 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tutorial on Canonical Correlation Methods
Nov 07, 2017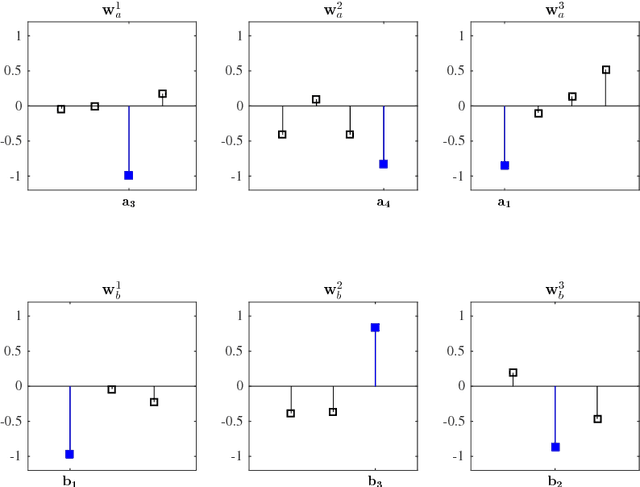
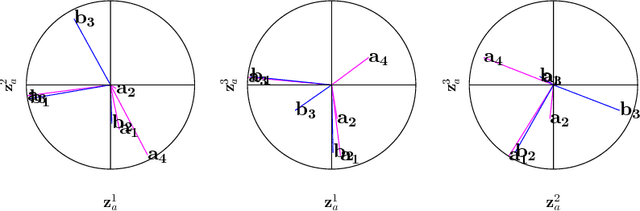
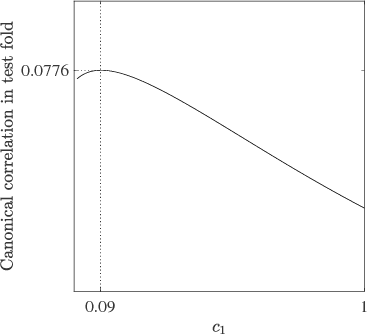
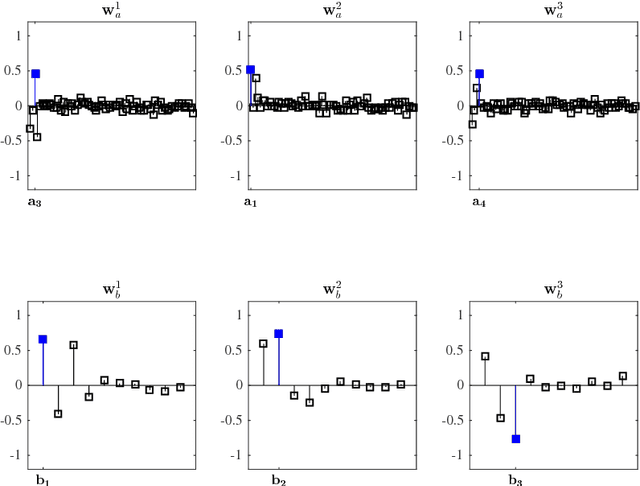
Canonical correlation analysis is a family of multivariate statistical methods for the analysis of paired sets of variables. Since its proposition, canonical correlation analysis has for instance been extended to extract relations between two sets of variables when the sample size is insufficient in relation to the data dimensionality, when the relations have been considered to be non-linear, and when the dimensionality is too large for human interpretation. This tutorial explains the theory of canonical correlation analysis including its regularised, kernel, and sparse variants. Additionally, the deep and Bayesian CCA extensions are briefly reviewed. Together with the numerical examples, this overview provides a coherent compendium on the applicability of the variants of canonical correlation analysis. By bringing together techniques for solving the optimisation problems, evaluating the statistical significance and generalisability of the canonical correlation model, and interpreting the relations, we hope that this article can serve as a hands-on tool for applying canonical correlation methods in data analysis.
* 33 pages
Principled Non-Linear Feature Selection
Feb 18, 2014

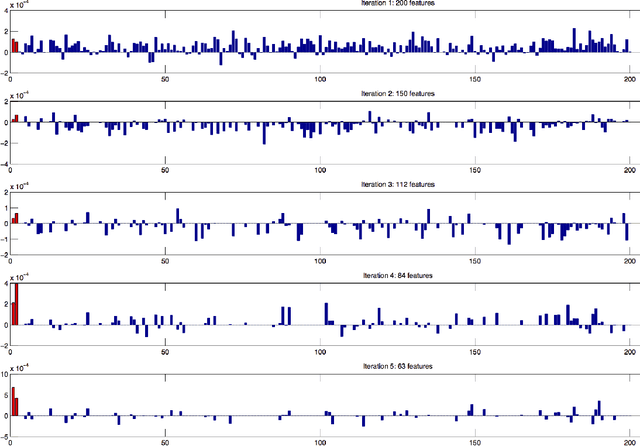
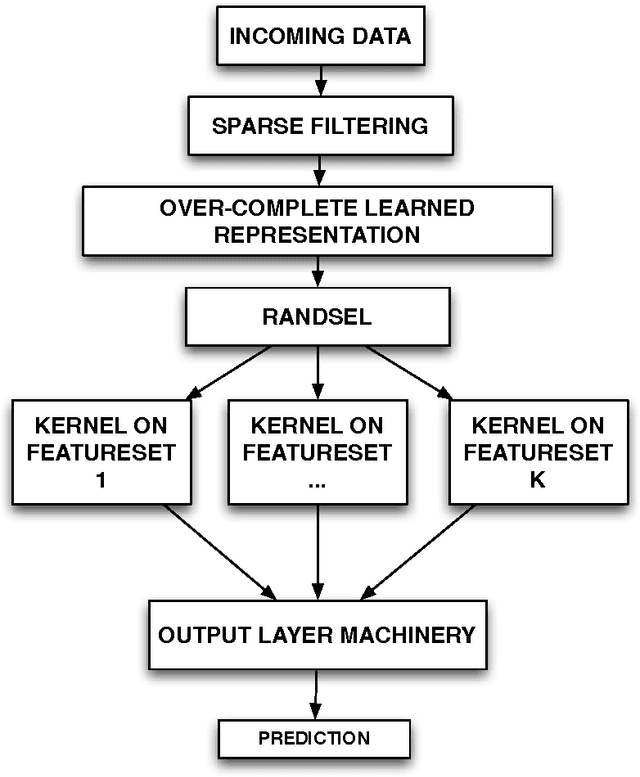
Recent non-linear feature selection approaches employing greedy optimisation of Centred Kernel Target Alignment(KTA) exhibit strong results in terms of generalisation accuracy and sparsity. However, they are computationally prohibitive for large datasets. We propose randSel, a randomised feature selection algorithm, with attractive scaling properties. Our theoretical analysis of randSel provides strong probabilistic guarantees for correct identification of relevant features. RandSel's characteristics make it an ideal candidate for identifying informative learned representations. We've conducted experimentation to establish the performance of this approach, and present encouraging results, including a 3rd position result in the recent ICML black box learning challenge as well as competitive results for signal peptide prediction, an important problem in bioinformatics.
Learning Non-Linear Feature Maps
Nov 22, 2013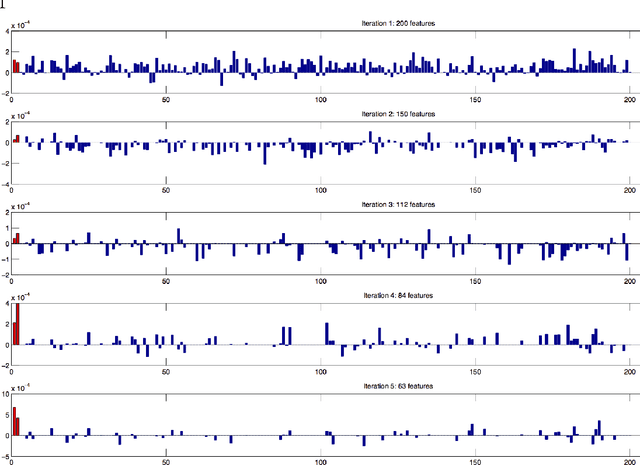
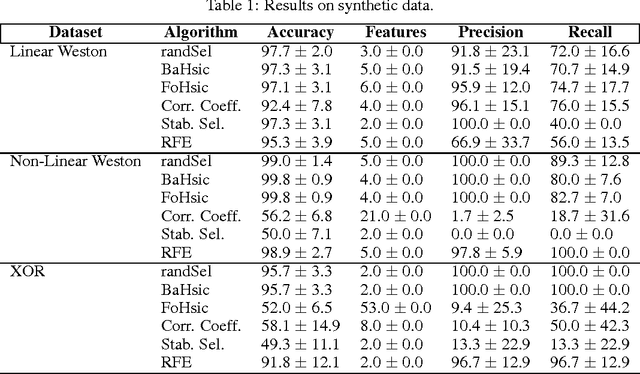
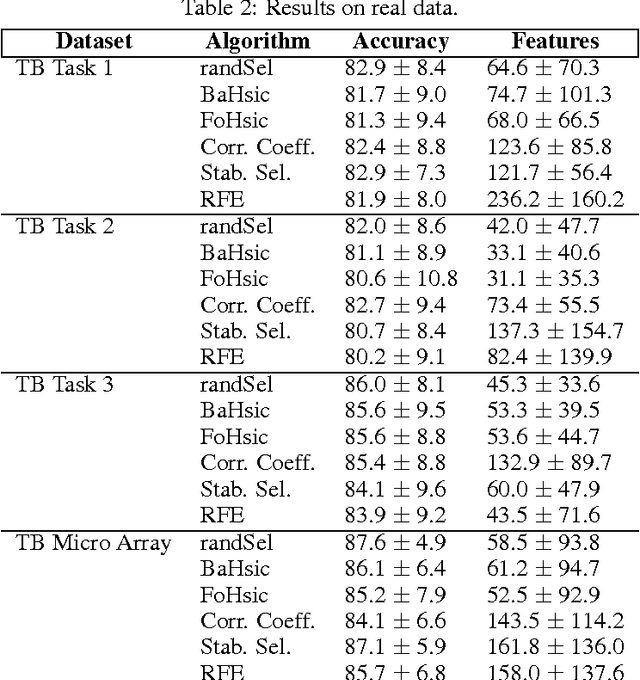
Feature selection plays a pivotal role in learning, particularly in areas were parsimonious features can provide insight into the underlying process, such as biology. Recent approaches for non-linear feature selection employing greedy optimisation of Centred Kernel Target Alignment(KTA), while exhibiting strong results in terms of generalisation accuracy and sparsity, can become computationally prohibitive for high-dimensional datasets. We propose randSel, a randomised feature selection algorithm, with attractive scaling properties. Our theoretical analysis of randSel provides strong probabilistic guarantees for the correct identification of relevant features. Experimental results on real and artificial data, show that the method successfully identifies effective features, performing better than a number of competitive approaches.