 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCong Fang
Layer-Peeled Model: Toward Understanding Well-Trained Deep Neural Networks
Feb 15, 2021
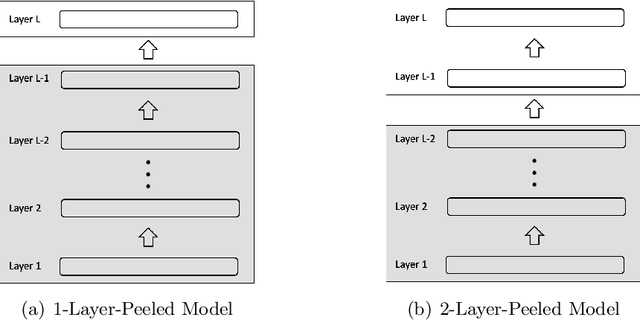

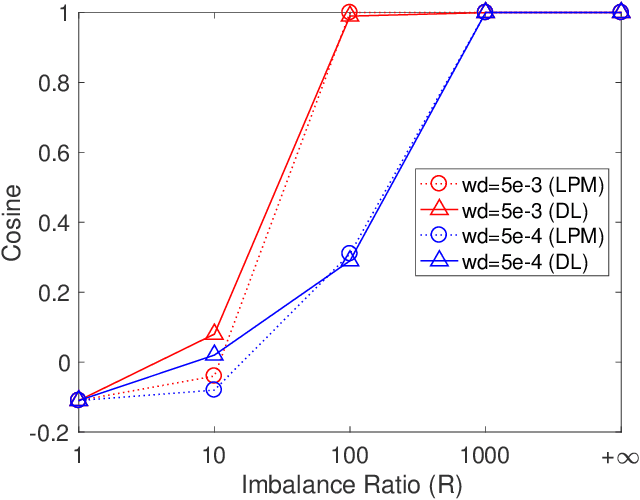

In this paper, we introduce the Layer-Peeled Model, a nonconvex yet analytically tractable optimization program, in a quest to better understand deep neural networks that are trained for a sufficiently long time. As the name suggests, this new model is derived by isolating the topmost layer from the remainder of the neural network, followed by imposing certain constraints separately on the two parts. We demonstrate that the Layer-Peeled Model, albeit simple, inherits many characteristics of well-trained neural networks, thereby offering an effective tool for explaining and predicting common empirical patterns of deep learning training. First, when working on class-balanced datasets, we prove that any solution to this model forms a simplex equiangular tight frame, which in part explains the recently discovered phenomenon of neural collapse in deep learning training [PHD20]. Moreover, when moving to the imbalanced case, our analysis of the Layer-Peeled Model reveals a hitherto unknown phenomenon that we term Minority Collapse, which fundamentally limits the performance of deep learning models on the minority classes. In addition, we use the Layer-Peeled Model to gain insights into how to mitigate Minority Collapse. Interestingly, this phenomenon is first predicted by the Layer-Peeled Model before its confirmation by our computational experiments.
Mathematical Models of Overparameterized Neural Networks
Dec 27, 2020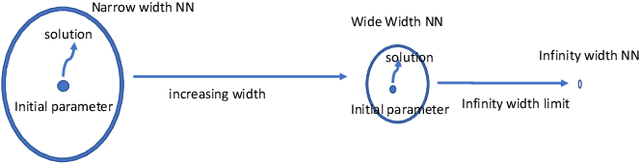
Deep learning has received considerable empirical successes in recent years. However, while many ad hoc tricks have been discovered by practitioners, until recently, there has been a lack of theoretical understanding for tricks invented in the deep learning literature. Known by practitioners that overparameterized neural networks are easy to learn, in the past few years there have been important theoretical developments in the analysis of overparameterized neural networks. In particular, it was shown that such systems behave like convex systems under various restricted settings, such as for two-layer NNs, and when learning is restricted locally in the so-called neural tangent kernel space around specialized initializations. This paper discusses some of these recent progresses leading to significant better understanding of neural networks. We will focus on the analysis of two-layer neural networks, and explain the key mathematical models, with their algorithmic implications. We will then discuss challenges in understanding deep neural networks and some current research directions.
Improved Analysis of Clipping Algorithms for Non-convex Optimization
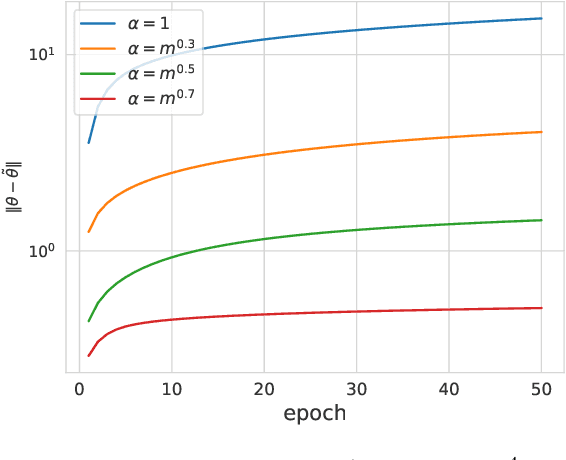
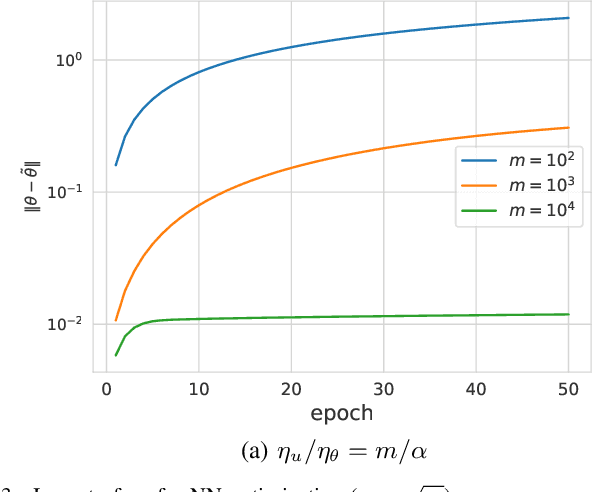
Oct 29, 2020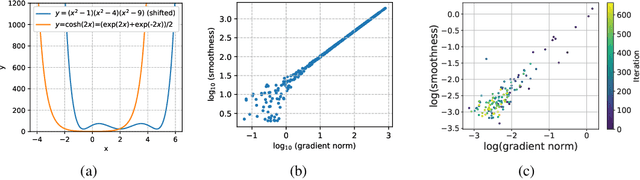

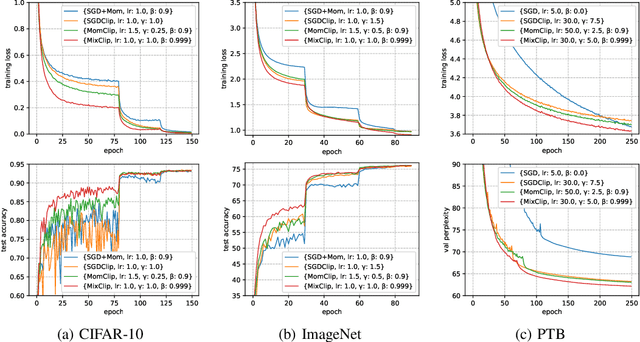
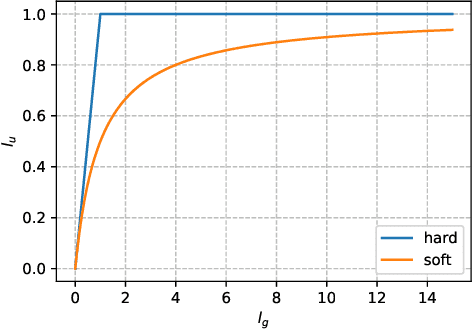
Gradient clipping is commonly used in training deep neural networks partly due to its practicability in relieving the exploding gradient problem. Recently, \citet{zhang2019gradient} show that clipped (stochastic) Gradient Descent (GD) converges faster than vanilla GD/SGD via introducing a new assumption called $(L_0, L_1)$-smoothness, which characterizes the violent fluctuation of gradients typically encountered in deep neural networks. However, their iteration complexities on the problem-dependent parameters are rather pessimistic, and theoretical justification of clipping combined with other crucial techniques, e.g. momentum acceleration, are still lacking. In this paper, we bridge the gap by presenting a general framework to study the clipping algorithms, which also takes momentum methods into consideration. We provide convergence analysis of the framework in both deterministic and stochastic setting, and demonstrate the tightness of our results by comparing them with existing lower bounds. Our results imply that the efficiency of clipping methods will not degenerate even in highly non-smooth regions of the landscape. Experiments confirm the superiority of clipping-based methods in deep learning tasks.
Modeling from Features: a Mean-field Framework for Over-parameterized Deep Neural Networks
Jul 03, 2020This paper proposes a new mean-field framework for over-parameterized deep neural networks (DNNs), which can be used to analyze neural network training. In this framework, a DNN is represented by probability measures and functions over its features (that is, the function values of the hidden units over the training data) in the continuous limit, instead of the neural network parameters as most existing studies have done. This new representation overcomes the degenerate situation where all the hidden units essentially have only one meaningful hidden unit in each middle layer, and further leads to a simpler representation of DNNs, for which the training objective can be reformulated as a convex optimization problem via suitable re-parameterization. Moreover, we construct a non-linear dynamics called neural feature flow, which captures the evolution of an over-parameterized DNN trained by Gradient Descent. We illustrate the framework via the standard DNN and the Residual Network (Res-Net) architectures. Furthermore, we show, for Res-Net, when the neural feature flow process converges, it reaches a global minimal solution under suitable conditions. Our analysis leads to the first global convergence proof for over-parameterized neural network training with more than $3$ layers in the mean-field regime.
Convex Formulation of Overparameterized Deep Neural Networks
Nov 18, 2019
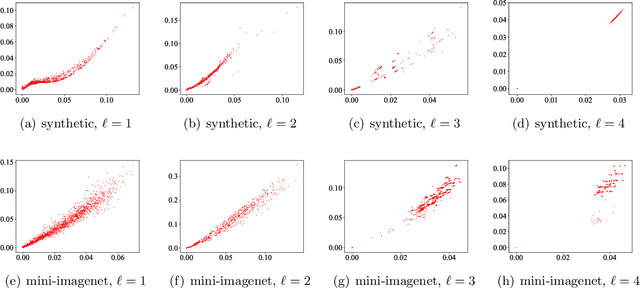
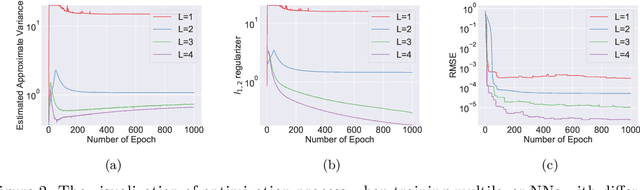
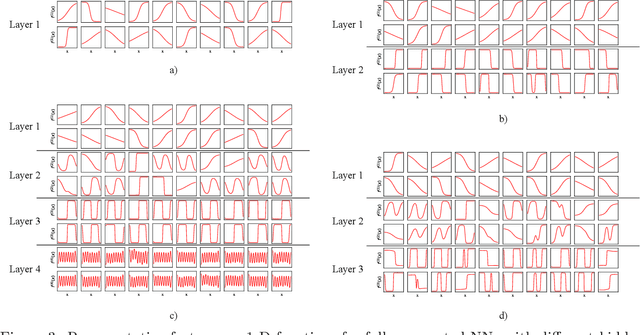
Analysis of over-parameterized neural networks has drawn significant attention in recentyears. It was shown that such systems behave like convex systems under various restrictedsettings, such as for two-level neural networks, and when learning is only restricted locally inthe so-called neural tangent kernel space around specialized initializations. However, there areno theoretical techniques that can analyze fully trained deep neural networks encountered inpractice. This paper solves this fundamental problem by investigating such overparameterizeddeep neural networks when fully trained. We generalize a new technique called neural feature repopulation, originally introduced in (Fang et al., 2019a) for two-level neural networks, to analyze deep neural networks. It is shown that under suitable representations, overparameterized deep neural networks are inherently convex, and when optimized, the system can learn effective features suitable for the underlying learning task under mild conditions. This new analysis is consistent with empirical observations that deep neural networks are capable of learning efficient feature representations. Therefore, the highly unexpected result of this paper can satisfactorily explain the practical success of deep neural networks. Empirical studies confirm that predictions of our theory are consistent with results observed in practice.
Over Parameterized Two-level Neural Networks Can Learn Near Optimal Feature Representations
Oct 25, 2019
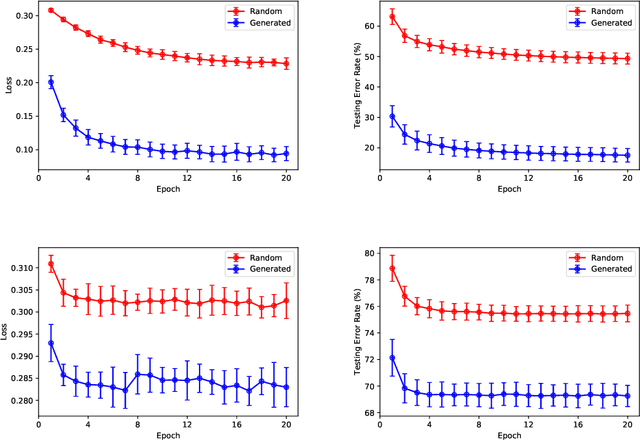

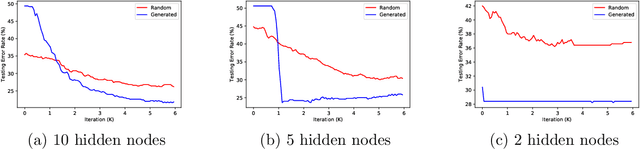
Recently, over-parameterized neural networks have been extensively analyzed in the literature. However, the previous studies cannot satisfactorily explain why fully trained neural networks are successful in practice. In this paper, we present a new theoretical framework for analyzing over-parameterized neural networks which we call neural feature repopulation. Our analysis can satisfactorily explain the empirical success of two level neural networks that are trained by standard learning algorithms. Our key theoretical result is that in the limit of infinite number of hidden neurons, over-parameterized two-level neural networks trained via the standard (noisy) gradient descent learns a well-defined feature distribution (population), and the limiting feature distribution is nearly optimal for the underlying learning task under certain conditions. Empirical studies confirm that predictions of our theory are consistent with the results observed in real practice.
A Stochastic Trust Region Method for Non-convex Minimization
Mar 04, 2019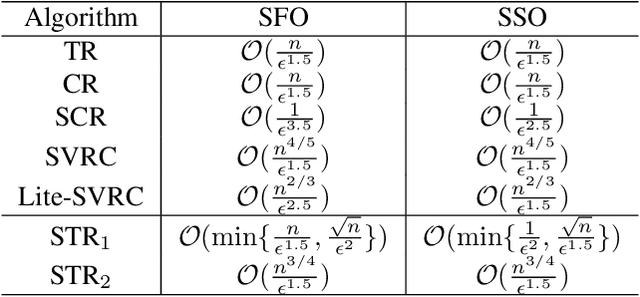
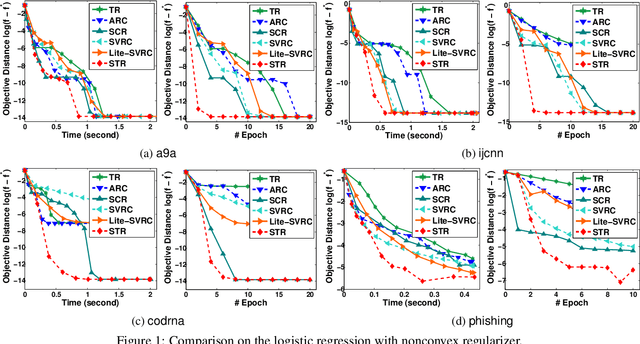
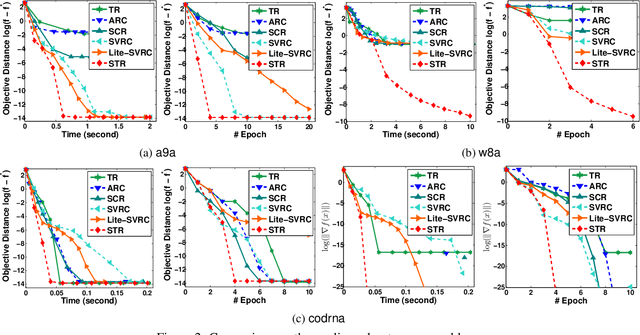

We target the problem of finding a local minimum in non-convex finite-sum minimization. Towards this goal, we first prove that the trust region method with inexact gradient and Hessian estimation can achieve a convergence rate of order $\mathcal{O}(1/{k^{2/3}})$ as long as those differential estimations are sufficiently accurate. Combining such result with a novel Hessian estimator, we propose the sample-efficient stochastic trust region (STR) algorithm which finds an $(\epsilon, \sqrt{\epsilon})$-approximate local minimum within $\mathcal{O}({\sqrt{n}}/{\epsilon^{1.5}})$ stochastic Hessian oracle queries. This improves state-of-the-art result by $\mathcal{O}(n^{1/6})$. Experiments verify theoretical conclusions and the efficiency of STR.
Sharp Analysis for Nonconvex SGD Escaping from Saddle Points
Feb 01, 2019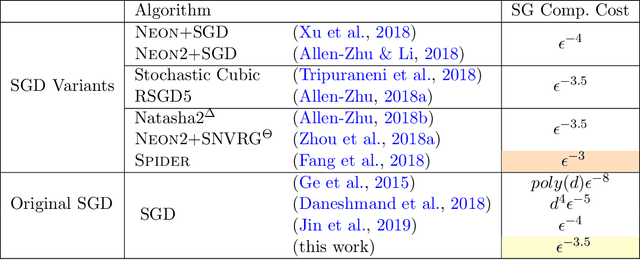
In this paper, we prove that the simplest Stochastic Gradient Descent (SGD) algorithm is able to efficiently escape from saddle points and find an $(\epsilon, O(\epsilon^{0.5}))$-approximate second-order stationary point in $\tilde{O}(\epsilon^{-3.5})$ stochastic gradient computations for generic nonconvex optimization problems, under both gradient-Lipschitz and Hessian-Lipschitz assumptions. This unexpected result subverts the classical belief that SGD requires at least $O(\epsilon^{-4})$ stochastic gradient computations for obtaining an $(\epsilon, O(\epsilon ^{0.5}))$-approximate second-order stationary point. Such SGD rate matches, up to a polylogarithmic factor of problem-dependent parameters, the rate of most accelerated nonconvex stochastic optimization algorithms that adopt additional techniques, such as Nesterov's momentum acceleration, negative curvature search, as well as quadratic and cubic regularization tricks. Our novel analysis gives new insights into nonconvex SGD and can be potentially generalized to a broad class of stochastic optimization algorithms.