 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Face Identification Network Enhanced by Facial Attributes Prediction
Apr 20, 2018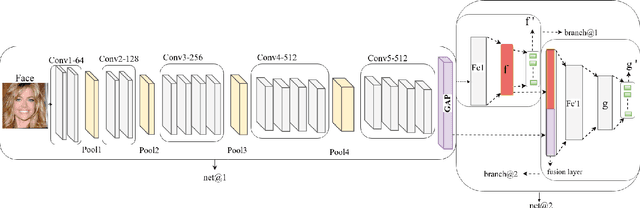
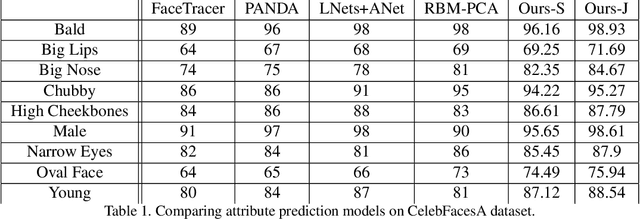

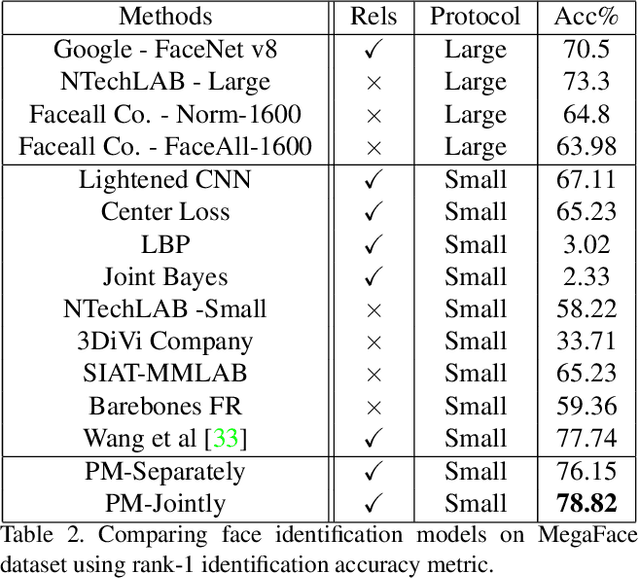
In this paper, we propose a new deep framework which predicts facial attributes and leverage it as a soft modality to improve face identification performance. Our model is an end to end framework which consists of a convolutional neural network (CNN) whose output is fanned out into two separate branches; the first branch predicts facial attributes while the second branch identifies face images. Contrary to the existing multi-task methods which only use a shared CNN feature space to train these two tasks jointly, we fuse the predicted attributes with the features from the face modality in order to improve the face identification performance. Experimental results show that our model brings benefits to both face identification as well as facial attribute prediction performance, especially in the case of identity facial attributes such as gender prediction. We tested our model on two standard datasets annotated by identities and face attributes. Experimental results indicate that the proposed model outperforms most of the current existing face identification and attribute prediction methods.
Blood capillaries and vessels segmentation in optical coherence tomography angiogram using fuzzy C-means and Curvelet transform
May 31, 2017This paper has been removed from arXiv as the submitter did not have ownership of the data presented in this work.
An ensemble learning method for scene classification based on Hidden Markov Model image representation
Oct 05, 2016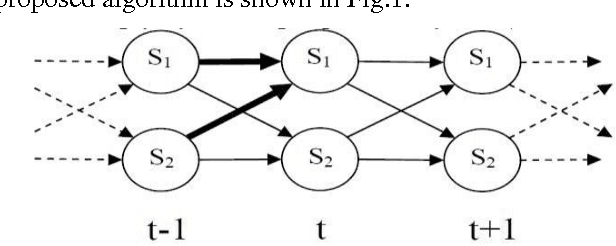
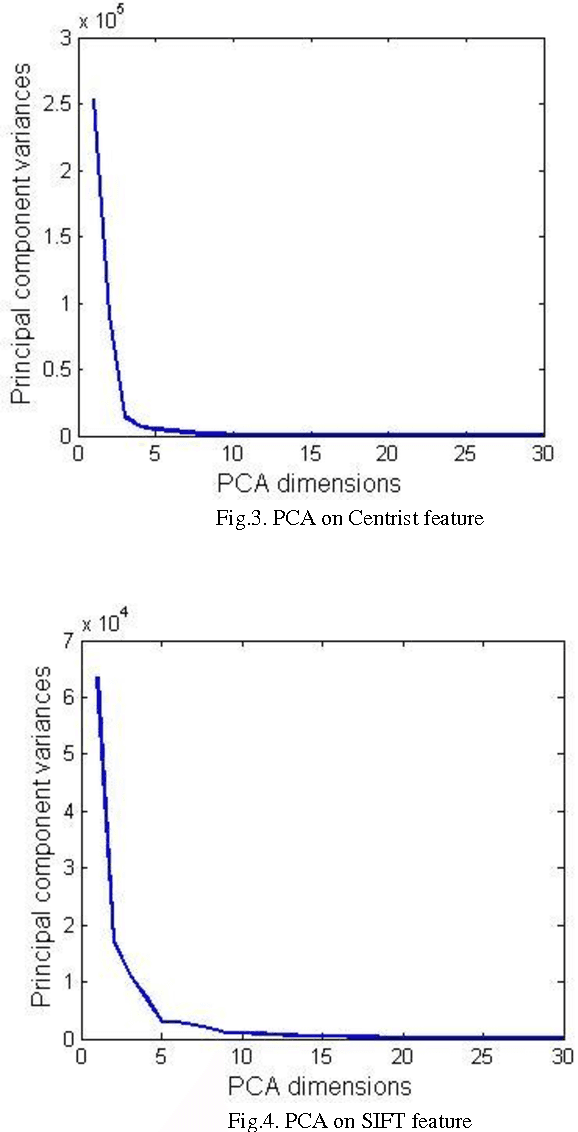
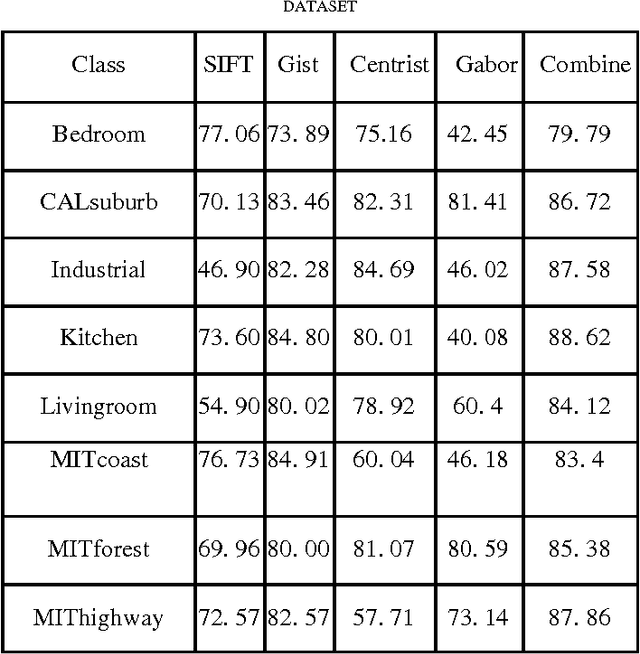
Low level images representation in feature space performs poorly for classification with high accuracy since this level of representation is not able to project images into the discriminative feature space. In this work, we propose an efficient image representation model for classification. First we apply Hidden Markov Model (HMM) on ordered grids represented by different type of image descriptors in order to include causality of local properties existing in image for feature extraction and then we train up a separate classifier for each of these features sets. Finally we ensemble these classifiers efficiently in a way that they can cancel out each other errors for obtaining higher accuracy. This method is evaluated on 15 natural scene dataset. Experimental results show the superiority of the proposed method in comparison to some current existing methods
A probabilistic patch based image representation using Conditional Random Field model for image classification
Oct 05, 2016In this paper we proposed an ordered patch based method using Conditional Random Field (CRF) in order to encode local properties and their spatial relationship in images to address texture classification, face recognition, and scene classification problems. Typical image classification approaches work without considering spatial causality among distinctive properties of an image for image representation in feature space. In this method first, each image is encoded as a sequence of ordered patches, including local properties. Second, the sequence of these ordered patches is modeled as a probabilistic feature vector by CRF to model spatial relationship of these local properties. And finally, image classification is performed on such probabilistic image representation. Experimental results on several standard image datasets indicate that proposed method outperforms some of existing image classification methods.