 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Examples for $k$-Nearest Neighbor Classifiers Based on Higher-Order Voronoi Diagrams
Nov 19, 2020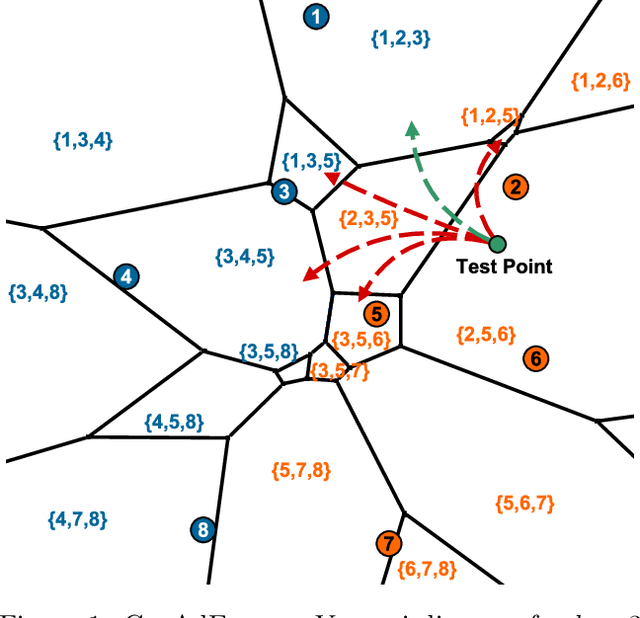
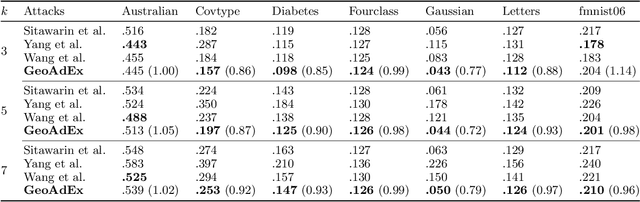
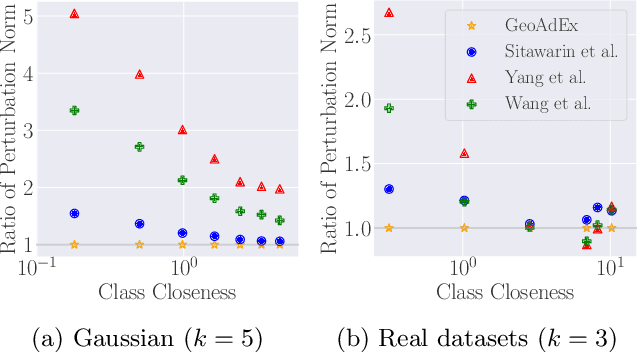
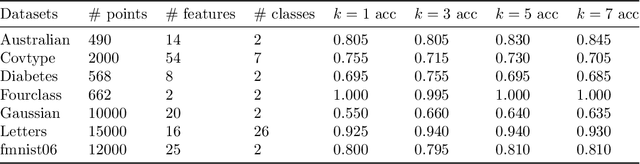
Adversarial examples are a widely studied phenomenon in machine learning models. While most of the attention has been focused on neural networks, other practical models also suffer from this issue. In this work, we propose an algorithm for evaluating the adversarial robustness of $k$-nearest neighbor classification, i.e., finding a minimum-norm adversarial example. Diverging from previous proposals, we take a geometric approach by performing a search that expands outwards from a given input point. On a high level, the search radius expands to the nearby Voronoi cells until we find a cell that classifies differently from the input point. To scale the algorithm to a large $k$, we introduce approximation steps that find perturbations with smaller norm, compared to the baselines, in a variety of datasets. Furthermore, we analyze the structural properties of a dataset where our approach outperforms the competition.
Minority Reports Defense: Defending Against Adversarial Patches
Apr 28, 2020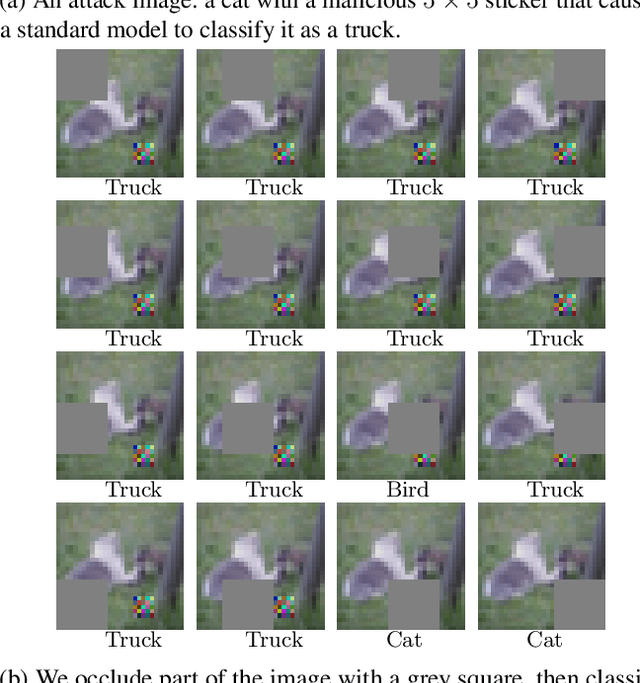
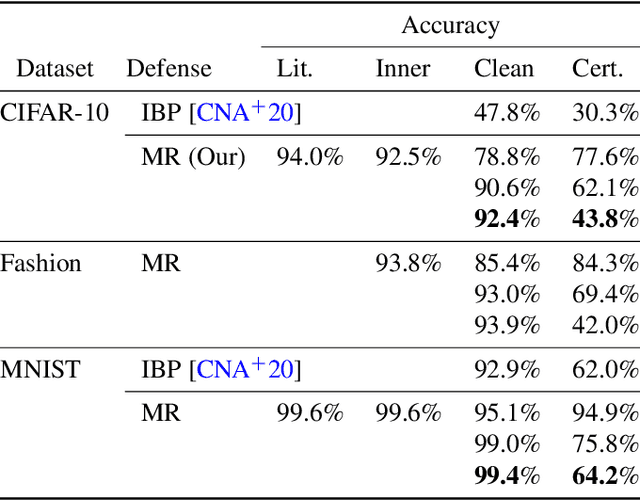
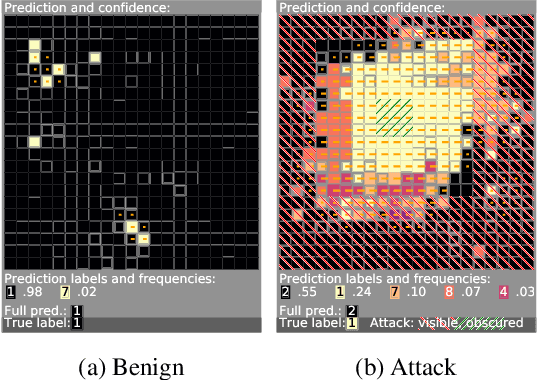
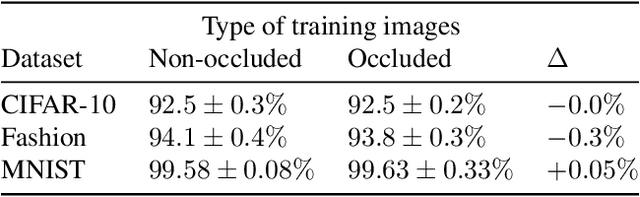
Deep learning image classification is vulnerable to adversarial attack, even if the attacker changes just a small patch of the image. We propose a defense against patch attacks based on partially occluding the image around each candidate patch location, so that a few occlusions each completely hide the patch. We demonstrate on CIFAR-10, Fashion MNIST, and MNIST that our defense provides certified security against patch attacks of a certain size.
Improving Adversarial Robustness Through Progressive Hardening
Mar 18, 2020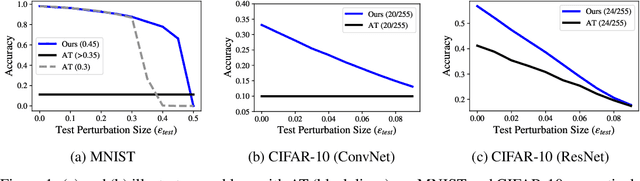
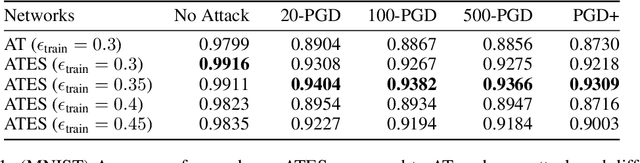

Adversarial training (AT) has become a popular choice for training robust networks. However, by virtue of its formulation, AT tends to sacrifice clean accuracy heavily in favor of robustness. Furthermore, AT with a large perturbation budget can cause models to get stuck at poor local minima and behave like a constant function, always predicting the same class. To address the above concerns we propose Adversarial Training with Early Stopping (ATES). The design of ATES is guided by principles from curriculum learning that emphasizes on starting "easy" and gradually ramping up on the "difficulty" of training. We do so by early stopping the adversarial example generation step in AT, progressively increasing difficulty of the samples the network trains on. This stabilizes network training even for large perturbation budgets and allows the network to operate at a better clean accuracy versus robustness trade-off curve compared to AT. Functionally, this leads to a significant improvement in both clean accuracy and robustness for ATES models.
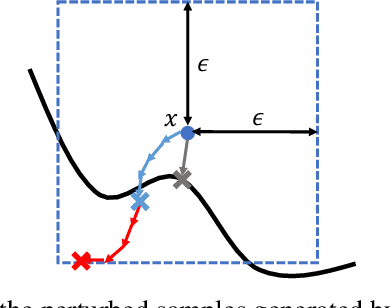
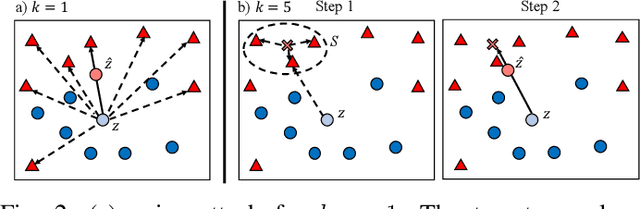
Minimum-Norm Adversarial Examples on KNN and KNN-Based Models
Mar 14, 2020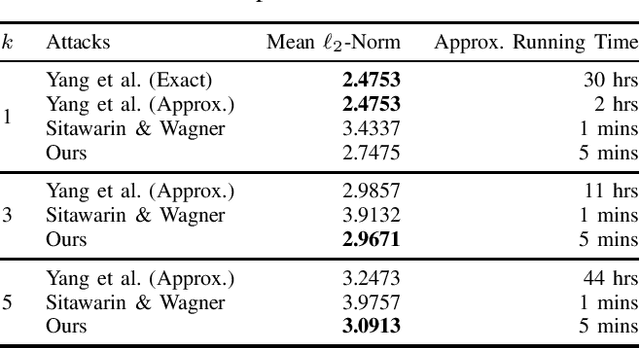
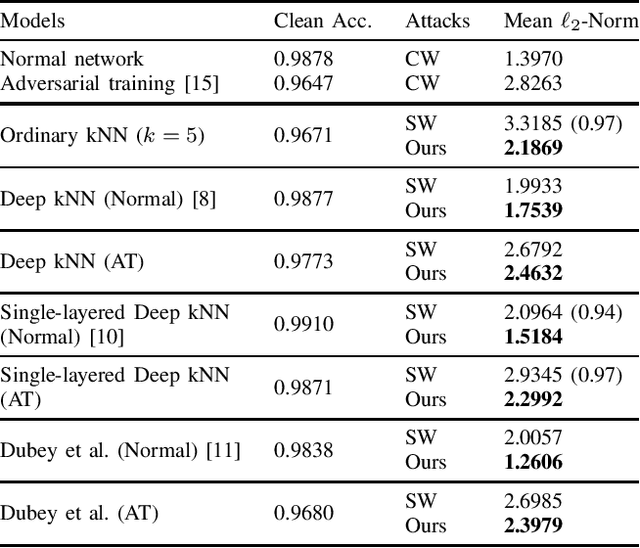
We study the robustness against adversarial examples of kNN classifiers and classifiers that combine kNN with neural networks. The main difficulty lies in the fact that finding an optimal attack on kNN is intractable for typical datasets. In this work, we propose a gradient-based attack on kNN and kNN-based defenses, inspired by the previous work by Sitawarin & Wagner [1]. We demonstrate that our attack outperforms their method on all of the models we tested with only a minimal increase in the computation time. The attack also beats the state-of-the-art attack [2] on kNN when k > 1 using less than 1% of its running time. We hope that this attack can be used as a new baseline for evaluating the robustness of kNN and its variants.
Stateful Detection of Black-Box Adversarial Attacks
Jul 12, 2019
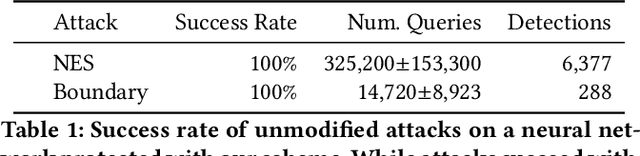
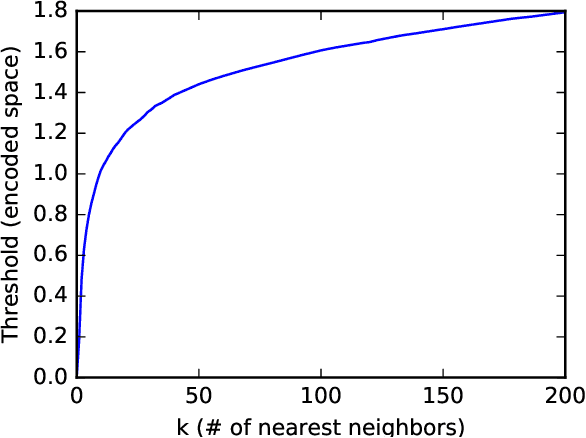
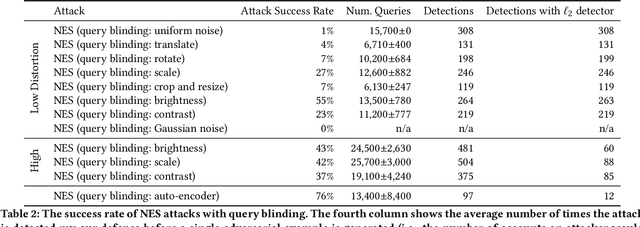
The problem of adversarial examples, evasion attacks on machine learning classifiers, has proven extremely difficult to solve. This is true even when, as is the case in many practical settings, the classifier is hosted as a remote service and so the adversary does not have direct access to the model parameters. This paper argues that in such settings, defenders have a much larger space of actions than have been previously explored. Specifically, we deviate from the implicit assumption made by prior work that a defense must be a stateless function that operates on individual examples, and explore the possibility for stateful defenses. To begin, we develop a defense designed to detect the process of adversarial example generation. By keeping a history of the past queries, a defender can try to identify when a sequence of queries appears to be for the purpose of generating an adversarial example. We then introduce query blinding, a new class of attacks designed to bypass defenses that rely on such a defense approach. We believe that expanding the study of adversarial examples from stateless classifiers to stateful systems is not only more realistic for many black-box settings, but also gives the defender a much-needed advantage in responding to the adversary.
Defending Against Adversarial Examples with K-Nearest Neighbor
Jun 23, 2019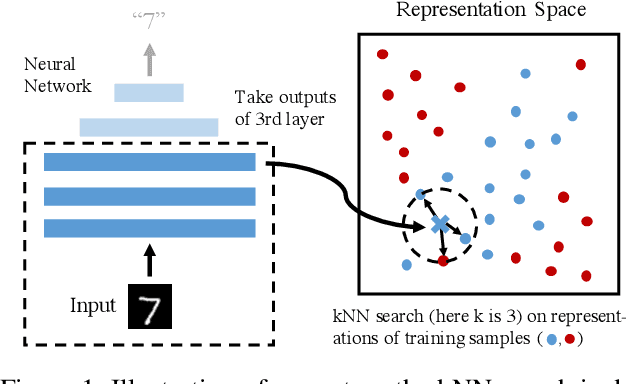

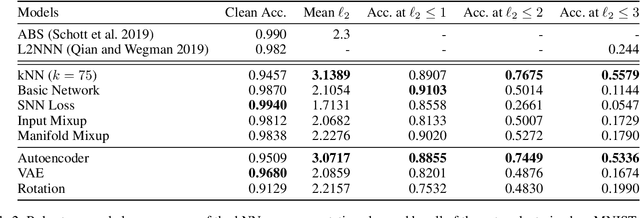
Robustness is an increasingly important property of machine learning models as they become more and more prevalent. We propose a defense against adversarial examples based on a k-nearest neighbor (kNN) on the intermediate activation of neural networks. Our scheme surpasses state-of-the-art defenses on MNIST and CIFAR-10 against l2-perturbation by a significant margin. With our models, the mean perturbation norm required to fool our MNIST model is 3.07 and 2.30 on CIFAR-10. Additionally, we propose a simple certifiable lower bound on the l2-norm of the adversarial perturbation using a more specific version of our scheme, a 1-NN on representations learned by a Lipschitz network. Our model provides a nontrivial average lower bound of the perturbation norm, comparable to other schemes on MNIST with similar clean accuracy.
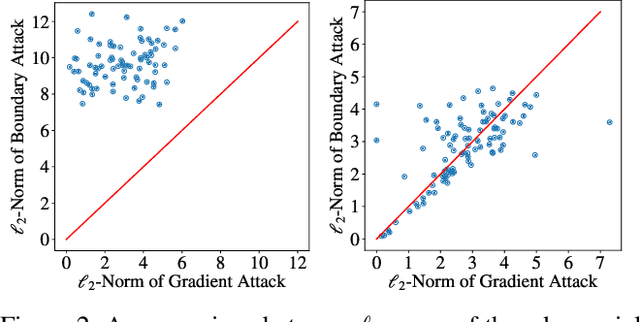
On the Robustness of Deep K-Nearest Neighbors
Mar 20, 2019
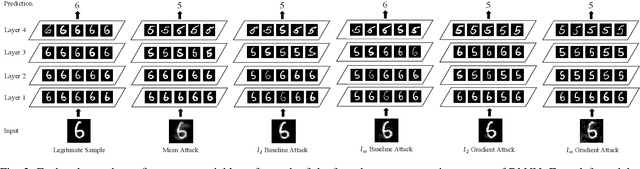
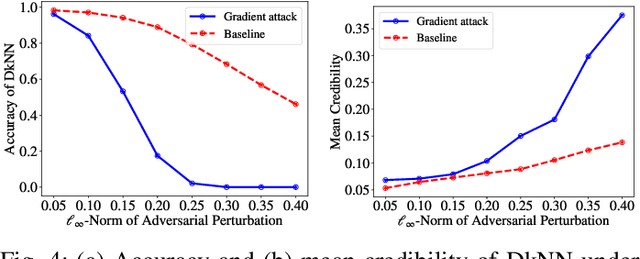
Despite a large amount of attention on adversarial examples, very few works have demonstrated an effective defense against this threat. We examine Deep k-Nearest Neighbor (DkNN), a proposed defense that combines k-Nearest Neighbor (kNN) and deep learning to improve the model's robustness to adversarial examples. It is challenging to evaluate the robustness of this scheme due to a lack of efficient algorithm for attacking kNN classifiers with large k and high-dimensional data. We propose a heuristic attack that allows us to use gradient descent to find adversarial examples for kNN classifiers, and then apply it to attack the DkNN defense as well. Results suggest that our attack is moderately stronger than any naive attack on kNN and significantly outperforms other attacks on DkNN.
Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples
Jul 31, 2018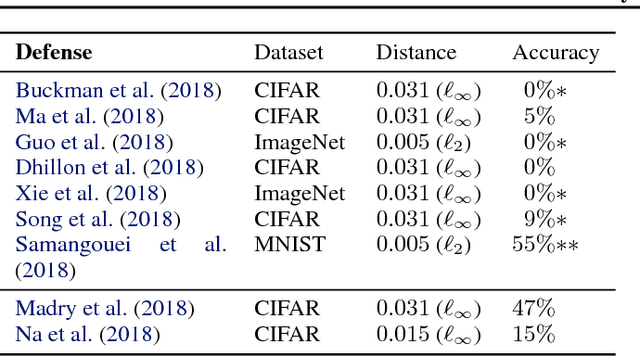
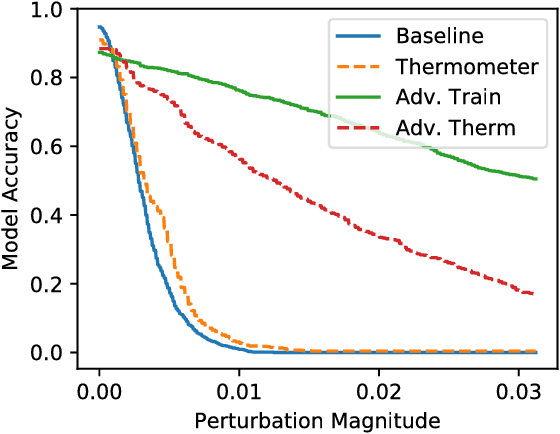

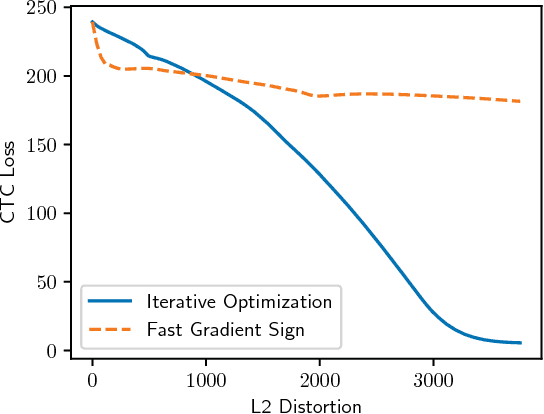
We identify obfuscated gradients, a kind of gradient masking, as a phenomenon that leads to a false sense of security in defenses against adversarial examples. While defenses that cause obfuscated gradients appear to defeat iterative optimization-based attacks, we find defenses relying on this effect can be circumvented. We describe characteristic behaviors of defenses exhibiting the effect, and for each of the three types of obfuscated gradients we discover, we develop attack techniques to overcome it. In a case study, examining non-certified white-box-secure defenses at ICLR 2018, we find obfuscated gradients are a common occurrence, with 7 of 9 defenses relying on obfuscated gradients. Our new attacks successfully circumvent 6 completely, and 1 partially, in the original threat model each paper considers.
Audio Adversarial Examples: Targeted Attacks on Speech-to-Text
Mar 30, 2018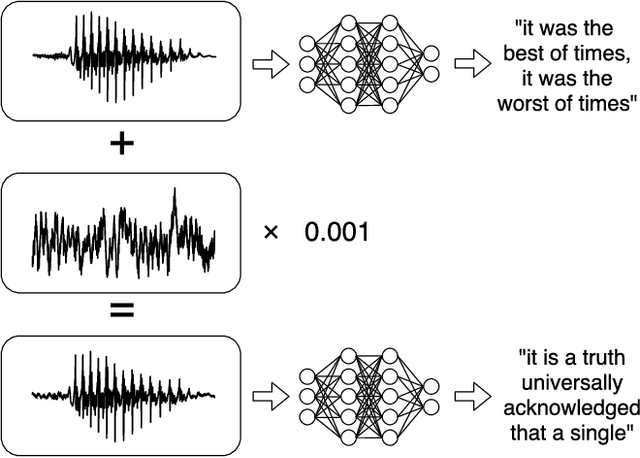

We construct targeted audio adversarial examples on automatic speech recognition. Given any audio waveform, we can produce another that is over 99.9% similar, but transcribes as any phrase we choose (recognizing up to 50 characters per second of audio). We apply our white-box iterative optimization-based attack to Mozilla's implementation DeepSpeech end-to-end, and show it has a 100% success rate. The feasibility of this attack introduce a new domain to study adversarial examples.
MagNet and "Efficient Defenses Against Adversarial Attacks" are Not Robust to Adversarial Examples
Nov 22, 2017



MagNet and "Efficient Defenses..." were recently proposed as a defense to adversarial examples. We find that we can construct adversarial examples that defeat these defenses with only a slight increase in distortion.