 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunhua Shen
Efficient Anomaly Detection with Budget Annotation Using Semi-Supervised Residual Transformer
Jun 06, 2023

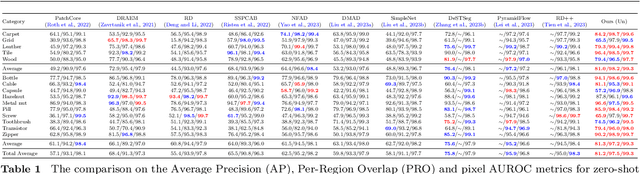
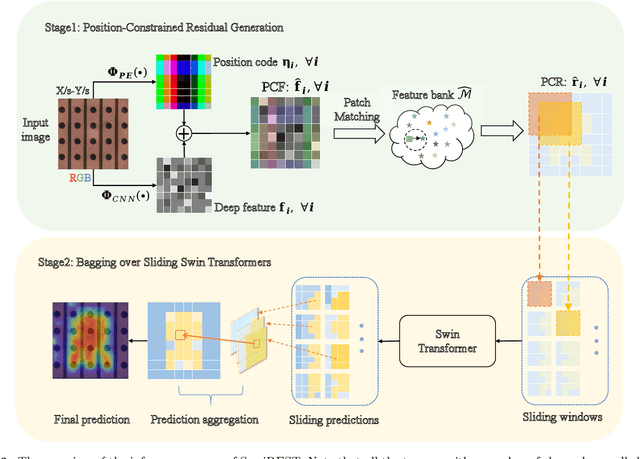
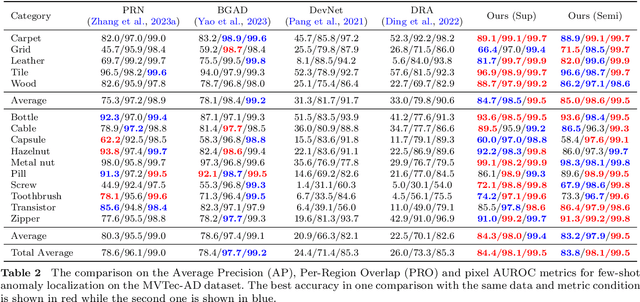
Anomaly Detection is challenging as usually only the normal samples are seen during training and the detector needs to discover anomalies on-the-fly. The recently proposed deep-learning-based approaches could somehow alleviate the problem but there is still a long way to go in obtaining an industrial-class anomaly detector for real-world applications. On the other hand, in some particular AD tasks, a few anomalous samples are labeled manually for achieving higher accuracy. However, this performance gain is at the cost of considerable annotation efforts, which can be intractable in many practical scenarios. In this work, the above two problems are addressed in a unified framework. Firstly, inspired by the success of the patch-matching-based AD algorithms, we train a sliding vision transformer over the residuals generated by a novel position-constrained patch-matching. Secondly, the conventional pixel-wise segmentation problem is cast into a block-wise classification problem. Thus the sliding transformer can attain even higher accuracy with much less annotation labor. Thirdly, to further reduce the labeling cost, we propose to label the anomalous regions using only bounding boxes. The unlabeled regions caused by the weak labels are effectively exploited using a highly-customized semi-supervised learning scheme equipped with two novel data augmentation methods. The proposed method outperforms all the state-of-the-art approaches using all the evaluation metrics in both the unsupervised and supervised scenarios. On the popular MVTec-AD dataset, our SemiREST algorithm obtains the Average Precision (AP) of 81.2% in the unsupervised condition and 84.4% AP for supervised anomaly detection. Surprisingly, with the bounding-box-based semi-supervisions, SemiREST still outperforms the SOTA methods with full supervision (83.8% AP) on MVTec-AD.
Pruning Meets Low-Rank Parameter-Efficient Fine-Tuning
May 31, 2023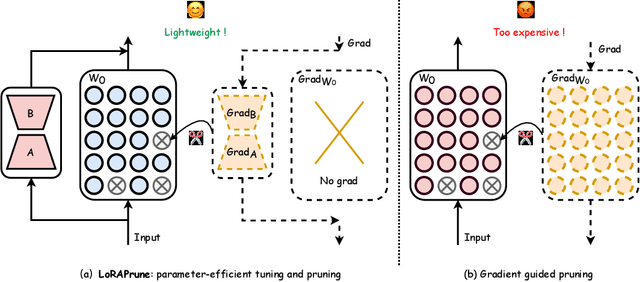
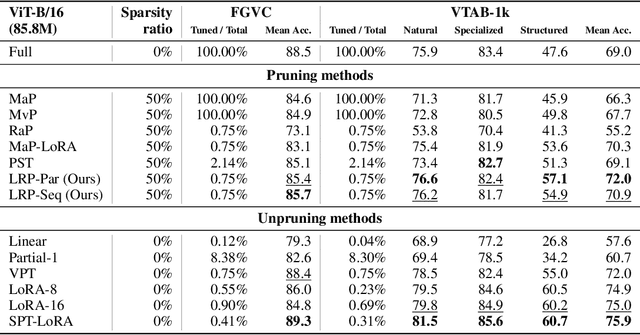
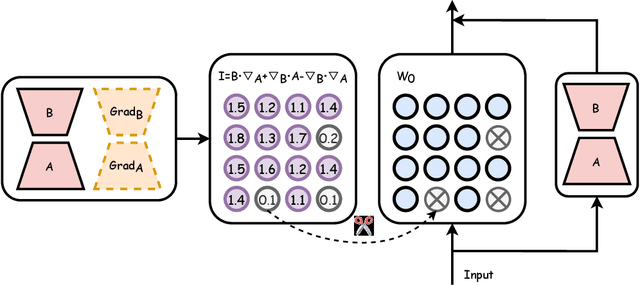
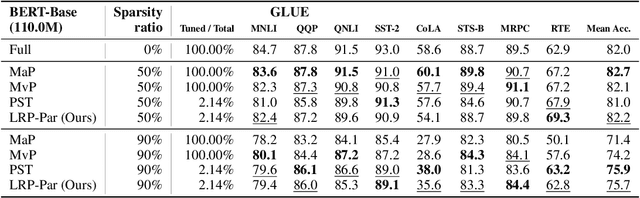
Large pre-trained models (LPMs), such as LLaMA and ViT-G, have shown exceptional performance across various tasks. Although parameter-efficient fine-tuning (PEFT) has emerged to cheaply fine-tune these large models on downstream tasks, their deployment is still hindered by the vast model scale and computational costs. Neural network pruning offers a solution for model compression by removing redundant parameters, but most existing methods rely on computing parameter gradients. However, obtaining the gradients is computationally prohibitive for LPMs, which necessitates the exploration of alternative approaches. To this end, we propose a unified framework for efficient fine-tuning and deployment of LPMs, termed LoRAPrune. We first design a PEFT-aware pruning criterion, which utilizes the values and gradients of Low-Rank Adaption (LoRA), rather than the gradients of pre-trained parameters for importance estimation. We then propose an iterative pruning procedure to remove redundant parameters while maximizing the advantages of PEFT. Thus, our LoRAPrune delivers an accurate, compact model for efficient inference in a highly cost-effective manner. Experimental results on various tasks demonstrate that our method achieves state-of-the-art results. For instance, in the VTAB-1k benchmark, LoRAPrune utilizes only 0.76% of the trainable parameters and outperforms magnitude and movement pruning methods by a significant margin, achieving a mean Top-1 accuracy that is 5.7% and 4.3% higher, respectively. Moreover, our approach achieves comparable performance to PEFT methods, highlighting its efficacy in delivering high-quality results while benefiting from the advantages of pruning.
A Geometric Perspective on Diffusion Models
May 31, 2023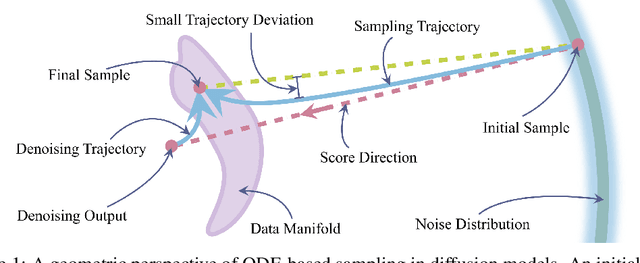
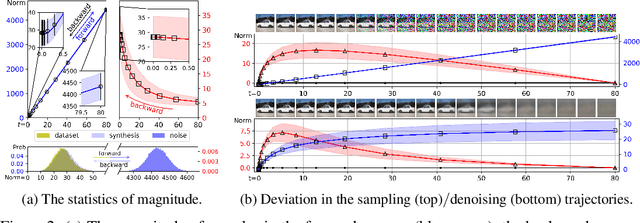

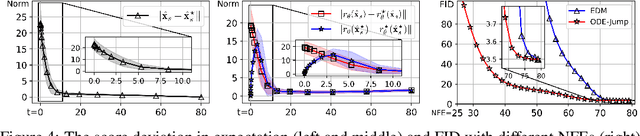
Recent years have witnessed significant progress in developing efficient training and fast sampling approaches for diffusion models. A recent remarkable advancement is the use of stochastic differential equations (SDEs) to describe data perturbation and generative modeling in a unified mathematical framework. In this paper, we reveal several intriguing geometric structures of diffusion models and contribute a simple yet powerful interpretation to their sampling dynamics. Through carefully inspecting a popular variance-exploding SDE and its marginal-preserving ordinary differential equation (ODE) for sampling, we discover that the data distribution and the noise distribution are smoothly connected with an explicit, quasi-linear sampling trajectory, and another implicit denoising trajectory, which even converges faster in terms of visual quality. We also establish a theoretical relationship between the optimal ODE-based sampling and the classic mean-shift (mode-seeking) algorithm, with which we can characterize the asymptotic behavior of diffusion models and identify the score deviation. These new geometric observations enable us to improve previous sampling algorithms, re-examine latent interpolation, as well as re-explain the working principles of distillation-based fast sampling techniques.
StyleAvatar3D: Leveraging Image-Text Diffusion Models for High-Fidelity 3D Avatar Generation
May 31, 2023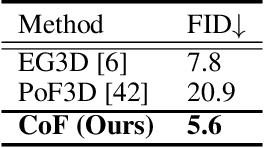
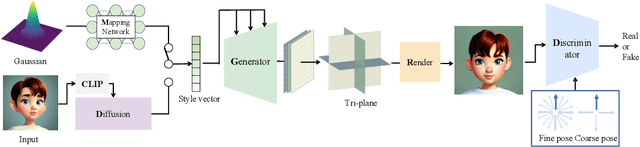


The recent advancements in image-text diffusion models have stimulated research interest in large-scale 3D generative models. Nevertheless, the limited availability of diverse 3D resources presents significant challenges to learning. In this paper, we present a novel method for generating high-quality, stylized 3D avatars that utilizes pre-trained image-text diffusion models for data generation and a Generative Adversarial Network (GAN)-based 3D generation network for training. Our method leverages the comprehensive priors of appearance and geometry offered by image-text diffusion models to generate multi-view images of avatars in various styles. During data generation, we employ poses extracted from existing 3D models to guide the generation of multi-view images. To address the misalignment between poses and images in data, we investigate view-specific prompts and develop a coarse-to-fine discriminator for GAN training. We also delve into attribute-related prompts to increase the diversity of the generated avatars. Additionally, we develop a latent diffusion model within the style space of StyleGAN to enable the generation of avatars based on image inputs. Our approach demonstrates superior performance over current state-of-the-art methods in terms of visual quality and diversity of the produced avatars.
Learning Conditional Attributes for Compositional Zero-Shot Learning
May 29, 2023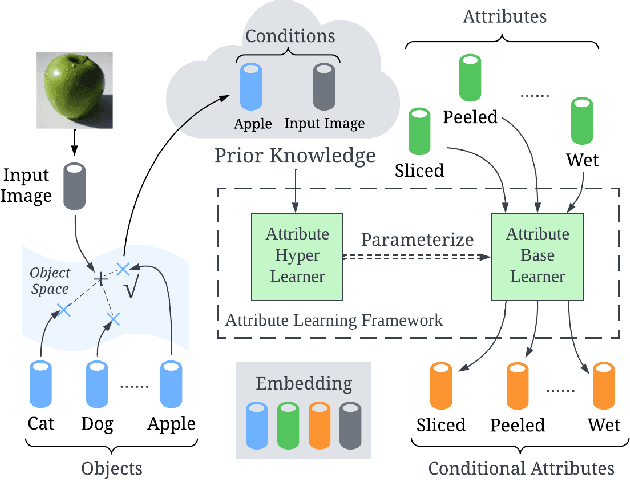

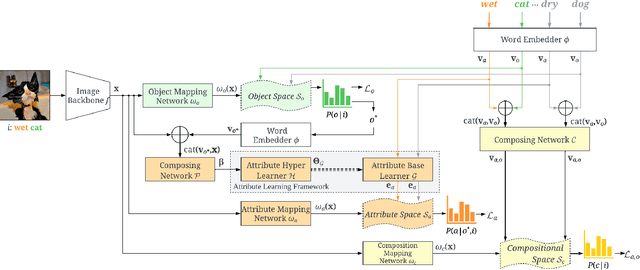
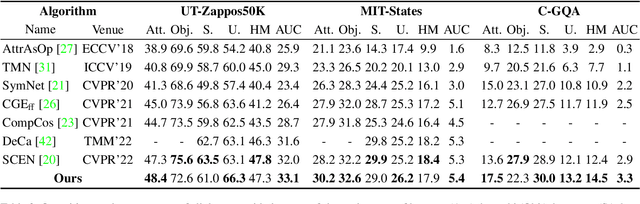
Compositional Zero-Shot Learning (CZSL) aims to train models to recognize novel compositional concepts based on learned concepts such as attribute-object combinations. One of the challenges is to model attributes interacted with different objects, e.g., the attribute ``wet" in ``wet apple" and ``wet cat" is different. As a solution, we provide analysis and argue that attributes are conditioned on the recognized object and input image and explore learning conditional attribute embeddings by a proposed attribute learning framework containing an attribute hyper learner and an attribute base learner. By encoding conditional attributes, our model enables to generate flexible attribute embeddings for generalization from seen to unseen compositions. Experiments on CZSL benchmarks, including the more challenging C-GQA dataset, demonstrate better performances compared with other state-of-the-art approaches and validate the importance of learning conditional attributes. Code is available at https://github.com/wqshmzh/CANet-CZSL
Matcher: Segment Anything with One Shot Using All-Purpose Feature Matching
May 22, 2023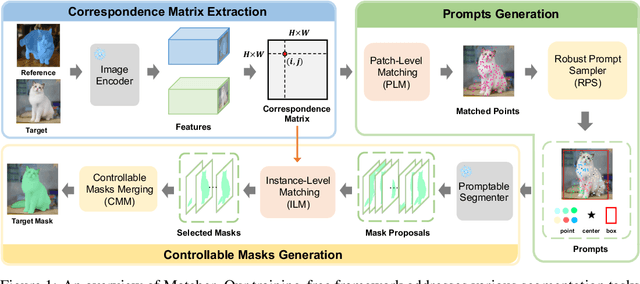
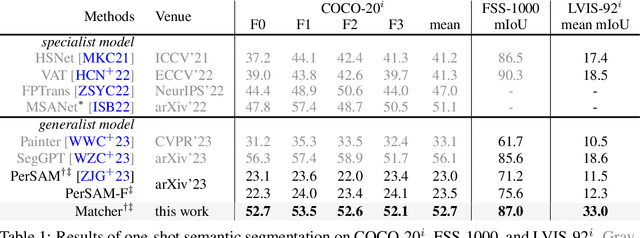
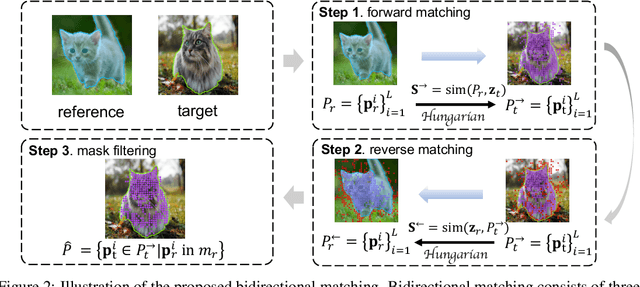
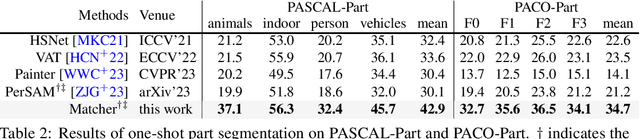
Powered by large-scale pre-training, vision foundation models exhibit significant potential in open-world image understanding. Even though individual models have limited capabilities, combining multiple such models properly can lead to positive synergies and unleash their full potential. In this work, we present Matcher, which segments anything with one shot by integrating an all-purpose feature extraction model and a class-agnostic segmentation model. Naively connecting the models results in unsatisfying performance, e.g., the models tend to generate matching outliers and false-positive mask fragments. To address these issues, we design a bidirectional matching strategy for accurate cross-image semantic dense matching and a robust prompt sampler for mask proposal generation. In addition, we propose a novel instance-level matching strategy for controllable mask merging. The proposed Matcher method delivers impressive generalization performance across various segmentation tasks, all without training. For example, it achieves 52.7% mIoU on COCO-20$^i$ for one-shot semantic segmentation, surpassing the state-of-the-art specialist model by 1.6%. In addition, our visualization results show open-world generality and flexibility on images in the wild. The code shall be released at https://github.com/aim-uofa/Matcher.
Zero-Shot Video Editing Using Off-The-Shelf Image Diffusion Models
Apr 13, 2023
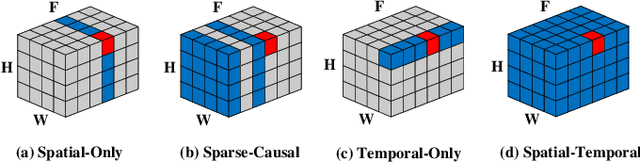

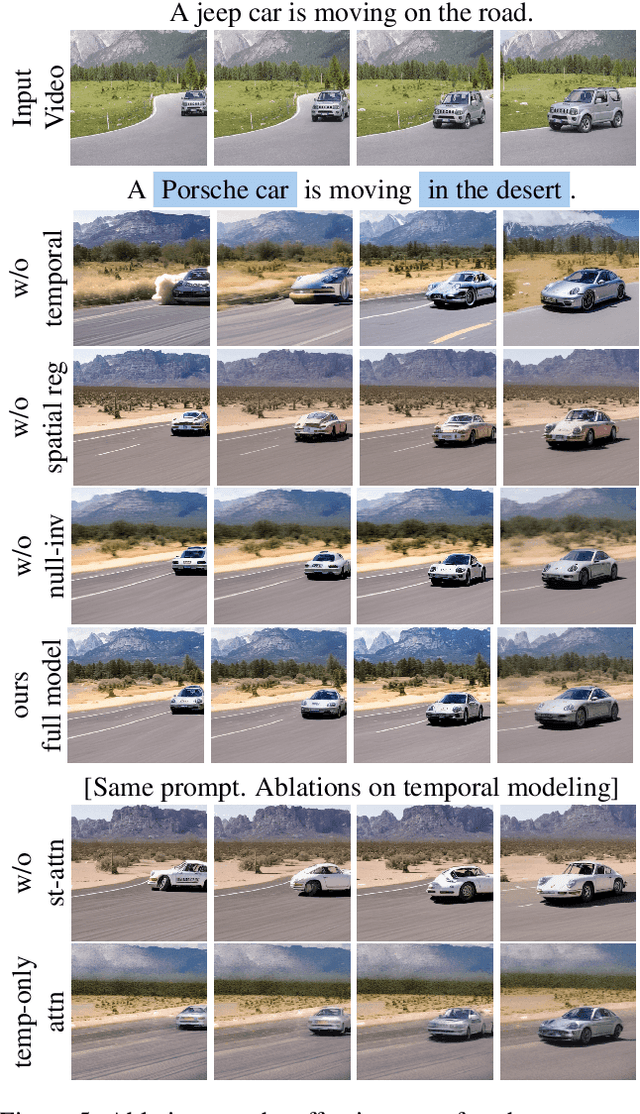
Large-scale text-to-image diffusion models achieve unprecedented success in image generation and editing. However, how to extend such success to video editing is unclear. Recent initial attempts at video editing require significant text-to-video data and computation resources for training, which is often not accessible. In this work, we propose vid2vid-zero, a simple yet effective method for zero-shot video editing. Our vid2vid-zero leverages off-the-shelf image diffusion models, and doesn't require training on any video. At the core of our method is a null-text inversion module for text-to-video alignment, a cross-frame modeling module for temporal consistency, and a spatial regularization module for fidelity to the original video. Without any training, we leverage the dynamic nature of the attention mechanism to enable bi-directional temporal modeling at test time. Experiments and analyses show promising results in editing attributes, subjects, places, etc., in real-world videos. Code is made available at \url{https://github.com/baaivision/vid2vid-zero}.
SegGPT: Segmenting Everything In Context
Apr 06, 2023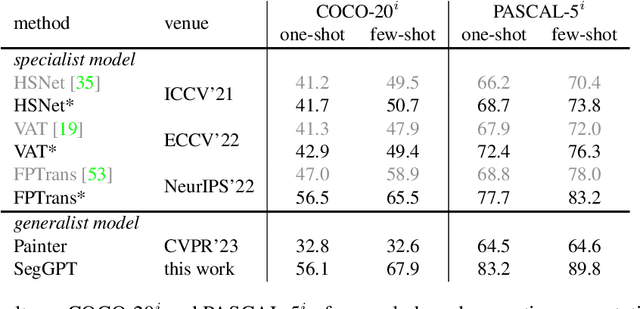
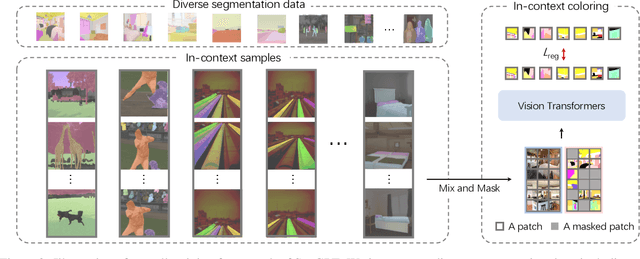
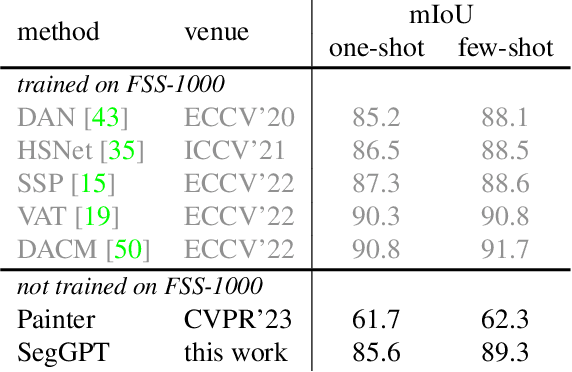
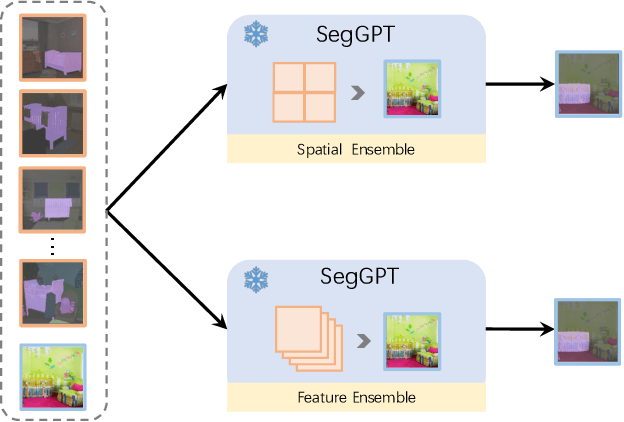
We present SegGPT, a generalist model for segmenting everything in context. We unify various segmentation tasks into a generalist in-context learning framework that accommodates different kinds of segmentation data by transforming them into the same format of images. The training of SegGPT is formulated as an in-context coloring problem with random color mapping for each data sample. The objective is to accomplish diverse tasks according to the context, rather than relying on specific colors. After training, SegGPT can perform arbitrary segmentation tasks in images or videos via in-context inference, such as object instance, stuff, part, contour, and text. SegGPT is evaluated on a broad range of tasks, including few-shot semantic segmentation, video object segmentation, semantic segmentation, and panoptic segmentation. Our results show strong capabilities in segmenting in-domain and out-of-domain targets, either qualitatively or quantitatively.
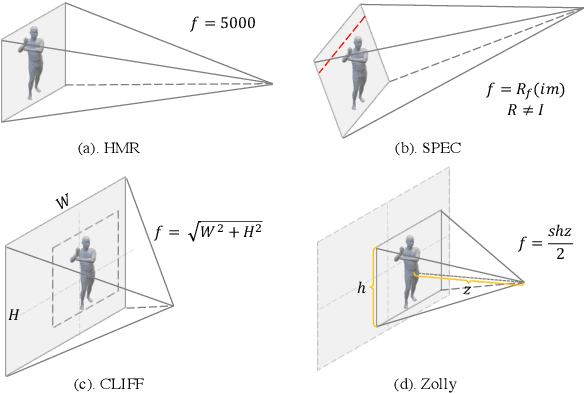
Zolly: Zoom Focal Length Correctly for Perspective-Distorted Human Mesh Reconstruction
Mar 24, 2023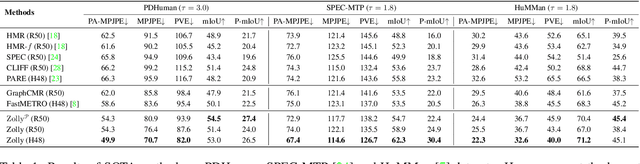
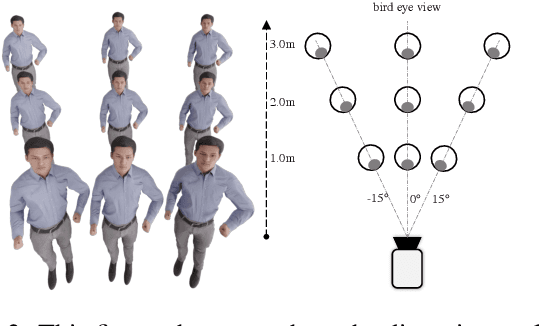
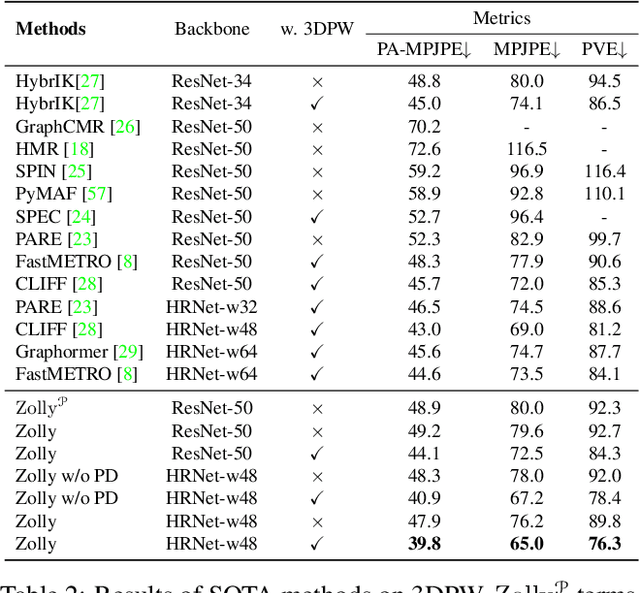
As it is hard to calibrate single-view RGB images in the wild, existing 3D human mesh reconstruction (3DHMR) methods either use a constant large focal length or estimate one based on the background environment context, which can not tackle the problem of the torso, limb, hand or face distortion caused by perspective camera projection when the camera is close to the human body. The naive focal length assumptions can harm this task with the incorrectly formulated projection matrices. To solve this, we propose Zolly, the first 3DHMR method focusing on perspective-distorted images. Our approach begins with analysing the reason for perspective distortion, which we find is mainly caused by the relative location of the human body to the camera center. We propose a new camera model and a novel 2D representation, termed distortion image, which describes the 2D dense distortion scale of the human body. We then estimate the distance from distortion scale features rather than environment context features. Afterwards, we integrate the distortion feature with image features to reconstruct the body mesh. To formulate the correct projection matrix and locate the human body position, we simultaneously use perspective and weak-perspective projection loss. Since existing datasets could not handle this task, we propose the first synthetic dataset PDHuman and extend two real-world datasets tailored for this task, all containing perspective-distorted human images. Extensive experiments show that Zolly outperforms existing state-of-the-art methods on both perspective-distorted datasets and the standard benchmark (3DPW).