 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmily Dinan
Generating Interactive Worlds with Text
Nov 20, 2019
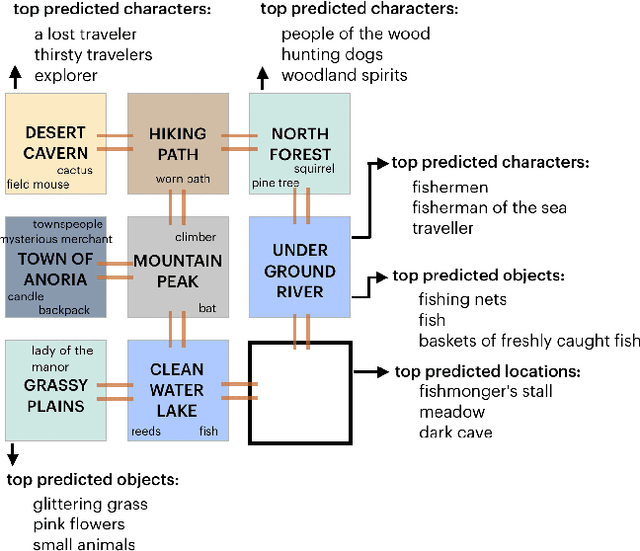
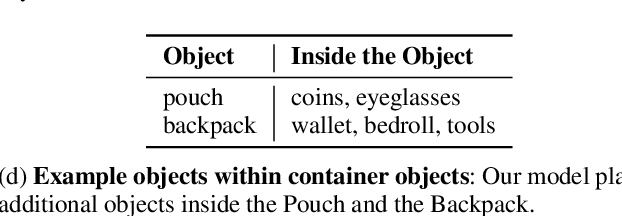
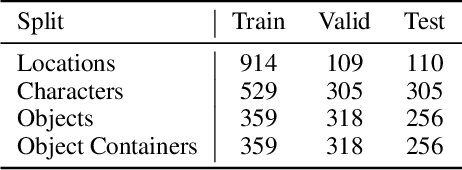
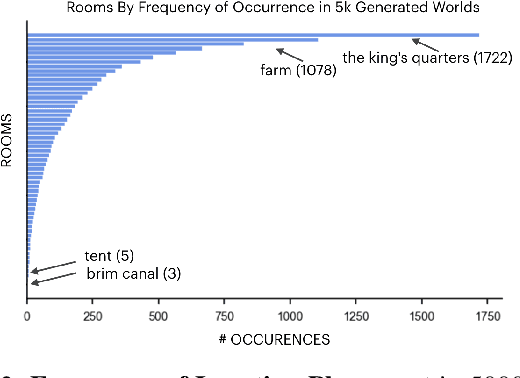
Procedurally generating cohesive and interesting game environments is challenging and time-consuming. In order for the relationships between the game elements to be natural, common-sense has to be encoded into arrangement of the elements. In this work, we investigate a machine learning approach for world creation using content from the multi-player text adventure game environment LIGHT. We introduce neural network based models to compositionally arrange locations, characters, and objects into a coherent whole. In addition to creating worlds based on existing elements, our models can generate new game content. Humans can also leverage our models to interactively aid in worldbuilding. We show that the game environments created with our approach are cohesive, diverse, and preferred by human evaluators compared to other machine learning based world construction algorithms.
Zero-Shot Fine-Grained Style Transfer: Leveraging Distributed Continuous Style Representations to Transfer To Unseen Styles
Nov 10, 2019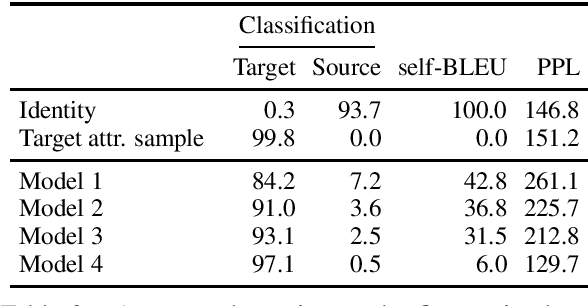

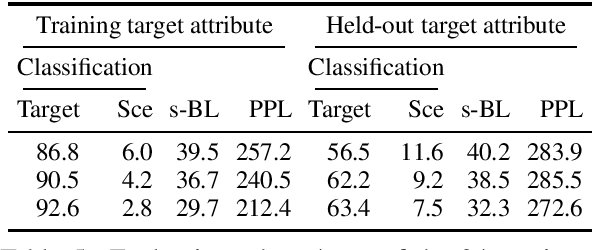

Text style transfer is usually performed using attributes that can take a handful of discrete values (e.g., positive to negative reviews). In this work, we introduce an architecture that can leverage pre-trained consistent continuous distributed style representations and use them to transfer to an attribute unseen during training, without requiring any re-tuning of the style transfer model. We demonstrate the method by training an architecture to transfer text conveying one sentiment to another sentiment, using a fine-grained set of over 20 sentiment labels rather than the binary positive/negative often used in style transfer. Our experiments show that this model can then rewrite text to match a target sentiment that was unseen during training.
Queens are Powerful too: Mitigating Gender Bias in Dialogue Generation
Nov 10, 2019
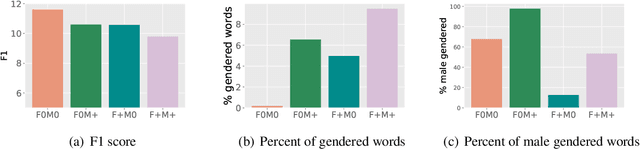
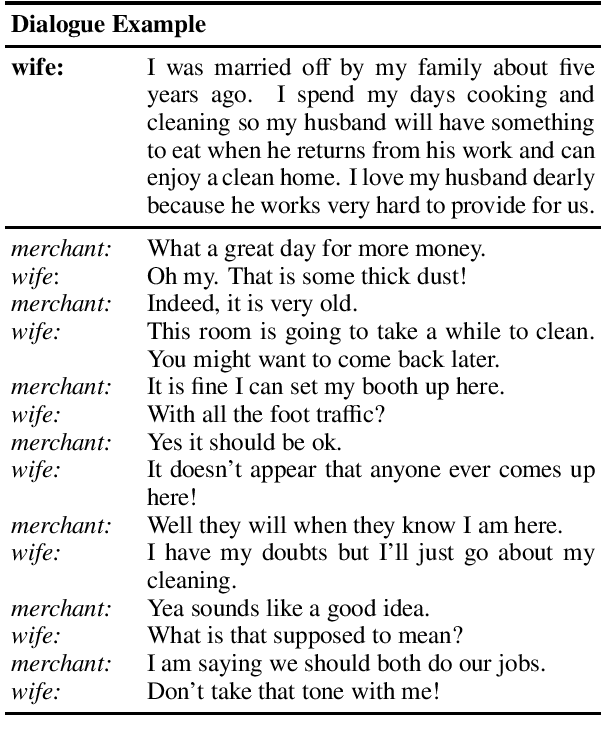
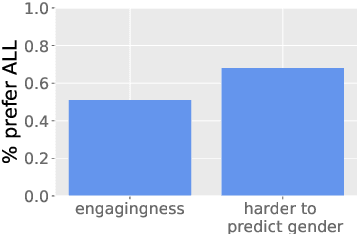
Models often easily learn biases present in the training data, and their predictions directly reflect this bias. We analyze the presence of gender bias in dialogue and examine the subsequent effect on generative chitchat dialogue models. Based on this analysis, we propose a combination of three techniques to mitigate bias: counterfactual data augmentation, targeted data collection, and conditional training. We focus on the multi-player text-based fantasy adventure dataset LIGHT as a testbed for our work. LIGHT contains gender imbalance between male and female characters with around 1.6 times as many male characters, likely because it is entirely collected by crowdworkers and reflects common biases that exist in fantasy or medieval settings. We show that (i) our proposed techniques mitigate gender bias by balancing the genderedness of generated dialogue utterances; and (ii) they work particularly well in combination. Further, we show through various metrics---such as quantity of gendered words, a dialogue safety classifier, and human evaluation---that our models generate less gendered, but still engaging chitchat responses.
The Dialogue Dodecathlon: Open-Domain Knowledge and Image Grounded Conversational Agents
Nov 09, 2019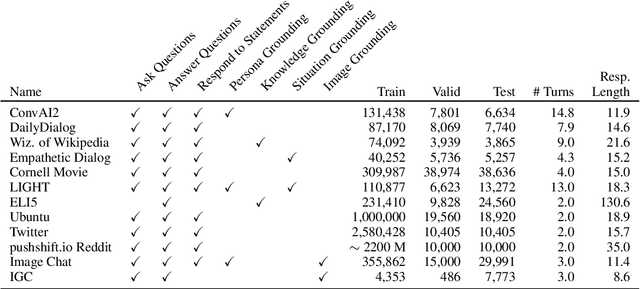
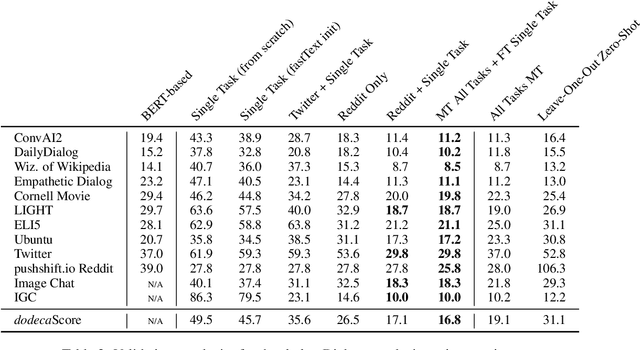
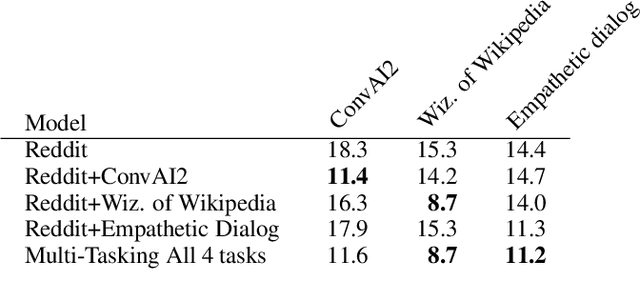

We introduce dodecaDialogue: a set of 12 tasks that measures if a conversational agent can communicate engagingly with personality and empathy, ask questions, answer questions by utilizing knowledge resources, discuss topics and situations, and perceive and converse about images. By multi-tasking on such a broad large-scale set of data, we hope to both move towards and measure progress in producing a single unified agent that can perceive, reason and converse with humans in an open-domain setting. We show that such multi-tasking improves over a BERT pre-trained baseline, largely due to multi-tasking with very large dialogue datasets in a similar domain, and that the multi-tasking in general provides gains to both text and image-based tasks using several metrics in both the fine-tune and task transfer settings. We obtain state-of-the-art results on many of the tasks, providing a strong baseline for this challenge.
Adversarial NLI: A New Benchmark for Natural Language Understanding
Oct 31, 2019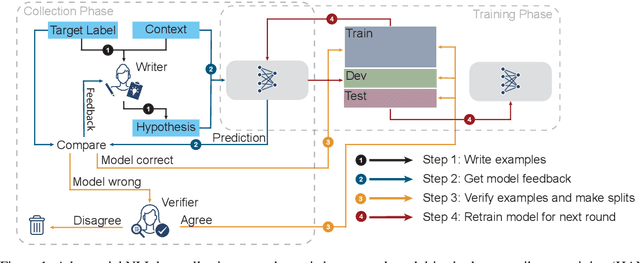
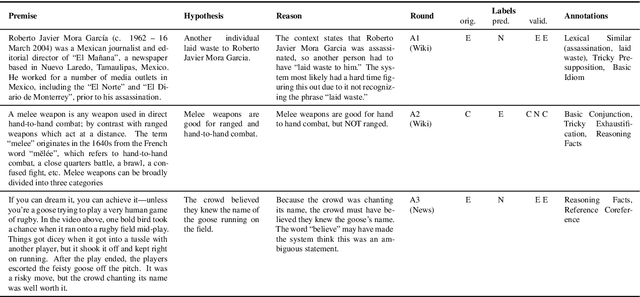
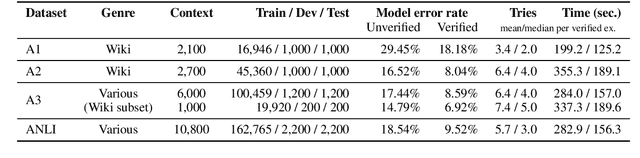
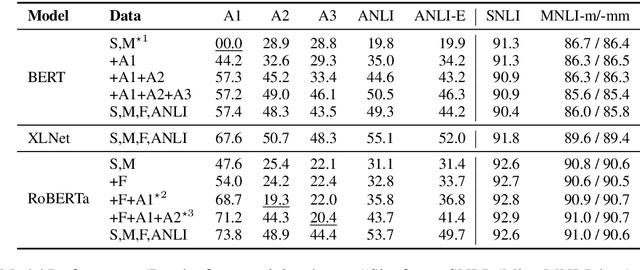
We introduce a new large-scale NLI benchmark dataset, collected via an iterative, adversarial human-and-model-in-the-loop procedure. We show that training models on this new dataset leads to state-of-the-art performance on a variety of popular NLI benchmarks, while posing a more difficult challenge with its new test set. Our analysis sheds light on the shortcomings of current state-of-the-art models, and shows that non-expert annotators are successful at finding their weaknesses. The data collection method can be applied in a never-ending learning scenario, becoming a moving target for NLU, rather than a static benchmark that will quickly saturate.
Build it Break it Fix it for Dialogue Safety: Robustness from Adversarial Human Attack
Aug 17, 2019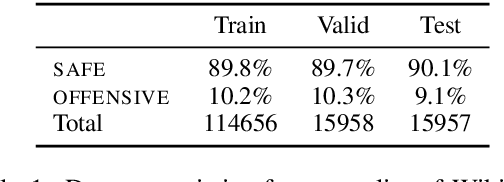
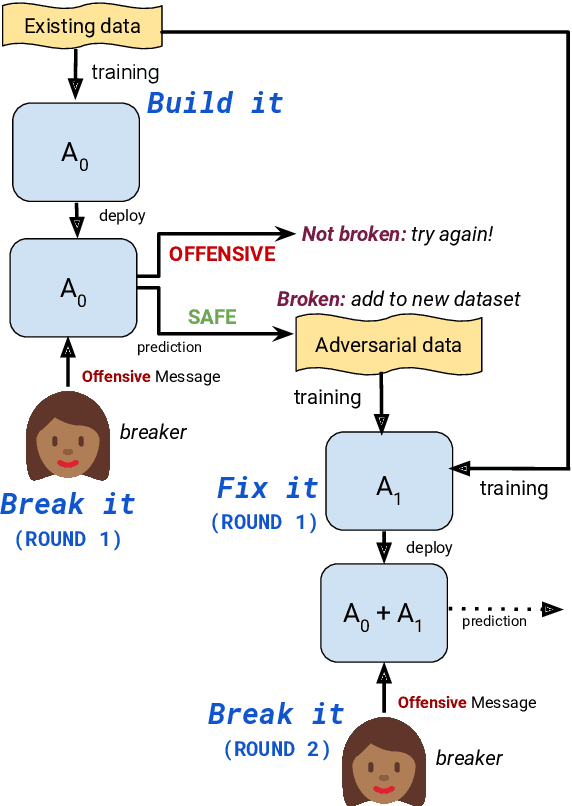


The detection of offensive language in the context of a dialogue has become an increasingly important application of natural language processing. The detection of trolls in public forums (Gal\'an-Garc\'ia et al., 2016), and the deployment of chatbots in the public domain (Wolf et al., 2017) are two examples that show the necessity of guarding against adversarially offensive behavior on the part of humans. In this work, we develop a training scheme for a model to become robust to such human attacks by an iterative build it, break it, fix it strategy with humans and models in the loop. In detailed experiments we show this approach is considerably more robust than previous systems. Further, we show that offensive language used within a conversation critically depends on the dialogue context, and cannot be viewed as a single sentence offensive detection task as in most previous work. Our newly collected tasks and methods will be made open source and publicly available.
Neural Text Generation with Unlikelihood Training
Aug 12, 2019


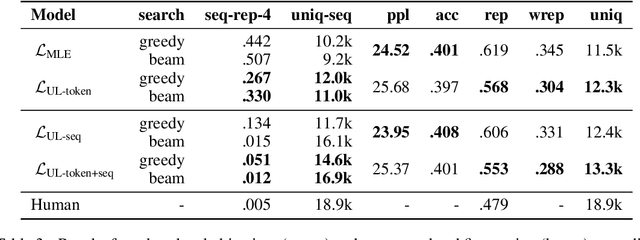
Neural text generation is a key tool in natural language applications, but it is well known there are major problems at its core. In particular, standard likelihood training and decoding leads to dull and repetitive responses. While some post-hoc fixes have been proposed, in particular top-k and nucleus sampling, they do not address the fact that the token-level probabilities predicted by the model itself are poor. In this paper we show that the likelihood objective itself is at fault, resulting in a model that assigns too much probability to sequences that contain repeats and frequent words unlike the human training distribution. We propose a new objective, unlikelihood training, which forces unlikely generations to be assigned lower probability by the model. We show that both token and sequence level unlikelihood training give less repetitive, less dull text while maintaining perplexity, giving far superior generations using standard greedy or beam search. Our approach provides a strong alternative to traditional training.
Learning to Speak and Act in a Fantasy Text Adventure Game
Mar 07, 2019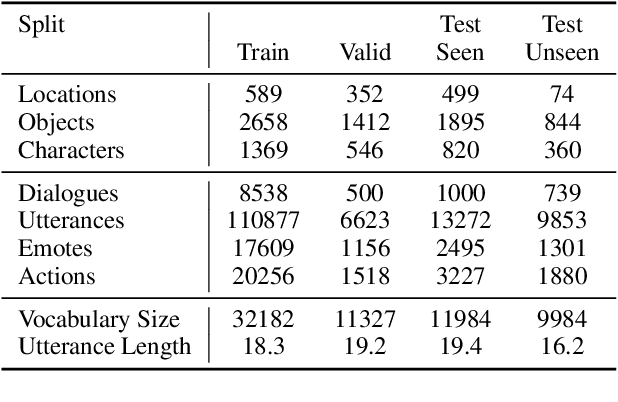
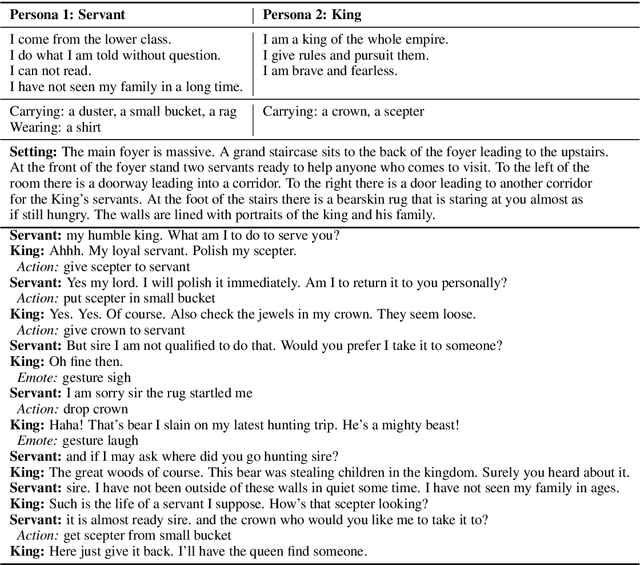
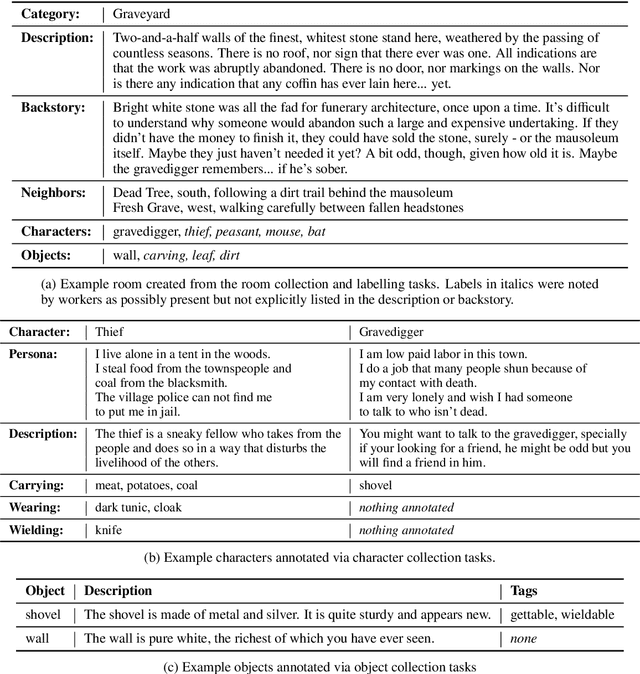

We introduce a large scale crowdsourced text adventure game as a research platform for studying grounded dialogue. In it, agents can perceive, emote, and act whilst conducting dialogue with other agents. Models and humans can both act as characters within the game. We describe the results of training state-of-the-art generative and retrieval models in this setting. We show that in addition to using past dialogue, these models are able to effectively use the state of the underlying world to condition their predictions. In particular, we show that grounding on the details of the local environment, including location descriptions, and the objects (and their affordances) and characters (and their previous actions) present within it allows better predictions of agent behavior and dialogue. We analyze the ingredients necessary for successful grounding in this setting, and how each of these factors relate to agents that can talk and act successfully.
The Second Conversational Intelligence Challenge (ConvAI2)
Jan 31, 2019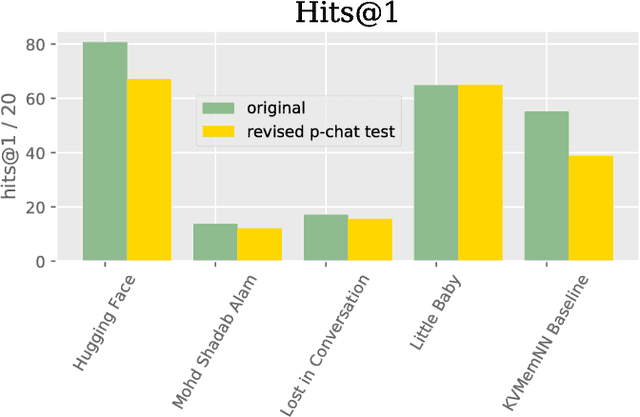

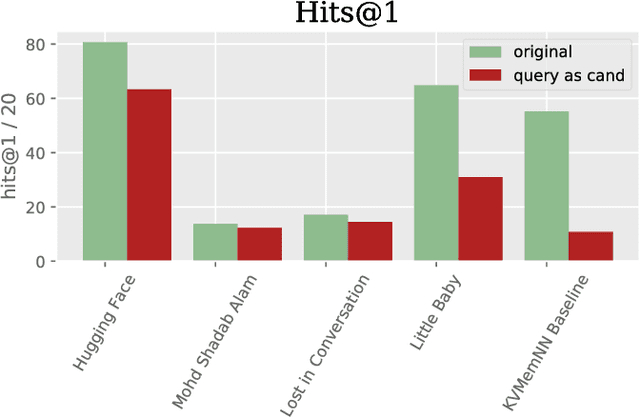
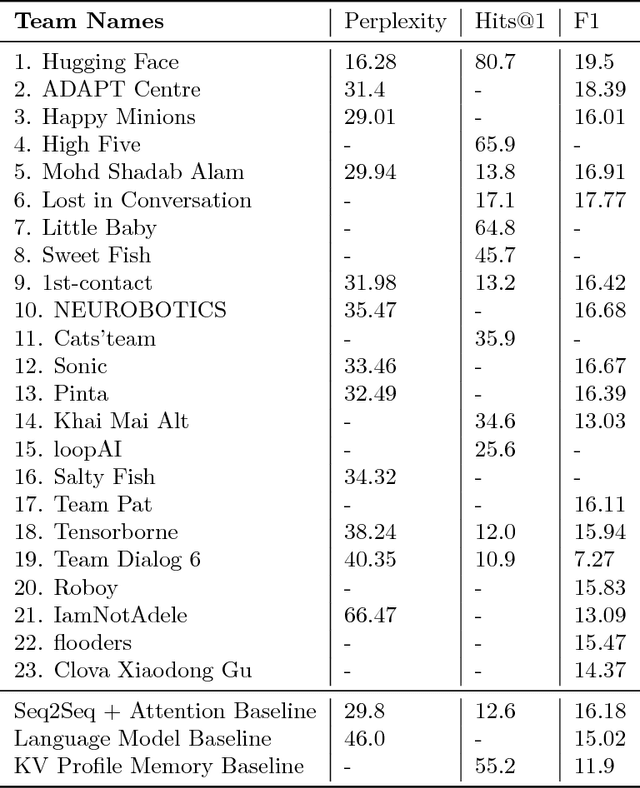
We describe the setting and results of the ConvAI2 NeurIPS competition that aims to further the state-of-the-art in open-domain chatbots. Some key takeaways from the competition are: (i) pretrained Transformer variants are currently the best performing models on this task, (ii) but to improve performance on multi-turn conversations with humans, future systems must go beyond single word metrics like perplexity to measure the performance across sequences of utterances (conversations) -- in terms of repetition, consistency and balance of dialogue acts (e.g. how many questions asked vs. answered).
Wizard of Wikipedia: Knowledge-Powered Conversational agents
Nov 03, 2018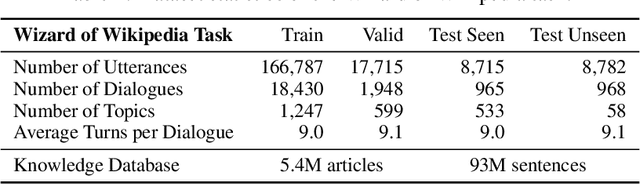
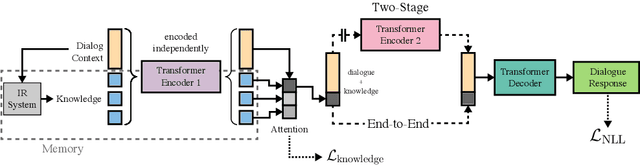

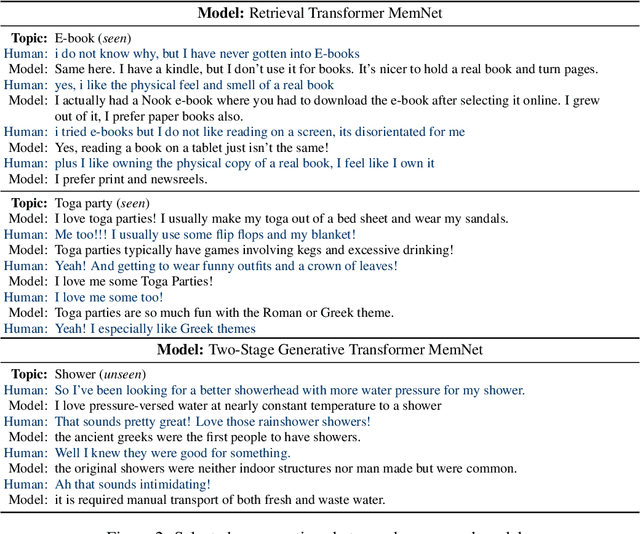
In open-domain dialogue intelligent agents should exhibit the use of knowledge, however there are few convincing demonstrations of this to date. The most popular sequence to sequence models typically "generate and hope" generic utterances that can be memorized in the weights of the model when mapping from input utterance(s) to output, rather than employing recalled knowledge as context. Use of knowledge has so far proved difficult, in part because of the lack of a supervised learning benchmark task which exhibits knowledgeable open dialogue with clear grounding. To that end we collect and release a large dataset with conversations directly grounded with knowledge retrieved from Wikipedia. We then design architectures capable of retrieving knowledge, reading and conditioning on it, and finally generating natural responses. Our best performing dialogue models are able to conduct knowledgeable discussions on open-domain topics as evaluated by automatic metrics and human evaluations, while our new benchmark allows for measuring further improvements in this important research direction.