 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChristopher Amato
Vision and Language Navigation in the Real World via Online Visual Language Mapping
Oct 16, 2023
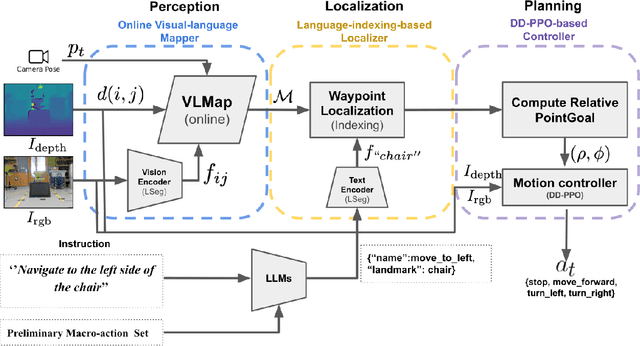


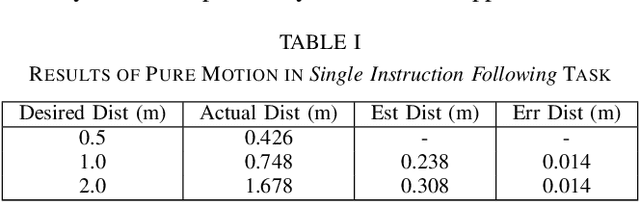
Navigating in unseen environments is crucial for mobile robots. Enhancing them with the ability to follow instructions in natural language will further improve navigation efficiency in unseen cases. However, state-of-the-art (SOTA) vision-and-language navigation (VLN) methods are mainly evaluated in simulation, neglecting the complex and noisy real world. Directly transferring SOTA navigation policies trained in simulation to the real world is challenging due to the visual domain gap and the absence of prior knowledge about unseen environments. In this work, we propose a novel navigation framework to address the VLN task in the real world. Utilizing the powerful foundation models, the proposed framework includes four key components: (1) an LLMs-based instruction parser that converts the language instruction into a sequence of pre-defined macro-action descriptions, (2) an online visual-language mapper that builds a real-time visual-language map to maintain a spatial and semantic understanding of the unseen environment, (3) a language indexing-based localizer that grounds each macro-action description into a waypoint location on the map, and (4) a DD-PPO-based local controller that predicts the action. We evaluate the proposed pipeline on an Interbotix LoCoBot WX250 in an unseen lab environment. Without any fine-tuning, our pipeline significantly outperforms the SOTA VLN baseline in the real world.
Multi-Agent Reinforcement Learning Based on Representational Communication for Large-Scale Traffic Signal Control
Oct 03, 2023Traffic signal control (TSC) is a challenging problem within intelligent transportation systems and has been tackled using multi-agent reinforcement learning (MARL). While centralized approaches are often infeasible for large-scale TSC problems, decentralized approaches provide scalability but introduce new challenges, such as partial observability. Communication plays a critical role in decentralized MARL, as agents must learn to exchange information using messages to better understand the system and achieve effective coordination. Deep MARL has been used to enable inter-agent communication by learning communication protocols in a differentiable manner. However, many deep MARL communication frameworks proposed for TSC allow agents to communicate with all other agents at all times, which can add to the existing noise in the system and degrade overall performance. In this study, we propose a communication-based MARL framework for large-scale TSC. Our framework allows each agent to learn a communication policy that dictates "which" part of the message is sent "to whom". In essence, our framework enables agents to selectively choose the recipients of their messages and exchange variable length messages with them. This results in a decentralized and flexible communication mechanism in which agents can effectively use the communication channel only when necessary. We designed two networks, a synthetic $4 \times 4$ grid network and a real-world network based on the Pasubio neighborhood in Bologna. Our framework achieved the lowest network congestion compared to related methods, with agents utilizing $\sim 47-65 \%$ of the communication channel. Ablation studies further demonstrated the effectiveness of the communication policies learned within our framework.
On-Robot Bayesian Reinforcement Learning for POMDPs
Jul 22, 2023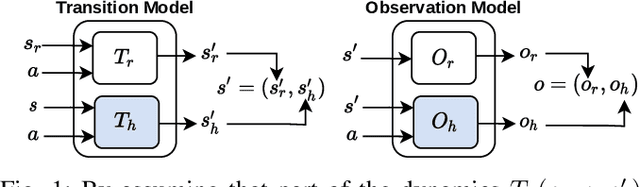
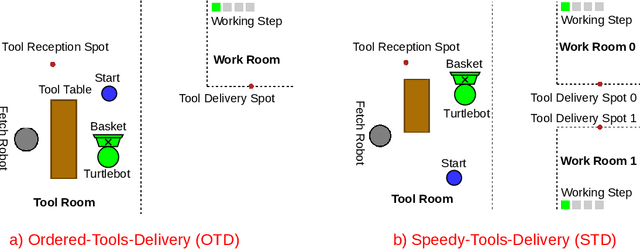

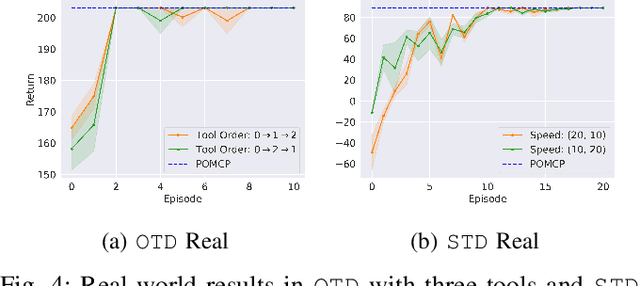
Robot learning is often difficult due to the expense of gathering data. The need for large amounts of data can, and should, be tackled with effective algorithms and leveraging expert information on robot dynamics. Bayesian reinforcement learning (BRL), thanks to its sample efficiency and ability to exploit prior knowledge, is uniquely positioned as such a solution method. Unfortunately, the application of BRL has been limited due to the difficulties of representing expert knowledge as well as solving the subsequent inference problem. This paper advances BRL for robotics by proposing a specialized framework for physical systems. In particular, we capture this knowledge in a factored representation, then demonstrate the posterior factorizes in a similar shape, and ultimately formalize the model in a Bayesian framework. We then introduce a sample-based online solution method, based on Monte-Carlo tree search and particle filtering, specialized to solve the resulting model. This approach can, for example, utilize typical low-level robot simulators and handle uncertainty over unknown dynamics of the environment. We empirically demonstrate its efficiency by performing on-robot learning in two human-robot interaction tasks with uncertainty about human behavior, achieving near-optimal performance after only a handful of real-world episodes. A video of learned policies is at https://youtu.be/H9xp60ngOes.
Improving Deep Policy Gradients with Value Function Search
Feb 20, 2023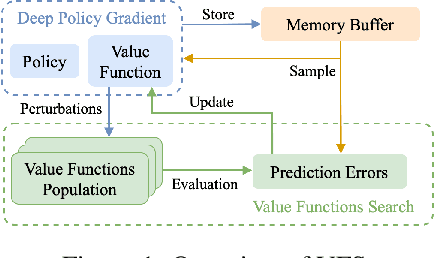
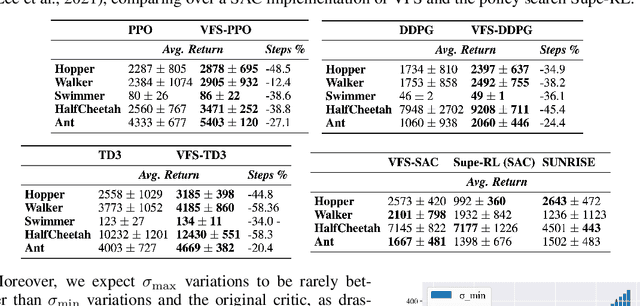
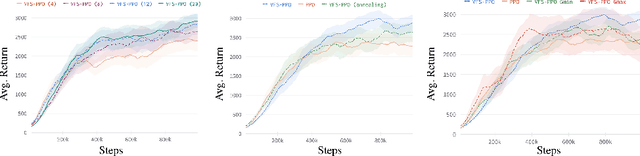
Deep Policy Gradient (PG) algorithms employ value networks to drive the learning of parameterized policies and reduce the variance of the gradient estimates. However, value function approximation gets stuck in local optima and struggles to fit the actual return, limiting the variance reduction efficacy and leading policies to sub-optimal performance. This paper focuses on improving value approximation and analyzing the effects on Deep PG primitives such as value prediction, variance reduction, and correlation of gradient estimates with the true gradient. To this end, we introduce a Value Function Search that employs a population of perturbed value networks to search for a better approximation. Our framework does not require additional environment interactions, gradient computations, or ensembles, providing a computationally inexpensive approach to enhance the supervised learning task on which value networks train. Crucially, we show that improving Deep PG primitives results in improved sample efficiency and policies with higher returns using common continuous control benchmark domains.
Safe Deep Reinforcement Learning by Verifying Task-Level Properties
Feb 20, 2023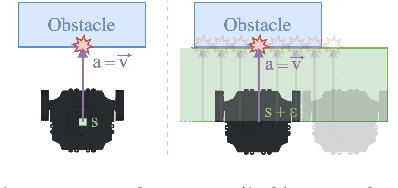
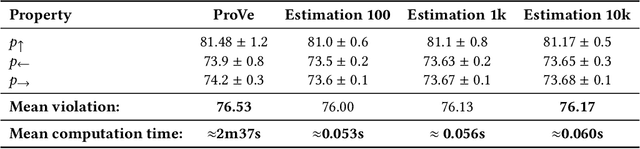
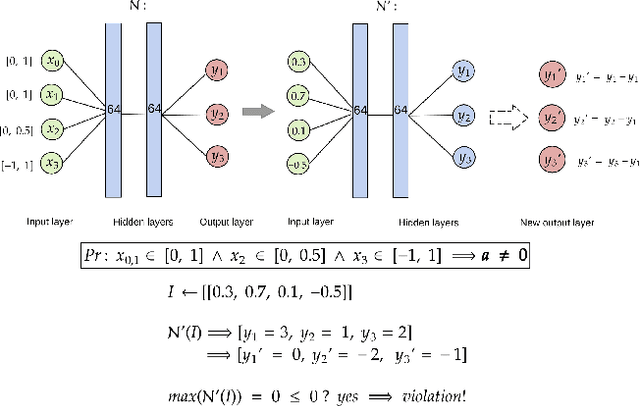

Cost functions are commonly employed in Safe Deep Reinforcement Learning (DRL). However, the cost is typically encoded as an indicator function due to the difficulty of quantifying the risk of policy decisions in the state space. Such an encoding requires the agent to visit numerous unsafe states to learn a cost-value function to drive the learning process toward safety. Hence, increasing the number of unsafe interactions and decreasing sample efficiency. In this paper, we investigate an alternative approach that uses domain knowledge to quantify the risk in the proximity of such states by defining a violation metric. This metric is computed by verifying task-level properties, shaped as input-output conditions, and it is used as a penalty to bias the policy away from unsafe states without learning an additional value function. We investigate the benefits of using the violation metric in standard Safe DRL benchmarks and robotic mapless navigation tasks. The navigation experiments bridge the gap between Safe DRL and robotics, introducing a framework that allows rapid testing on real robots. Our experiments show that policies trained with the violation penalty achieve higher performance over Safe DRL baselines and significantly reduce the number of visited unsafe states.
Trajectory-Aware Eligibility Traces for Off-Policy Reinforcement Learning
Jan 26, 2023

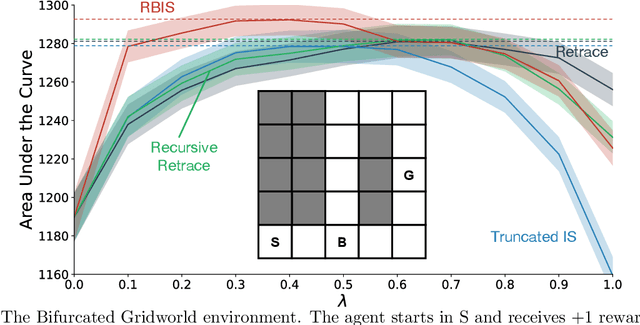
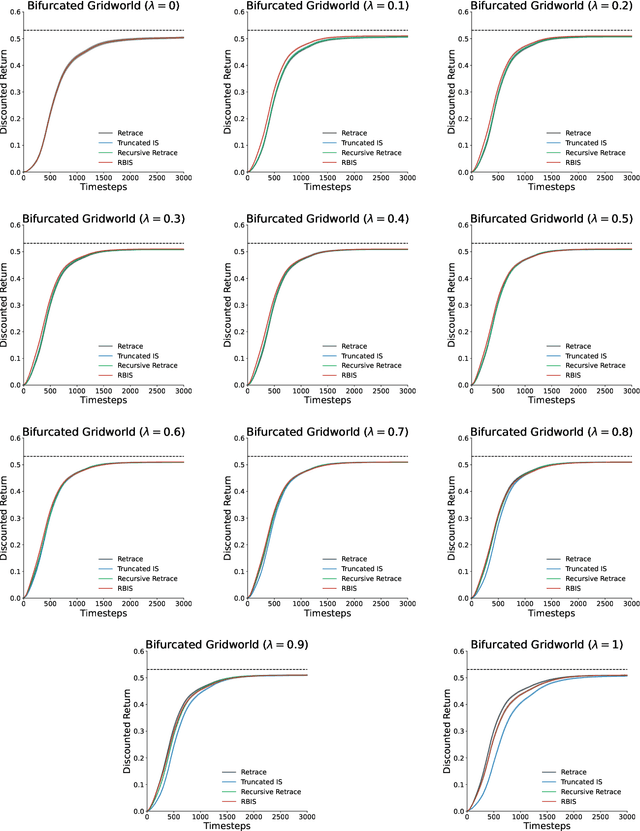
Off-policy learning from multistep returns is crucial for sample-efficient reinforcement learning, but counteracting off-policy bias without exacerbating variance is challenging. Classically, off-policy bias is corrected in a per-decision manner: past temporal-difference errors are re-weighted by the instantaneous Importance Sampling (IS) ratio after each action via eligibility traces. Many off-policy algorithms rely on this mechanism, along with differing protocols for cutting the IS ratios to combat the variance of the IS estimator. Unfortunately, once a trace has been fully cut, the effect cannot be reversed. This has led to the development of credit-assignment strategies that account for multiple past experiences at a time. These trajectory-aware methods have not been extensively analyzed, and their theoretical justification remains uncertain. In this paper, we propose a multistep operator that can express both per-decision and trajectory-aware methods. We prove convergence conditions for our operator in the tabular setting, establishing the first guarantees for several existing methods as well as many new ones. Finally, we introduce Recency-Bounded Importance Sampling (RBIS), which leverages trajectory awareness to perform robustly across $\lambda$-values in an off-policy control task.
Leveraging Fully Observable Policies for Learning under Partial Observability
Nov 10, 2022
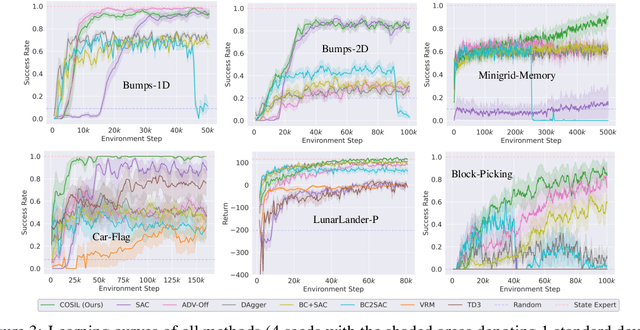
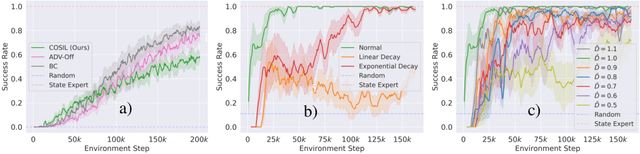
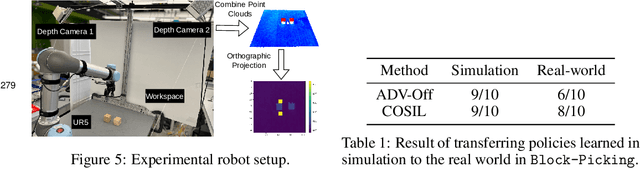
Reinforcement learning in partially observable domains is challenging due to the lack of observable state information. Thankfully, learning offline in a simulator with such state information is often possible. In particular, we propose a method for partially observable reinforcement learning that uses a fully observable policy (which we call a state expert) during offline training to improve online performance. Based on Soft Actor-Critic (SAC), our agent balances performing actions similar to the state expert and getting high returns under partial observability. Our approach can leverage the fully-observable policy for exploration and parts of the domain that are fully observable while still being able to learn under partial observability. On six robotics domains, our method outperforms pure imitation, pure reinforcement learning, the sequential or parallel combination of both types, and a recent state-of-the-art method in the same setting. A successful policy transfer to a physical robot in a manipulation task from pixels shows our approach's practicality in learning interesting policies under partial observability.
Asynchronous Actor-Critic for Multi-Agent Reinforcement Learning
Oct 11, 2022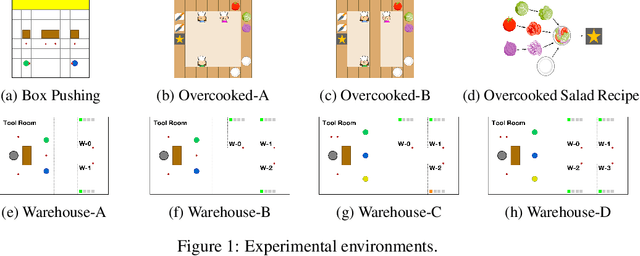



Synchronizing decisions across multiple agents in realistic settings is problematic since it requires agents to wait for other agents to terminate and communicate about termination reliably. Ideally, agents should learn and execute asynchronously instead. Such asynchronous methods also allow temporally extended actions that can take different amounts of time based on the situation and action executed. Unfortunately, current policy gradient methods are not applicable in asynchronous settings, as they assume that agents synchronously reason about action selection at every time step. To allow asynchronous learning and decision-making, we formulate a set of asynchronous multi-agent actor-critic methods that allow agents to directly optimize asynchronous policies in three standard training paradigms: decentralized learning, centralized learning, and centralized training for decentralized execution. Empirical results (in simulation and hardware) in a variety of realistic domains demonstrate the superiority of our approaches in large multi-agent problems and validate the effectiveness of our algorithms for learning high-quality and asynchronous solutions.