 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Gaussian Networks
Feb 27, 2013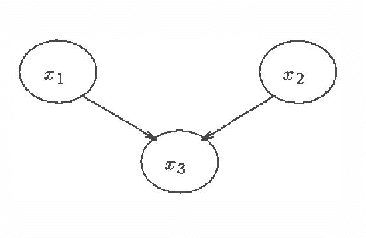
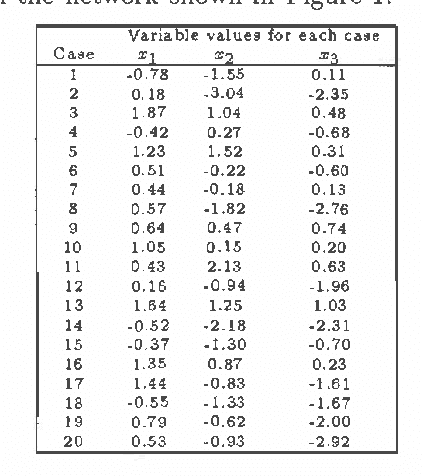
We describe algorithms for learning Bayesian networks from a combination of user knowledge and statistical data. The algorithms have two components: a scoring metric and a search procedure. The scoring metric takes a network structure, statistical data, and a user's prior knowledge, and returns a score proportional to the posterior probability of the network structure given the data. The search procedure generates networks for evaluation by the scoring metric. Previous work has concentrated on metrics for domains containing only discrete variables, under the assumption that data represents a multinomial sample. In this paper, we extend this work, developing scoring metrics for domains containing all continuous variables or a mixture of discrete and continuous variables, under the assumption that continuous data is sampled from a multivariate normal distribution. Our work extends traditional statistical approaches for identifying vanishing regression coefficients in that we identify two important assumptions, called event equivalence and parameter modularity, that when combined allow the construction of prior distributions for multivariate normal parameters from a single prior Bayesian network specified by a user.
Learning Bayesian Networks: A Unification for Discrete and Gaussian Domains
Feb 20, 2013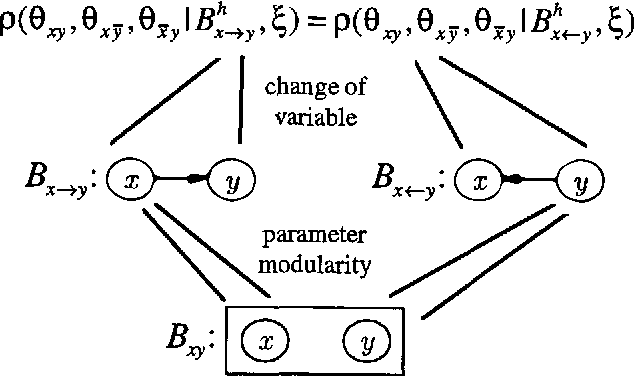
We examine Bayesian methods for learning Bayesian networks from a combination of prior knowledge and statistical data. In particular, we unify the approaches we presented at last year's conference for discrete and Gaussian domains. We derive a general Bayesian scoring metric, appropriate for both domains. We then use this metric in combination with well-known statistical facts about the Dirichlet and normal--Wishart distributions to derive our metrics for discrete and Gaussian domains.
A Characterization of the Dirichlet Distribution with Application to Learning Bayesian Networks
Feb 20, 2013We provide a new characterization of the Dirichlet distribution. This characterization implies that under assumptions made by several previous authors for learning belief networks, a Dirichlet prior on the parameters is inevitable.
Models and Selection Criteria for Regression and Classification
Feb 06, 2013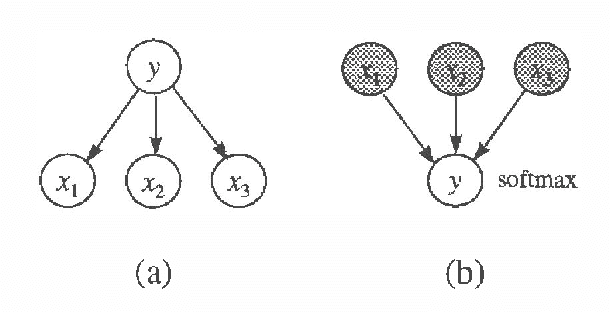
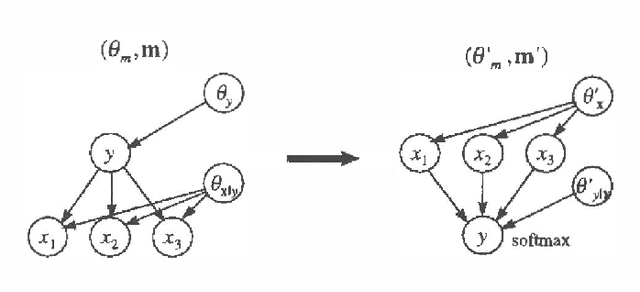
When performing regression or classification, we are interested in the conditional probability distribution for an outcome or class variable Y given a set of explanatoryor input variables X. We consider Bayesian models for this task. In particular, we examine a special class of models, which we call Bayesian regression/classification (BRC) models, that can be factored into independent conditional (y|x) and input (x) models. These models are convenient, because the conditional model (the portion of the full model that we care about) can be analyzed by itself. We examine the practice of transforming arbitrary Bayesian models to BRC models, and argue that this practice is often inappropriate because it ignores prior knowledge that may be important for learning. In addition, we examine Bayesian methods for learning models from data. We discuss two criteria for Bayesian model selection that are appropriate for repression/classification: one described by Spiegelhalter et al. (1993), and another by Buntine (1993). We contrast these two criteria using the prequential framework of Dawid (1984), and give sufficient conditions under which the criteria agree.
The Lumiere Project: Bayesian User Modeling for Inferring the Goals and Needs of Software Users
Jan 30, 2013
The Lumiere Project centers on harnessing probability and utility to provide assistance to computer software users. We review work on Bayesian user models that can be employed to infer a users needs by considering a user's background, actions, and queries. Several problems were tackled in Lumiere research, including (1) the construction of Bayesian models for reasoning about the time-varying goals of computer users from their observed actions and queries, (2) gaining access to a stream of events from software applications, (3) developing a language for transforming system events into observational variables represented in Bayesian user models, (4) developing persistent profiles to capture changes in a user expertise, and (5) the development of an overall architecture for an intelligent user interface. Lumiere prototypes served as the basis for the Office Assistant in the Microsoft Office '97 suite of productivity applications.
Empirical Analysis of Predictive Algorithms for Collaborative Filtering
Jan 30, 2013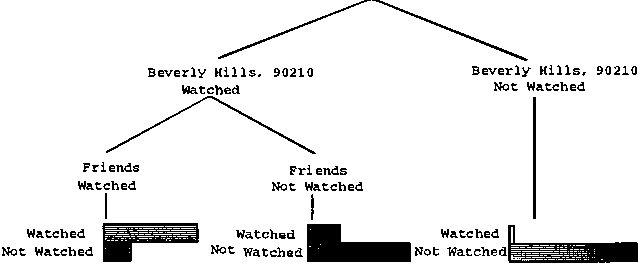
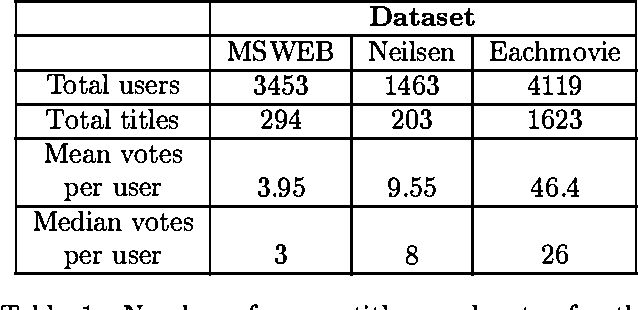
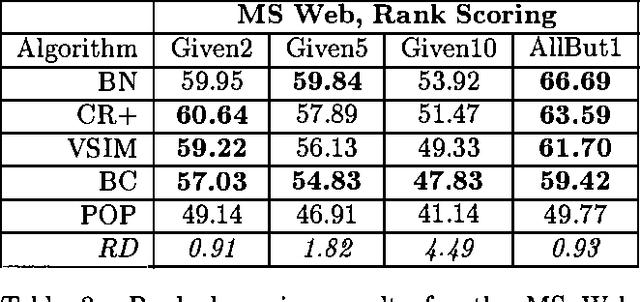

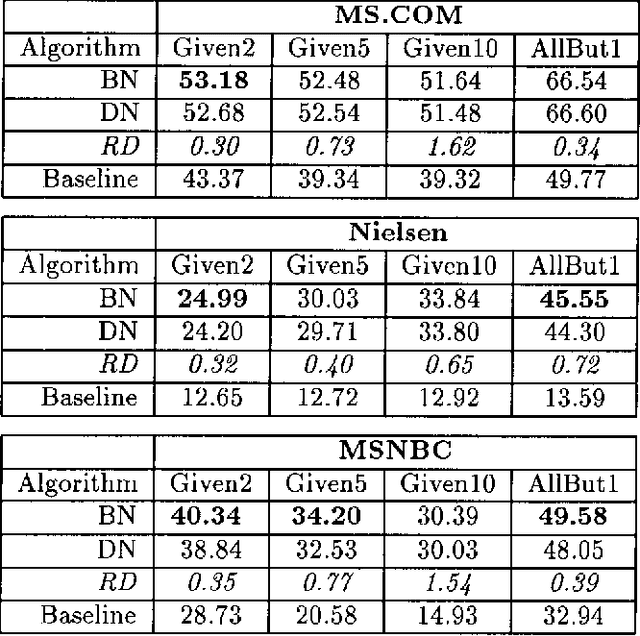
Collaborative filtering or recommender systems use a database about user preferences to predict additional topics or products a new user might like. In this paper we describe several algorithms designed for this task, including techniques based on correlation coefficients, vector-based similarity calculations, and statistical Bayesian methods. We compare the predictive accuracy of the various methods in a set of representative problem domains. We use two basic classes of evaluation metrics. The first characterizes accuracy over a set of individual predictions in terms of average absolute deviation. The second estimates the utility of a ranked list of suggested items. This metric uses an estimate of the probability that a user will see a recommendation in an ordered list. Experiments were run for datasets associated with 3 application areas, 4 experimental protocols, and the 2 evaluation metrics for the various algorithms. Results indicate that for a wide range of conditions, Bayesian networks with decision trees at each node and correlation methods outperform Bayesian-clustering and vector-similarity methods. Between correlation and Bayesian networks, the preferred method depends on the nature of the dataset, nature of the application (ranked versus one-by-one presentation), and the availability of votes with which to make predictions. Other considerations include the size of database, speed of predictions, and learning time.
Dependency Networks for Collaborative Filtering and Data Visualization
Jan 16, 2013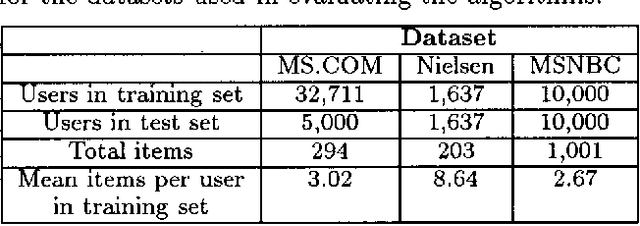
We describe a graphical model for probabilistic relationships---an alternative to the Bayesian network---called a dependency network. The graph of a dependency network, unlike a Bayesian network, is potentially cyclic. The probability component of a dependency network, like a Bayesian network, is a set of conditional distributions, one for each node given its parents. We identify several basic properties of this representation and describe a computationally efficient procedure for learning the graph and probability components from data. We describe the application of this representation to probabilistic inference, collaborative filtering (the task of predicting preferences), and the visualization of acausal predictive relationships.
A Decision Theoretic Approach to Targeted Advertising
Jan 16, 2013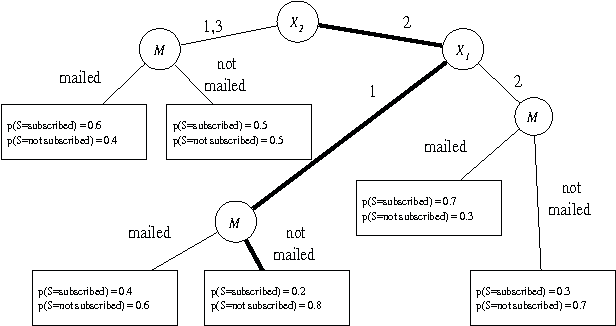
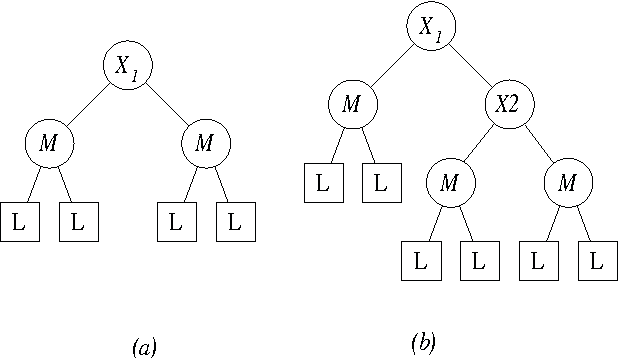
A simple advertising strategy that can be used to help increase sales of a product is to mail out special offers to selected potential customers. Because there is a cost associated with sending each offer, the optimal mailing strategy depends on both the benefit obtained from a purchase and how the offer affects the buying behavior of the customers. In this paper, we describe two methods for partitioning the potential customers into groups, and show how to perform a simple cost-benefit analysis to decide which, if any, of the groups should be targeted. In particular, we consider two decision-tree learning algorithms. The first is an "off the shelf" algorithm used to model the probability that groups of customers will buy the product. The second is a new algorithm that is similar to the first, except that for each group, it explicitly models the probability of purchase under the two mailing scenarios: (1) the mail is sent to members of that group and (2) the mail is not sent to members of that group. Using data from a real-world advertising experiment, we compare the algorithms to each other and to a naive mail-to-all strategy.
Staged Mixture Modelling and Boosting
Dec 12, 2012
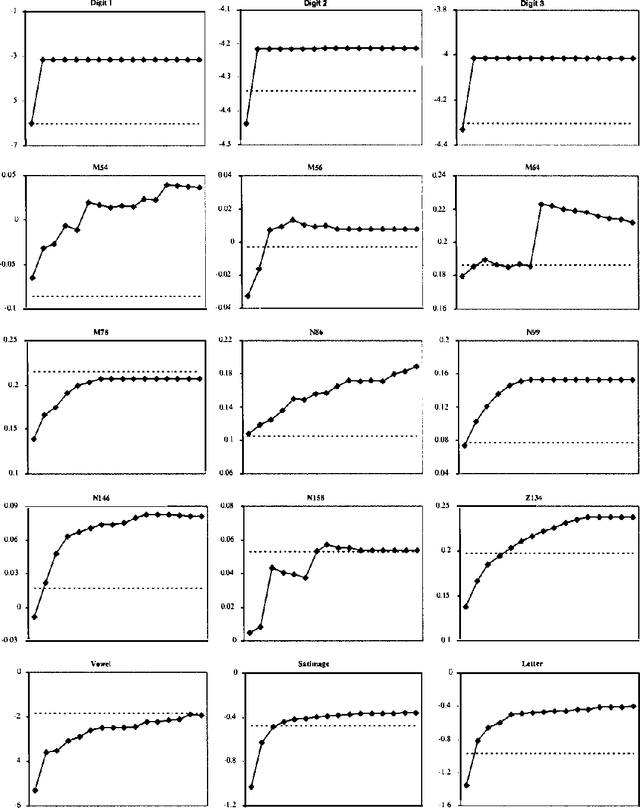

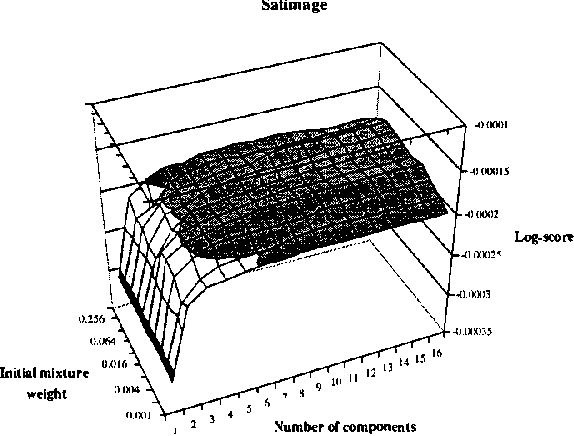
In this paper, we introduce and evaluate a data-driven staged mixture modeling technique for building density, regression, and classification models. Our basic approach is to sequentially add components to a finite mixture model using the structural expectation maximization (SEM) algorithm. We show that our technique is qualitatively similar to boosting. This correspondence is a natural byproduct of the fact that we use the SEM algorithm to sequentially fit the mixture model. Finally, in our experimental evaluation, we demonstrate the effectiveness of our approach on a variety of prediction and density estimation tasks using real-world data.
Large-Sample Learning of Bayesian Networks is NP-Hard
Oct 19, 2012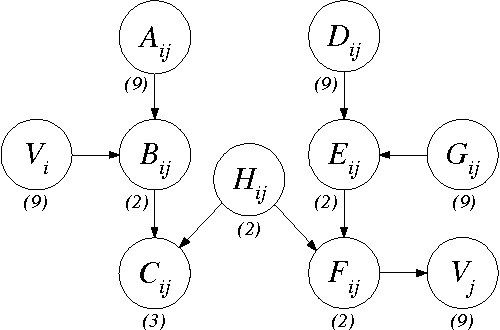
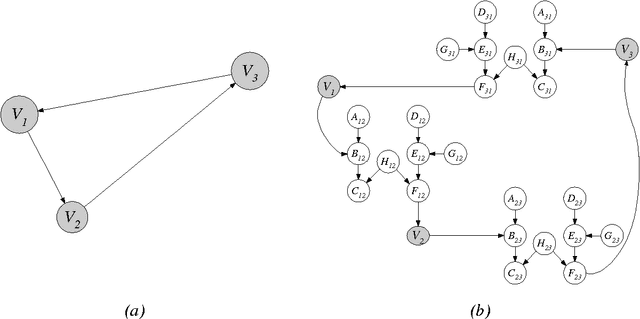
In this paper, we provide new complexity results for algorithms that learn discrete-variable Bayesian networks from data. Our results apply whenever the learning algorithm uses a scoring criterion that favors the simplest model able to represent the generative distribution exactly. Our results therefore hold whenever the learning algorithm uses a consistent scoring criterion and is applied to a sufficiently large dataset. We show that identifying high-scoring structures is hard, even when we are given an independence oracle, an inference oracle, and/or an information oracle. Our negative results also apply to the learning of discrete-variable Bayesian networks in which each node has at most k parents, for all k > 3.