 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Understanding of Image and Video Advertisements
Jul 10, 2017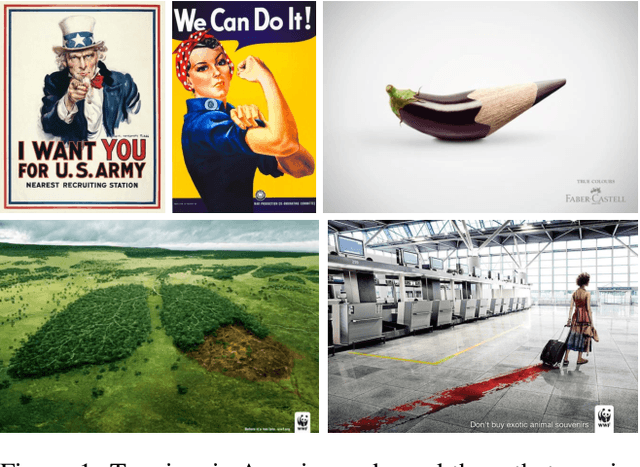
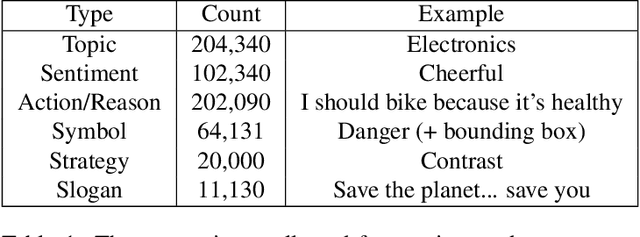

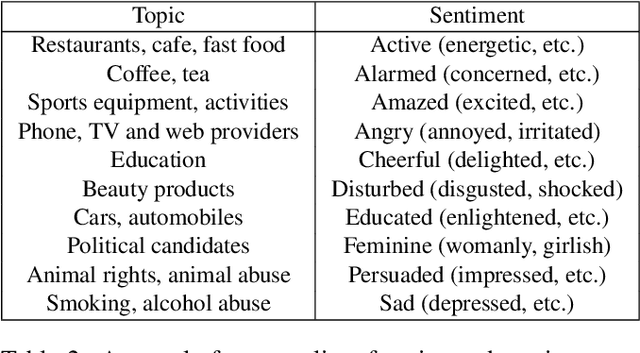
There is more to images than their objective physical content: for example, advertisements are created to persuade a viewer to take a certain action. We propose the novel problem of automatic advertisement understanding. To enable research on this problem, we create two datasets: an image dataset of 64,832 image ads, and a video dataset of 3,477 ads. Our data contains rich annotations encompassing the topic and sentiment of the ads, questions and answers describing what actions the viewer is prompted to take and the reasoning that the ad presents to persuade the viewer ("What should I do according to this ad, and why should I do it?"), and symbolic references ads make (e.g. a dove symbolizes peace). We also analyze the most common persuasive strategies ads use, and the capabilities that computer vision systems should have to understand these strategies. We present baseline classification results for several prediction tasks, including automatically answering questions about the messages of the ads.
OpenSalicon: An Open Source Implementation of the Salicon Saliency Model
Jun 01, 2016

In this technical report, we present our publicly downloadable implementation of the SALICON saliency model. At the time of this writing, SALICON is one of the top performing saliency models on the MIT 300 fixation prediction dataset which evaluates how well an algorithm is able to predict where humans would look in a given image. Recently, numerous models have achieved state-of-the-art performance on this benchmark, but none of the top 5 performing models (including SALICON) are available for download. To address this issue, we have created a publicly downloadable implementation of the SALICON model. It is our hope that our model will engender further research in visual attention modeling by providing a baseline for comparison of other algorithms and a platform for extending this implementation. The model we provide supports both training and testing, enabling researchers to quickly fine-tune the model on their own dataset. We also provide a pre-trained model and code for those users who only need to generate saliency maps for images without training their own model.
Seeing Behind the Camera: Identifying the Authorship of a Photograph
Jun 01, 2016


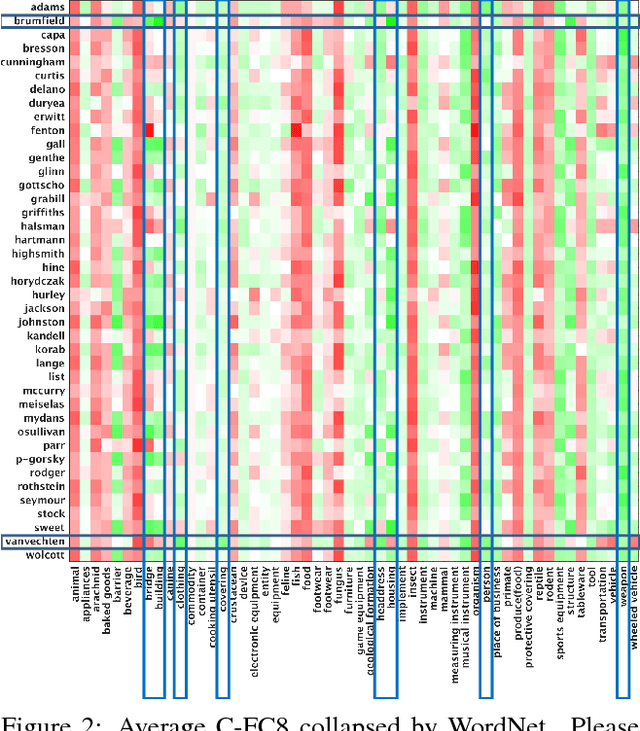
We introduce the novel problem of identifying the photographer behind a photograph. To explore the feasibility of current computer vision techniques to address this problem, we created a new dataset of over 180,000 images taken by 41 well-known photographers. Using this dataset, we examined the effectiveness of a variety of features (low and high-level, including CNN features) at identifying the photographer. We also trained a new deep convolutional neural network for this task. Our results show that high-level features greatly outperform low-level features. We provide qualitative results using these learned models that give insight into our method's ability to distinguish between photographers, and allow us to draw interesting conclusions about what specific photographers shoot. We also demonstrate two applications of our method.