 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning of New Sound Classes using Generative Replay
Jun 03, 2019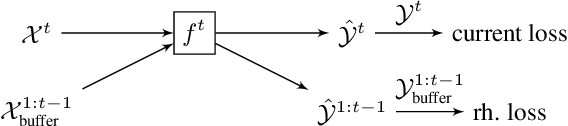

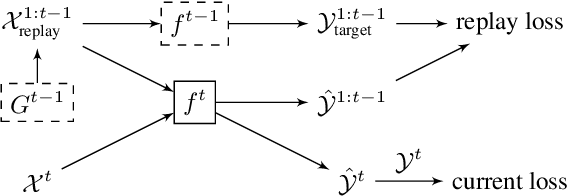
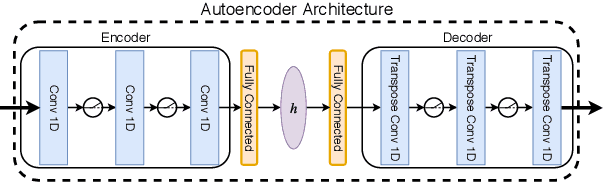
Continual learning consists in incrementally training a model on a sequence of datasets and testing on the union of all datasets. In this paper, we examine continual learning for the problem of sound classification, in which we wish to refine already trained models to learn new sound classes. In practice one does not want to maintain all past training data and retrain from scratch, but naively updating a model with new data(sets) results in a degradation of already learned tasks, which is referred to as "catastrophic forgetting." We develop a generative replay procedure for generating training audio spectrogram data, in place of keeping older training datasets. We show that by incrementally refining a classifier with generative replay a generator that is 4% of the size of all previous training data matches the performance of refining the classifier keeping 20% of all previous training data. We thus conclude that we can extend a trained sound classifier to learn new classes without having to keep previously used datasets.
Bootstrapped Coordinate Search for Multidimensional Scaling
Feb 04, 2019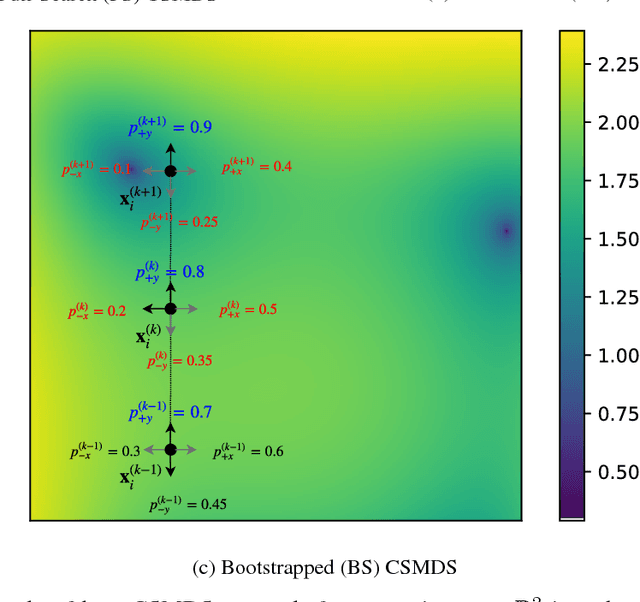
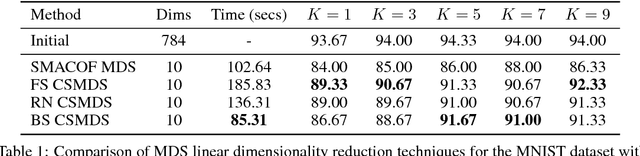

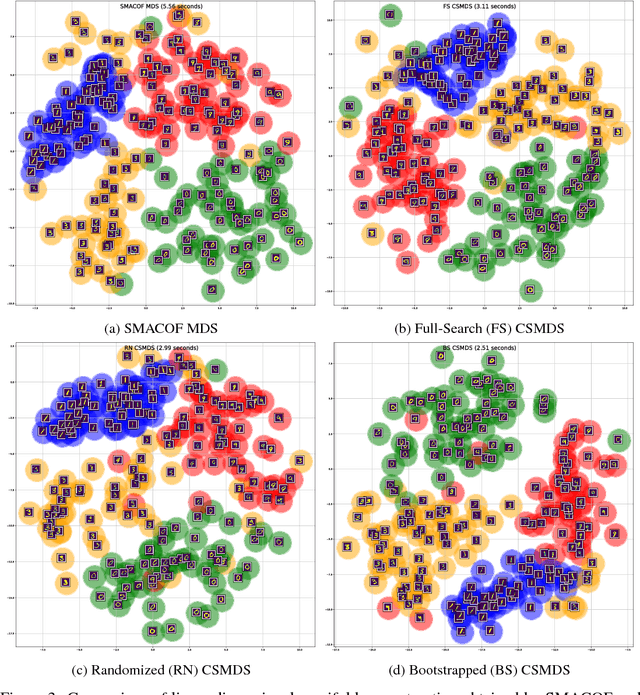
In this work, a unified framework for gradient-free Multidimensional Scaling (MDS) based on Coordinate Search (CS) is proposed. This family of algorithms is an instance of General Pattern Search (GPS) methods which avoid the explicit computation of derivatives but instead evaluate the objective function while searching on coordinate steps of the embedding space. The backbone element of CSMDS framework is the corresponding probability matrix that correspond to how likely is each corresponding coordinate to be evaluated. We propose a Bootstrapped instance of CSMDS (BS CSMDS) which enhances the probability of the direction that decreases the most the objective function while also reducing the corresponding probability of all the other coordinates. BS CSMDS manages to avoid unnecessary function evaluations and result to significant speedup over other CSMDS alternatives while also obtaining the same error rate. Experiments on both synthetic and real data reveal that BS CSMDS performs consistently better than other CSMDS alternatives under various experimental setups.
Integrating Recurrence Dynamics for Speech Emotion Recognition
Nov 09, 2018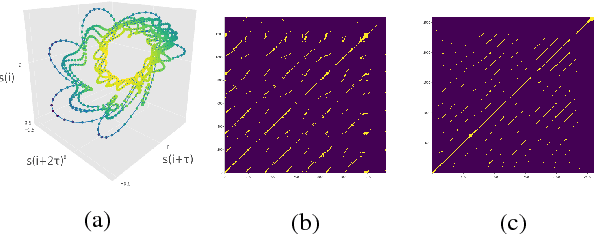

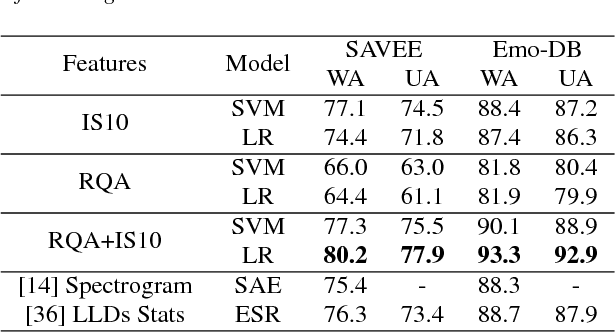
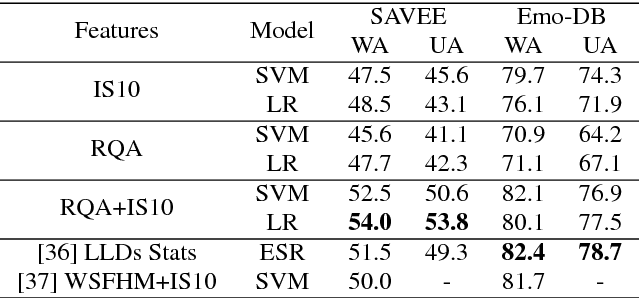
We investigate the performance of features that can capture nonlinear recurrence dynamics embedded in the speech signal for the task of Speech Emotion Recognition (SER). Reconstruction of the phase space of each speech frame and the computation of its respective Recurrence Plot (RP) reveals complex structures which can be measured by performing Recurrence Quantification Analysis (RQA). These measures are aggregated by using statistical functionals over segment and utterance periods. We report SER results for the proposed feature set on three databases using different classification methods. When fusing the proposed features with traditional feature sets, we show an improvement in unweighted accuracy of up to 5.7% and 10.7% on Speaker-Dependent (SD) and Speaker-Independent (SI) SER tasks, respectively, over the baseline. Following a segment-based approach we demonstrate state-of-the-art performance on IEMOCAP using a Bidirectional Recurrent Neural Network.
Unsupervised Deep Clustering for Source Separation: Direct Learning from Mixtures using Spatial Information
Nov 05, 2018



We present a monophonic source separation system that is trained by only observing mixtures with no ground truth separation information. We use a deep clustering approach which trains on multi-channel mixtures and learns to project spectrogram bins to source clusters that correlate with various spatial features. We show that using such a training process we can obtain separation performance that is as good as making use of ground truth separation information. Once trained, this system is capable of performing sound separation on monophonic inputs, despite having learned how to do so using multi-channel recordings.
Pattern Search Multidimensional Scaling
Jun 06, 2018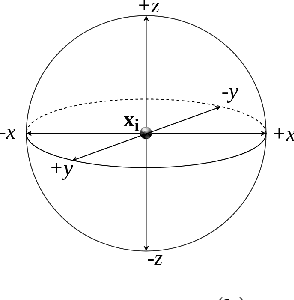
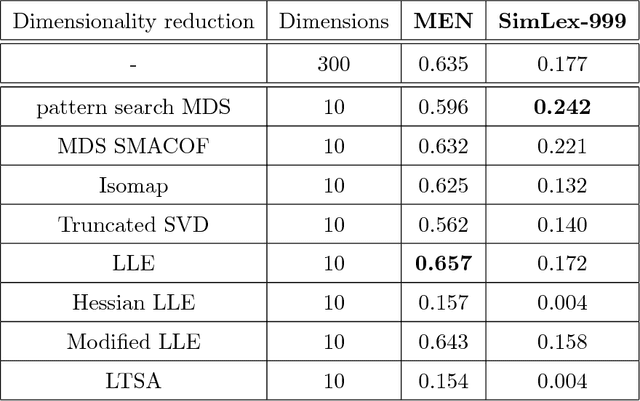
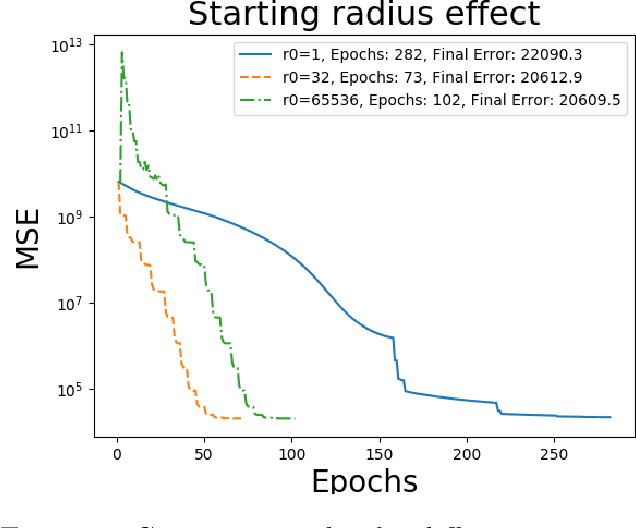
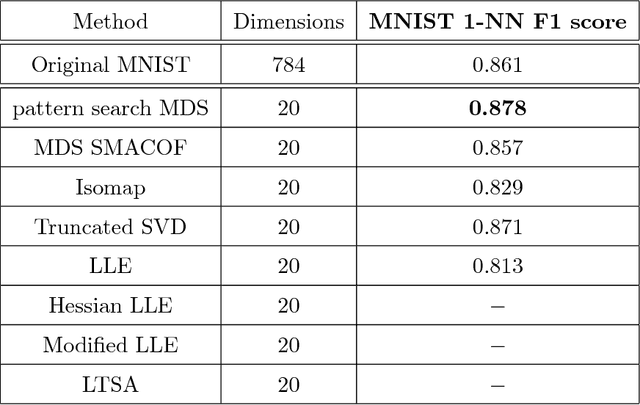
We present a novel view of nonlinear manifold learning using derivative-free optimization techniques. Specifically, we propose an extension of the classical multi-dimensional scaling (MDS) method, where instead of performing gradient descent, we sample and evaluate possible "moves" in a sphere of fixed radius for each point in the embedded space. A fixed-point convergence guarantee can be shown by formulating the proposed algorithm as an instance of General Pattern Search (GPS) framework. Evaluation on both clean and noisy synthetic datasets shows that pattern search MDS can accurately infer the intrinsic geometry of manifolds embedded in high-dimensional spaces. Additionally, experiments on real data, even under noisy conditions, demonstrate that the proposed pattern search MDS yields state-of-the-art results.