 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePNEL: Pointer Network based End-To-End Entity Linking over Knowledge Graphs
Aug 31, 2020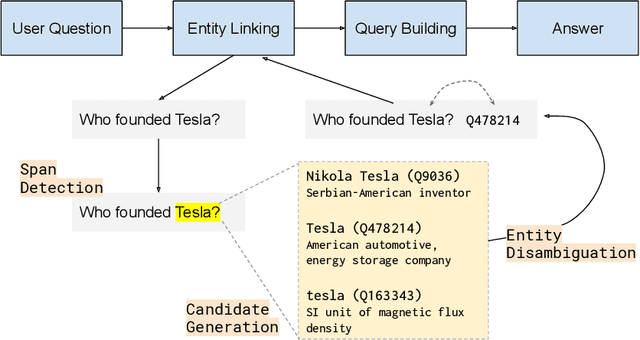
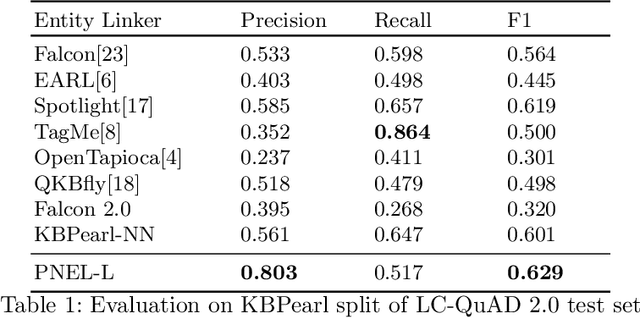
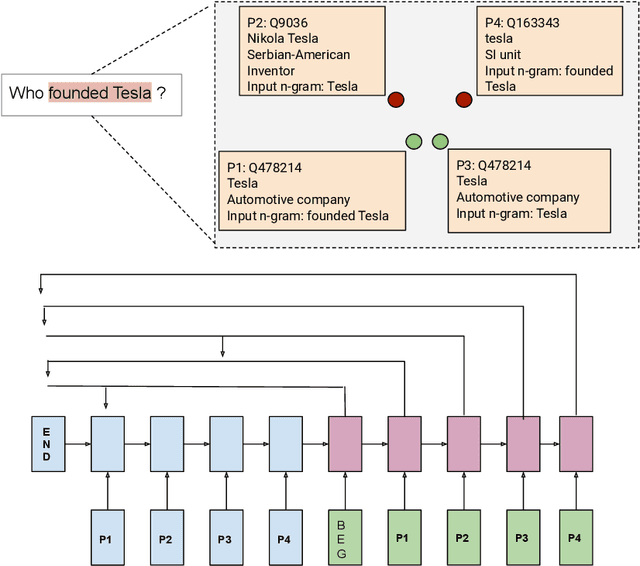
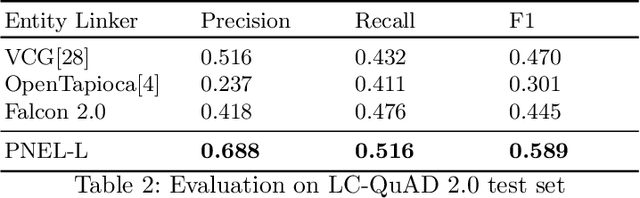
Question Answering systems are generally modelled as a pipeline consisting of a sequence of steps. In such a pipeline, Entity Linking (EL) is often the first step. Several EL models first perform span detection and then entity disambiguation. In such models errors from the span detection phase cascade to later steps and result in a drop of overall accuracy. Moreover, lack of gold entity spans in training data is a limiting factor for span detector training. Hence the movement towards end-to-end EL models began where no separate span detection step is involved. In this work we present a novel approach to end-to-end EL by applying the popular Pointer Network model, which achieves competitive performance. We demonstrate this in our evaluation over three datasets on the Wikidata Knowledge Graph.
Harvesting Information from Captions for Weakly Supervised Semantic Segmentation
May 16, 2019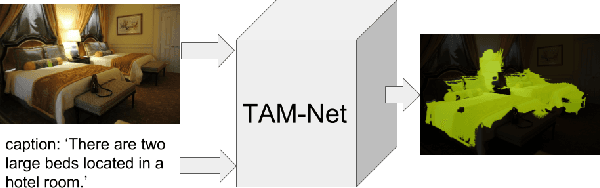
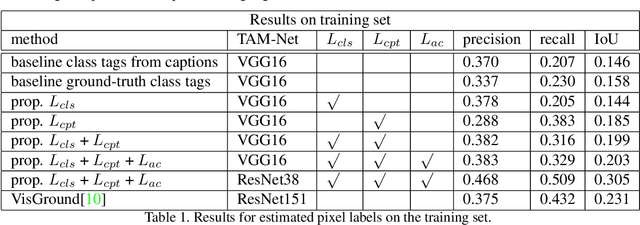
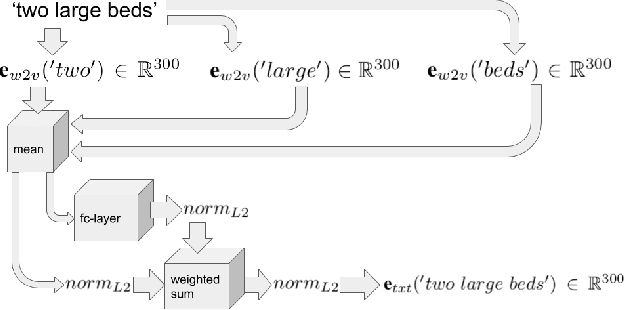

Since acquiring pixel-wise annotations for training convolutional neural networks for semantic image segmentation is time-consuming, weakly supervised approaches that only require class tags have been proposed. In this work, we propose another form of supervision, namely image captions as they can be found on the Internet. These captions have two advantages. They do not require additional curation as it is the case for the clean class tags used by current weakly supervised approaches and they provide textual context for the classes present in an image. To leverage such textual context, we deploy a multi-modal network that learns a joint embedding of the visual representation of the image and the textual representation of the caption. The network estimates text activation maps (TAMs) for class names as well as compound concepts, i.e. combinations of nouns and their attributes. The TAMs of compound concepts describing classes of interest substantially improve the quality of the estimated class activation maps which are then used to train a network for semantic segmentation. We evaluate our method on the COCO dataset where it achieves state of the art results for weakly supervised image segmentation.
EARL: Joint Entity and Relation Linking for Question Answering over Knowledge Graphs
Jun 25, 2018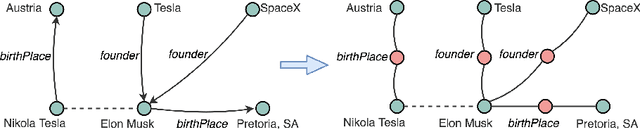
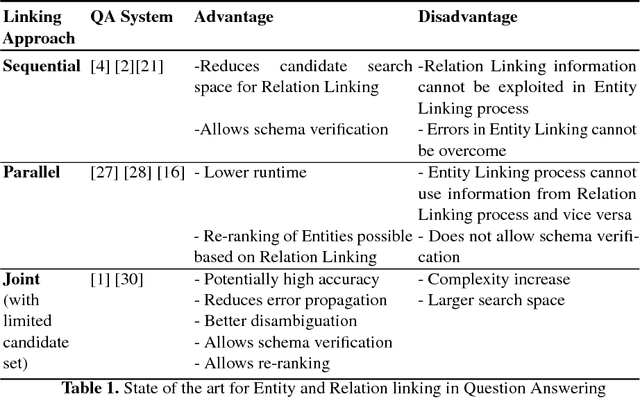
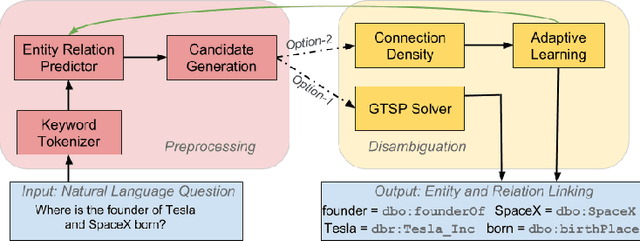
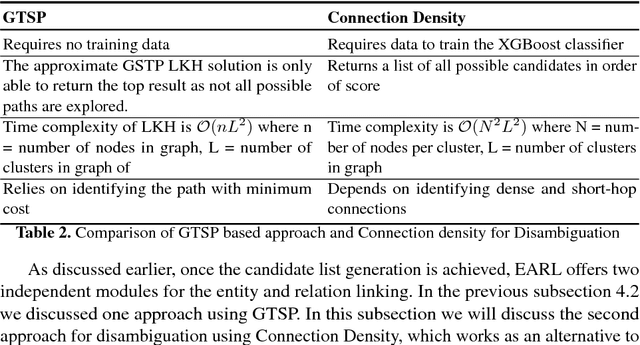
Many question answering systems over knowledge graphs rely on entity and relation linking components in order to connect the natural language input to the underlying knowledge graph. Traditionally, entity linking and relation linking have been performed either as dependent sequential tasks or as independent parallel tasks. In this paper, we propose a framework called EARL, which performs entity linking and relation linking as a joint task. EARL implements two different solution strategies for which we provide a comparative analysis in this paper: The first strategy is a formalisation of the joint entity and relation linking tasks as an instance of the Generalised Travelling Salesman Problem (GTSP). In order to be computationally feasible, we employ approximate GTSP solvers. The second strategy uses machine learning in order to exploit the connection density between nodes in the knowledge graph. It relies on three base features and re-ranking steps in order to predict entities and relations. We compare the strategies and evaluate them on a dataset with 5000 questions. Both strategies significantly outperform the current state-of-the-art approaches for entity and relation linking.