 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDerek Nowrouzezahrai
Overfit Neural Networks as a Compact Shape Representation
Oct 12, 2020
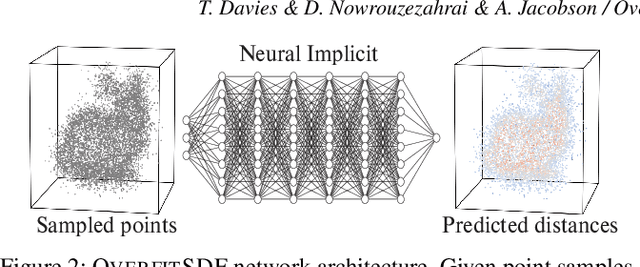
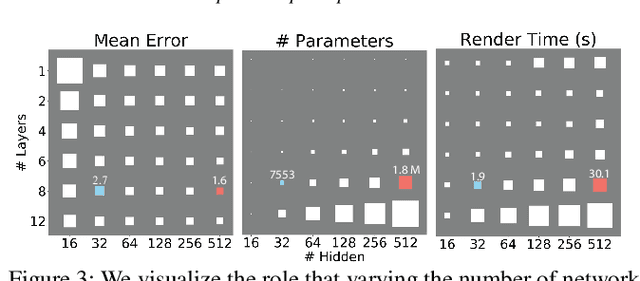
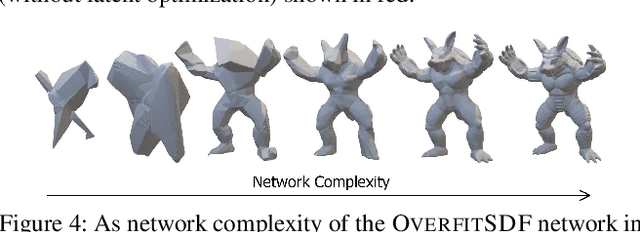

Neural networks have proven to be effective approximators of signed distance fields (SDFs) for solid 3D objects. While prior work has focused on the generalization power of such approximations, we instead explore their suitability as a compact - if purposefully overfit - SDF representation of individual shapes. Specifically, we ask whether neural networks can serve as first-class implicit shape representations in computer graphics. We call such overfit networks Neural Implicits. Similar to SDFs stored on a regular grid, Neural Implicits have fixed storage profiles and memory layout, but afford far greater accuracy. At equal storage cost, Neural Implicits consistently match or exceed the accuracy of irregularly-sampled triangle meshes. We achieve this with a combination of a novel loss function, sampling strategy and supervision protocol designed to facilitate robust shape overfitting. We demonstrate the flexibility of our representation on a variety of standard rendering and modelling tasks.
Regularized Inverse Reinforcement Learning
Oct 07, 2020

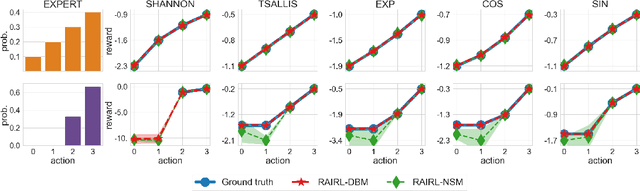

Inverse Reinforcement Learning (IRL) aims to facilitate a learner's ability to imitate expert behavior by acquiring reward functions that explain the expert's decisions. Regularized IRL applies convex regularizers to the learner's policy in order to avoid the expert's behavior being rationalized by arbitrary constant rewards, also known as degenerate solutions. We propose analytical solutions, and practical methods to obtain them, for regularized IRL. Current methods are restricted to the maximum-entropy IRL framework, limiting them to Shannon-entropy regularizers, as well as proposing functional-form solutions that are generally intractable. We present theoretical backing for our proposed IRL method's applicability to both discrete and continuous controls and empirically validate its performance on a variety of tasks.
A Weakly Supervised Region-Based Active Learning Method for COVID-19 Segmentation in CT Images
Jul 07, 2020
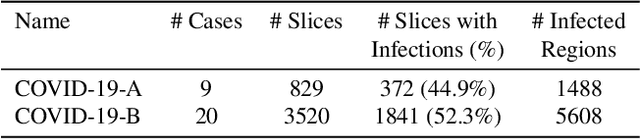
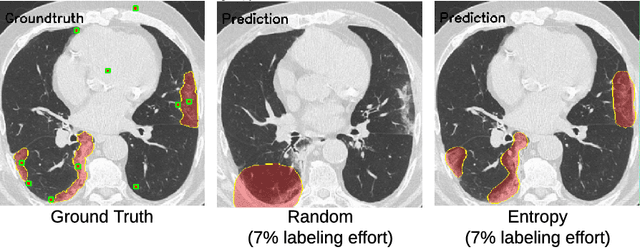
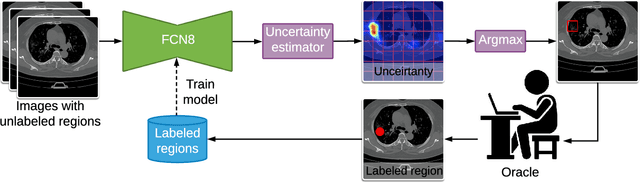
One of the key challenges in the battle against the Coronavirus (COVID-19) pandemic is to detect and quantify the severity of the disease in a timely manner. Computed tomographies (CT) of the lungs are effective for assessing the state of the infection. Unfortunately, labeling CT scans can take a lot of time and effort, with up to 150 minutes per scan. We address this challenge introducing a scalable, fast, and accurate active learning system that accelerates the labeling of CT scan images. Conventionally, active learning methods require the labelers to annotate whole images with full supervision, but that can lead to wasted efforts as many of the annotations could be redundant. Thus, our system presents the annotator with unlabeled regions that promise high information content and low annotation cost. Further, the system allows annotators to label regions using point-level supervision, which is much cheaper to acquire than per-pixel annotations. Our experiments on open-source COVID-19 datasets show that using an entropy-based method to rank unlabeled regions yields to significantly better results than random labeling of these regions. Also, we show that labeling small regions of images is more efficient than labeling whole images. Finally, we show that with only 7\% of the labeling effort required to label the whole training set gives us around 90\% of the performance obtained by training the model on the fully annotated training set. Code is available at: \url{https://github.com/IssamLaradji/covid19_active_learning}.
A Weakly Supervised Consistency-based Learning Method for COVID-19 Segmentation in CT Images
Jul 07, 2020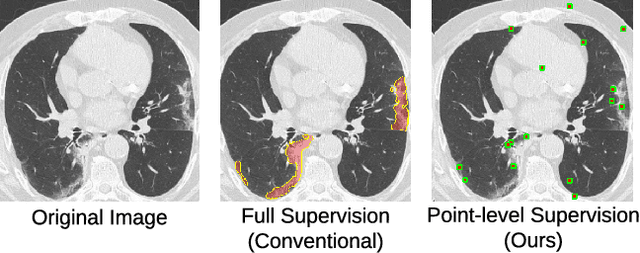

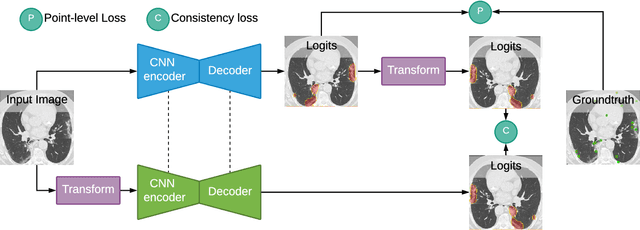
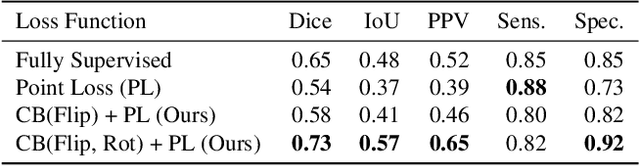
Coronavirus Disease 2019 (COVID-19) has spread aggressively across the world causing an existential health crisis. Thus, having a system that automatically detects COVID-19 in tomography (CT) images can assist in quantifying the severity of the illness. Unfortunately, labelling chest CT scans requires significant domain expertise, time, and effort. We address these labelling challenges by only requiring point annotations, a single pixel for each infected region on a CT image. This labeling scheme allows annotators to label a pixel in a likely infected region, only taking 1-3 seconds, as opposed to 10-15 seconds to segment a region. Conventionally, segmentation models train on point-level annotations using the cross-entropy loss function on these labels. However, these models often suffer from low precision. Thus, we propose a consistency-based (CB) loss function that encourages the output predictions to be consistent with spatial transformations of the input images. The experiments on 3 open-source COVID-19 datasets show that this loss function yields significant improvement over conventional point-level loss functions and almost matches the performance of models trained with full supervision with much less human effort. Code is available at: \url{https://github.com/IssamLaradji/covid19_weak_supervision}.
Adversarial Soft Advantage Fitting: Imitation Learning without Policy Optimization
Jun 23, 2020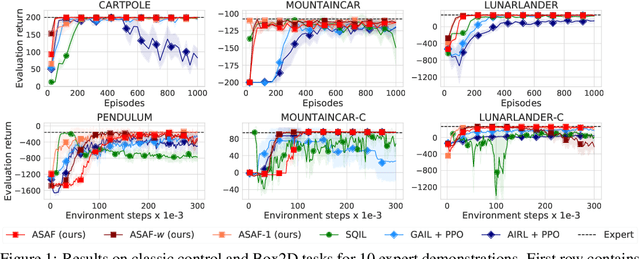
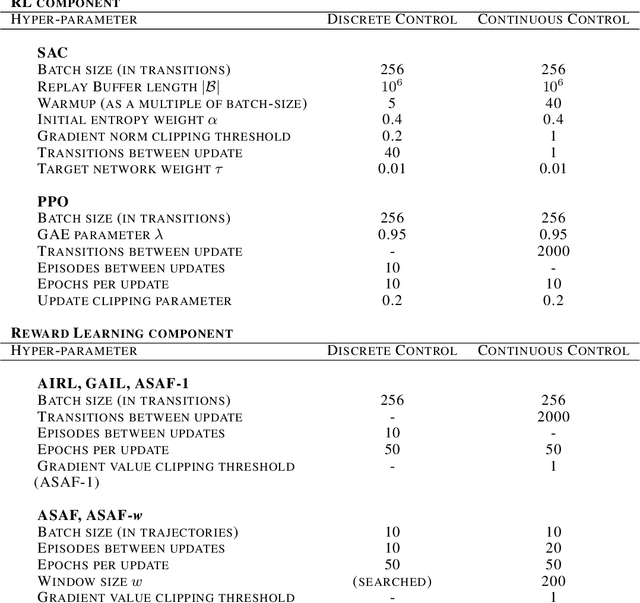
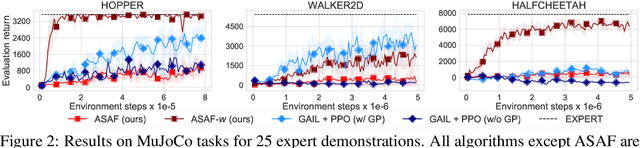
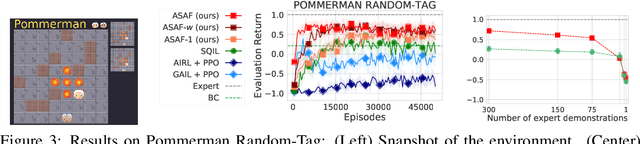
Adversarial imitation learning alternates between learning a discriminator -- which tells apart expert's demonstrations from generated ones -- and a generator's policy to produce trajectories that can fool this discriminator. This alternated optimization is known to be delicate in practice since it compounds unstable adversarial training with brittle and sample-inefficient reinforcement learning. We propose to remove the burden of the policy optimization steps by leveraging a novel discriminator formulation. Specifically, our discriminator is explicitly conditioned on two policies: the one from the previous generator's iteration and a learnable policy. When optimized, this discriminator directly learns the optimal generator's policy. Consequently, our discriminator's update solves the generator's optimization problem for free: learning a policy that imitates the expert does not require an additional optimization loop. This formulation effectively cuts by half the implementation and computational burden of adversarial imitation learning algorithms by removing the reinforcement learning phase altogether. We show on a variety of tasks that our simpler approach is competitive to prevalent imitation learning methods.
Surprisal-Triggered Conditional Computation with Neural Networks
Jun 02, 2020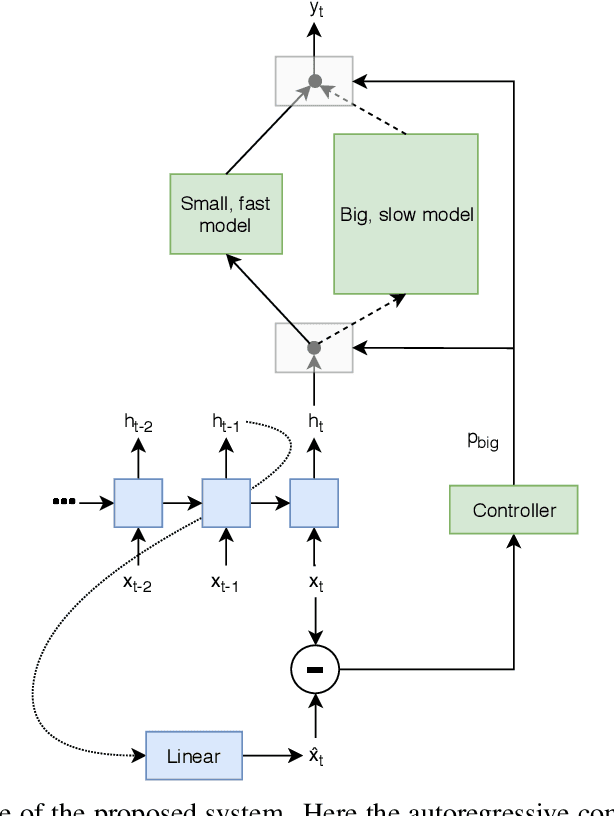

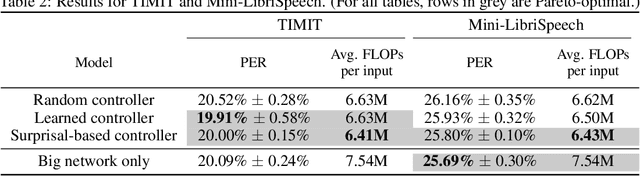
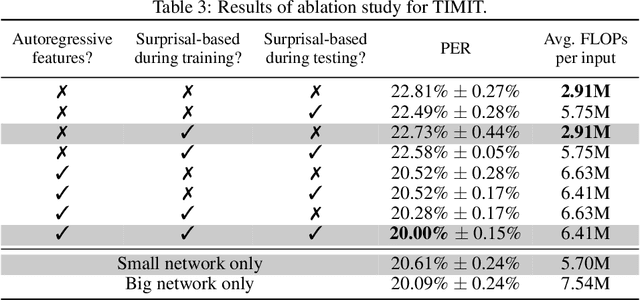
Autoregressive neural network models have been used successfully for sequence generation, feature extraction, and hypothesis scoring. This paper presents yet another use for these models: allocating more computation to more difficult inputs. In our model, an autoregressive model is used both to extract features and to predict observations in a stream of input observations. The surprisal of the input, measured as the negative log-likelihood of the current observation according to the autoregressive model, is used as a measure of input difficulty. This in turn determines whether a small, fast network, or a big, slow network, is used. Experiments on two speech recognition tasks show that our model can match the performance of a baseline in which the big network is always used with 15% fewer FLOPs.
Pix2Shape: Towards Unsupervised Learning of 3D Scenes from Images using a View-based Representation
Apr 17, 2020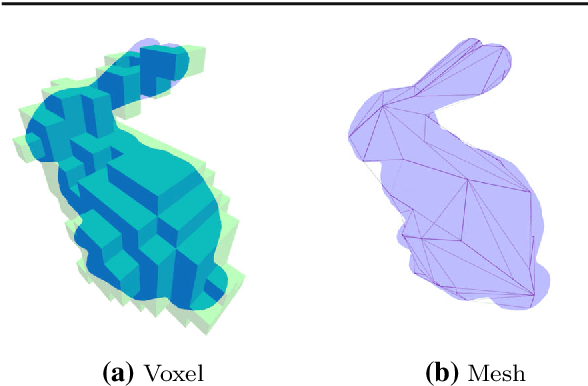
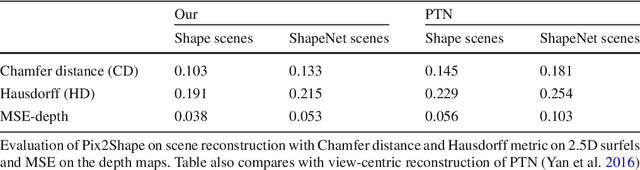

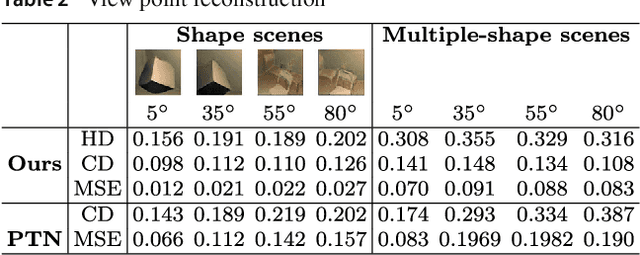
We infer and generate three-dimensional (3D) scene information from a single input image and without supervision. This problem is under-explored, with most prior work relying on supervision from, e.g., 3D ground-truth, multiple images of a scene, image silhouettes or key-points. We propose Pix2Shape, an approach to solve this problem with four components: (i) an encoder that infers the latent 3D representation from an image, (ii) a decoder that generates an explicit 2.5D surfel-based reconstruction of a scene from the latent code (iii) a differentiable renderer that synthesizes a 2D image from the surfel representation, and (iv) a critic network trained to discriminate between images generated by the decoder-renderer and those from a training distribution. Pix2Shape can generate complex 3D scenes that scale with the view-dependent on-screen resolution, unlike representations that capture world-space resolution, i.e., voxels or meshes. We show that Pix2Shape learns a consistent scene representation in its encoded latent space and that the decoder can then be applied to this latent representation in order to synthesize the scene from a novel viewpoint. We evaluate Pix2Shape with experiments on the ShapeNet dataset as well as on a novel benchmark we developed, called 3D-IQTT, to evaluate models based on their ability to enable 3d spatial reasoning. Qualitative and quantitative evaluation demonstrate Pix2Shape's ability to solve scene reconstruction, generation, and understanding tasks.
* This is a pre-print of an article published in International Journal of Computer Vision. The final authenticated version is available online at: https://doi.org/10.1007/s11263-020-01322-1
Pix2Shape -- Towards Unsupervised Learning of 3D Scenes from Images using a View-based Representation
Mar 23, 2020We infer and generate three-dimensional (3D) scene information from a single input image and without supervision. This problem is under-explored, with most prior work relying on supervision from, e.g., 3D ground-truth, multiple images of a scene, image silhouettes or key-points. We propose Pix2Shape, an approach to solve this problem with four components: (i) an encoder that infers the latent 3D representation from an image, (ii) a decoder that generates an explicit 2.5D surfel-based reconstruction of a scene from the latent code (iii) a differentiable renderer that synthesizes a 2D image from the surfel representation, and (iv) a critic network trained to discriminate between images generated by the decoder-renderer and those from a training distribution. Pix2Shape can generate complex 3D scenes that scale with the view-dependent on-screen resolution, unlike representations that capture world-space resolution, i.e., voxels or meshes. We show that Pix2Shape learns a consistent scene representation in its encoded latent space and that the decoder can then be applied to this latent representation in order to synthesize the scene from a novel viewpoint. We evaluate Pix2Shape with experiments on the ShapeNet dataset as well as on a novel benchmark we developed, called 3D-IQTT, to evaluate models based on their ability to enable 3d spatial reasoning. Qualitative and quantitative evaluation demonstrate Pix2Shape's ability to solve scene reconstruction, generation, and understanding tasks.
* This is a pre-print of an article published in International Journal of Computer Vision. The final authenticated version is available online at: https://doi.org/10.1007/s11263-020-01322-1