 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCong Yu
Generating Representative Headlines for News Stories
Jan 28, 2020
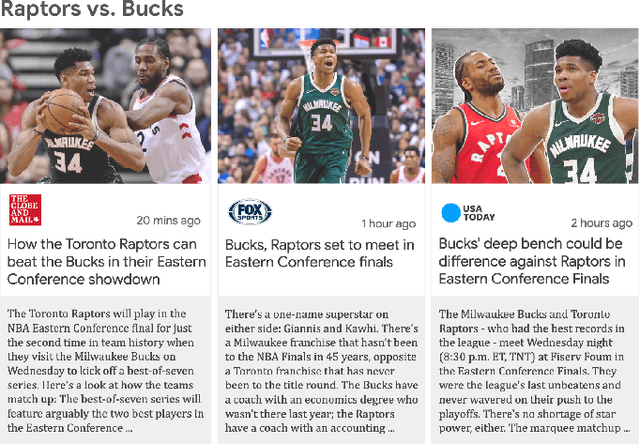
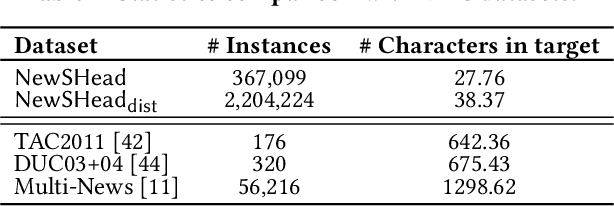

Millions of news articles are published online every day, which can be overwhelming for readers to follow. Grouping articles that are reporting the same event into news stories is a common way of assisting readers in their news consumption. However, it remains a challenging research problem to efficiently and effectively generate a representative headline for each story. Automatic summarization of a document set has been studied for decades, while few studies have focused on generating representative headlines for a set of articles. Unlike summaries, which aim to capture most information with least redundancy, headlines aim to capture information jointly shared by the story articles in short length, and exclude information that is too specific to each individual article. In this work, we study the problem of generating representative headlines for news stories. We develop a distant supervision approach to train large-scale generation models without any human annotation. This approach centers on two technical components. First, we propose a multi-level pre-training framework that incorporates massive unlabeled corpus with different quality-vs.-quantity balance at different levels. We show that models trained within this framework outperform those trained with pure human curated corpus. Second, we propose a novel self-voting-based article attention layer to extract salient information shared by multiple articles. We show that models that incorporate this layer are robust to potential noises in news stories and outperform existing baselines with or without noises. We can further enhance our model by incorporating human labels, and we show our distant supervision approach significantly reduces the demand on labeled data.
CLUENER2020: Fine-grained Named Entity Recognition Dataset and Benchmark for Chinese
Jan 20, 2020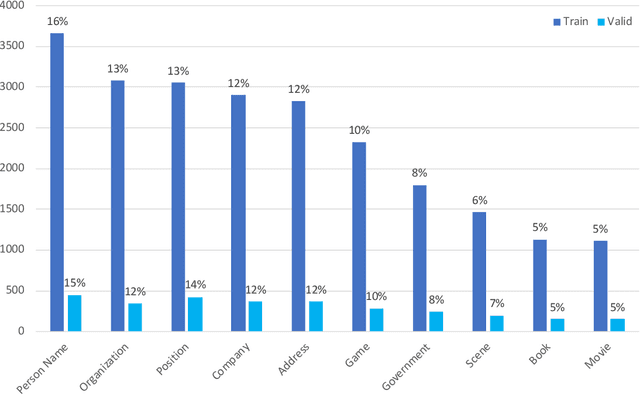

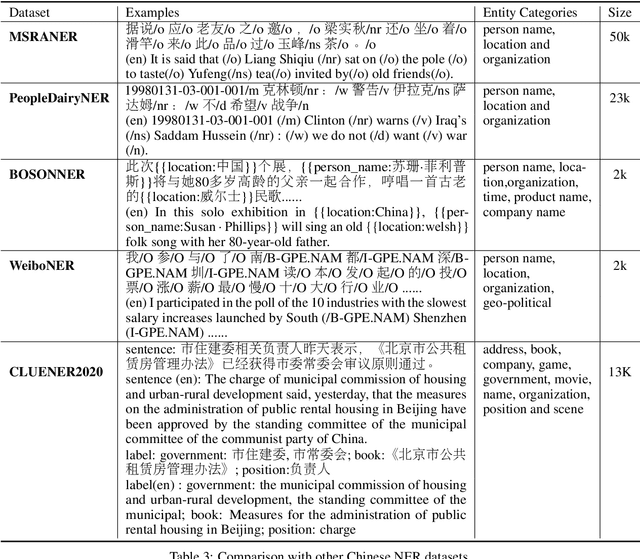
In this paper, we introduce the NER dataset from CLUE organization (CLUENER2020), a well-defined fine-grained dataset for named entity recognition in Chinese. CLUENER2020 contains 10 categories. Apart from common labels like person, organization, and location, it contains more diverse categories. It is more challenging than current other Chinese NER datasets and could better reflect real-world applications. For comparison, we implement several state-of-the-art baselines as sequence labeling tasks and report human performance, as well as its analysis. To facilitate future work on fine-grained NER for Chinese, we release our dataset, baselines, and leader-board.
CLUENER2020: Fine-grained Name Entity Recognition for Chinese
Jan 13, 2020In this paper, we introduce the NER dataset from CLUE organization (CLUENER2020), a well-defined fine-grained dataset for name entity recognition in Chinese. CLUENER2020 contains 10 categories. Apart from common labels like person, organization and location, it contains more diverse categories. It is more challenging than current other Chinese NER datasets and could better reflect real-world applications. For comparison, we implement several state-of-the-art baselines as sequence labelling tasks and report human performance, as well as its analysis. To facilitate future work on fine-grained NER for Chinese, we release our dataset, baselines and leader-board.
Title Generation for Web Tables
Jun 30, 2018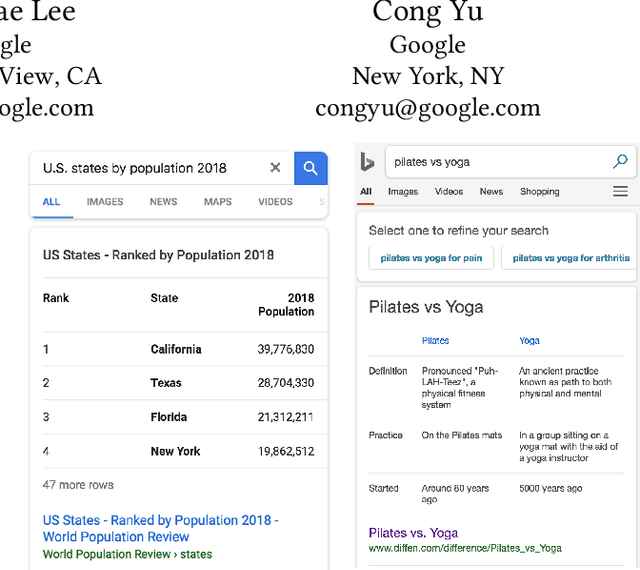

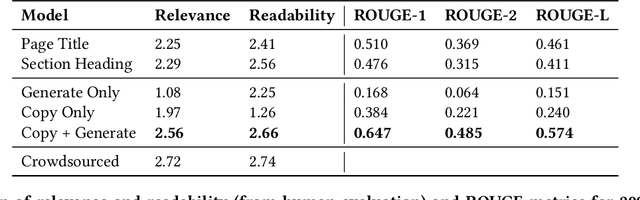
Descriptive titles provide crucial context for interpreting tables that are extracted from web pages and are a key component of table-based web applications. Prior approaches have attempted to produce titles by selecting existing text snippets associated with the table. These approaches, however, are limited by their dependence on suitable titles existing a priori. In our user study, we observe that the relevant information for the title tends to be scattered across the page, and often---more than 80% of time---does not appear verbatim anywhere in the page. We propose instead the application of a sequence-to-sequence neural network model as a more generalizable means of generating high-quality titles. This is accomplished by extracting many text snippets that have potentially relevant information to the table, encoding them into an input sequence, and using both copy and generation mechanisms in the decoder to balance relevance and readability of the generated title. We validate this approach with human evaluation on sample web tables and report that while sequence models with only a copy mechanism or only a generation mechanism are easily outperformed by simple selection-based baselines, the model with both capabilities outperforms them all, approaching the quality of crowdsourced titles while training on fewer than ten thousand examples. To the best of our knowledge, the proposed technique is the first to consider text-generation methods for table titles, and establishes a new state of the art.