 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy Efficient Hardware for On-Device CNN Inference via Transfer Learning
Dec 04, 2018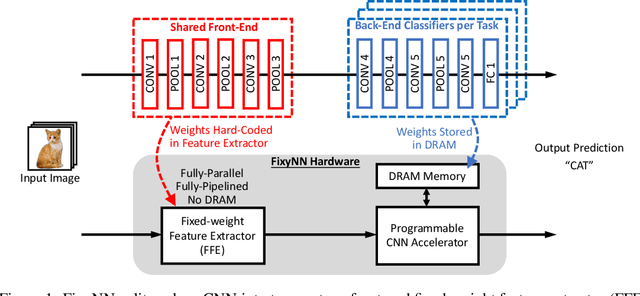

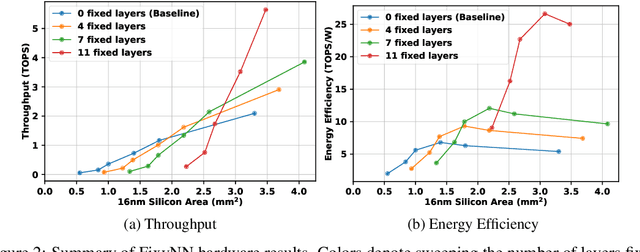
On-device CNN inference for real-time computer vision applications can result in computational demands that far exceed the energy budgets of mobile devices. This paper proposes FixyNN, a co-designed hardware accelerator platform which splits a CNN model into two parts: a set of layers that are fixed in the hardware platform as a front-end fixed-weight feature extractor, and the remaining layers which become a back-end classifier running on a conventional programmable CNN accelerator. The common front-end provides ubiquitous CNN features for all FixyNN models, while the back-end is programmable and specific to a given dataset. Image classification models for FixyNN are trained end-to-end via transfer learning, with front-end layers fixed for the shared feature extractor, and back-end layers fine-tuned for a specific task. Over a suite of six datasets, we trained models via transfer learning with an accuracy loss of <1%, resulting in a FixyNN hardware platform with nearly 2 times better energy efficiency than a conventional programmable CNN accelerator of the same silicon area (i.e. hardware cost).