 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunjing Xu
RNAS: Architecture Ranking for Powerful Networks
Oct 09, 2019
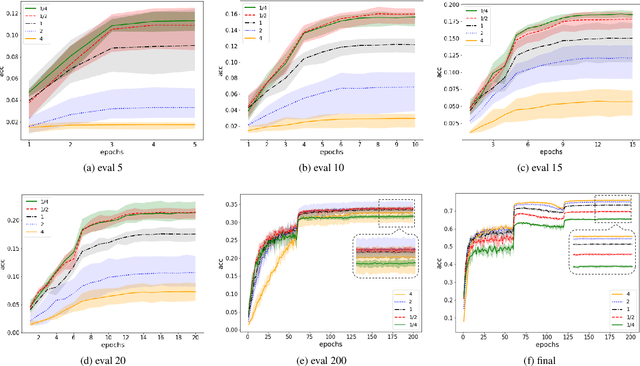
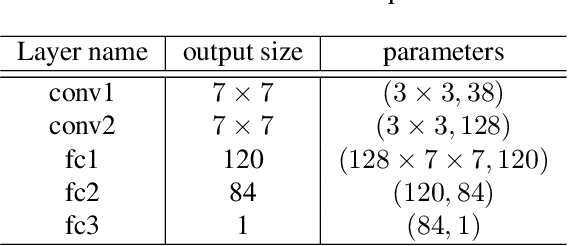
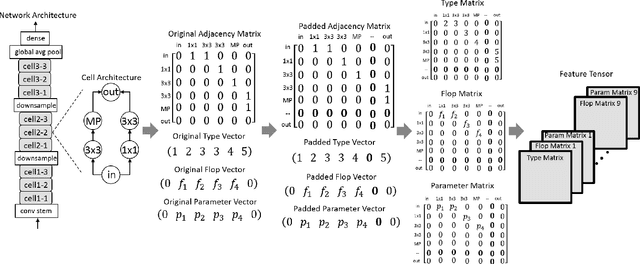
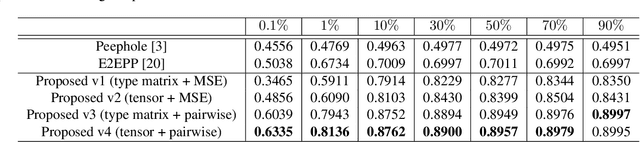
Neural Architecture Search (NAS) is attractive for automatically producing deep networks with excellent performance and acceptable computational costs. The performance of intermediate networks in most of existing NAS algorithms are usually represented by the results evaluated on a small proxy dataset with insufficient training in order to save computational resources and time. Although these representations could help us to distinct some searched architectures, they are still far away from the exact performance or ranking orders of all networks sampled from the given search space. Therefore, we propose to learn a performance predictor for ranking different models in the searching period using few networks pre-trained on the entire dataset. We represent each neural architecture as a feature tensor and use the predictor to further refining the representations of networks in the search space. The resulting performance predictor can be utilized for searching desired architectures without additional evaluation. Experimental results illustrate that, we can only use $0.1\%$ (424 models) of the entire NASBench dataset to construct an accurate predictor for efficiently finding the architecture with $93.90\%$ accuracy ($0.04\%$ top performance in the whole search space), which is about $0.5\%$ higher than that of the state-of-the-art methods.
Positive-Unlabeled Compression on the Cloud
Oct 08, 2019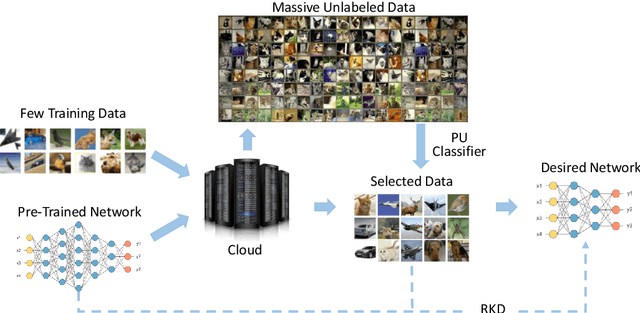
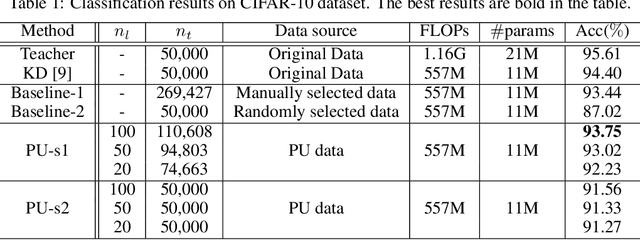
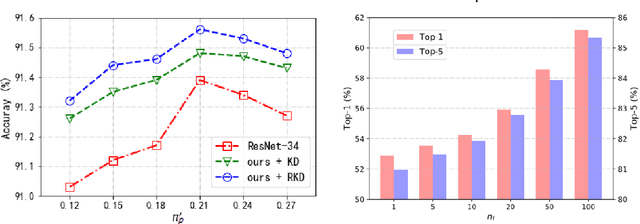
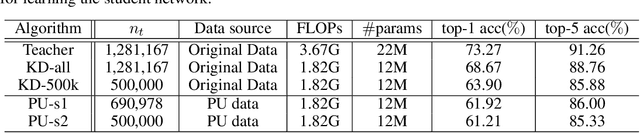
Many attempts have been done to extend the great success of convolutional neural networks (CNNs) achieved on high-end GPU servers to portable devices such as smart phones. Providing compression and acceleration service of deep learning models on the cloud is therefore of significance and is attractive for end users. However, existing network compression and acceleration approaches usually fine-tuning the svelte model by requesting the entire original training data (\eg ImageNet), which could be more cumbersome than the network itself and cannot be easily uploaded to the cloud. In this paper, we present a novel positive-unlabeled (PU) setting for addressing this problem. In practice, only a small portion of the original training set is required as positive examples and more useful training examples can be obtained from the massive unlabeled data on the cloud through a PU classifier with an attention based multi-scale feature extractor. We further introduce a robust knowledge distillation (RKD) scheme to deal with the class imbalance problem of these newly augmented training examples. The superiority of the proposed method is verified through experiments conducted on the benchmark models and datasets. We can use only $8\%$ of uniformly selected data from the ImageNet to obtain an efficient model with comparable performance to the baseline ResNet-34.
Unsupervised Image Super-Resolution with an Indirect Supervised Path
Oct 07, 2019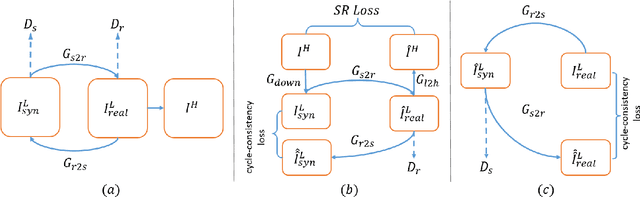



The task of single image super-resolution (SISR) aims at reconstructing a high-resolution (HR) image from a low-resolution (LR) image. Although significant progress has been made by deep learning models, they are trained on synthetic paired data in a supervised way and do not perform well on real data. There are several attempts that directly apply unsupervised image translation models to address such a problem. However, unsupervised low-level vision problem poses more challenge on the accuracy of translation. In this work,we propose a novel framework which is composed of two stages: 1) unsupervised image translation between real LR images and synthetic LR images; 2) supervised super-resolution from approximated real LR images to HR images. It takes the synthetic LR images as a bridge and creates an indirect supervised path from real LR images to HR images. Any existed deep learning based image super-resolution model can be integrated into the second stage of the proposed framework for further improvement. In addition it shows great flexibility in balancing between distortion and perceptual quality under unsupervised setting. The proposed method is evaluated on both NTIRE 2017 and 2018 challenge datasets and achieves favorable performance against supervised methods.
Efficient Residual Dense Block Search for Image Super-Resolution
Sep 27, 2019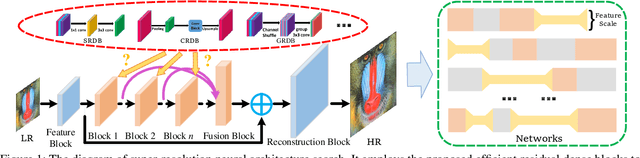
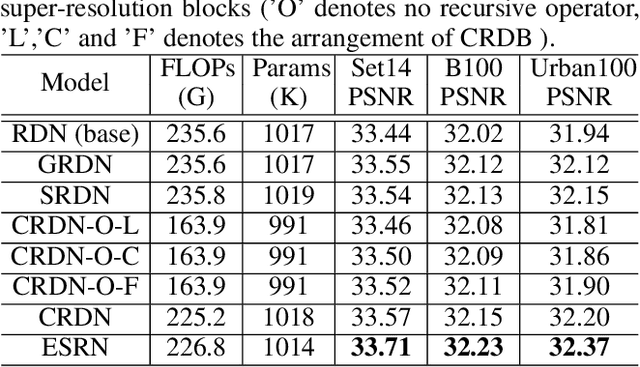
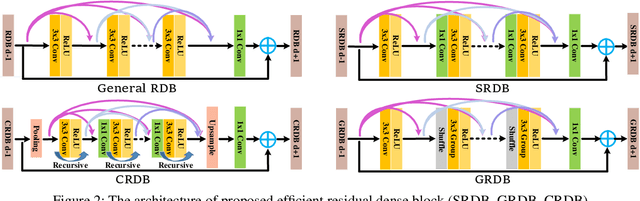
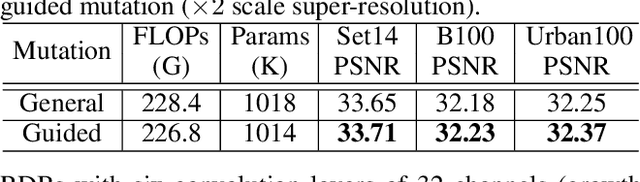
Although remarkable progress has been made on single image super-resolution due to the revival of deep convolutional neural networks, deep learning methods are confronted with the challenges of computation and memory consumption in practice, especially for mobile devices. Focusing on this issue, we propose an efficient residual dense block search algorithm with multiple objectives to hunt for fast, lightweight and accurate networks for image super-resolution. Firstly, to accelerate super-resolution network, we exploit the variation of feature scale adequately with the proposed efficient residual dense blocks. In the proposed evolutionary algorithm, the locations of pooling and upsampling operator are searched automatically. Secondly, network architecture is evolved with the guidance of block credits to acquire accurate super-resolution network. The block credit reflects the effect of current block and is earned during model evaluation process. It guides the evolution by weighing the sampling probability of mutation to favor admirable blocks. Extensive experimental results demonstrate the effectiveness of the proposed searching method and the found efficient super-resolution models achieve better performance than the state-of-the-art methods with limited number of parameters and FLOPs.
CARS: Continuous Evolution for Efficient Neural Architecture Search
Sep 17, 2019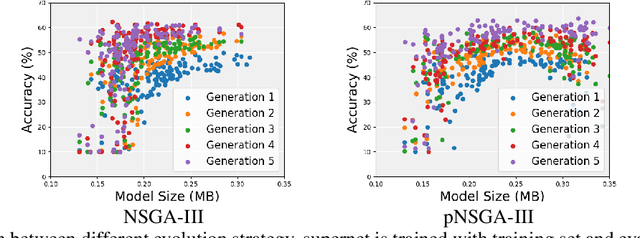
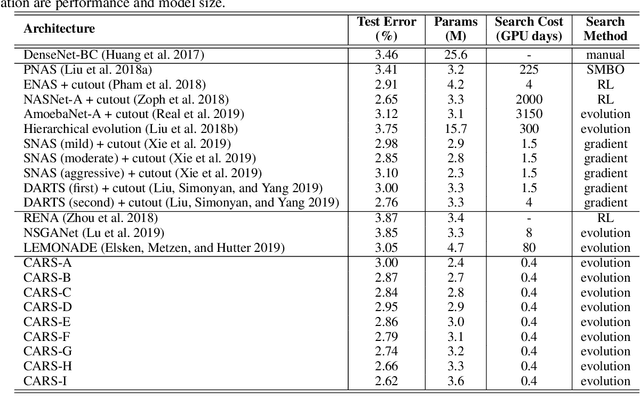
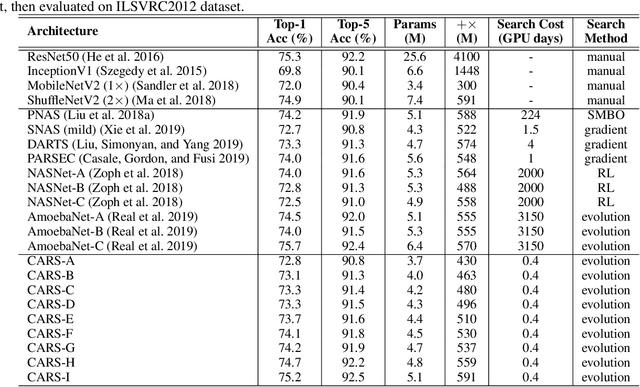
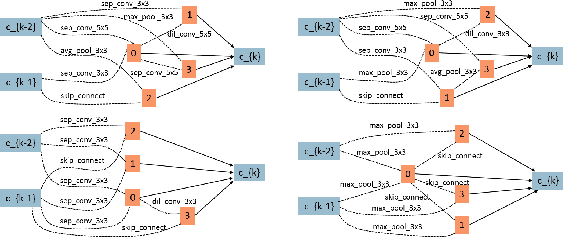
Searching techniques in most of existing neural architecture search (NAS) algorithms are mainly dominated by differentiable methods for the efficiency reason. In contrast, we develop an efficient continuous evolutionary approach for searching neural networks. Architectures in the population which share parameters within one supernet in the latest iteration will be tuned over the training dataset with a few epochs. The searching in the next evolution iteration will directly inherit both the supernet and the population, which accelerates the optimal network generation. The non-dominated sorting strategy is further applied to preserve only results on the Pareto front for accurately updating the supernet. Several neural networks with different model sizes and performance will be produced after the continuous search with only 0.4 GPU days. As a result, our framework provides a series of networks with the number of parameters ranging from 3.7M to 5.1M under mobile settings. These networks surpass those produced by the state-of-the-art methods on the benchmark ImageNet dataset.
Searching for Accurate Binary Neural Architectures
Sep 16, 2019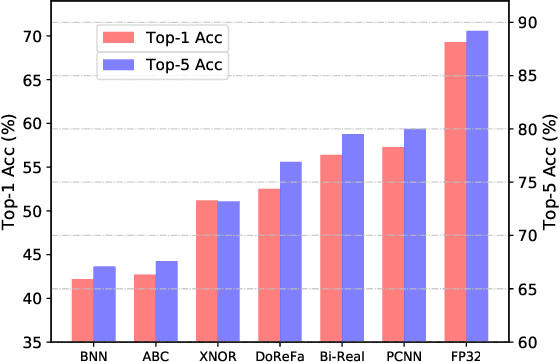
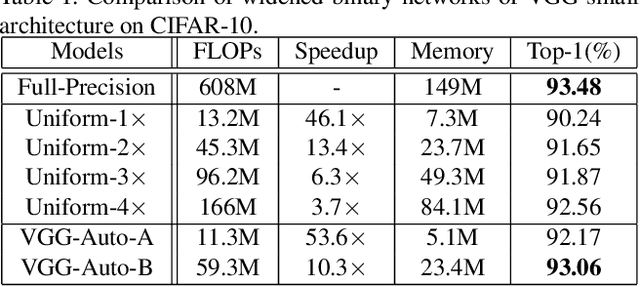
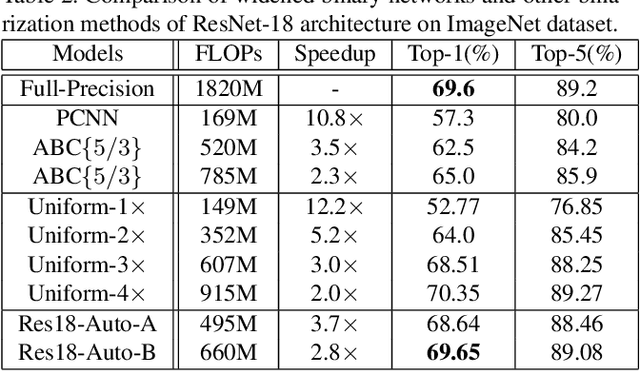
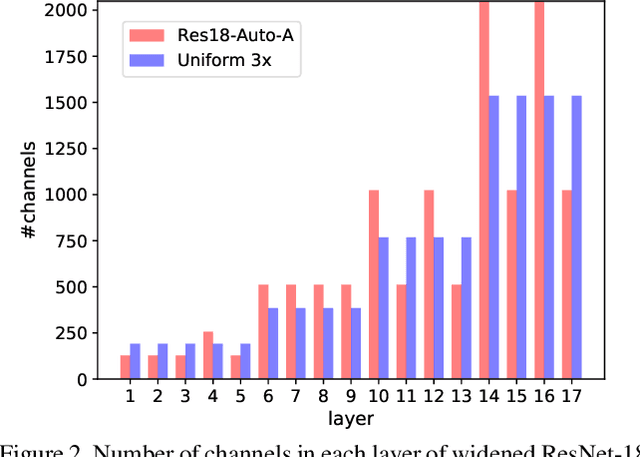
Binary neural networks have attracted tremendous attention due to the efficiency for deploying them on mobile devices. Since the weak expression ability of binary weights and features, their accuracy is usually much lower than that of full-precision (i.e. 32-bit) models. Here we present a new frame work for automatically searching for compact but accurate binary neural networks. In practice, number of channels in each layer will be encoded into the search space and optimized using the evolutionary algorithm. Experiments conducted on benchmark datasets and neural architectures demonstrate that our searched binary networks can achieve the performance of full-precision models with acceptable increments on model sizes and calculations.
Full-Stack Filters to Build Minimum Viable CNNs
Aug 06, 2019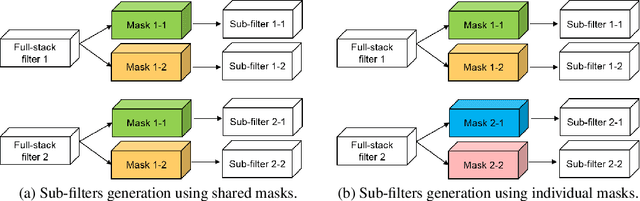
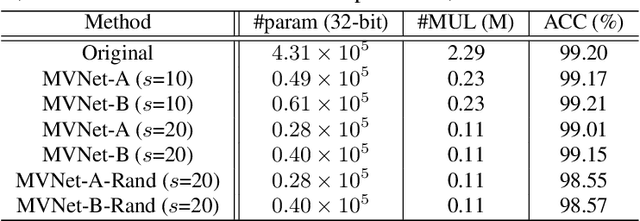
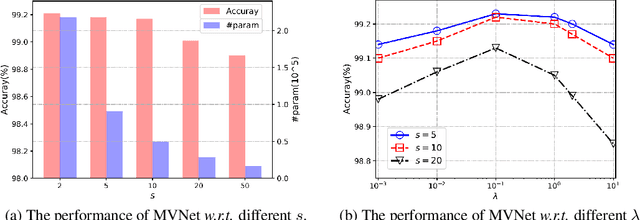
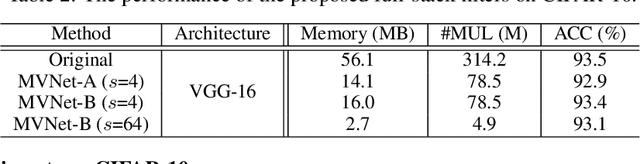
Deep convolutional neural networks (CNNs) are usually over-parameterized, which cannot be easily deployed on edge devices such as mobile phones and smart cameras. Existing works used to decrease the number or size of requested convolution filters for a minimum viable CNN on edge devices. In contrast, this paper introduces filters that are full-stack and can be used to generate many more sub-filters. Weights of these sub-filters are inherited from full-stack filters with the help of different binary masks. Orthogonal constraints are applied over binary masks to decrease their correlation and promote the diversity of generated sub-filters. To preserve the same volume of output feature maps, we can naturally reduce the number of established filters by only maintaining a few full-stack filters and a set of binary masks. We also conduct theoretical analysis on the memory cost and an efficient implementation is introduced for the convolution of the proposed filters. Experiments on several benchmark datasets and CNN models demonstrate that the proposed method is able to construct minimum viable convolution networks of comparable performance.
Learning Instance-wise Sparsity for Accelerating Deep Models
Jul 27, 2019
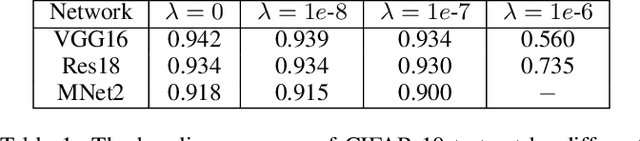
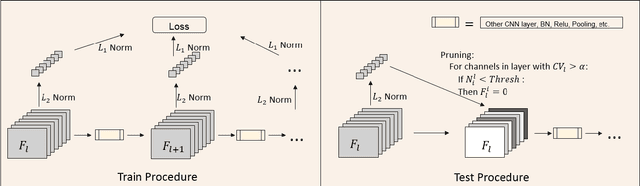
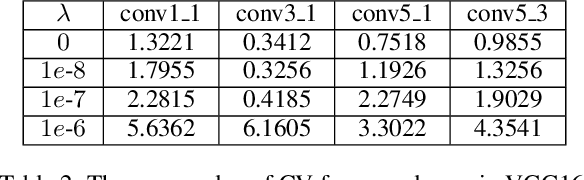
Exploring deep convolutional neural networks of high efficiency and low memory usage is very essential for a wide variety of machine learning tasks. Most of existing approaches used to accelerate deep models by manipulating parameters or filters without data, e.g., pruning and decomposition. In contrast, we study this problem from a different perspective by respecting the difference between data. An instance-wise feature pruning is developed by identifying informative features for different instances. Specifically, by investigating a feature decay regularization, we expect intermediate feature maps of each instance in deep neural networks to be sparse while preserving the overall network performance. During online inference, subtle features of input images extracted by intermediate layers of a well-trained neural network can be eliminated to accelerate the subsequent calculations. We further take coefficient of variation as a measure to select the layers that are appropriate for acceleration. Extensive experiments conducted on benchmark datasets and networks demonstrate the effectiveness of the proposed method.