 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesmond Elliott
Textual Supervision for Visually Grounded Spoken Language Understanding
Oct 07, 2020


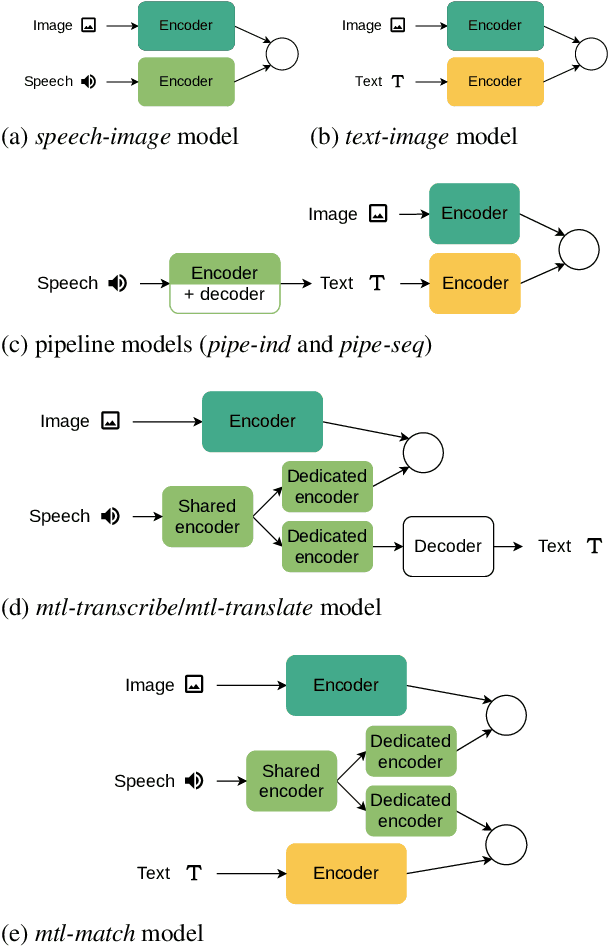

Visually-grounded models of spoken language understanding extract semantic information directly from speech, without relying on transcriptions. This is useful for low-resource languages, where transcriptions can be expensive or impossible to obtain. Recent work showed that these models can be improved if transcriptions are available at training time. However, it is not clear how an end-to-end approach compares to a traditional pipeline-based approach when one has access to transcriptions. Comparing different strategies, we find that the pipeline approach works better when enough text is available. With low-resource languages in mind, we also show that translations can be effectively used in place of transcriptions but more data is needed to obtain similar results.
Fine-Grained Grounding for Multimodal Speech Recognition
Oct 05, 2020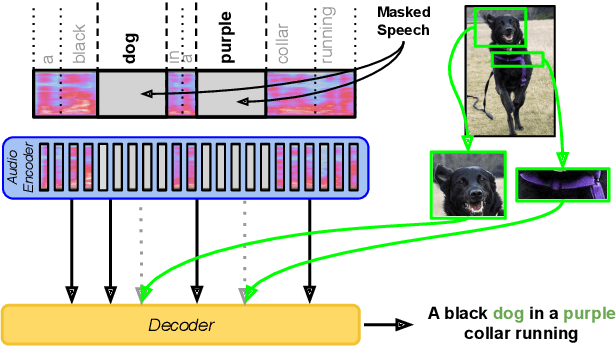
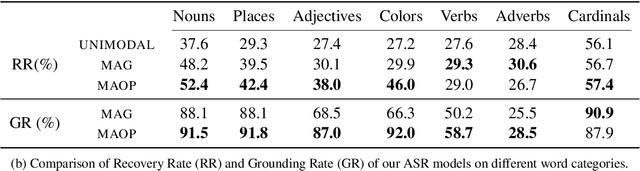
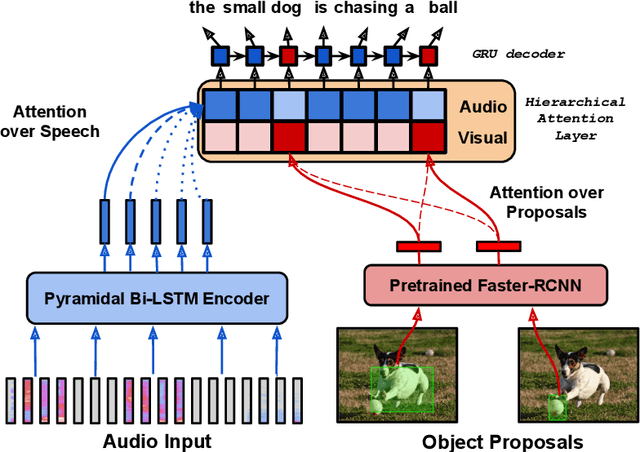
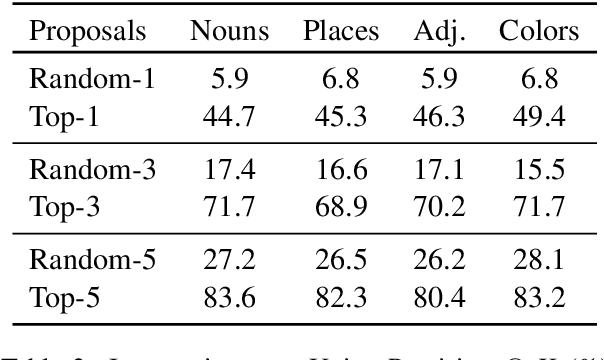
Multimodal automatic speech recognition systems integrate information from images to improve speech recognition quality, by grounding the speech in the visual context. While visual signals have been shown to be useful for recovering entities that have been masked in the audio, these models should be capable of recovering a broader range of word types. Existing systems rely on global visual features that represent the entire image, but localizing the relevant regions of the image will make it possible to recover a larger set of words, such as adjectives and verbs. In this paper, we propose a model that uses finer-grained visual information from different parts of the image, using automatic object proposals. In experiments on the Flickr8K Audio Captions Corpus, we find that our model improves over approaches that use global visual features, that the proposals enable the model to recover entities and other related words, such as adjectives, and that improvements are due to the model's ability to localize the correct proposals.
CompGuessWhat?!: A Multi-task Evaluation Framework for Grounded Language Learning
Jun 03, 2020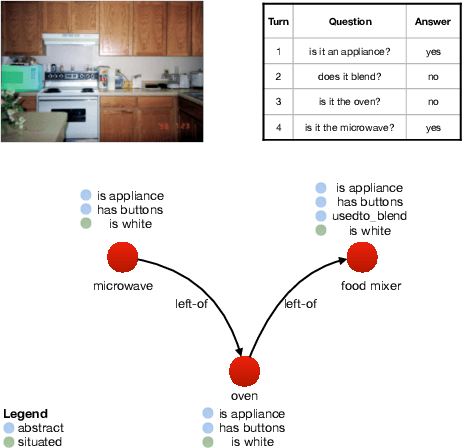
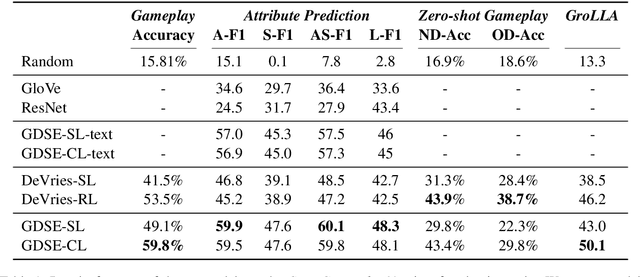


Approaches to Grounded Language Learning typically focus on a single task-based final performance measure that may not depend on desirable properties of the learned hidden representations, such as their ability to predict salient attributes or to generalise to unseen situations. To remedy this, we present GROLLA, an evaluation framework for Grounded Language Learning with Attributes with three sub-tasks: 1) Goal-oriented evaluation; 2) Object attribute prediction evaluation; and 3) Zero-shot evaluation. We also propose a new dataset CompGuessWhat?! as an instance of this framework for evaluating the quality of learned neural representations, in particular concerning attribute grounding. To this end, we extend the original GuessWhat?! dataset by including a semantic layer on top of the perceptual one. Specifically, we enrich the VisualGenome scene graphs associated with the GuessWhat?! images with abstract and situated attributes. By using diagnostic classifiers, we show that current models learn representations that are not expressive enough to encode object attributes (average F1 of 44.27). In addition, they do not learn strategies nor representations that are robust enough to perform well when novel scenes or objects are involved in gameplay (zero-shot best accuracy 50.06%).
The Sensitivity of Language Models and Humans to Winograd Schema Perturbations
May 07, 2020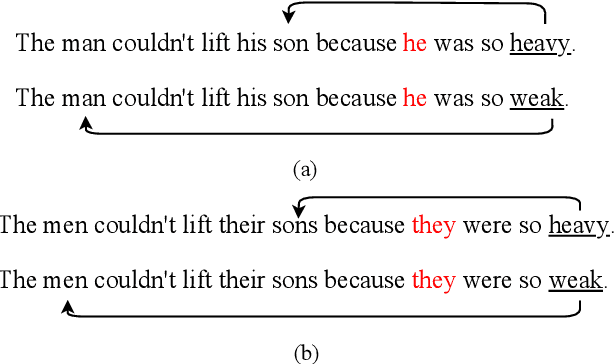

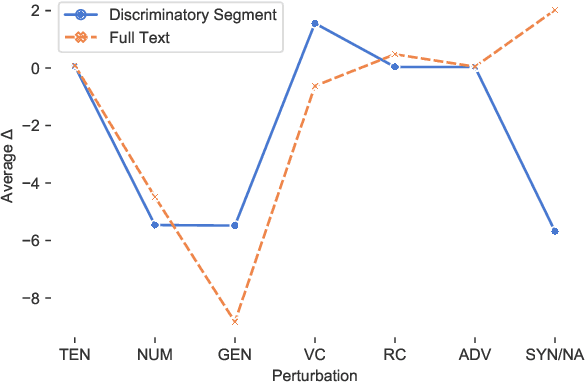
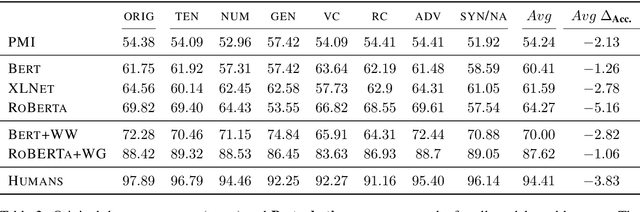
Large-scale pretrained language models are the major driving force behind recent improvements in performance on the Winograd Schema Challenge, a widely employed test of common sense reasoning ability. We show, however, with a new diagnostic dataset, that these models are sensitive to linguistic perturbations of the Winograd examples that minimally affect human understanding. Our results highlight interesting differences between humans and language models: language models are more sensitive to number or gender alternations and synonym replacements than humans, and humans are more stable and consistent in their predictions, maintain a much higher absolute performance, and perform better on non-associative instances than associative ones. Overall, humans are correct more often than out-of-the-box models, and the models are sometimes right for the wrong reasons. Finally, we show that fine-tuning on a large, task-specific dataset can offer a solution to these issues.
Multimodal Machine Translation through Visuals and Speech
Nov 28, 2019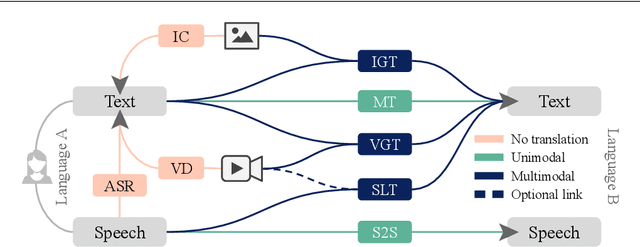
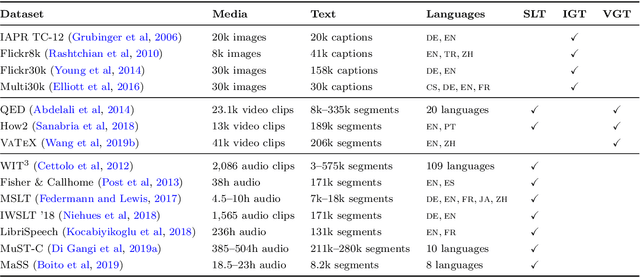

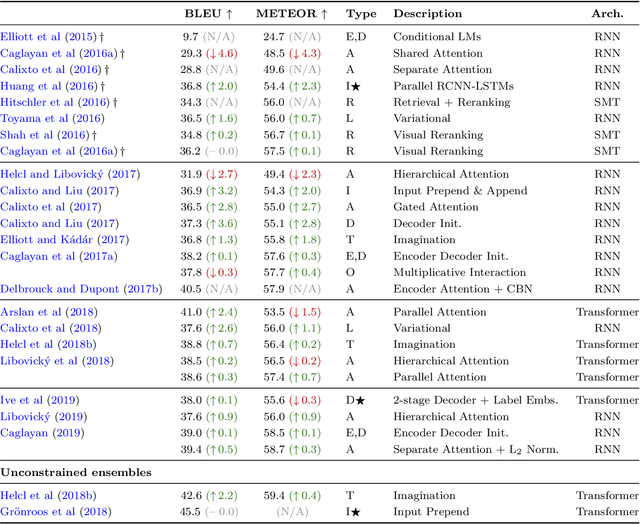
Multimodal machine translation involves drawing information from more than one modality, based on the assumption that the additional modalities will contain useful alternative views of the input data. The most prominent tasks in this area are spoken language translation, image-guided translation, and video-guided translation, which exploit audio and visual modalities, respectively. These tasks are distinguished from their monolingual counterparts of speech recognition, image captioning, and video captioning by the requirement of models to generate outputs in a different language. This survey reviews the major data resources for these tasks, the evaluation campaigns concentrated around them, the state of the art in end-to-end and pipeline approaches, and also the challenges in performance evaluation. The paper concludes with a discussion of directions for future research in these areas: the need for more expansive and challenging datasets, for targeted evaluations of model performance, and for multimodality in both the input and output space.
Bootstrapping Disjoint Datasets for Multilingual Multimodal Representation Learning
Nov 09, 2019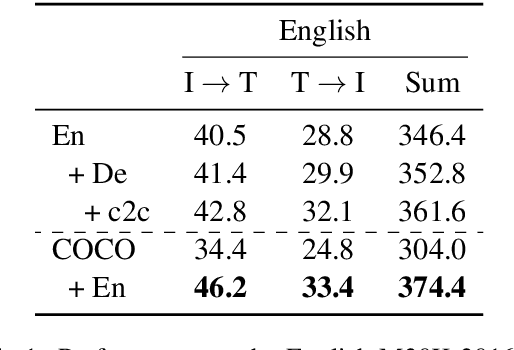

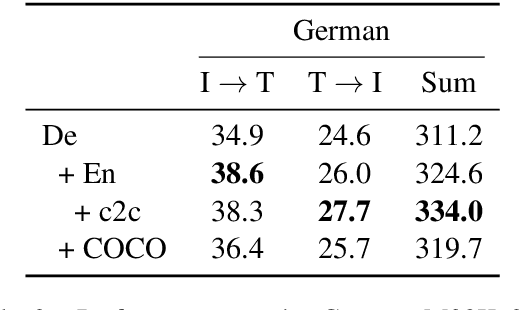

Recent work has highlighted the advantage of jointly learning grounded sentence representations from multiple languages. However, the data used in these studies has been limited to an aligned scenario: the same images annotated with sentences in multiple languages. We focus on the more realistic disjoint scenario in which there is no overlap between the images in multilingual image--caption datasets. We confirm that training with aligned data results in better grounded sentence representations than training with disjoint data, as measured by image--sentence retrieval performance. In order to close this gap in performance, we propose a pseudopairing method to generate synthetically aligned English--German--image triplets from the disjoint sets. The method works by first training a model on the disjoint data, and then creating new triples across datasets using sentence similarity under the learned model. Experiments show that pseudopairs improve image--sentence retrieval performance compared to disjoint training, despite requiring no external data or models. However, we do find that using an external machine translation model to generate the synthetic data sets results in better performance.
Compositional Generalization in Image Captioning
Sep 16, 2019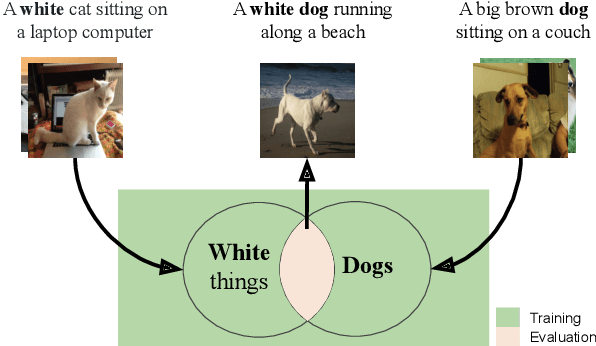

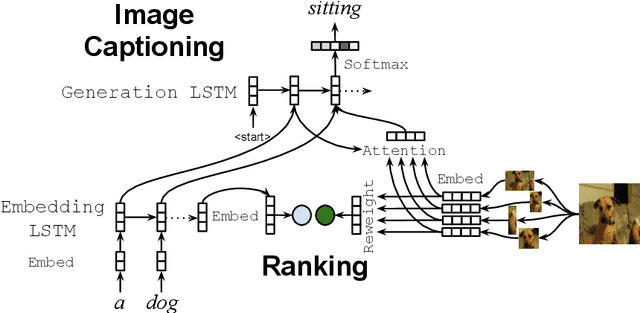
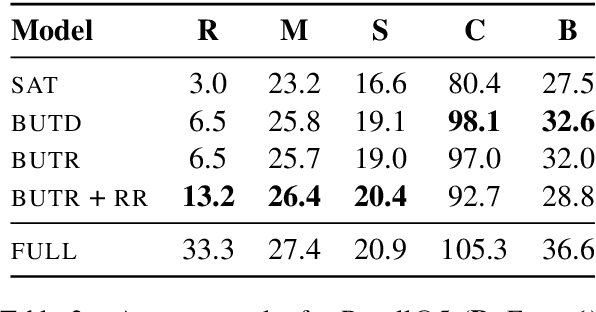
Image captioning models are usually evaluated on their ability to describe a held-out set of images, not on their ability to generalize to unseen concepts. We study the problem of compositional generalization, which measures how well a model composes unseen combinations of concepts when describing images. State-of-the-art image captioning models show poor generalization performance on this task. We propose a multi-task model to address the poor performance, that combines caption generation and image--sentence ranking, and uses a decoding mechanism that re-ranks the captions according their similarity to the image. This model is substantially better at generalizing to unseen combinations of concepts compared to state-of-the-art captioning models.
Cross-lingual Visual Verb Sense Disambiguation
Apr 17, 2019

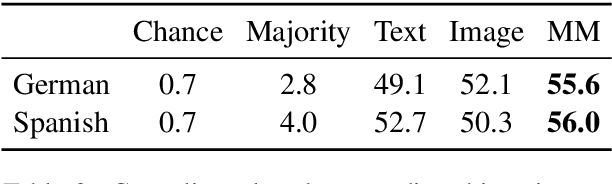
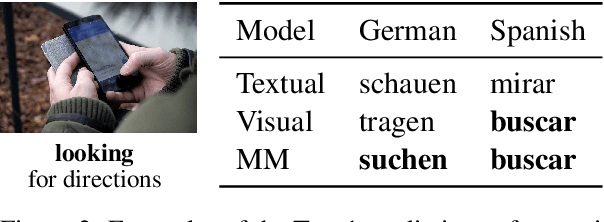
Recent work has shown that visual context improves cross-lingual sense disambiguation for nouns. We extend this line of work to the more challenging task of cross-lingual verb sense disambiguation, introducing the MultiSense dataset of 9,504 images annotated with English, German, and Spanish verbs. Each image in MultiSense is annotated with an English verb and its translation in German or Spanish. We show that cross-lingual verb sense disambiguation models benefit from visual context, compared to unimodal baselines. We also show that the verb sense predicted by our best disambiguation model can improve the results of a text-only machine translation system when used for a multimodal translation task.
How2: A Large-scale Dataset for Multimodal Language Understanding
Nov 01, 2018
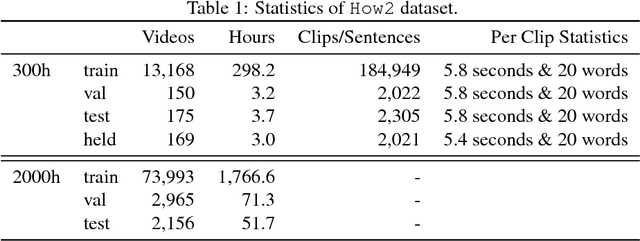
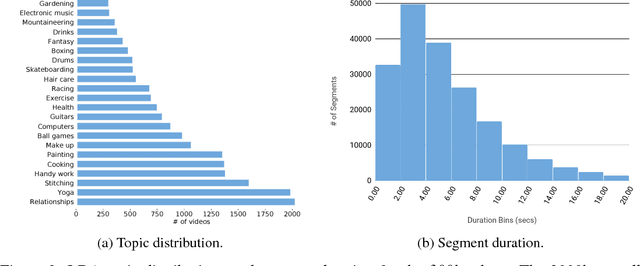

In this paper, we introduce How2, a multimodal collection of instructional videos with English subtitles and crowdsourced Portuguese translations. We also present integrated sequence-to-sequence baselines for machine translation, automatic speech recognition, spoken language translation, and multimodal summarization. By making available data and code for several multimodal natural language tasks, we hope to stimulate more research on these and similar challenges, to obtain a deeper understanding of multimodality in language processing.
Lessons learned in multilingual grounded language learning
Sep 20, 2018
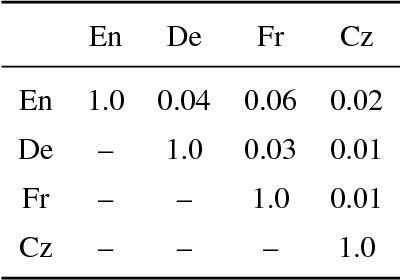
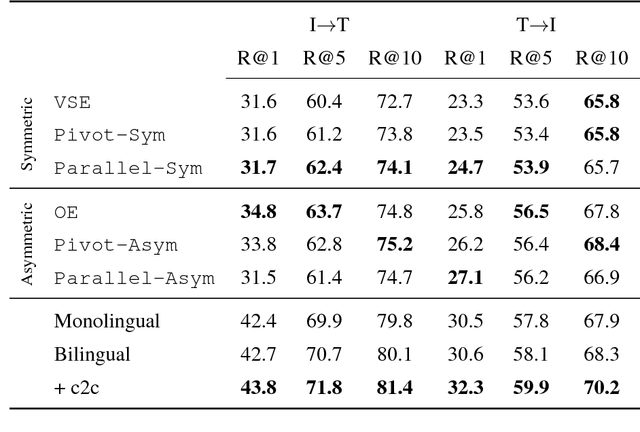
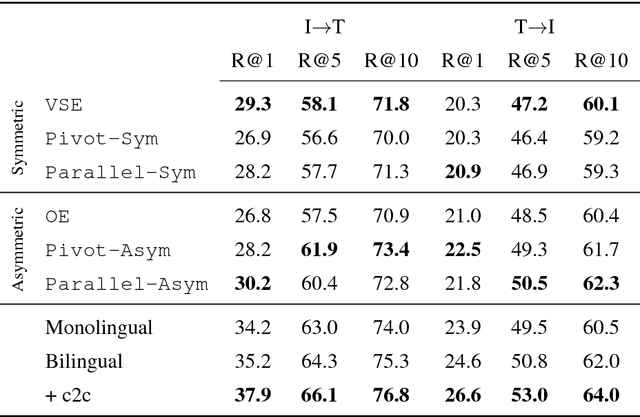
Recent work has shown how to learn better visual-semantic embeddings by leveraging image descriptions in more than one language. Here, we investigate in detail which conditions affect the performance of this type of grounded language learning model. We show that multilingual training improves over bilingual training, and that low-resource languages benefit from training with higher-resource languages. We demonstrate that a multilingual model can be trained equally well on either translations or comparable sentence pairs, and that annotating the same set of images in multiple language enables further improvements via an additional caption-caption ranking objective.