 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Using Machine Translation Techniques to Induce Multilingual Lexica of Discourse Markers
Mar 31, 2015Discourse markers are universal linguistic events subject to language variation. Although an extensive literature has already reported language specific traits of these events, little has been said on their cross-language behavior and on building an inventory of multilingual lexica of discourse markers. This work describes new methods and approaches for the description, classification, and annotation of discourse markers in the specific domain of the Europarl corpus. The study of discourse markers in the context of translation is crucial due to the idiomatic nature of these structures. Multilingual lexica together with the functional analysis of such structures are useful tools for the hard task of translating discourse markers into possible equivalents from one language to another. Using Daniel Marcu's validated discourse markers for English, extracted from the Brown Corpus, our purpose is to build multilingual lexica of discourse markers for other languages, based on machine translation techniques. The major assumption in this study is that the usage of a discourse marker is independent of the language, i.e., the rhetorical function of a discourse marker in a sentence in one language is equivalent to the rhetorical function of the same discourse marker in another language.
On the Application of Generic Summarization Algorithms to Music
Jun 18, 2014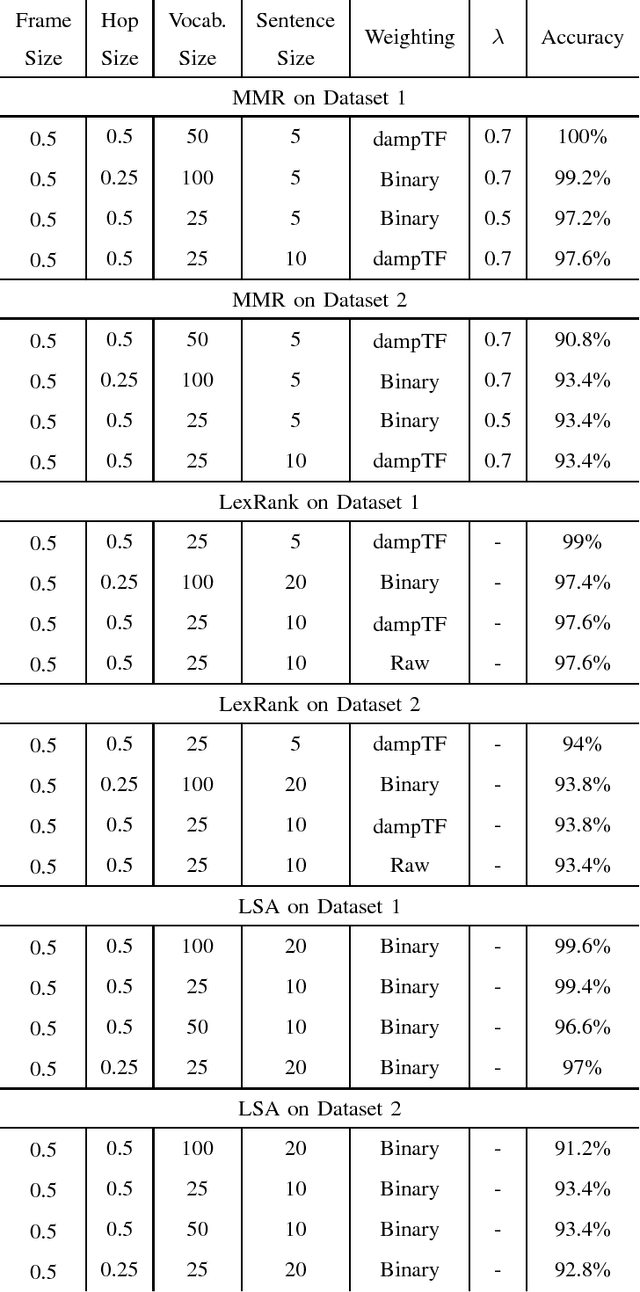
Several generic summarization algorithms were developed in the past and successfully applied in fields such as text and speech summarization. In this paper, we review and apply these algorithms to music. To evaluate this summarization's performance, we adopt an extrinsic approach: we compare a Fado Genre Classifier's performance using truncated contiguous clips against the summaries extracted with those algorithms on 2 different datasets. We show that Maximal Marginal Relevance (MMR), LexRank and Latent Semantic Analysis (LSA) all improve classification performance in both datasets used for testing.
* 12 pages, 1 table; Submitted to IEEE Signal Processing Letters
Automatic Fado Music Classification
Jun 17, 2014

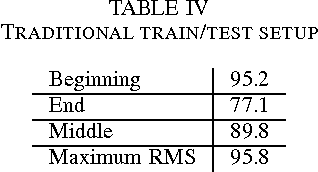
In late 2011, Fado was elevated to the oral and intangible heritage of humanity by UNESCO. This study aims to develop a tool for automatic detection of Fado music based on the audio signal. To do this, frequency spectrum-related characteristics were captured form the audio signal: in addition to the Mel Frequency Cepstral Coefficients (MFCCs) and the energy of the signal, the signal was further analysed in two frequency ranges, providing additional information. Tests were run both in a 10-fold cross-validation setup (97.6% accuracy), and in a traditional train/test setup (95.8% accuracy). The good results reflect the fact that Fado is a very distinctive musical style.
Ensemble Detection of Single & Multiple Events at Sentence-Level
Mar 24, 2014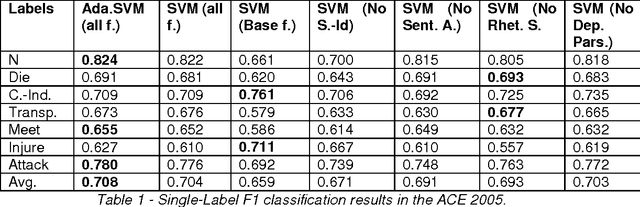
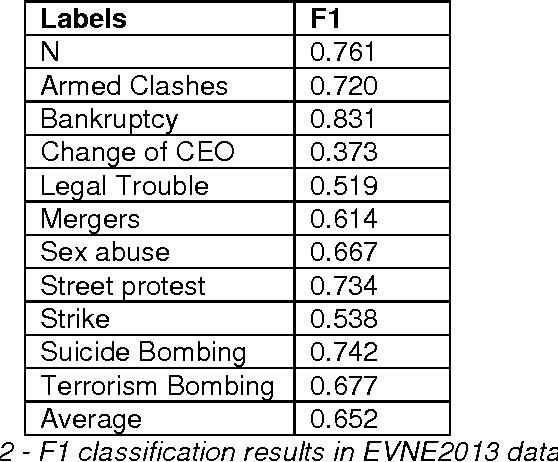
Event classification at sentence level is an important Information Extraction task with applications in several NLP, IR, and personalization systems. Multi-label binary relevance (BR) are the state-of-art methods. In this work, we explored new multi-label methods known for capturing relations between event types. These new methods, such as the ensemble Chain of Classifiers, improve the F1 on average across the 6 labels by 2.8% over the Binary Relevance. The low occurrence of multi-label sentences motivated the reduction of the hard imbalanced multi-label classification problem with low number of occurrences of multiple labels per instance to an more tractable imbalanced multiclass problem with better results (+ 4.6%). We report the results of adding new features, such as sentiment strength, rhetorical signals, domain-id (source-id and date), and key-phrases in both single-label and multi-label event classification scenarios.
Co-Multistage of Multiple Classifiers for Imbalanced Multiclass Learning
Jan 24, 2014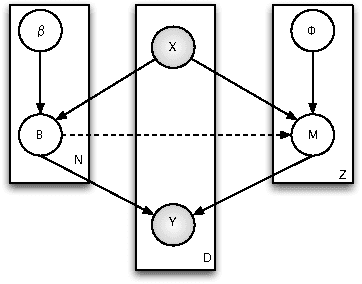
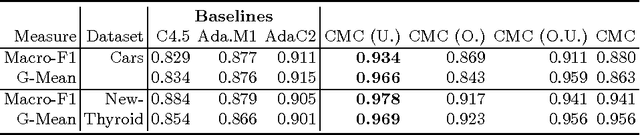
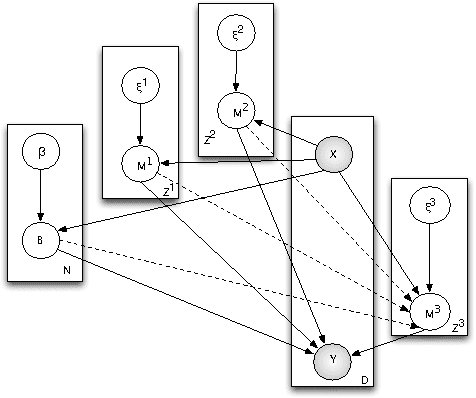

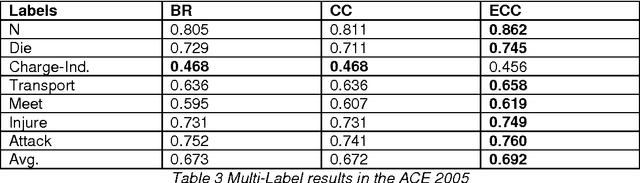
In this work, we propose two stochastic architectural models (CMC and CMC-M) with two layers of classifiers applicable to datasets with one and multiple skewed classes. This distinction becomes important when the datasets have a large number of classes. Therefore, we present a novel solution to imbalanced multiclass learning with several skewed majority classes, which improves minority classes identification. This fact is particularly important for text classification tasks, such as event detection. Our models combined with pre-processing sampling techniques improved the classification results on six well-known datasets. Finally, we have also introduced a new metric SG-Mean to overcome the multiplication by zero limitation of G-Mean.
Centrality-as-Relevance: Support Sets and Similarity as Geometric Proximity
Jan 16, 2014

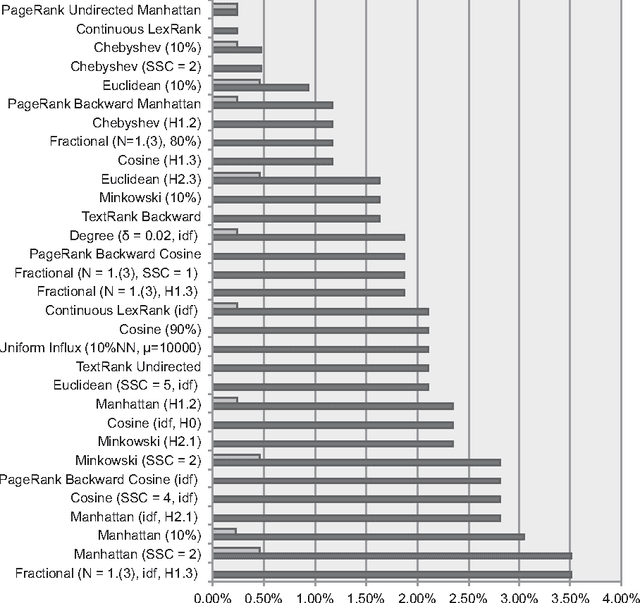
In automatic summarization, centrality-as-relevance means that the most important content of an information source, or a collection of information sources, corresponds to the most central passages, considering a representation where such notion makes sense (graph, spatial, etc.). We assess the main paradigms, and introduce a new centrality-based relevance model for automatic summarization that relies on the use of support sets to better estimate the relevant content. Geometric proximity is used to compute semantic relatedness. Centrality (relevance) is determined by considering the whole input source (and not only local information), and by taking into account the existence of minor topics or lateral subjects in the information sources to be summarized. The method consists in creating, for each passage of the input source, a support set consisting only of the most semantically related passages. Then, the determination of the most relevant content is achieved by selecting the passages that occur in the largest number of support sets. This model produces extractive summaries that are generic, and language- and domain-independent. Thorough automatic evaluation shows that the method achieves state-of-the-art performance, both in written text, and automatically transcribed speech summarization, including when compared to considerably more complex approaches.
Key Phrase Extraction of Lightly Filtered Broadcast News
Jun 20, 2013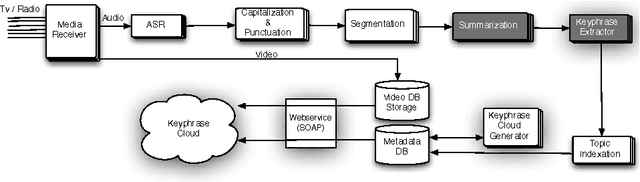
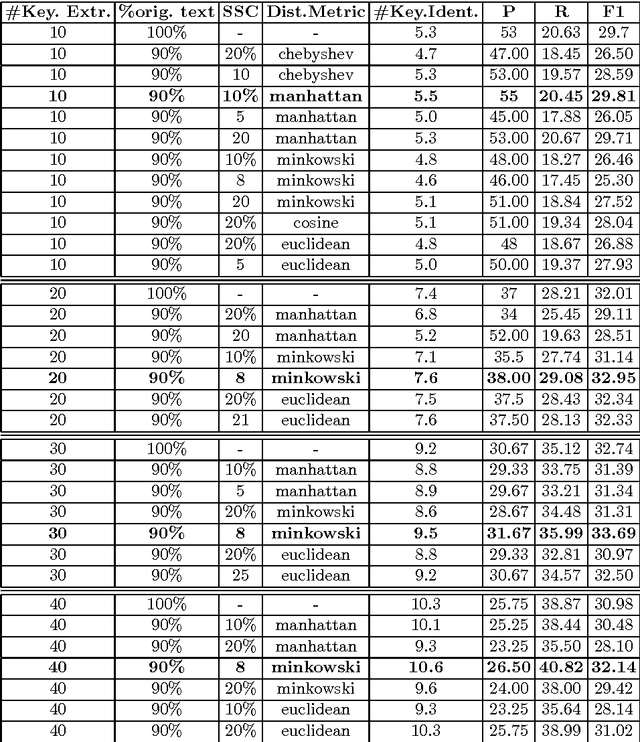
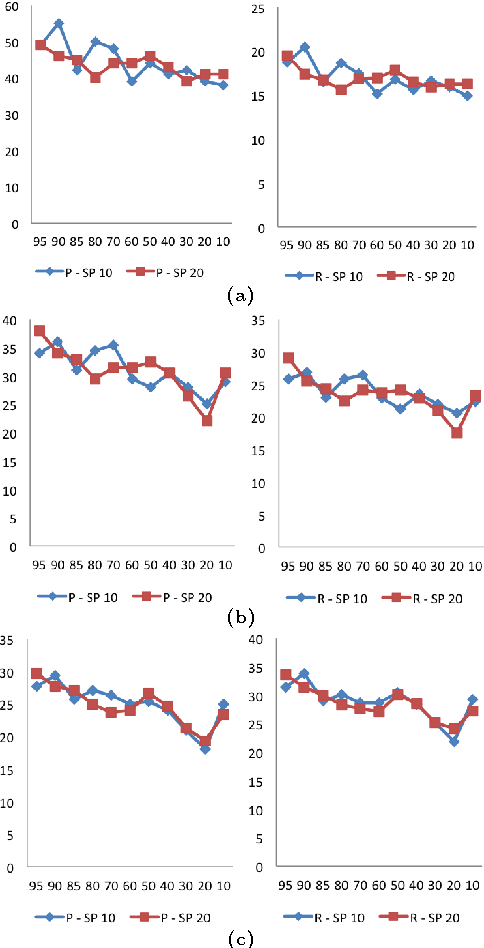
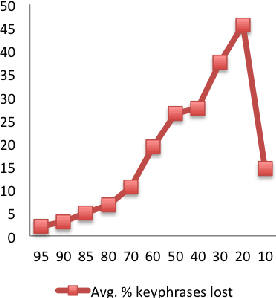
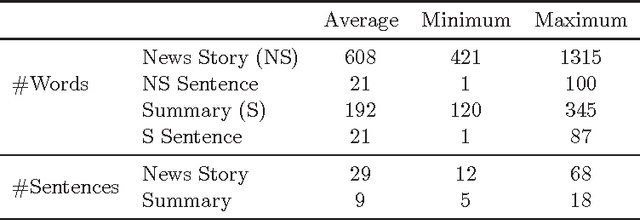
This paper explores the impact of light filtering on automatic key phrase extraction (AKE) applied to Broadcast News (BN). Key phrases are words and expressions that best characterize the content of a document. Key phrases are often used to index the document or as features in further processing. This makes improvements in AKE accuracy particularly important. We hypothesized that filtering out marginally relevant sentences from a document would improve AKE accuracy. Our experiments confirmed this hypothesis. Elimination of as little as 10% of the document sentences lead to a 2% improvement in AKE precision and recall. AKE is built over MAUI toolkit that follows a supervised learning approach. We trained and tested our AKE method on a gold standard made of 8 BN programs containing 110 manually annotated news stories. The experiments were conducted within a Multimedia Monitoring Solution (MMS) system for TV and radio news/programs, running daily, and monitoring 12 TV and 4 radio channels.
Frame Interpretation and Validation in a Open Domain Dialogue System
Jul 18, 2012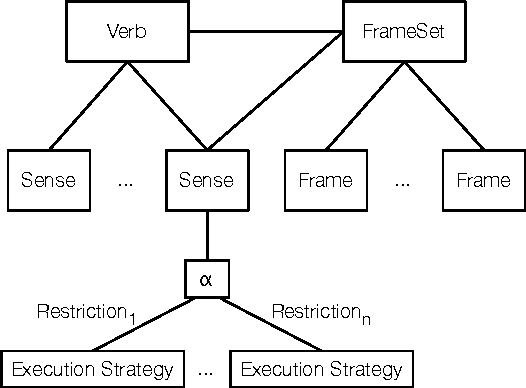
Our goal in this paper is to establish a means for a dialogue platform to be able to cope with open domains considering the possible interaction between the embodied agent and humans. To this end we present an algorithm capable of processing natural language utterances and validate them against knowledge structures of an intelligent agent's mind. Our algorithm leverages dialogue techniques in order to solve ambiguities and acquire knowledge about unknown entities.