 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChristopher D. Manning
Simpler but More Accurate Semantic Dependency Parsing
Jul 03, 2018

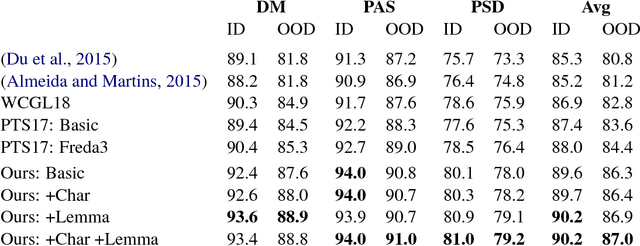

While syntactic dependency annotations concentrate on the surface or functional structure of a sentence, semantic dependency annotations aim to capture between-word relationships that are more closely related to the meaning of a sentence, using graph-structured representations. We extend the LSTM-based syntactic parser of Dozat and Manning (2017) to train on and generate these graph structures. The resulting system on its own achieves state-of-the-art performance, beating the previous, substantially more complex state-of-the-art system by 0.6% labeled F1. Adding linguistically richer input representations pushes the margin even higher, allowing us to beat it by 1.9% labeled F1.
Compositional Attention Networks for Machine Reasoning
Apr 24, 2018
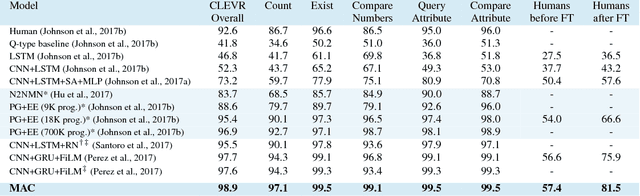
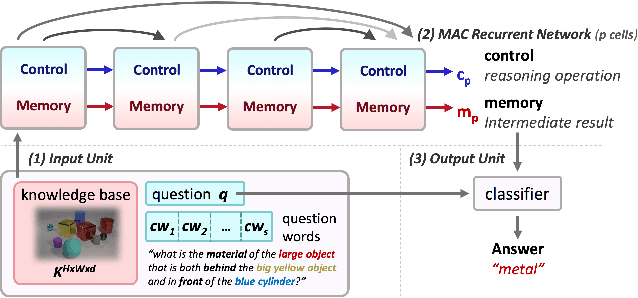
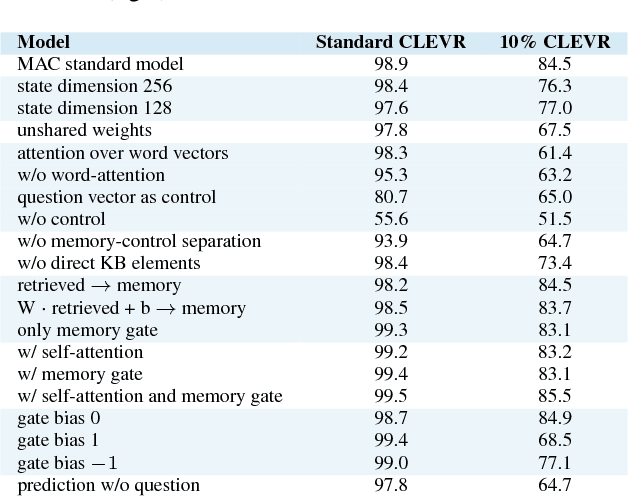
We present the MAC network, a novel fully differentiable neural network architecture, designed to facilitate explicit and expressive reasoning. MAC moves away from monolithic black-box neural architectures towards a design that encourages both transparency and versatility. The model approaches problems by decomposing them into a series of attention-based reasoning steps, each performed by a novel recurrent Memory, Attention, and Composition (MAC) cell that maintains a separation between control and memory. By stringing the cells together and imposing structural constraints that regulate their interaction, MAC effectively learns to perform iterative reasoning processes that are directly inferred from the data in an end-to-end approach. We demonstrate the model's strength, robustness and interpretability on the challenging CLEVR dataset for visual reasoning, achieving a new state-of-the-art 98.9% accuracy, halving the error rate of the previous best model. More importantly, we show that the model is computationally-efficient and data-efficient, in particular requiring 5x less data than existing models to achieve strong results.
Sentences with Gapping: Parsing and Reconstructing Elided Predicates
Apr 18, 2018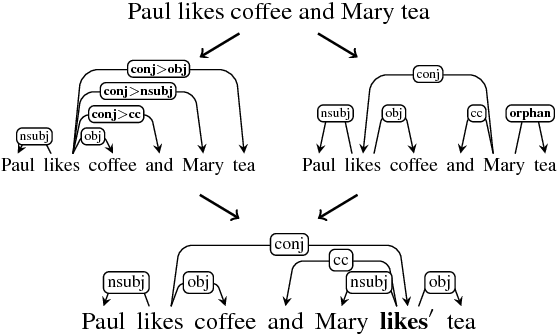
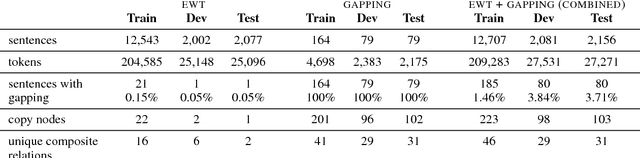


Sentences with gapping, such as Paul likes coffee and Mary tea, lack an overt predicate to indicate the relation between two or more arguments. Surface syntax representations of such sentences are often produced poorly by parsers, and even if correct, not well suited to downstream natural language understanding tasks such as relation extraction that are typically designed to extract information from sentences with canonical clause structure. In this paper, we present two methods for parsing to a Universal Dependencies graph representation that explicitly encodes the elided material with additional nodes and edges. We find that both methods can reconstruct elided material from dependency trees with high accuracy when the parser correctly predicts the existence of a gap. We further demonstrate that one of our methods can be applied to other languages based on a case study on Swedish.
* To be presented at NAACL 2018
A Copy-Augmented Sequence-to-Sequence Architecture Gives Good Performance on Task-Oriented Dialogue
Aug 14, 2017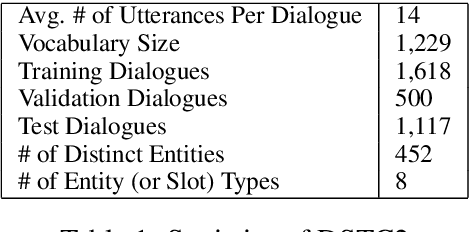
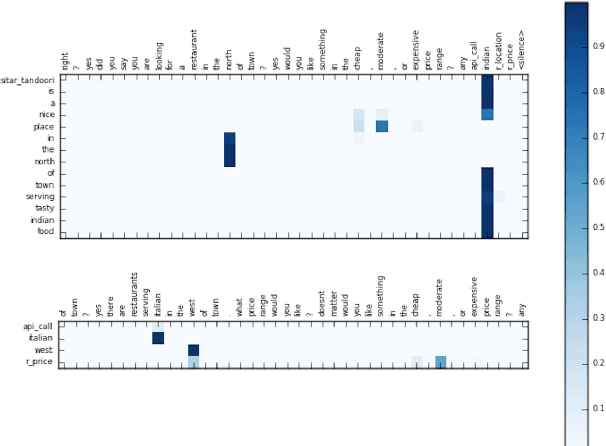
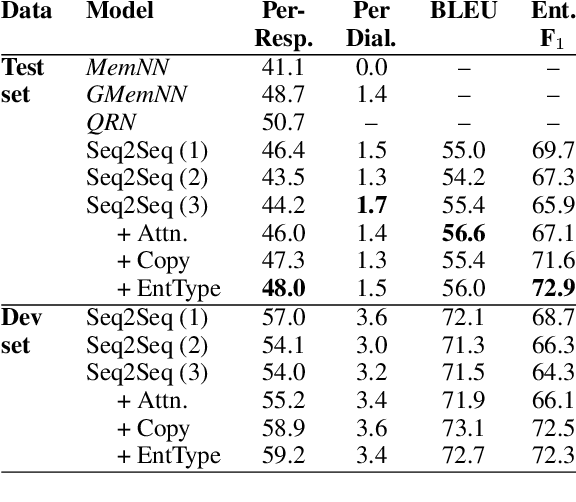

Task-oriented dialogue focuses on conversational agents that participate in user-initiated dialogues on domain-specific topics. In contrast to chatbots, which simply seek to sustain open-ended meaningful discourse, existing task-oriented agents usually explicitly model user intent and belief states. This paper examines bypassing such an explicit representation by depending on a latent neural embedding of state and learning selective attention to dialogue history together with copying to incorporate relevant prior context. We complement recent work by showing the effectiveness of simple sequence-to-sequence neural architectures with a copy mechanism. Our model outperforms more complex memory-augmented models by 7% in per-response generation and is on par with the current state-of-the-art on DSTC2.
Key-Value Retrieval Networks for Task-Oriented Dialogue
Jul 14, 2017

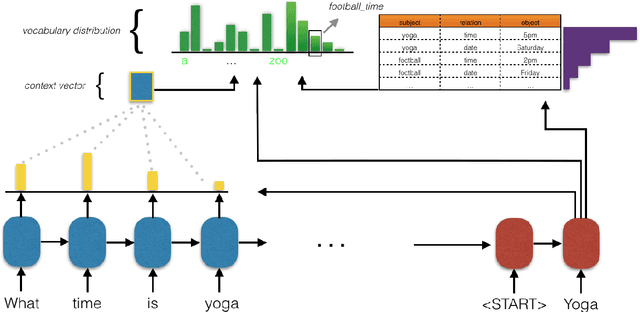
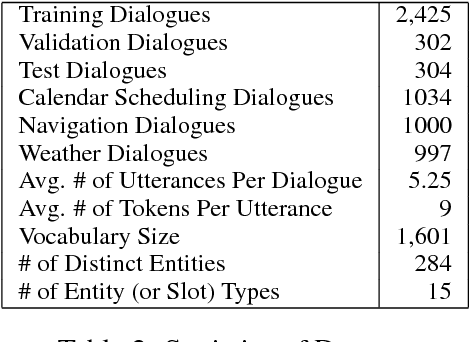
Neural task-oriented dialogue systems often struggle to smoothly interface with a knowledge base. In this work, we seek to address this problem by proposing a new neural dialogue agent that is able to effectively sustain grounded, multi-domain discourse through a novel key-value retrieval mechanism. The model is end-to-end differentiable and does not need to explicitly model dialogue state or belief trackers. We also release a new dataset of 3,031 dialogues that are grounded through underlying knowledge bases and span three distinct tasks in the in-car personal assistant space: calendar scheduling, weather information retrieval, and point-of-interest navigation. Our architecture is simultaneously trained on data from all domains and significantly outperforms a competitive rule-based system and other existing neural dialogue architectures on the provided domains according to both automatic and human evaluation metrics.
Arc-swift: A Novel Transition System for Dependency Parsing
May 12, 2017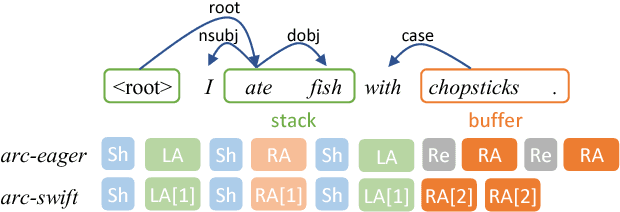
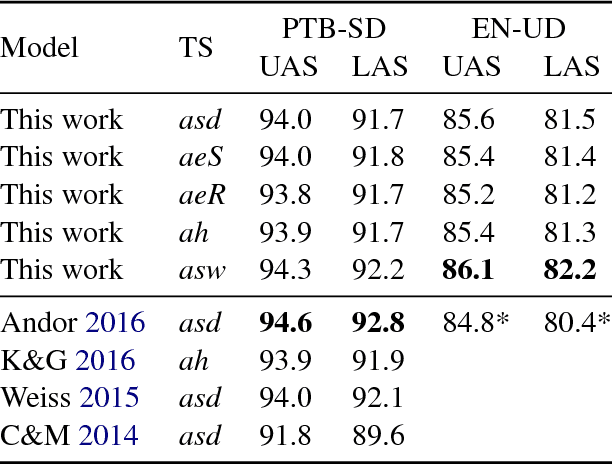

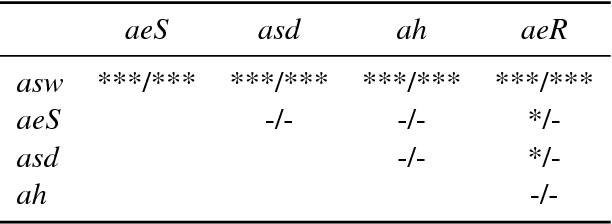
Transition-based dependency parsers often need sequences of local shift and reduce operations to produce certain attachments. Correct individual decisions hence require global information about the sentence context and mistakes cause error propagation. This paper proposes a novel transition system, arc-swift, that enables direct attachments between tokens farther apart with a single transition. This allows the parser to leverage lexical information more directly in transition decisions. Hence, arc-swift can achieve significantly better performance with a very small beam size. Our parsers reduce error by 3.7--7.6% relative to those using existing transition systems on the Penn Treebank dependency parsing task and English Universal Dependencies.
Get To The Point: Summarization with Pointer-Generator Networks
Apr 25, 2017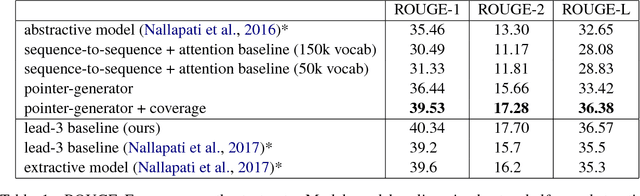
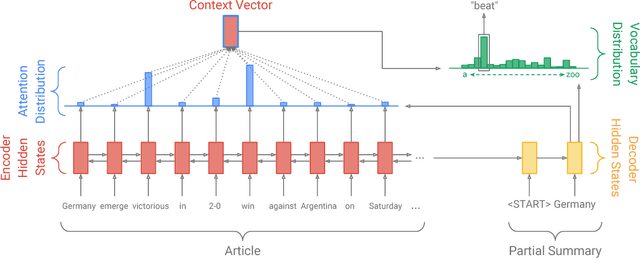
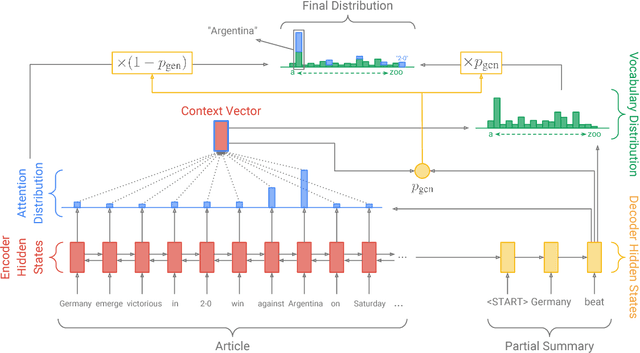
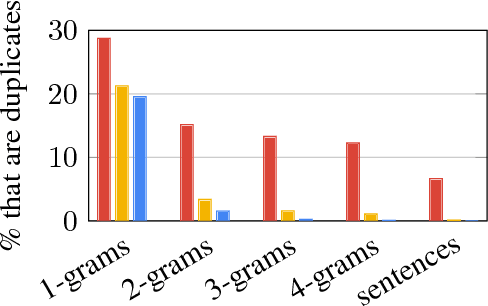
Neural sequence-to-sequence models have provided a viable new approach for abstractive text summarization (meaning they are not restricted to simply selecting and rearranging passages from the original text). However, these models have two shortcomings: they are liable to reproduce factual details inaccurately, and they tend to repeat themselves. In this work we propose a novel architecture that augments the standard sequence-to-sequence attentional model in two orthogonal ways. First, we use a hybrid pointer-generator network that can copy words from the source text via pointing, which aids accurate reproduction of information, while retaining the ability to produce novel words through the generator. Second, we use coverage to keep track of what has been summarized, which discourages repetition. We apply our model to the CNN / Daily Mail summarization task, outperforming the current abstractive state-of-the-art by at least 2 ROUGE points.
Deep Biaffine Attention for Neural Dependency Parsing
Mar 10, 2017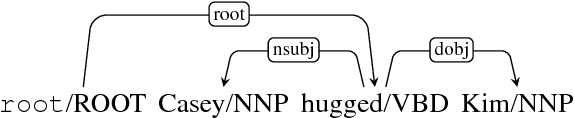
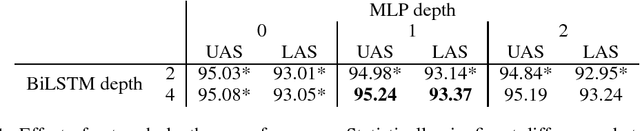
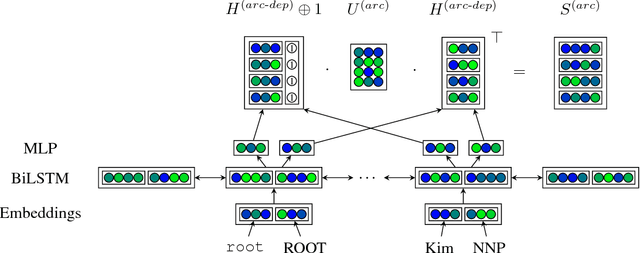

This paper builds off recent work from Kiperwasser & Goldberg (2016) using neural attention in a simple graph-based dependency parser. We use a larger but more thoroughly regularized parser than other recent BiLSTM-based approaches, with biaffine classifiers to predict arcs and labels. Our parser gets state of the art or near state of the art performance on standard treebanks for six different languages, achieving 95.7% UAS and 94.1% LAS on the most popular English PTB dataset. This makes it the highest-performing graph-based parser on this benchmark---outperforming Kiperwasser Goldberg (2016) by 1.8% and 2.2%---and comparable to the highest performing transition-based parser (Kuncoro et al., 2016), which achieves 95.8% UAS and 94.6% LAS. We also show which hyperparameter choices had a significant effect on parsing accuracy, allowing us to achieve large gains over other graph-based approaches.
SceneSeer: 3D Scene Design with Natural Language
Feb 28, 2017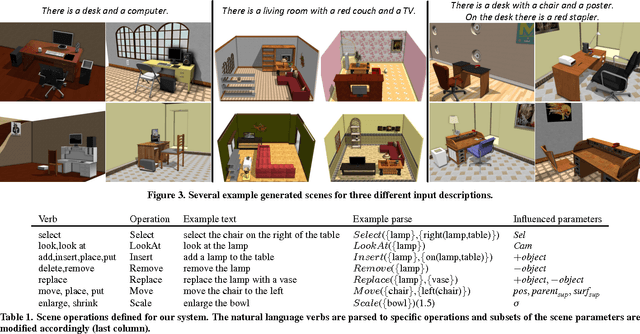

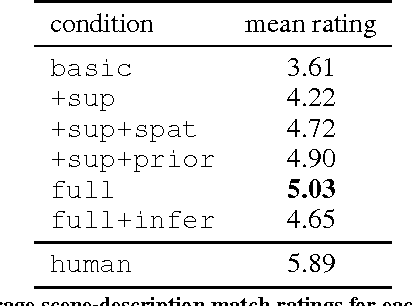

Designing 3D scenes is currently a creative task that requires significant expertise and effort in using complex 3D design interfaces. This effortful design process starts in stark contrast to the easiness with which people can use language to describe real and imaginary environments. We present SceneSeer: an interactive text to 3D scene generation system that allows a user to design 3D scenes using natural language. A user provides input text from which we extract explicit constraints on the objects that should appear in the scene. Given these explicit constraints, the system then uses a spatial knowledge base learned from an existing database of 3D scenes and 3D object models to infer an arrangement of the objects forming a natural scene matching the input description. Using textual commands the user can then iteratively refine the created scene by adding, removing, replacing, and manipulating objects. We evaluate the quality of 3D scenes generated by SceneSeer in a perceptual evaluation experiment where we compare against manually designed scenes and simpler baselines for 3D scene generation. We demonstrate how the generated scenes can be iteratively refined through simple natural language commands.
Deep Reinforcement Learning for Mention-Ranking Coreference Models
Oct 31, 2016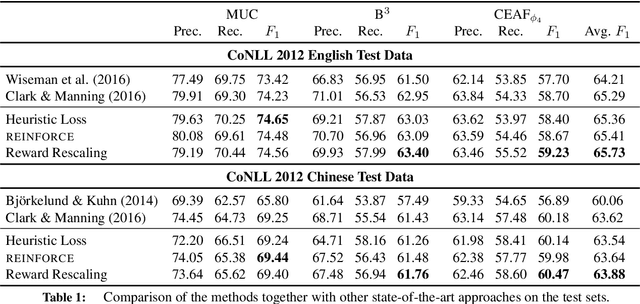
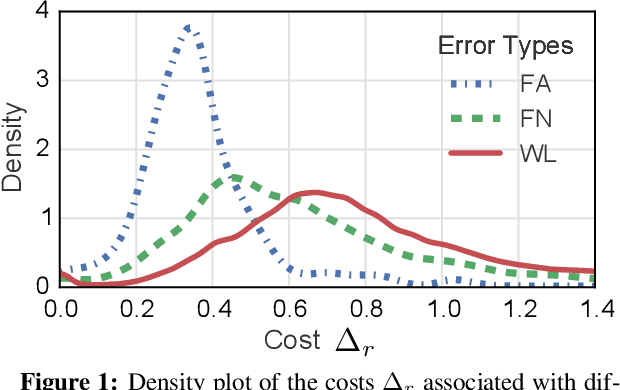


Coreference resolution systems are typically trained with heuristic loss functions that require careful tuning. In this paper we instead apply reinforcement learning to directly optimize a neural mention-ranking model for coreference evaluation metrics. We experiment with two approaches: the REINFORCE policy gradient algorithm and a reward-rescaled max-margin objective. We find the latter to be more effective, resulting in significant improvements over the current state-of-the-art on the English and Chinese portions of the CoNLL 2012 Shared Task.