 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError-Corrected Margin-Based Deep Cross-Modal Hashing for Facial Image Retrieval
Apr 03, 2020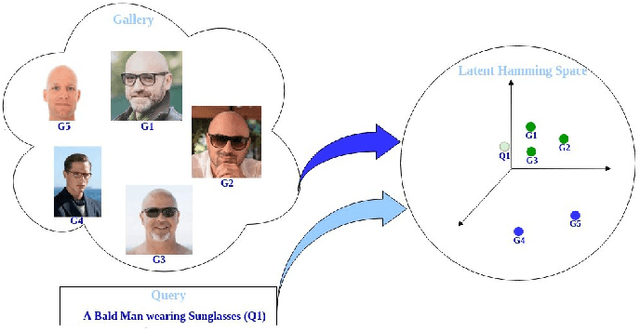
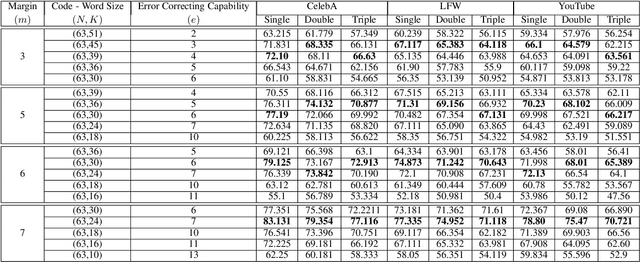
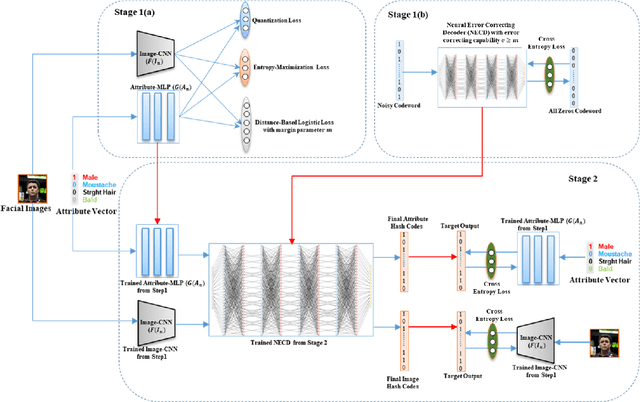
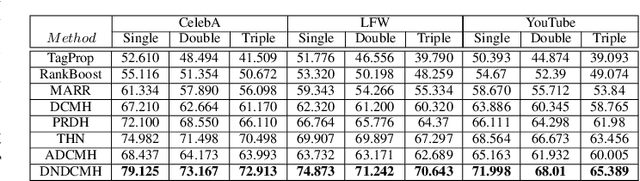
Cross-modal hashing facilitates mapping of heterogeneous multimedia data into a common Hamming space, which can beutilized for fast and flexible retrieval across different modalities. In this paper, we propose a novel cross-modal hashingarchitecture-deep neural decoder cross-modal hashing (DNDCMH), which uses a binary vector specifying the presence of certainfacial attributes as an input query to retrieve relevant face images from a database. The DNDCMH network consists of two separatecomponents: an attribute-based deep cross-modal hashing (ADCMH) module, which uses a margin (m)-based loss function toefficiently learn compact binary codes to preserve similarity between modalities in the Hamming space, and a neural error correctingdecoder (NECD), which is an error correcting decoder implemented with a neural network. The goal of NECD network in DNDCMH isto error correct the hash codes generated by ADCMH to improve the retrieval efficiency. The NECD network is trained such that it hasan error correcting capability greater than or equal to the margin (m) of the margin-based loss function. This results in NECD cancorrect the corrupted hash codes generated by ADCMH up to the Hamming distance of m. We have evaluated and comparedDNDCMH with state-of-the-art cross-modal hashing methods on standard datasets to demonstrate the superiority of our method.
SuperMix: Supervising the Mixing Data Augmentation
Mar 10, 2020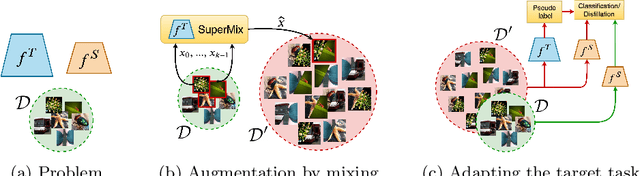
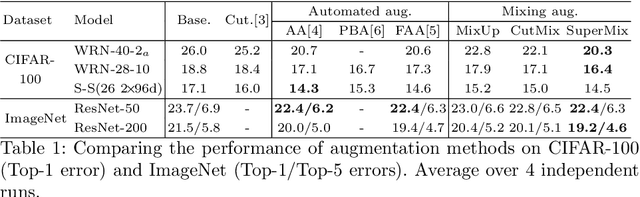
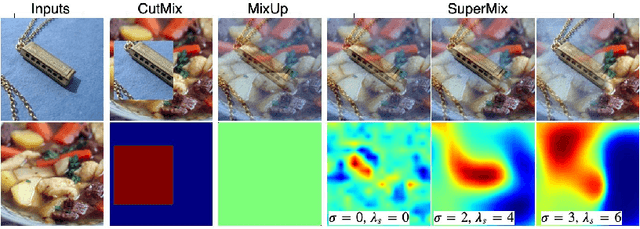
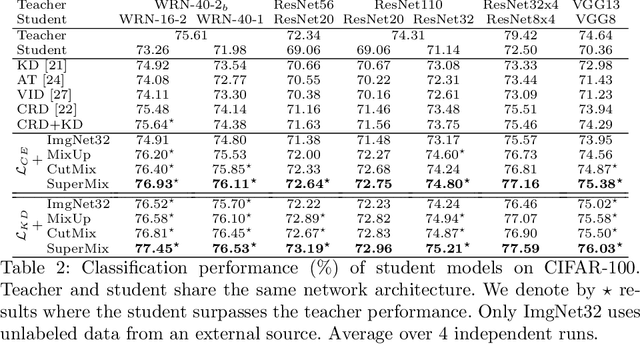
In this paper, we propose a supervised mixing augmentation method, termed SuperMix, which exploits the knowledge of a teacher to mix images based on their salient regions. SuperMix optimizes a mixing objective that considers: i) forcing the class of input images to appear in the mixed image, ii) preserving the local structure of images, and iii) reducing the risk of suppressing important features. To make the mixing suitable for large-scale applications, we develop an optimization technique, $65\times$ faster than gradient descent on the same problem. We validate the effectiveness of SuperMix through extensive evaluations and ablation studies on two tasks of object classification and knowledge distillation. On the classification task, SuperMix provides the same performance as the advanced augmentation methods, such as AutoAugment. On the distillation task, SuperMix sets a new state-of-the-art with a significantly simplified distillation method. Particularly, in six out of eight teacher-student setups from the same architectures, the students trained on the mixed data surpass their teachers with a notable margin.
Boosting Deep Face Recognition via Disentangling Appearance and Geometry
Jan 13, 2020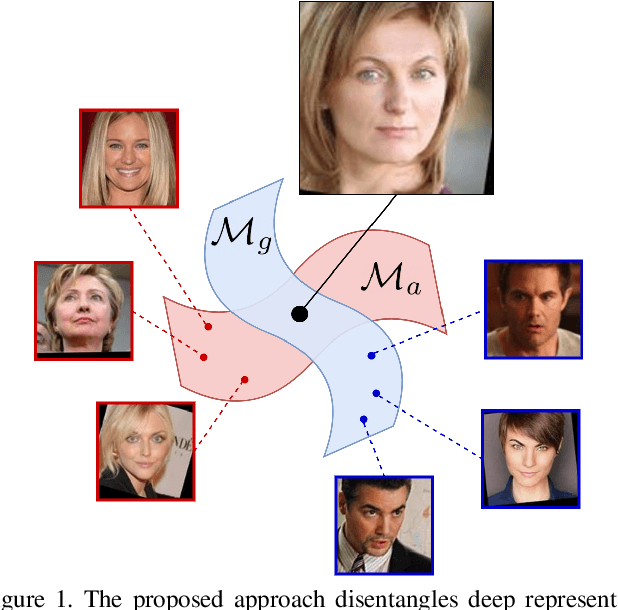
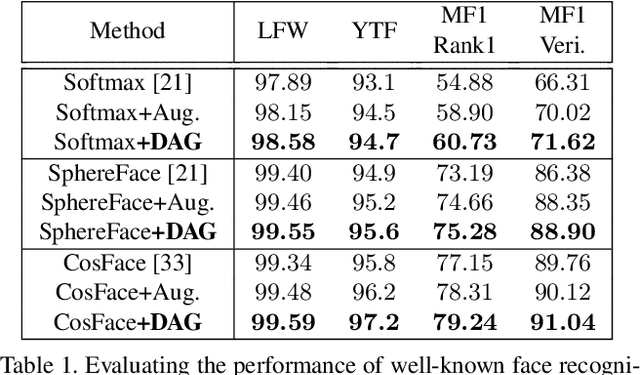

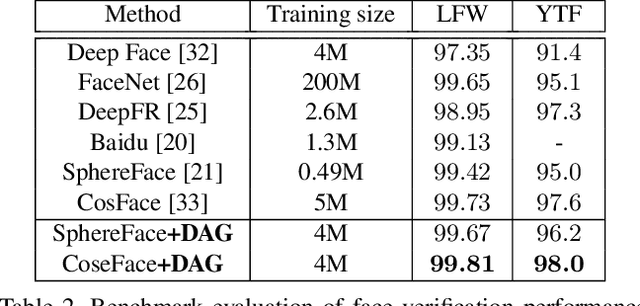
In this paper, we propose a framework for disentangling the appearance and geometry representations in the face recognition task. To provide supervision for this aim, we generate geometrically identical faces by incorporating spatial transformations. We demonstrate that the proposed approach enhances the performance of deep face recognition models by assisting the training process in two ways. First, it enforces the early and intermediate convolutional layers to learn more representative features that satisfy the properties of disentangled embeddings. Second, it augments the training set by altering faces geometrically. Through extensive experiments, we demonstrate that integrating the proposed approach into state-of-the-art face recognition methods effectively improves their performance on challenging datasets, such as LFW, YTF, and MegaFace. Both theoretical and practical aspects of the method are analyzed rigorously by concerning ablation studies and knowledge transfer tasks. Furthermore, we show that the knowledge leaned by the proposed method can favor other face-related tasks, such as attribute prediction.
SmoothFool: An Efficient Framework for Computing Smooth Adversarial Perturbations
Oct 08, 2019
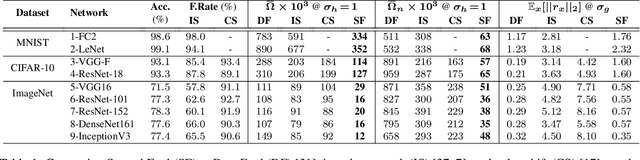
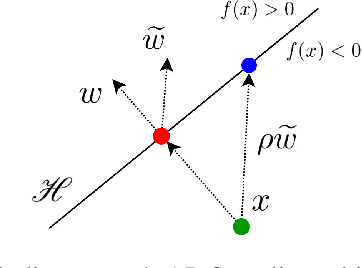
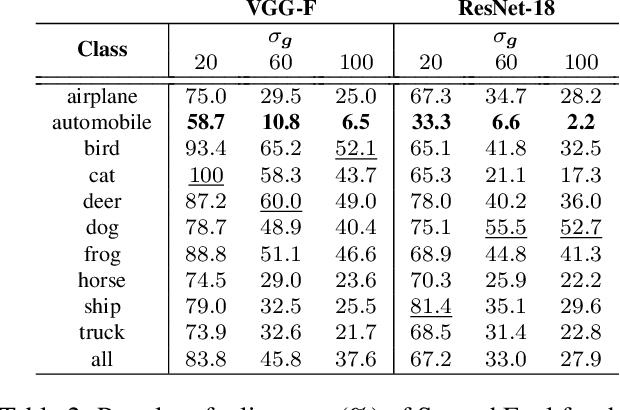
Deep neural networks are susceptible to adversarial manipulations in the input domain. The extent of vulnerability has been explored intensively in cases of $\ell_p$-bounded and $\ell_p$-minimal adversarial perturbations. However, the vulnerability of DNNs to adversarial perturbations with specific statistical properties or frequency-domain characteristics has not been sufficiently explored. In this paper, we study the smoothness of perturbations and propose SmoothFool, a general and computationally efficient framework for computing smooth adversarial perturbations. Through extensive experiments, we validate the efficacy of the proposed method for both the white-box and black-box attack scenarios. In particular, we demonstrate that: (i) there exist extremely smooth adversarial perturbations for well-established and widely used network architectures, (ii) smoothness significantly enhances the robustness of perturbations against state-of-the-art defense mechanisms, (iii) smoothness improves the transferability of adversarial perturbations across both data points and network architectures, and (iv) class categories exhibit a variable range of susceptibility to smooth perturbations. Our results suggest that smooth APs can play a significant role in exploring the vulnerability extent of DNNs to adversarial examples.
Identity-Aware Deep Face Hallucination via Adversarial Face Verification
Sep 17, 2019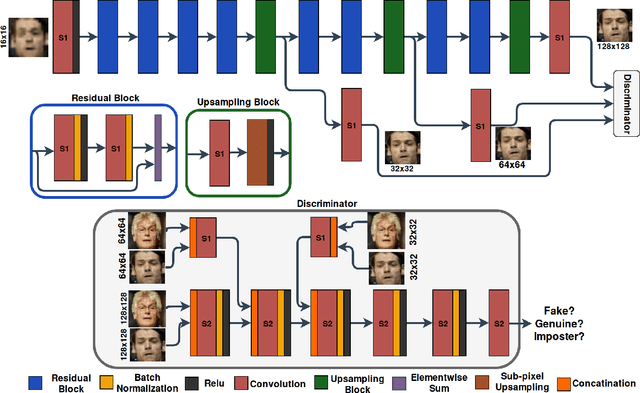
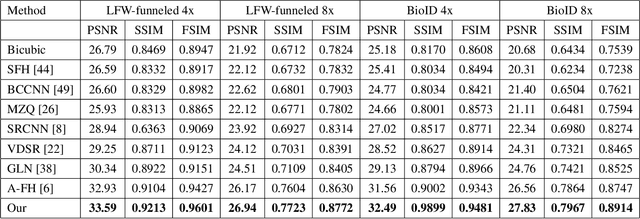

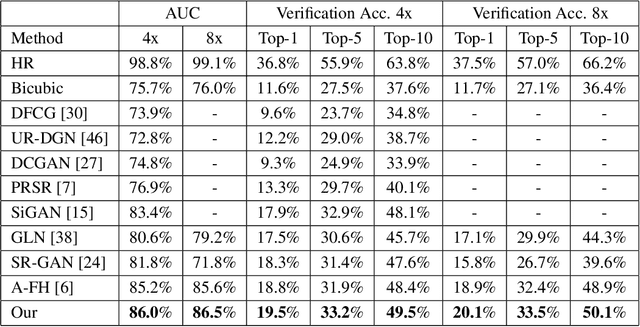
In this paper, we address the problem of face hallucination by proposing a novel multi-scale generative adversarial network (GAN) architecture optimized for face verification. First, we propose a multi-scale generator architecture for face hallucination with a high up-scaling ratio factor, which has multiple intermediate outputs at different resolutions. The intermediate outputs have the growing goal of synthesizing small to large images. Second, we incorporate a face verifier with the original GAN discriminator and propose a novel discriminator which learns to discriminate different identities while distinguishing fake generated HR face images from their ground truth images. In particular, the learned generator cares for not only the visual quality of hallucinated face images but also preserving the discriminative features in the hallucination process. In addition, to capture perceptually relevant differences we employ a perceptual similarity loss, instead of similarity in pixel space. We perform a quantitative and qualitative evaluation of our framework on the LFW and CelebA datasets. The experimental results show the advantages of our proposed method against the state-of-the-art methods on the 8x downsampled testing dataset.
Deep Sparse Band Selection for Hyperspectral Face Recognition
Aug 15, 2019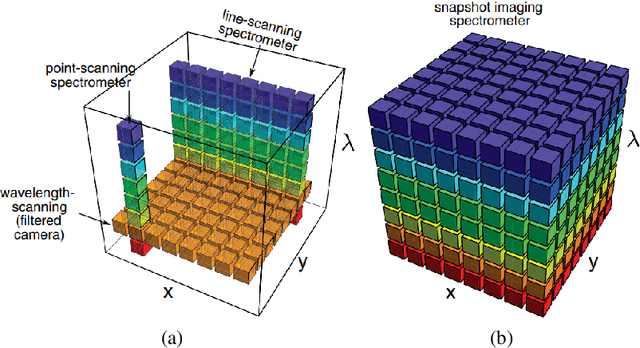


Hyperspectral imaging systems collect and process information from specific wavelengths across the electromagnetic spectrum. The fusion of multi-spectral bands in the visible spectrum has been exploited to improve face recognition performance over all the conventional broad band face images. In this book chapter, we propose a new Convolutional Neural Network (CNN) framework which adopts a structural sparsity learning technique to select the optimal spectral bands to obtain the best face recognition performance over all of the spectral bands. Specifically, in this method, images from all bands are fed to a CNN, and the convolutional filters in the first layer of the CNN are then regularized by employing a group Lasso algorithm to zero out the redundant bands during the training of the network. Contrary to other methods which usually select the useful bands manually or in a greedy fashion, our method selects the optimal spectral bands automatically to achieve the best face recognition performance over all spectral bands. Moreover, experimental results demonstrate that our method outperforms state of the art band selection methods for face recognition on several publicly-available hyperspectral face image datasets.
Attribute-Guided Coupled GAN for Cross-Resolution Face Recognition
Aug 05, 2019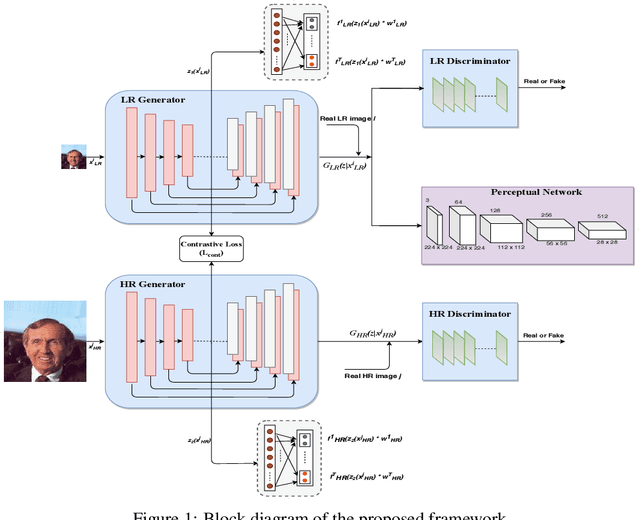
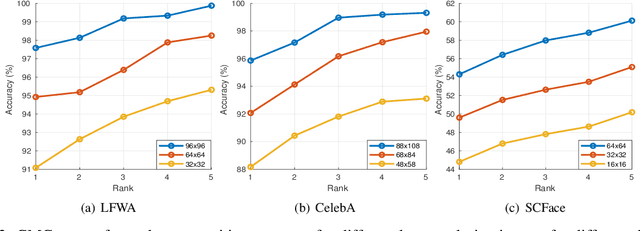

In this paper, we propose a novel attribute-guided cross-resolution (low-resolution to high-resolution) face recognition framework that leverages a coupled generative adversarial network (GAN) structure with adversarial training to find the hidden relationship between the low-resolution and high-resolution images in a latent common embedding subspace. The coupled GAN framework consists of two sub-networks, one dedicated to the low-resolution domain and the other dedicated to the high-resolution domain. Each sub-network aims to find a projection that maximizes the pair-wise correlation between the two feature domains in a common embedding subspace. In addition to projecting the images into a common subspace, the coupled network also predicts facial attributes to improve the cross-resolution face recognition. Specifically, our proposed coupled framework exploits facial attributes to further maximize the pair-wise correlation by implicitly matching facial attributes of the low and high-resolution images during the training, which leads to a more discriminative embedding subspace resulting in performance enhancement for cross-resolution face recognition. The efficacy of our approach compared with the state-of-the-art is demonstrated using the LFWA, Celeb-A, SCFace and UCCS datasets.
Using Deep Cross Modal Hashing and Error Correcting Codes for Improving the Efficiency of Attribute Guided Facial Image Retrieval
Feb 11, 2019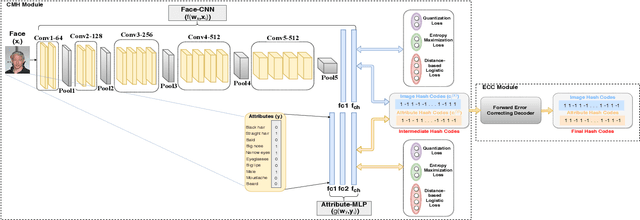

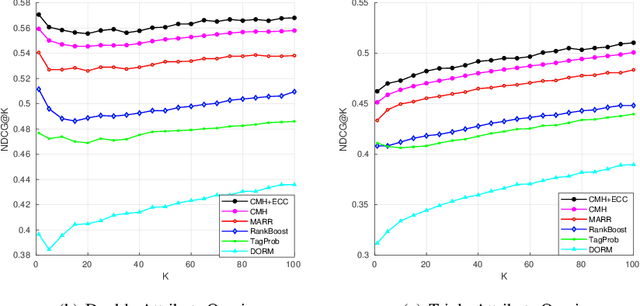
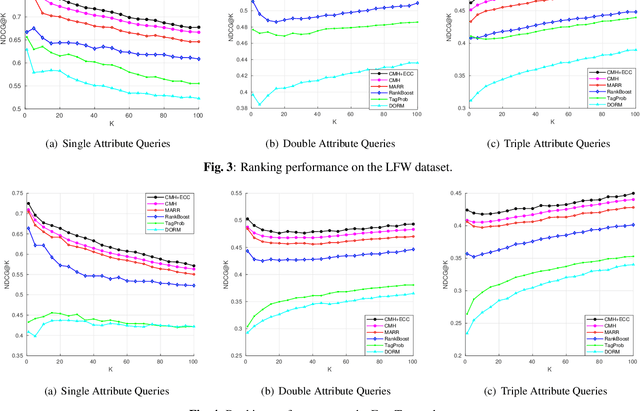
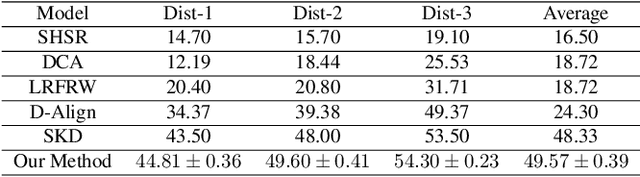
With benefits of fast query speed and low storage cost, hashing-based image retrieval approaches have garnered considerable attention from the research community. In this paper, we propose a novel Error-Corrected Deep Cross Modal Hashing (CMH-ECC) method which uses a bitmap specifying the presence of certain facial attributes as an input query to retrieve relevant face images from the database. In this architecture, we generate compact hash codes using an end-to-end deep learning module, which effectively captures the inherent relationships between the face and attribute modality. We also integrate our deep learning module with forward error correction codes to further reduce the distance between different modalities of the same subject. Specifically, the properties of deep hashing and forward error correction codes are exploited to design a cross modal hashing framework with high retrieval performance. Experimental results using two standard datasets with facial attributes-image modalities indicate that our CMH-ECC face image retrieval model outperforms most of the current attribute-based face image retrieval approaches.
Unsupervised Image-to-Image Translation Using Domain-Specific Variational Information Bound
Nov 29, 2018
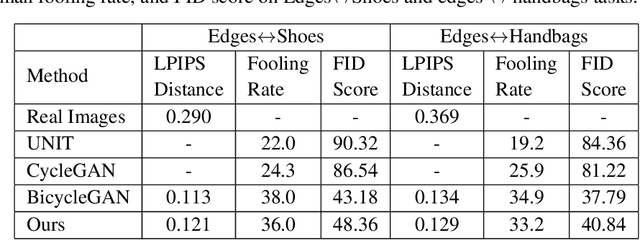
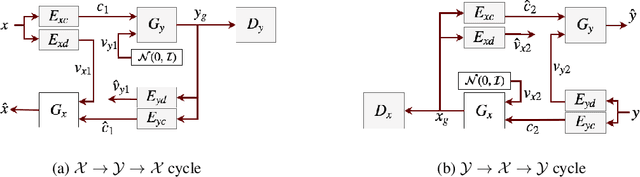
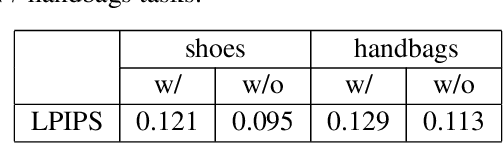
Unsupervised image-to-image translation is a class of computer vision problems which aims at modeling conditional distribution of images in the target domain, given a set of unpaired images in the source and target domains. An image in the source domain might have multiple representations in the target domain. Therefore, ambiguity in modeling of the conditional distribution arises, specially when the images in the source and target domains come from different modalities. Current approaches mostly rely on simplifying assumptions to map both domains into a shared-latent space. Consequently, they are only able to model the domain-invariant information between the two modalities. These approaches usually fail to model domain-specific information which has no representation in the target domain. In this work, we propose an unsupervised image-to-image translation framework which maximizes a domain-specific variational information bound and learns the target domain-invariant representation of the two domain. The proposed framework makes it possible to map a single source image into multiple images in the target domain, utilizing several target domain-specific codes sampled randomly from the prior distribution, or extracted from reference images.
Unsupervised Facial Geometry Learning for Sketch to Photo Synthesis
Oct 12, 2018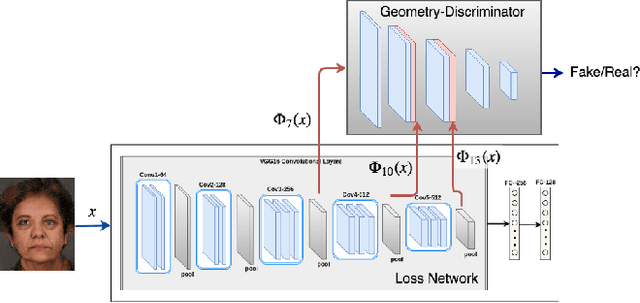
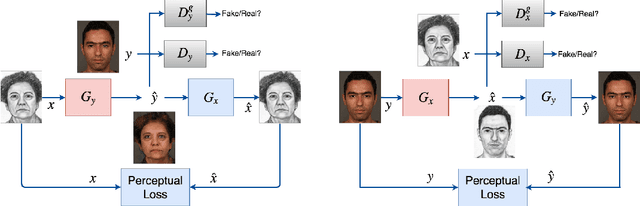

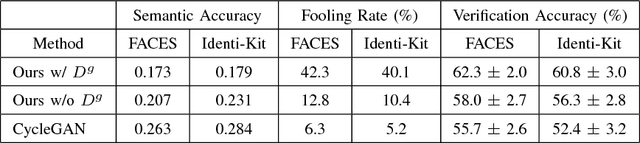
Face sketch-photo synthesis is a critical application in law enforcement and digital entertainment industry where the goal is to learn the mapping between a face sketch image and its corresponding photo-realistic image. However, the limited number of paired sketch-photo training data usually prevents the current frameworks to learn a robust mapping between the geometry of sketches and their matching photo-realistic images. Consequently, in this work, we present an approach for learning to synthesize a photo-realistic image from a face sketch in an unsupervised fashion. In contrast to current unsupervised image-to-image translation techniques, our framework leverages a novel perceptual discriminator to learn the geometry of human face. Learning facial prior information empowers the network to remove the geometrical artifacts in the face sketch. We demonstrate that a simultaneous optimization of the face photo generator network, employing the proposed perceptual discriminator in combination with a texture-wise discriminator, results in a significant improvement in quality and recognition rate of the synthesized photos. We evaluate the proposed network by conducting extensive experiments on multiple baseline sketch-photo datasets.