 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory in Plain Sight: A Survey of the Uncanny Resemblances between Diffusion Models and Associative Memories
Sep 28, 2023


Diffusion Models (DMs) have recently set state-of-the-art on many generation benchmarks. However, there are myriad ways to describe them mathematically, which makes it difficult to develop a simple understanding of how they work. In this survey, we provide a concise overview of DMs from the perspective of dynamical systems and Ordinary Differential Equations (ODEs) which exposes a mathematical connection to the highly related yet often overlooked class of energy-based models, called Associative Memories (AMs). Energy-based AMs are a theoretical framework that behave much like denoising DMs, but they enable us to directly compute a Lyapunov energy function on which we can perform gradient descent to denoise data. We then summarize the 40 year history of energy-based AMs, beginning with the original Hopfield Network, and discuss new research directions for AMs and DMs that are revealed by characterizing the extent of their similarities and differences
Long Sequence Hopfield Memory
Jun 07, 2023



Sequence memory is an essential attribute of natural and artificial intelligence that enables agents to encode, store, and retrieve complex sequences of stimuli and actions. Computational models of sequence memory have been proposed where recurrent Hopfield-like neural networks are trained with temporally asymmetric Hebbian rules. However, these networks suffer from limited sequence capacity (maximal length of the stored sequence) due to interference between the memories. Inspired by recent work on Dense Associative Memories, we expand the sequence capacity of these models by introducing a nonlinear interaction term, enhancing separation between the patterns. We derive novel scaling laws for sequence capacity with respect to network size, significantly outperforming existing scaling laws for models based on traditional Hopfield networks, and verify these theoretical results with numerical simulation. Moreover, we introduce a generalized pseudoinverse rule to recall sequences of highly correlated patterns. Finally, we extend this model to store sequences with variable timing between states' transitions and describe a biologically-plausible implementation, with connections to motor neuroscience.
End-to-end Differentiable Clustering with Associative Memories
Jun 05, 2023



Clustering is a widely used unsupervised learning technique involving an intensive discrete optimization problem. Associative Memory models or AMs are differentiable neural networks defining a recursive dynamical system, which have been integrated with various deep learning architectures. We uncover a novel connection between the AM dynamics and the inherent discrete assignment necessary in clustering to propose a novel unconstrained continuous relaxation of the discrete clustering problem, enabling end-to-end differentiable clustering with AM, dubbed ClAM. Leveraging the pattern completion ability of AMs, we further develop a novel self-supervised clustering loss. Our evaluations on varied datasets demonstrate that ClAM benefits from the self-supervision, and significantly improves upon both the traditional Lloyd's k-means algorithm, and more recent continuous clustering relaxations (by upto 60% in terms of the Silhouette Coefficient).
Sparse Distributed Memory is a Continual Learner
Mar 20, 2023Continual learning is a problem for artificial neural networks that their biological counterparts are adept at solving. Building on work using Sparse Distributed Memory (SDM) to connect a core neural circuit with the powerful Transformer model, we create a modified Multi-Layered Perceptron (MLP) that is a strong continual learner. We find that every component of our MLP variant translated from biology is necessary for continual learning. Our solution is also free from any memory replay or task information, and introduces novel methods to train sparse networks that may be broadly applicable.
* 9 Pages. ICLR Acceptance
Energy Transformer
Feb 14, 2023



Transformers have become the de facto models of choice in machine learning, typically leading to impressive performance on many applications. At the same time, the architectural development in the transformer world is mostly driven by empirical findings, and the theoretical understanding of their architectural building blocks is rather limited. In contrast, Dense Associative Memory models or Modern Hopfield Networks have a well-established theoretical foundation, but have not yet demonstrated truly impressive practical results. We propose a transformer architecture that replaces the sequence of feedforward transformer blocks with a single large Associative Memory model. Our novel architecture, called Energy Transformer (or ET for short), has many of the familiar architectural primitives that are often used in the current generation of transformers. However, it is not identical to the existing architectures. The sequence of transformer layers in ET is purposely designed to minimize a specifically engineered energy function, which is responsible for representing the relationships between the tokens. As a consequence of this computational principle, the attention in ET is different from the conventional attention mechanism. In this work, we introduce the theoretical foundations of ET, explore it's empirical capabilities using the image completion task, and obtain strong quantitative results on the graph anomaly detection task.
Associative Learning for Network Embedding
Aug 30, 2022
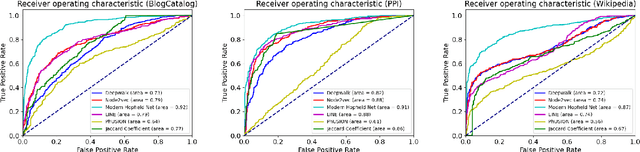

The network embedding task is to represent the node in the network as a low-dimensional vector while incorporating the topological and structural information. Most existing approaches solve this problem by factorizing a proximity matrix, either directly or implicitly. In this work, we introduce a network embedding method from a new perspective, which leverages Modern Hopfield Networks (MHN) for associative learning. Our network learns associations between the content of each node and that node's neighbors. These associations serve as memories in the MHN. The recurrent dynamics of the network make it possible to recover the masked node, given that node's neighbors. Our proposed method is evaluated on different downstream tasks such as node classification and linkage prediction. The results show competitive performance compared to the common matrix factorization techniques and deep learning based methods.
Hierarchical Associative Memory
Jul 14, 2021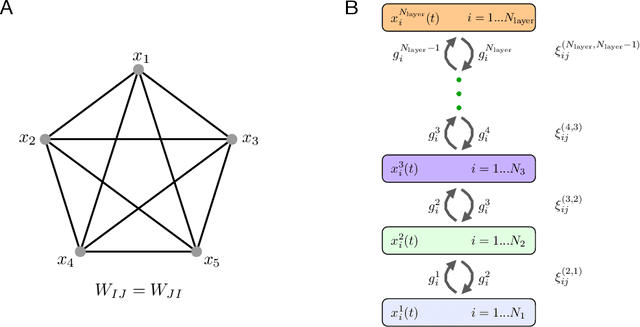
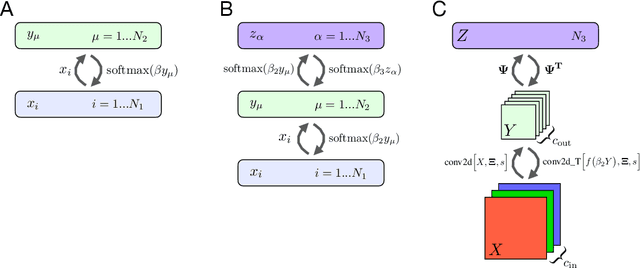
Dense Associative Memories or Modern Hopfield Networks have many appealing properties of associative memory. They can do pattern completion, store a large number of memories, and can be described using a recurrent neural network with a degree of biological plausibility and rich feedback between the neurons. At the same time, up until now all the models of this class have had only one hidden layer, and have only been formulated with densely connected network architectures, two aspects that hinder their machine learning applications. This paper tackles this gap and describes a fully recurrent model of associative memory with an arbitrary large number of layers, some of which can be locally connected (convolutional), and a corresponding energy function that decreases on the dynamical trajectory of the neurons' activations. The memories of the full network are dynamically "assembled" using primitives encoded in the synaptic weights of the lower layers, with the "assembling rules" encoded in the synaptic weights of the higher layers. In addition to the bottom-up propagation of information, typical of commonly used feedforward neural networks, the model described has rich top-down feedback from higher layers that help the lower-layer neurons to decide on their response to the input stimuli.
Can a Fruit Fly Learn Word Embeddings?
Jan 18, 2021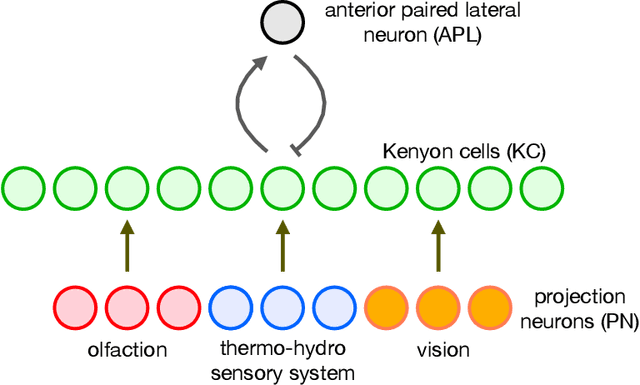
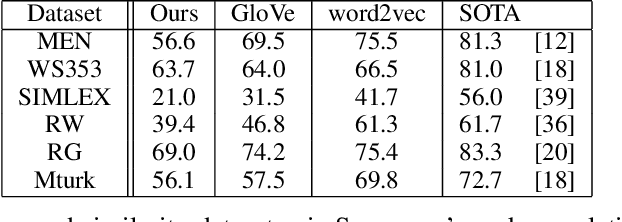
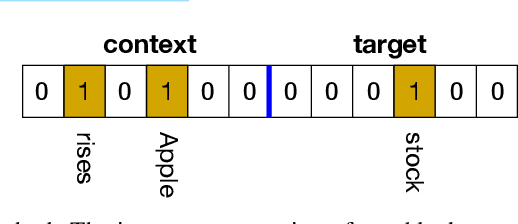

The mushroom body of the fruit fly brain is one of the best studied systems in neuroscience. At its core it consists of a population of Kenyon cells, which receive inputs from multiple sensory modalities. These cells are inhibited by the anterior paired lateral neuron, thus creating a sparse high dimensional representation of the inputs. In this work we study a mathematical formalization of this network motif and apply it to learning the correlational structure between words and their context in a corpus of unstructured text, a common natural language processing (NLP) task. We show that this network can learn semantic representations of words and can generate both static and context-dependent word embeddings. Unlike conventional methods (e.g., BERT, GloVe) that use dense representations for word embedding, our algorithm encodes semantic meaning of words and their context in the form of sparse binary hash codes. The quality of the learned representations is evaluated on word similarity analysis, word-sense disambiguation, and document classification. It is shown that not only can the fruit fly network motif achieve performance comparable to existing methods in NLP, but, additionally, it uses only a fraction of the computational resources (shorter training time and smaller memory footprint).
Large Associative Memory Problem in Neurobiology and Machine Learning
Aug 16, 2020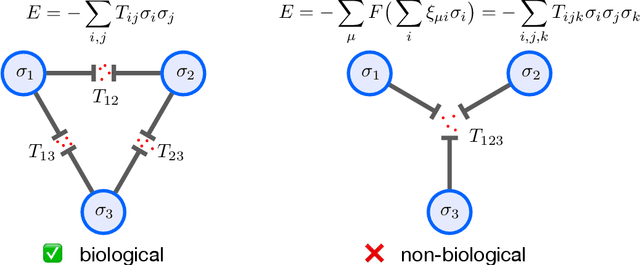
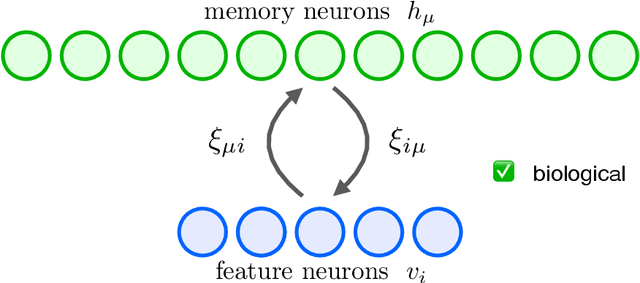
Dense Associative Memories or modern Hopfield networks permit storage and reliable retrieval of an exponentially large (in the dimension of feature space) number of memories. At the same time, their naive implementation is non-biological, since it seemingly requires the existence of many-body synaptic junctions between the neurons. We show that these models are effective descriptions of a more microscopic (written in terms of biological degrees of freedom) theory that has additional (hidden) neurons and only requires two-body interactions between them. For this reason our proposed microscopic theory is a valid model of large associative memory with a degree of biological plausibility. The dynamics of our network and its reduced dimensional equivalent both minimize energy (Lyapunov) functions. When certain dynamical variables (hidden neurons) are integrated out from our microscopic theory, one can recover many of the models that were previously discussed in the literature, e.g. the model presented in ''Hopfield Networks is All You Need'' paper. We also provide an alternative derivation of the energy function and the update rule proposed in the aforementioned paper and clarify the relationships between various models of this class.
Bio-Inspired Hashing for Unsupervised Similarity Search
Jan 14, 2020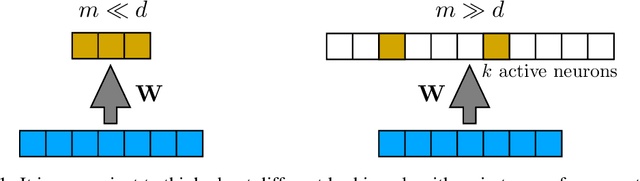
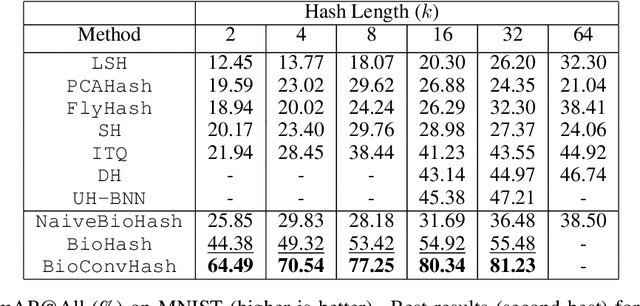
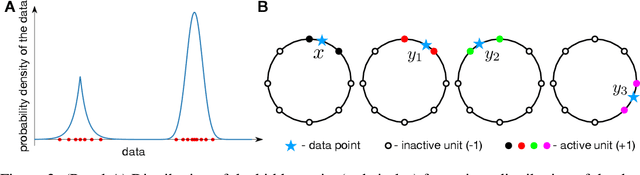
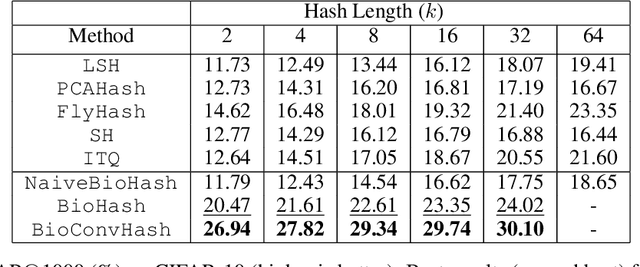
The fruit fly Drosophila's olfactory circuit has inspired a new locality sensitive hashing (LSH) algorithm, FlyHash. In contrast with classical LSH algorithms that produce low dimensional hash codes, FlyHash produces sparse high-dimensional hash codes and has also been shown to have superior empirical performance compared to classical LSH algorithms in similarity search. However, FlyHash uses random projections and cannot learn from data. Building on inspiration from FlyHash and the ubiquity of sparse expansive representations in neurobiology, our work proposes a novel hashing algorithm BioHash that produces sparse high dimensional hash codes in a data-driven manner. We show that BioHash outperforms previously published benchmarks for various hashing methods. Since our learning algorithm is based on a local and biologically plausible synaptic plasticity rule, our work provides evidence for the proposal that LSH might be a computational reason for the abundance of sparse expansive motifs in a variety of biological systems. We also propose a convolutional variant BioConvHash that further improves performance. From the perspective of computer science, BioHash and BioConvHash are fast, scalable and yield compressed binary representations that are useful for similarity search.