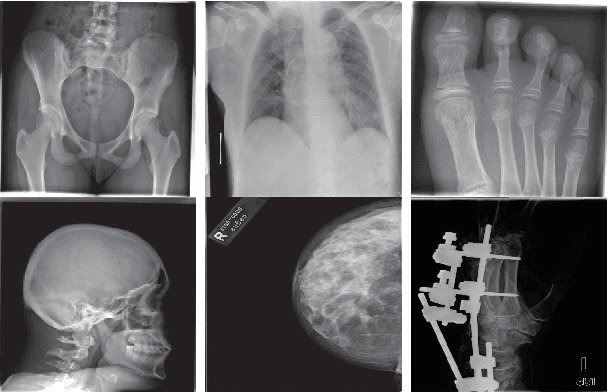
Good results on image classification and retrieval using support vector machines (SVM) with local binary patterns (LBPs) as features have been extensively reported in the literature where an entire image is retrieved or classified. In contrast, in medical imaging, not all parts of the image may be equally significant or relevant to the image retrieval application at hand. For instance, in lung x-ray image, the lung region may contain a tumour, hence being highly significant whereas the surrounding area does not contain significant information from medical diagnosis perspective. In this paper, we propose to detect salient regions of images during training and fold the data to reduce the effect of irrelevant regions. As a result, smaller image areas will be used for LBP features calculation and consequently classification by SVM. We use IRMA 2009 dataset with 14,410 x-ray images to verify the performance of the proposed approach. The results demonstrate the benefits of saliency-based folding approach that delivers comparable classification accuracies with state-of-the-art but exhibits lower computational cost and storage requirements, factors highly important for big data analytics.
Autoencoding the Retrieval Relevance of Medical Images
Jul 05, 2015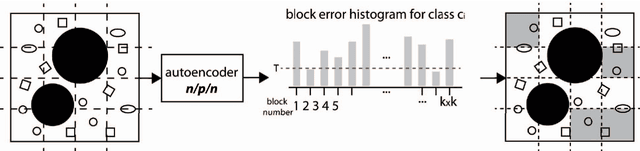
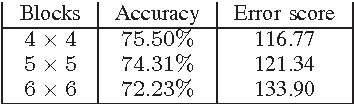
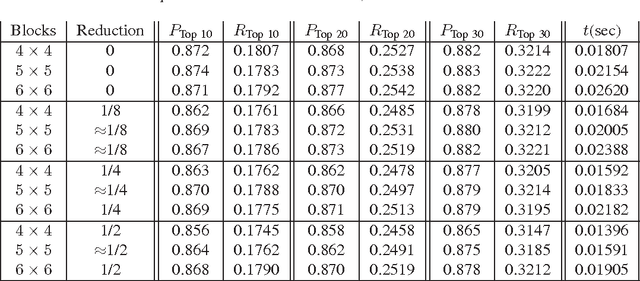
Content-based image retrieval (CBIR) of medical images is a crucial task that can contribute to a more reliable diagnosis if applied to big data. Recent advances in feature extraction and classification have enormously improved CBIR results for digital images. However, considering the increasing accessibility of big data in medical imaging, we are still in need of reducing both memory requirements and computational expenses of image retrieval systems. This work proposes to exclude the features of image blocks that exhibit a low encoding error when learned by a $n/p/n$ autoencoder ($p\!<\!n$). We examine the histogram of autoendcoding errors of image blocks for each image class to facilitate the decision which image regions, or roughly what percentage of an image perhaps, shall be declared relevant for the retrieval task. This leads to reduction of feature dimensionality and speeds up the retrieval process. To validate the proposed scheme, we employ local binary patterns (LBP) and support vector machines (SVM) which are both well-established approaches in CBIR research community. As well, we use IRMA dataset with 14,410 x-ray images as test data. The results show that the dimensionality of annotated feature vectors can be reduced by up to 50% resulting in speedups greater than 27% at expense of less than 1% decrease in the accuracy of retrieval when validating the precision and recall of the top 20 hits.
Evolving Fuzzy Image Segmentation with Self-Configuration
Apr 23, 2015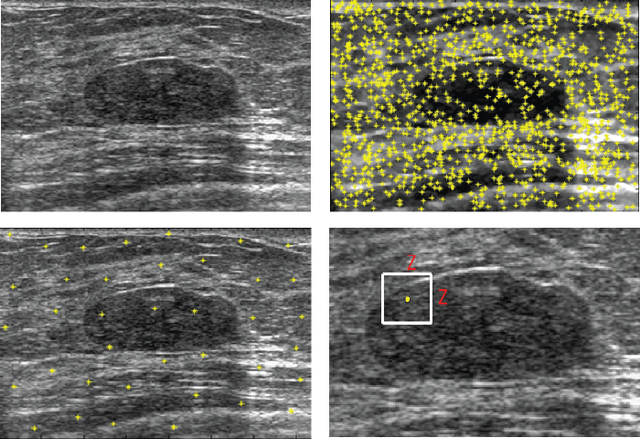

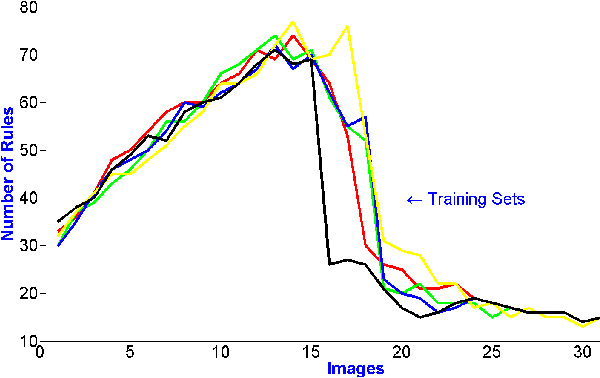
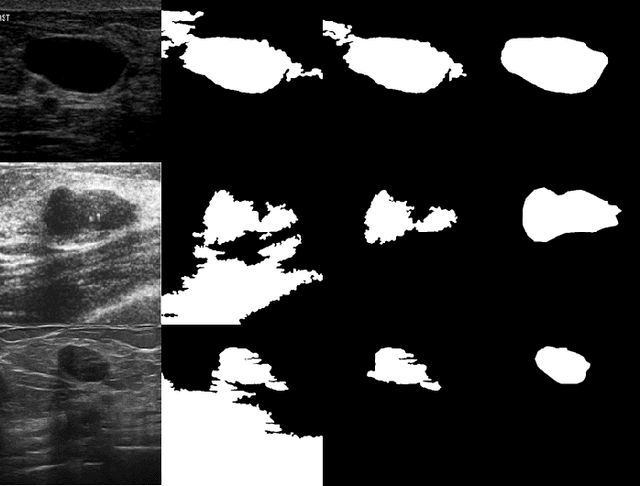
Current image segmentation techniques usually require that the user tune several parameters in order to obtain maximum segmentation accuracy, a computationally inefficient approach, especially when a large number of images must be processed sequentially in daily practice. The use of evolving fuzzy systems for designing a method that automatically adjusts parameters to segment medical images according to the quality expectation of expert users has been proposed recently (Evolving fuzzy image segmentation EFIS). However, EFIS suffers from a few limitations when used in practice mainly due to some fixed parameters. For instance, EFIS depends on auto-detection of the object of interest for feature calculation, a task that is highly application-dependent. This shortcoming limits the applicability of EFIS, which was proposed with the ultimate goal of offering a generic but adjustable segmentation scheme. In this paper, a new version of EFIS is proposed to overcome these limitations. The new EFIS, called self-configuring EFIS (SC-EFIS), uses available training data to self-estimate the parameters that are fixed in EFIS. As well, the proposed SC-EFIS relies on a feature selection process that does not require auto-detection of an ROI. The proposed SC-EFIS was evaluated using the same segmentation algorithms and the same dataset as for EFIS. The results show that SC-EFIS can provide the same results as EFIS but with a higher level of automation.