 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining PRNU and noiseprint for robust and efficient device source identification
Jan 17, 2020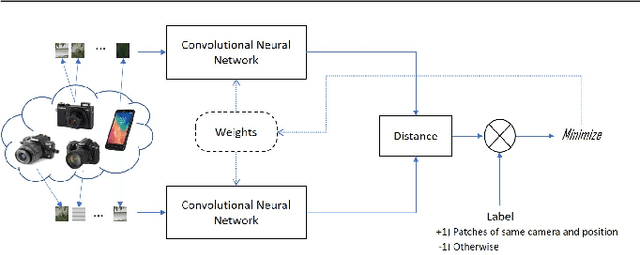

PRNU-based image processing is a key asset in digital multimedia forensics. It allows for reliable device identification and effective detection and localization of image forgeries, in very general conditions. However, performance impairs significantly in challenging conditions involving low quality and quantity of data. These include working on compressed and cropped images, or estimating the camera PRNU pattern based on only a few images. To boost the performance of PRNU-based analyses in such conditions we propose to leverage the image noiseprint, a recently proposed camera-model fingerprint that has proved effective for several forensic tasks. Numerical experiments on datasets widely used for source identification prove that the proposed method ensures a significant performance improvement in a wide range of challenging situations.
SpoC: Spoofing Camera Fingerprints
Nov 27, 2019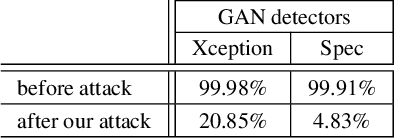
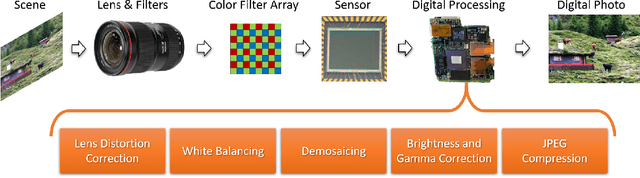
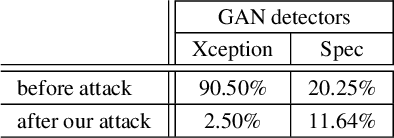
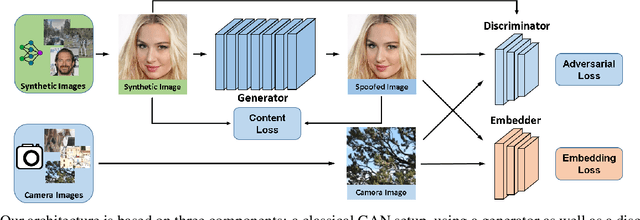
Thanks to the fast progress in synthetic media generation, creating realistic false images has become very easy. Such images can be used to wrap rich fake news with enhanced credibility, spawning a new wave of high-impact, high-risk misinformation campaigns. Therefore, there is a fast-growing interest in reliable detectors of manipulated media. The most powerful detectors, to date, rely on the subtle traces left by any device on all images acquired by it. In particular, due to proprietary in-camera processes, like demosaicing or compression, each camera model leaves trademark traces that can be exploited for forensic analyses. The absence or distortion of such traces in the target image is a strong hint of manipulation. In this paper, we challenge such detectors to gain better insight into their vulnerabilities. This is an important study in order to build better forgery detectors able to face malicious attacks. Our proposal consists of a GAN-based approach that injects camera traces into synthetic images. Given a GANgenerated image, we insert the traces of a specific camera model into it and deceive state-of-the-art detectors into believing the image was acquired by that model. Likewise, we deceive independent detectors of synthetic GAN images into believing the image is real. Experiments prove the effectiveness of the proposed method in a wide array of conditions. Moreover, no prior information on the attacked detectors is needed, but only sample images from the target camera.
FaceForensics++: Learning to Detect Manipulated Facial Images
Jan 25, 2019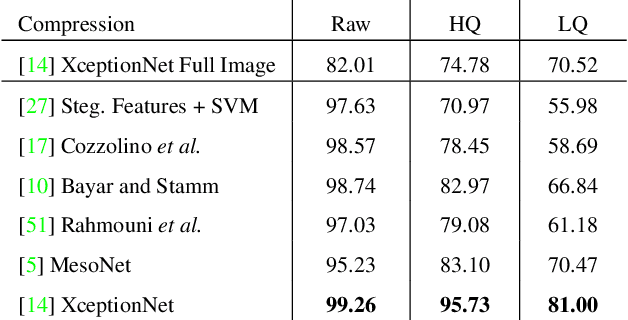

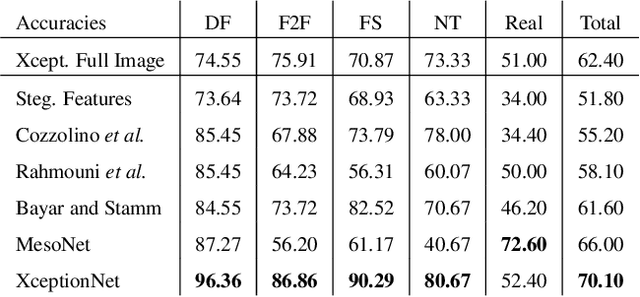
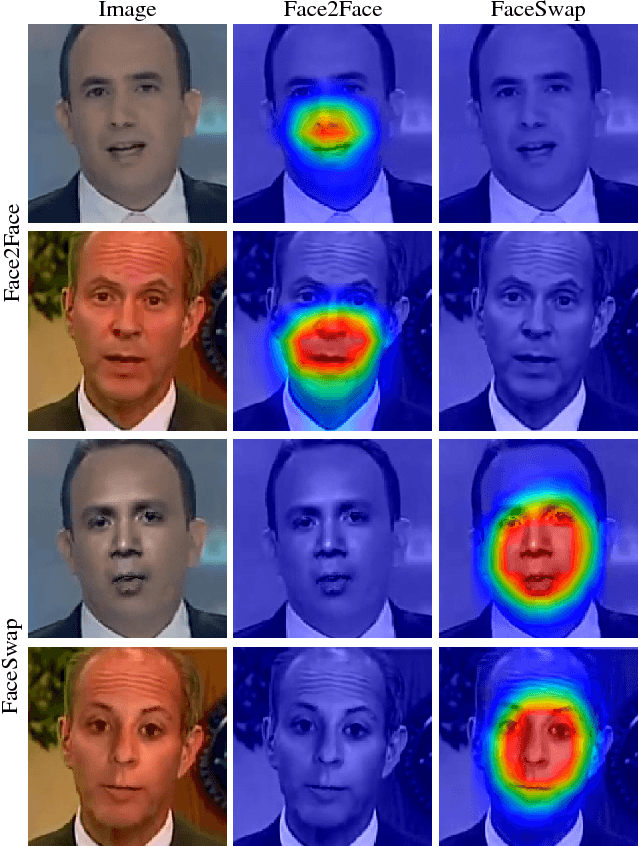
The rapid progress in synthetic image generation and manipulation has now come to a point where it raises significant concerns on the implication on the society. At best, this leads to a loss of trust in digital content, but it might even cause further harm by spreading false information and the creation of fake news. In this paper, we examine the realism of state-of-the-art image manipulations, and how difficult it is to detect them - either automatically or by humans. In particular, we focus on DeepFakes, Face2Face, and FaceSwap as prominent representatives for facial manipulations. We create more than half a million manipulated images respectively for each approach. The resulting publicly available dataset is at least an order of magnitude larger than comparable alternatives and it enables us to train data-driven forgery detectors in a supervised fashion. We show that the use of additional domain specific knowledge improves forgery detection to an unprecedented accuracy, even in the presence of strong compression. By conducting a series of thorough experiments, we quantify the differences between classical approaches, novel deep learning approaches, and the performance of human observers.
ForensicTransfer: Weakly-supervised Domain Adaptation for Forgery Detection
Dec 06, 2018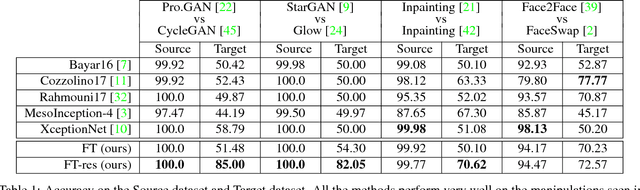


Distinguishing fakes from real images is becoming increasingly difficult as new sophisticated image manipulation approaches come out by the day. Convolutional neural networks (CNN) show excellent performance in detecting image manipulations when they are trained on a specific forgery method. However, on examples from unseen manipulation approaches, their performance drops significantly. To address this limitation in transferability, we introduce ForensicTransfer. ForensicTransfer tackles two challenges in multimedia forensics. First, we devise a learning-based forensic detector which adapts well to new domains, i.e., novel manipulation methods. Second we handle scenarios where only a handful of fake examples are available during training. To this end, we learn a forensic embedding that can be used to distinguish between real and fake imagery. We are using a new autoencoder-based architecture which enforces activations in different parts of a latent vector for the real and fake classes. Together with the constraint of correct reconstruction this ensures that the latent space keeps all the relevant information about the nature of the image. Therefore, the learned embedding acts as a form of anomaly detector; namely, an image manipulated from an unseen method will be detected as fake provided it maps sufficiently far away from the cluster of real images. Comparing with prior works, ForensicTransfer shows significant improvements in transferability, which we demonstrate in a series of experiments on cutting-edge benchmarks. For instance, on unseen examples, we achieve up to 80-85% in terms of accuracy compared to 50-59%, and with only a handful of seen examples, our performance already reaches around 95%.
Guided patch-wise nonlocal SAR despeckling
Nov 28, 2018

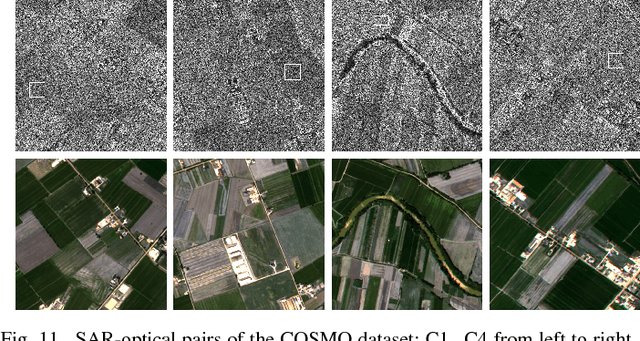

We propose a new method for SAR image despeckling which leverages information drawn from co-registered optical imagery. Filtering is performed by plain patch-wise nonlocal means, operating exclusively on SAR data. However, the filtering weights are computed by taking into account also the optical guide, which is much cleaner than the SAR data, and hence more discriminative. To avoid injecting optical-domain information into the filtered image, a SAR-domain statistical test is preliminarily performed to reject right away any risky predictor. Experiments on two SAR-optical datasets prove the proposed method to suppress very effectively the speckle, preserving structural details, and without introducing visible filtering artifacts. Overall, the proposed method compares favourably with all state-of-the-art despeckling filters, and also with our own previous optical-guided filter.
Camera-based Image Forgery Localization using Convolutional Neural Networks
Aug 29, 2018
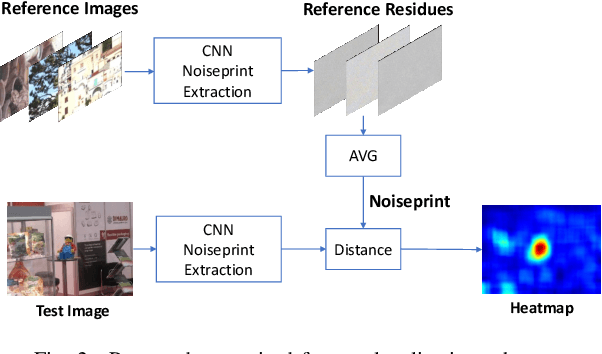
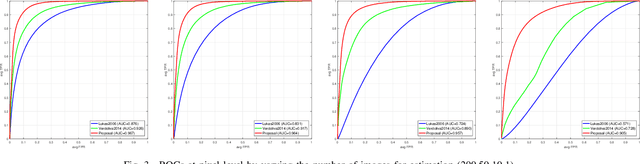
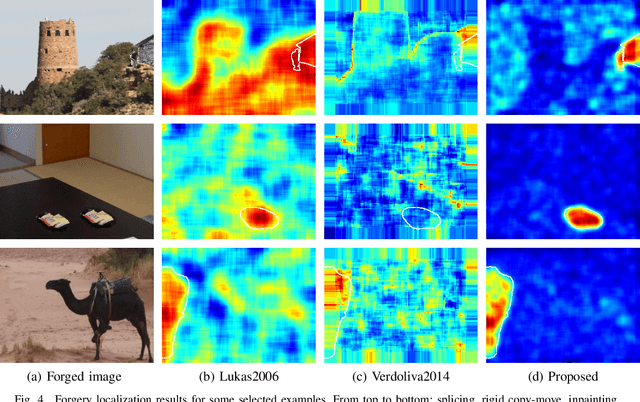
Camera fingerprints are precious tools for a number of image forensics tasks. A well-known example is the photo response non-uniformity (PRNU) noise pattern, a powerful device fingerprint. Here, to address the image forgery localization problem, we rely on noiseprint, a recently proposed CNN-based camera model fingerprint. The CNN is trained to minimize the distance between same-model patches, and maximize the distance otherwise. As a result, the noiseprint accounts for model-related artifacts just like the PRNU accounts for device-related non-uniformities. However, unlike the PRNU, it is only mildly affected by residuals of high-level scene content. The experiments show that the proposed noiseprint-based forgery localization method improves over the PRNU-based reference.
Noiseprint: a CNN-based camera model fingerprint
Aug 25, 2018



Forensic analyses of digital images rely heavily on the traces of in-camera and out-camera processes left on the acquired images. Such traces represent a sort of camera fingerprint. If one is able to recover them, by suppressing the high-level scene content and other disturbances, a number of forensic tasks can be easily accomplished. A notable example is the PRNU pattern, which can be regarded as a device fingerprint, and has received great attention in multimedia forensics. In this paper we propose a method to extract a camera model fingerprint, called noiseprint, where the scene content is largely suppressed and model-related artifacts are enhanced. This is obtained by means of a Siamese network, which is trained with pairs of image patches coming from the same (label +1) or different (label -1) cameras. Although noiseprints can be used for a large variety of forensic tasks, here we focus on image forgery localization. Experiments on several datasets widespread in the forensic community show noiseprint-based methods to provide state-of-the-art performance.
FaceForensics: A Large-scale Video Dataset for Forgery Detection in Human Faces
Mar 24, 2018
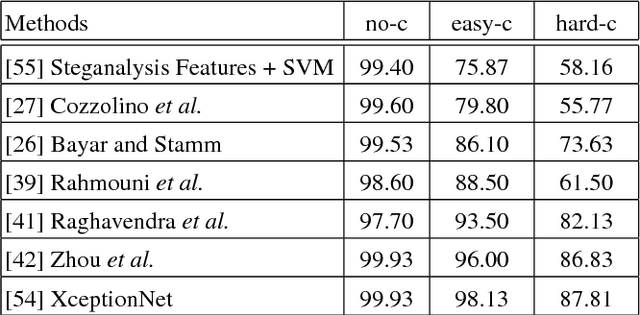

With recent advances in computer vision and graphics, it is now possible to generate videos with extremely realistic synthetic faces, even in real time. Countless applications are possible, some of which raise a legitimate alarm, calling for reliable detectors of fake videos. In fact, distinguishing between original and manipulated video can be a challenge for humans and computers alike, especially when the videos are compressed or have low resolution, as it often happens on social networks. Research on the detection of face manipulations has been seriously hampered by the lack of adequate datasets. To this end, we introduce a novel face manipulation dataset of about half a million edited images (from over 1000 videos). The manipulations have been generated with a state-of-the-art face editing approach. It exceeds all existing video manipulation datasets by at least an order of magnitude. Using our new dataset, we introduce benchmarks for classical image forensic tasks, including classification and segmentation, considering videos compressed at various quality levels. In addition, we introduce a benchmark evaluation for creating indistinguishable forgeries with known ground truth; for instance with generative refinement models.
Target-adaptive CNN-based pansharpening
Feb 23, 2018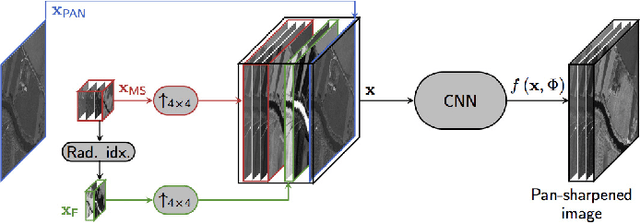


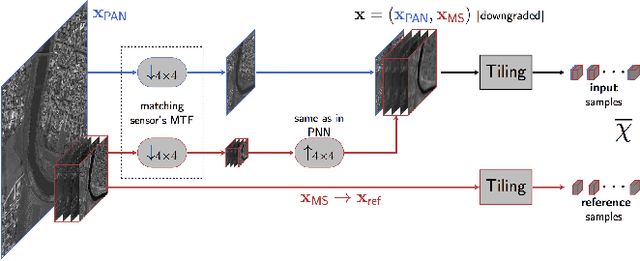
We recently proposed a convolutional neural network (CNN) for remote sensing image pansharpening obtaining a significant performance gain over the state of the art. In this paper, we explore a number of architectural and training variations to this baseline, achieving further performance gains with a lightweight network which trains very fast. Leveraging on this latter property, we propose a target-adaptive usage modality which ensures a very good performance also in the presence of a mismatch w.r.t. the training set, and even across different sensors. The proposed method, published online as an off-the-shelf software tool, allows users to perform fast and high-quality CNN-based pansharpening of their own target images on general-purpose hardware.
Autoencoder with recurrent neural networks for video forgery detection
Aug 29, 2017
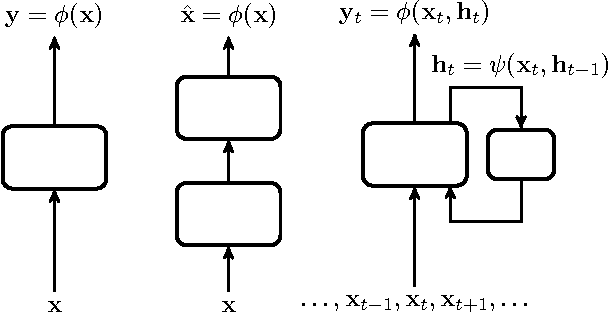
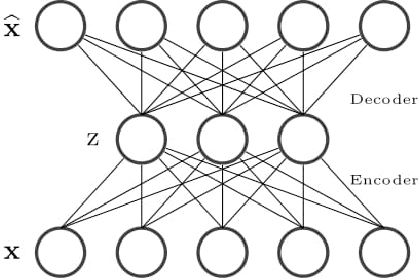
Video forgery detection is becoming an important issue in recent years, because modern editing software provide powerful and easy-to-use tools to manipulate videos. In this paper we propose to perform detection by means of deep learning, with an architecture based on autoencoders and recurrent neural networks. A training phase on a few pristine frames allows the autoencoder to learn an intrinsic model of the source. Then, forged material is singled out as anomalous, as it does not fit the learned model, and is encoded with a large reconstruction error. Recursive networks, implemented with the long short-term memory model, are used to exploit temporal dependencies. Preliminary results on forged videos show the potential of this approach.