 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChristoph Feichtenhofer
EGO-TOPO: Environment Affordances from Egocentric Video
Jan 14, 2020
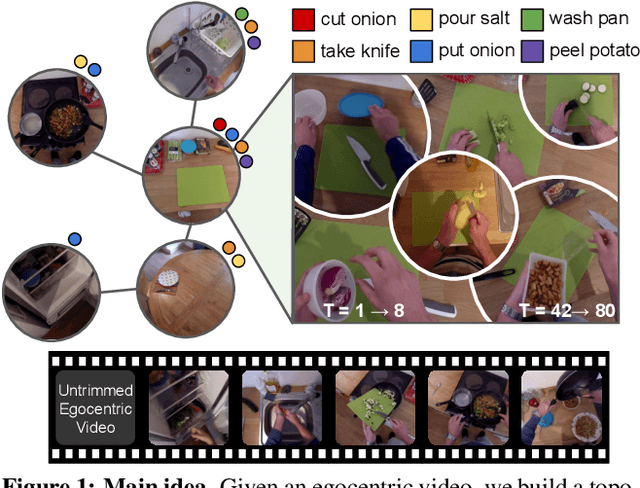
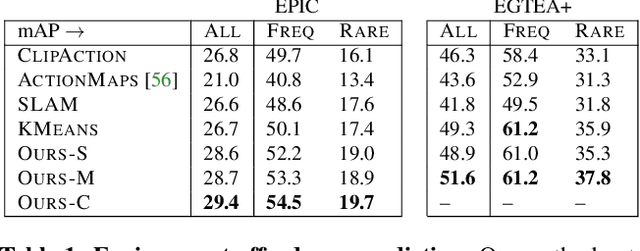

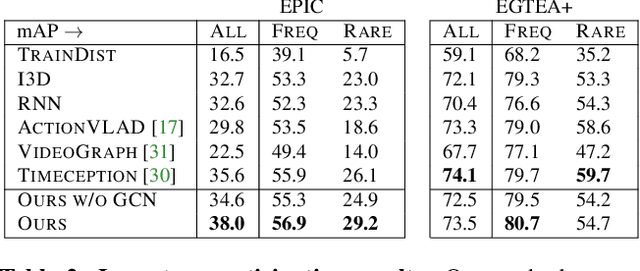
First-person video naturally brings the use of a physical environment to the forefront, since it shows the camera wearer interacting fluidly in a space based on his intentions. However, current methods largely separate the observed actions from the persistent space itself. We introduce a model for environment affordances that is learned directly from egocentric video. The main idea is to gain a human-centric model of a physical space (such as a kitchen) that captures (1) the primary spatial zones of interaction and (2) the likely activities they support. Our approach decomposes a space into a topological map derived from first-person activity, organizing an ego-video into a series of visits to the different zones. Further, we show how to link zones across multiple related environments (e.g., from videos of multiple kitchens) to obtain a consolidated representation of environment functionality. On EPIC-Kitchens and EGTEA+, we demonstrate our approach for learning scene affordances and anticipating future actions in long-form video.
A Multigrid Method for Efficiently Training Video Models
Dec 02, 2019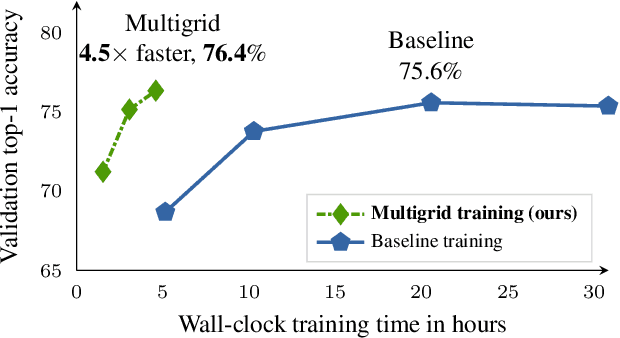

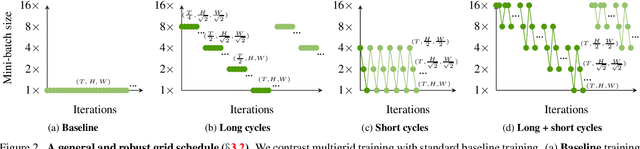

Training competitive deep video models is an order of magnitude slower than training their counterpart image models. Slow training causes long research cycles, which hinders progress in video understanding research. Following standard practice for training image models, video model training assumes a fixed mini-batch shape: a specific number of clips, frames, and spatial size. However, what is the optimal shape? High resolution models perform well, but train slowly. Low resolution models train faster, but they are inaccurate. Inspired by multigrid methods in numerical optimization, we propose to use variable mini-batch shapes with different spatial-temporal resolutions that are varied according to a schedule. The different shapes arise from resampling the training data on multiple sampling grids. Training is accelerated by scaling up the mini-batch size and learning rate when shrinking the other dimensions. We empirically demonstrate a general and robust grid schedule that yields a significant out-of-the-box training speedup without a loss in accuracy for different models (I3D, non-local, SlowFast), datasets (Kinetics, Something-Something, Charades), and training settings (with and without pre-training, 128 GPUs or 1 GPU). As an illustrative example, the proposed multigrid method trains a ResNet-50 SlowFast network 4.5x faster (wall-clock time, same hardware) while also improving accuracy (+0.8% absolute) on Kinetics-400 compared to the baseline training method.
Learning Temporal Pose Estimation from Sparsely-Labeled Videos
Jun 06, 2019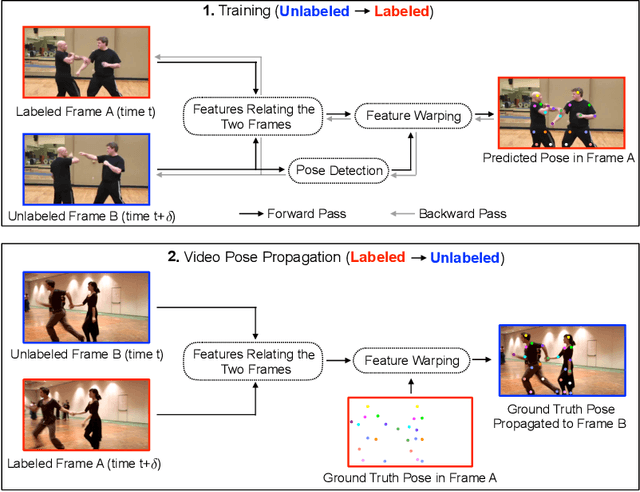

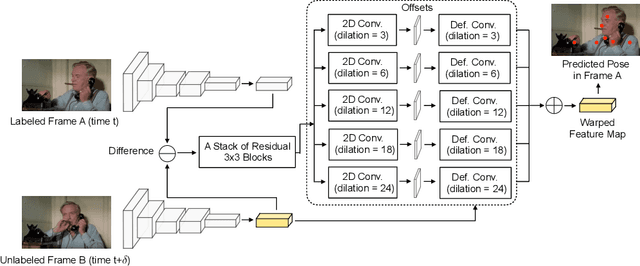
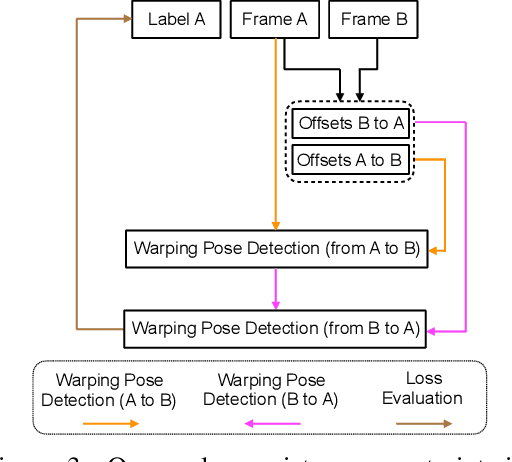
Modern approaches for multi-person pose estimation in video require large amounts of dense annotations. However, labeling every frame in a video is costly and labor intensive. To reduce the need for dense annotations, we propose a PoseWarper network that leverages training videos with sparse annotations (every k frames) to learn to perform dense temporal pose propagation and estimation. Given a pair of video frames---a labeled Frame A and an unlabeled Frame B---we train our model to predict human pose in Frame A using the features from Frame B by means of deformable convolutions to implicitly learn the pose warping between A and B. We demonstrate that we can leverage our trained PoseWarper for several applications. First, at inference time we can reverse the application direction of our network in order to propagate pose information from manually annotated frames to unlabeled frames. This makes it possible to generate pose annotations for the entire video given only a few manually-labeled frames. Compared to modern label propagation methods based on optical flow, our warping mechanism is much more compact (6M vs 39M parameters), and also more accurate (88.7% mAP vs 83.8% mAP). We also show that we can improve the accuracy of a pose estimator by training it on an augmented dataset obtained by adding our propagated poses to the original manual labels. Lastly, we can use our PoseWarper to aggregate temporal pose information from neighboring frames during inference. This allows our system to achieve state-of-the-art pose detection results on the PoseTrack2017 dataset.
Grounded Human-Object Interaction Hotspots from Video (Extended Abstract)
Jun 03, 2019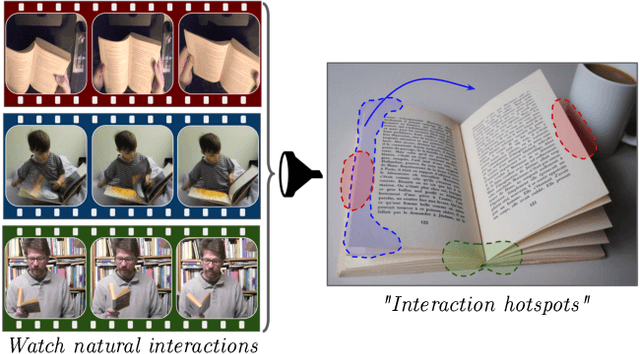
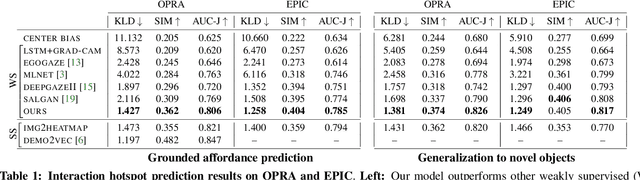

Learning how to interact with objects is an important step towards embodied visual intelligence, but existing techniques suffer from heavy supervision or sensing requirements. We propose an approach to learn human-object interaction "hotspots" directly from video. Rather than treat affordances as a manually supervised semantic segmentation task, our approach learns about interactions by watching videos of real human behavior and anticipating afforded actions. Given a novel image or video, our model infers a spatial hotspot map indicating how an object would be manipulated in a potential interaction, even if the object is currently at rest. Through results with both first and third person video, we show the value of grounding affordances in real human-object interactions. Not only are our weakly supervised hotspots competitive with strongly supervised affordance methods, but they can also anticipate object interaction for novel object categories. Project page: http://vision.cs.utexas.edu/projects/interaction-hotspots/
Modeling Human Motion with Quaternion-based Neural Networks
Jan 21, 2019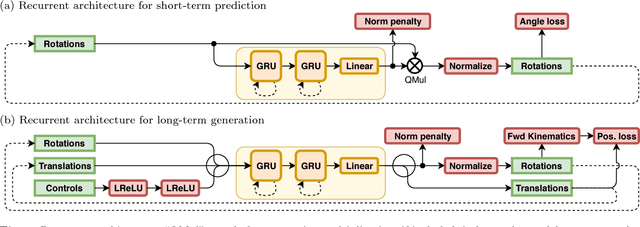
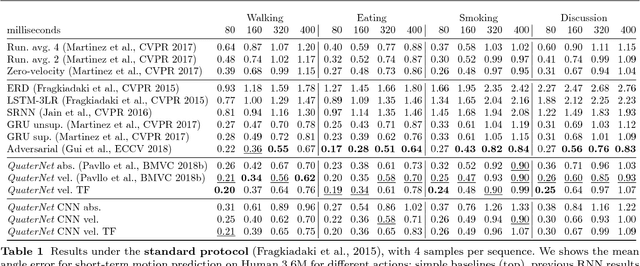
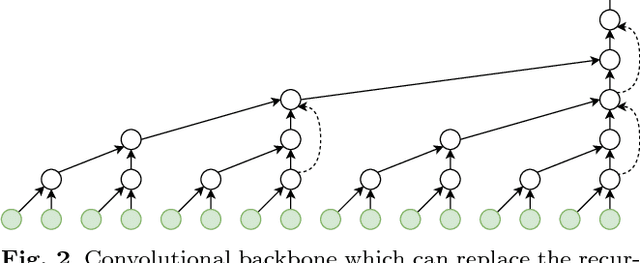
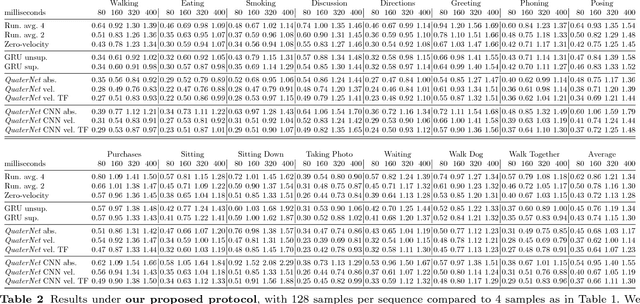
Previous work on predicting or generating 3D human pose sequences regresses either joint rotations or joint positions. The former strategy is prone to error accumulation along the kinematic chain, as well as discontinuities when using Euler angles or exponential maps as parameterizations. The latter requires re-projection onto skeleton constraints to avoid bone stretching and invalid configurations. This work addresses both limitations. QuaterNet represents rotations with quaternions and our loss function performs forward kinematics on a skeleton to penalize absolute position errors instead of angle errors. We investigate both recurrent and convolutional architectures and evaluate on short-term prediction and long-term generation. For the latter, our approach is qualitatively judged as realistic as recent neural strategies from the graphics literature. Our experiments compare quaternions to Euler angles as well as exponential maps and show that only a very short context is required to make reliable future predictions. Finally, we show that the standard evaluation protocol for Human3.6M produces high variance results and we propose a simple solution.
Long-Term Feature Banks for Detailed Video Understanding
Dec 12, 2018
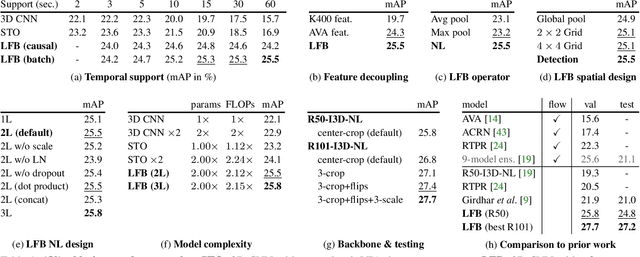

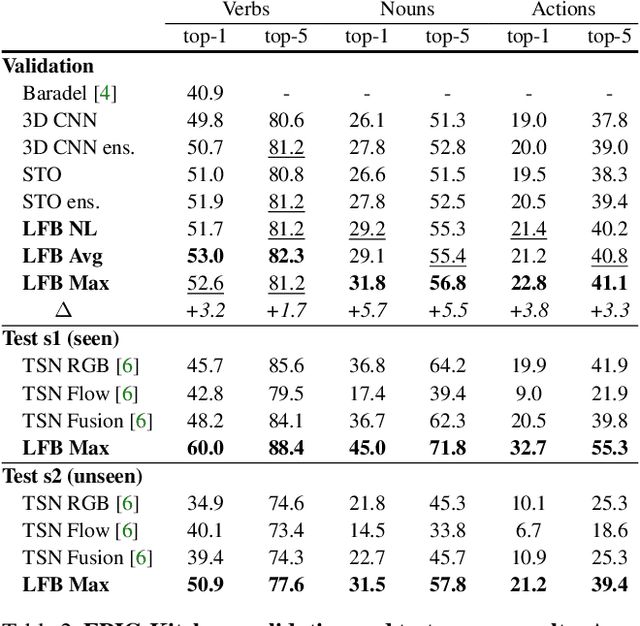
To understand the world, we humans constantly need to relate the present to the past, and put events in context. In this paper, we enable existing video models to do the same. We propose a long-term feature bank---supportive information extracted over the entire span of a video---to augment state-of-the-art video models that otherwise would only view short clips of 2-5 seconds. Our experiments demonstrate that augmenting 3D convolutional networks with a long-term feature bank yields state-of-the-art results on three challenging video datasets: AVA, EPIC-Kitchens, and Charades.
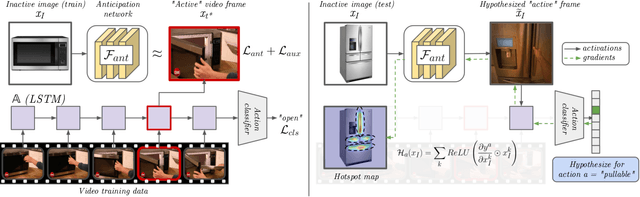
Grounded Human-Object Interaction Hotspots from Video
Dec 11, 2018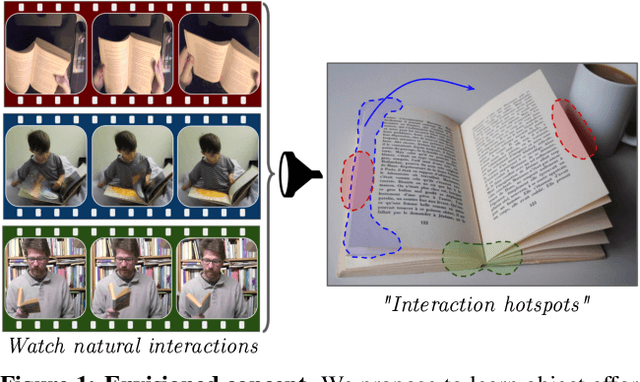

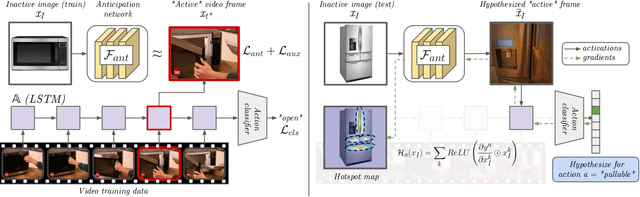
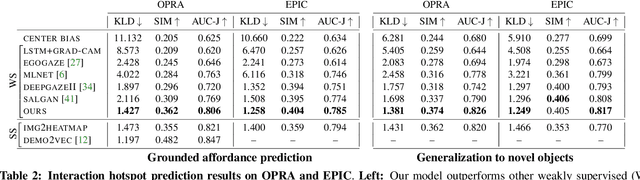
Learning how to interact with objects is an important step towards embodied visual intelligence, but existing techniques suffer from heavy supervision or sensing requirements. We propose an approach to learn human-object interaction "hotspots" directly from video. Rather than treat affordances as a manually supervised semantic segmentation task, our approach learns about interactions by watching videos of real human behavior and recognizing afforded actions. Given a novel image or video, our model infers a spatial hotspot map indicating how an object would be manipulated in a potential interaction -- even if the object is currently at rest. Through results with both first and third person video, we show the value of grounding affordance maps in real human-object interactions. Not only are our weakly supervised grounded hotspots competitive with strongly supervised affordance methods, but they can also anticipate object function for novel objects and enhance object recognition.
Learning Discriminative Motion Features Through Detection
Dec 11, 2018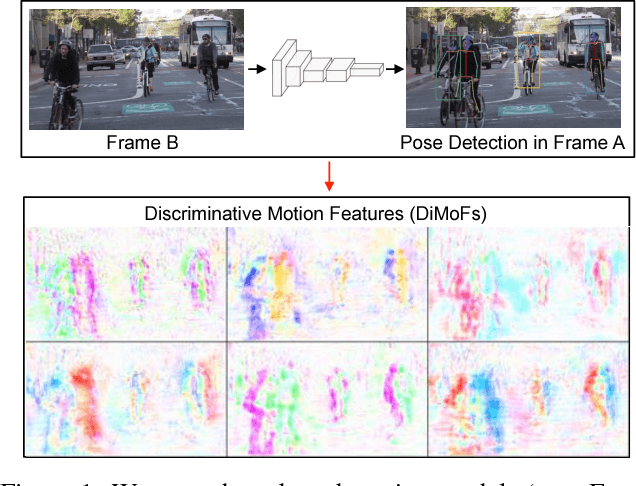

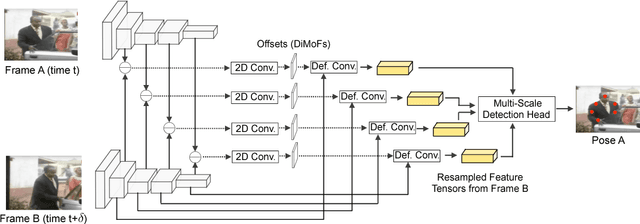

Despite huge success in the image domain, modern detection models such as Faster R-CNN have not been used nearly as much for video analysis. This is arguably due to the fact that detection models are designed to operate on single frames and as a result do not have a mechanism for learning motion representations directly from video. We propose a learning procedure that allows detection models such as Faster R-CNN to learn motion features directly from the RGB video data while being optimized with respect to a pose estimation task. Given a pair of video frames---Frame A and Frame B---we force our model to predict human pose in Frame A using the features from Frame B. We do so by leveraging deformable convolutions across space and time. Our network learns to spatially sample features from Frame B in order to maximize pose detection accuracy in Frame A. This naturally encourages our network to learn motion offsets encoding the spatial correspondences between the two frames. We refer to these motion offsets as DiMoFs (Discriminative Motion Features). In our experiments we show that our training scheme helps learn effective motion cues, which can be used to estimate and localize salient human motion. Furthermore, we demonstrate that as a byproduct, our model also learns features that lead to improved pose detection in still-images, and better keypoint tracking. Finally, we show how to leverage our learned model for the tasks of spatiotemporal action localization and fine-grained action recognition.
SlowFast Networks for Video Recognition
Dec 10, 2018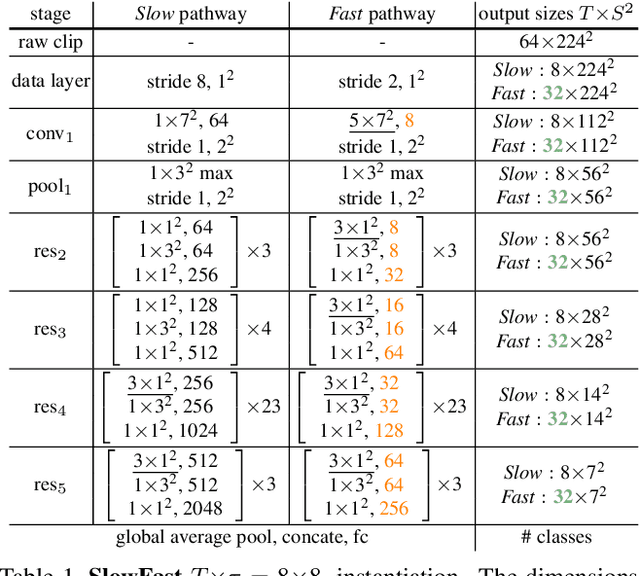

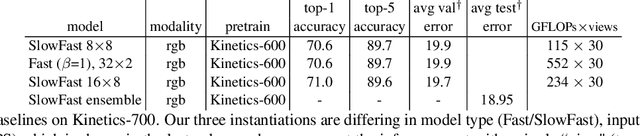
We present SlowFast networks for video recognition. Our model involves (i) a Slow pathway, operating at low frame rate, to capture spatial semantics, and (ii) a Fast pathway, operating at high frame rate, to capture motion at fine temporal resolution. The Fast pathway can be made very lightweight by reducing its channel capacity, yet can learn useful temporal information for video recognition. Our models achieve strong performance for both action classification and detection in video, and large improvements are pin-pointed as contributions by our SlowFast concept. We report 79.0% accuracy on the Kinetics dataset without using any pre-training, largely surpassing the previous best results of this kind. On AVA action detection we achieve a new state-of-the-art of 28.3 mAP. Code will be made publicly available.
3D human pose estimation in video with temporal convolutions and semi-supervised training
Nov 28, 2018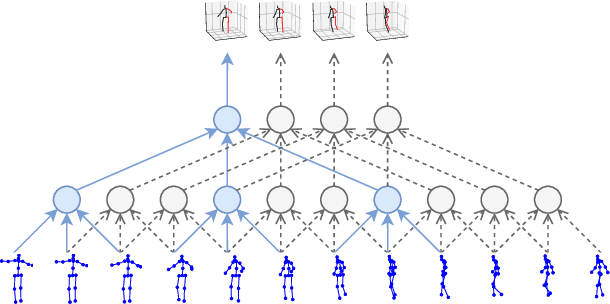
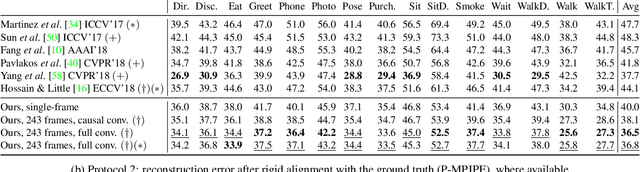

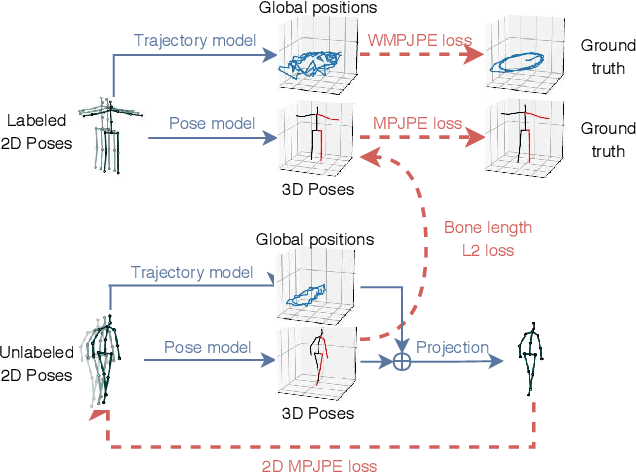
In this work, we demonstrate that 3D poses in video can be effectively estimated with a fully convolutional model based on dilated temporal convolutions over 2D keypoints. We also introduce back-projection, a simple and effective semi-supervised training method that leverages unlabeled video data. We start with predicted 2D keypoints for unlabeled video, then estimate 3D poses and finally back-project to the input 2D keypoints. In the supervised setting, our fully-convolutional model outperforms the previous best result from the literature by 6 mm mean per-joint position error on Human3.6M, corresponding to an error reduction of 11%, and the model also shows significant improvements on HumanEva-I. Moreover, experiments with back-projection show that it comfortably outperforms previous state-of-the-art results in semi-supervised settings where labeled data is scarce. Code and models are available at https://github.com/facebookresearch/VideoPose3D