 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChristoph Feichtenhofer
VideoCLIP: Contrastive Pre-training for Zero-shot Video-Text Understanding
Oct 01, 2021
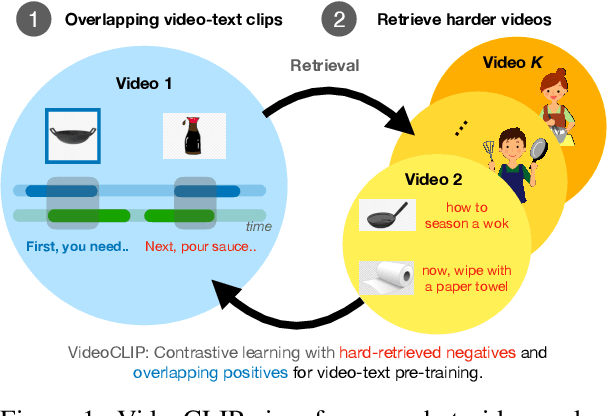
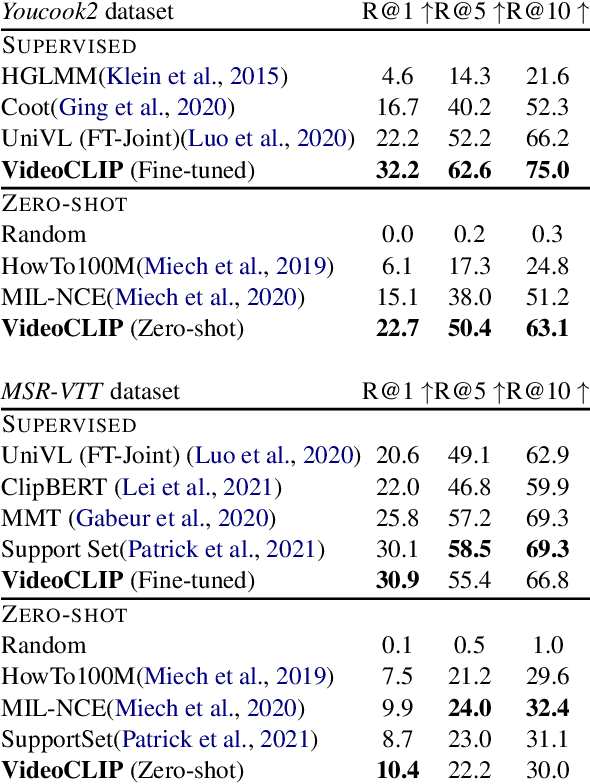
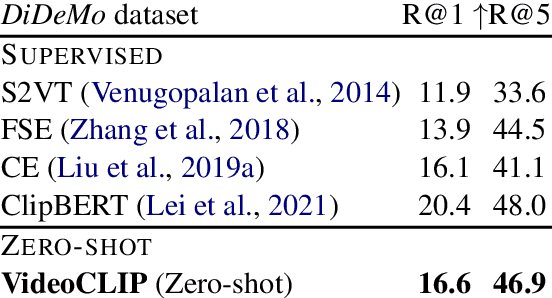
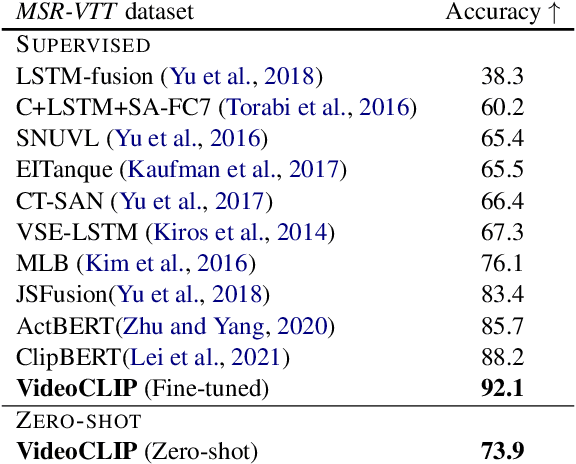
We present VideoCLIP, a contrastive approach to pre-train a unified model for zero-shot video and text understanding, without using any labels on downstream tasks. VideoCLIP trains a transformer for video and text by contrasting temporally overlapping positive video-text pairs with hard negatives from nearest neighbor retrieval. Our experiments on a diverse series of downstream tasks, including sequence-level text-video retrieval, VideoQA, token-level action localization, and action segmentation reveal state-of-the-art performance, surpassing prior work, and in some cases even outperforming supervised approaches. Code is made available at https://github.com/pytorch/fairseq/tree/main/examples/MMPT.
Keeping Your Eye on the Ball: Trajectory Attention in Video Transformers
Jun 09, 2021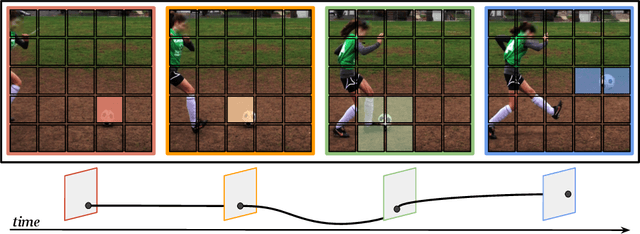

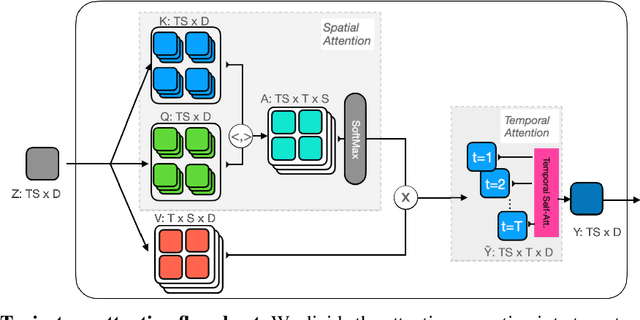
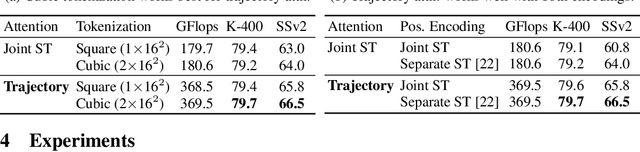
In video transformers, the time dimension is often treated in the same way as the two spatial dimensions. However, in a scene where objects or the camera may move, a physical point imaged at one location in frame $t$ may be entirely unrelated to what is found at that location in frame $t+k$. These temporal correspondences should be modeled to facilitate learning about dynamic scenes. To this end, we propose a new drop-in block for video transformers -- trajectory attention -- that aggregates information along implicitly determined motion paths. We additionally propose a new method to address the quadratic dependence of computation and memory on the input size, which is particularly important for high resolution or long videos. While these ideas are useful in a range of settings, we apply them to the specific task of video action recognition with a transformer model and obtain state-of-the-art results on the Kinetics, Something--Something V2, and Epic-Kitchens datasets. Code and models are available at: https://github.com/facebookresearch/Motionformer
VLM: Task-agnostic Video-Language Model Pre-training for Video Understanding
May 20, 2021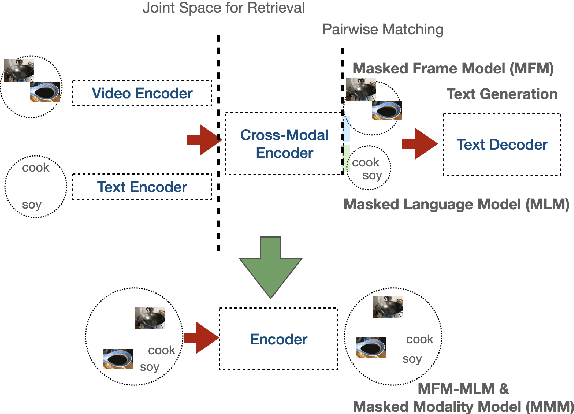

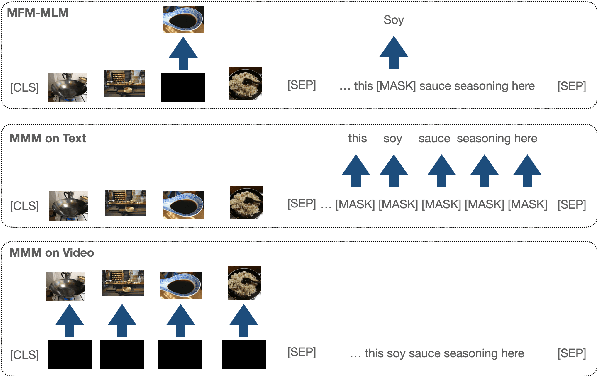
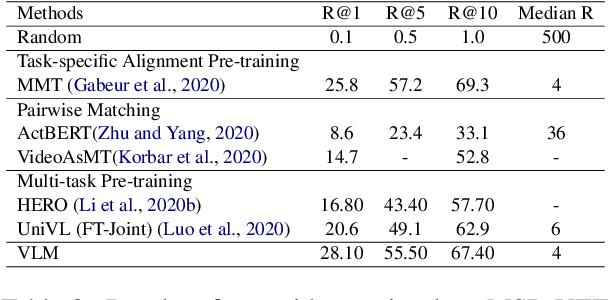
We present a simplified, task-agnostic multi-modal pre-training approach that can accept either video or text input, or both for a variety of end tasks. Existing pre-training are task-specific by adopting either a single cross-modal encoder that requires both modalities, limiting their use for retrieval-style end tasks or more complex multitask learning with two unimodal encoders, limiting early cross-modal fusion. We instead introduce new pretraining masking schemes that better mix across modalities (e.g. by forcing masks for text to predict the closest video embeddings) while also maintaining separability (e.g. unimodal predictions are sometimes required, without using all the input). Experimental results show strong performance across a wider range of tasks than any previous methods, often outperforming task-specific pre-training.
A Large-Scale Study on Unsupervised Spatiotemporal Representation Learning
Apr 29, 2021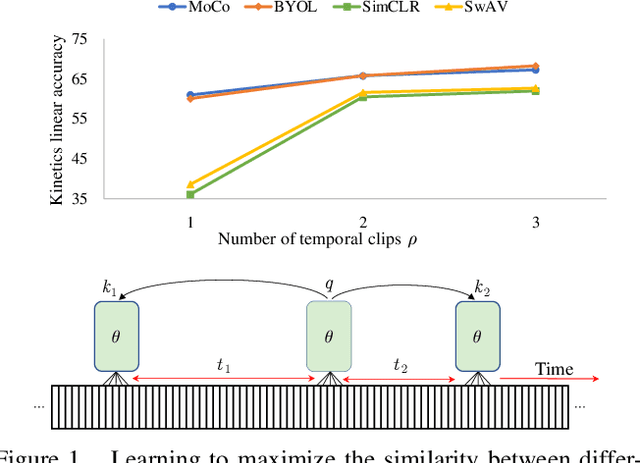

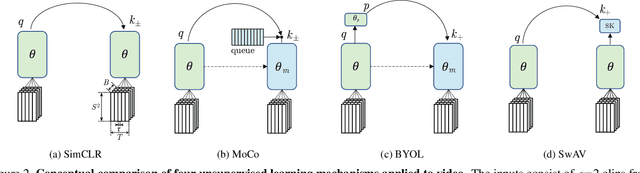
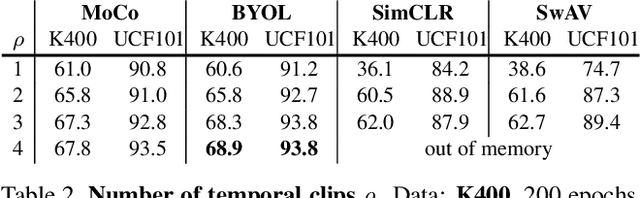
We present a large-scale study on unsupervised spatiotemporal representation learning from videos. With a unified perspective on four recent image-based frameworks, we study a simple objective that can easily generalize all these methods to space-time. Our objective encourages temporally-persistent features in the same video, and in spite of its simplicity, it works surprisingly well across: (i) different unsupervised frameworks, (ii) pre-training datasets, (iii) downstream datasets, and (iv) backbone architectures. We draw a series of intriguing observations from this study, e.g., we discover that encouraging long-spanned persistency can be effective even if the timespan is 60 seconds. In addition to state-of-the-art results in multiple benchmarks, we report a few promising cases in which unsupervised pre-training can outperform its supervised counterpart. Code is made available at https://github.com/facebookresearch/SlowFast
Multiscale Vision Transformers
Apr 22, 2021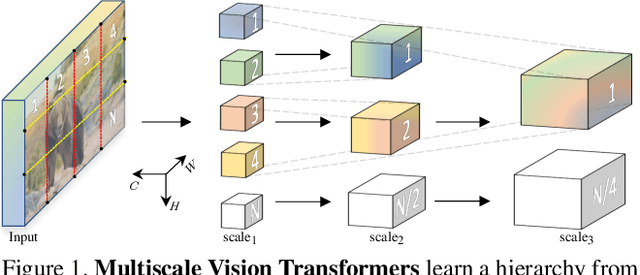

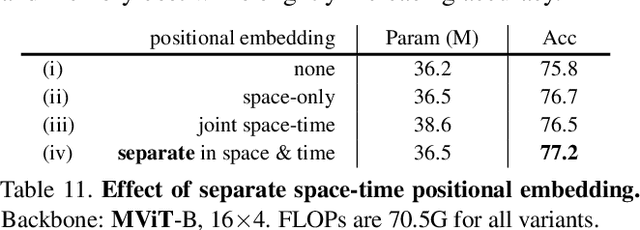
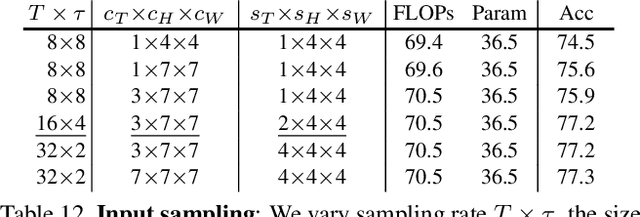
We present Multiscale Vision Transformers (MViT) for video and image recognition, by connecting the seminal idea of multiscale feature hierarchies with transformer models. Multiscale Transformers have several channel-resolution scale stages. Starting from the input resolution and a small channel dimension, the stages hierarchically expand the channel capacity while reducing the spatial resolution. This creates a multiscale pyramid of features with early layers operating at high spatial resolution to model simple low-level visual information, and deeper layers at spatially coarse, but complex, high-dimensional features. We evaluate this fundamental architectural prior for modeling the dense nature of visual signals for a variety of video recognition tasks where it outperforms concurrent vision transformers that rely on large scale external pre-training and are 5-10x more costly in computation and parameters. We further remove the temporal dimension and apply our model for image classification where it outperforms prior work on vision transformers. Code is available at: https://github.com/facebookresearch/SlowFast
Multiview Pseudo-Labeling for Semi-supervised Learning from Video
Apr 01, 2021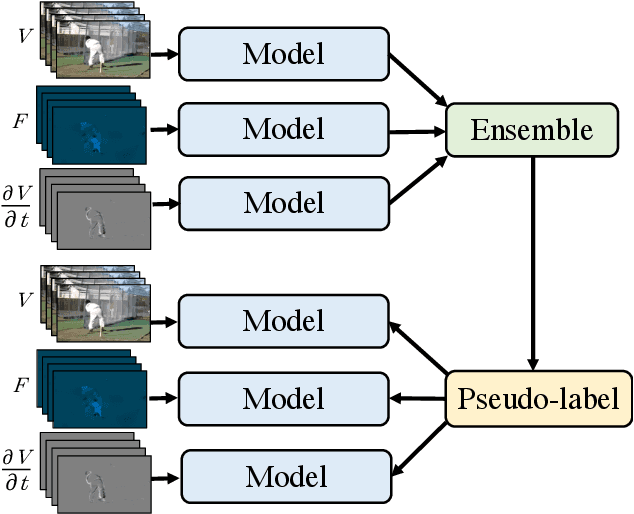
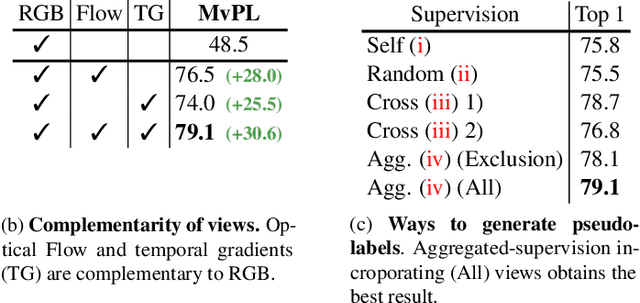
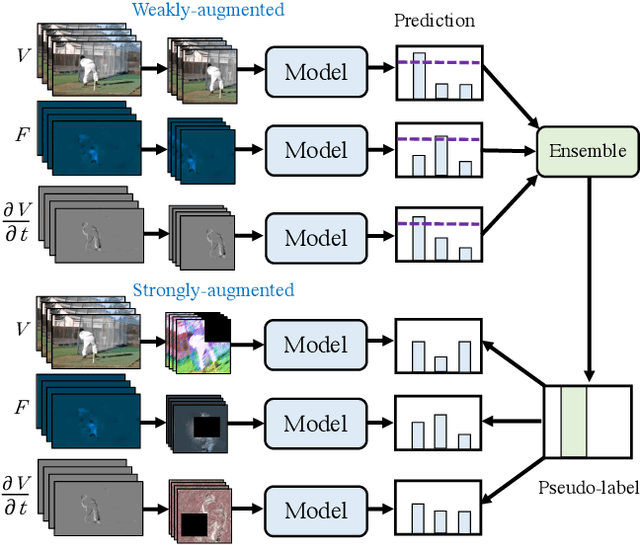

We present a multiview pseudo-labeling approach to video learning, a novel framework that uses complementary views in the form of appearance and motion information for semi-supervised learning in video. The complementary views help obtain more reliable pseudo-labels on unlabeled video, to learn stronger video representations than from purely supervised data. Though our method capitalizes on multiple views, it nonetheless trains a model that is shared across appearance and motion input and thus, by design, incurs no additional computation overhead at inference time. On multiple video recognition datasets, our method substantially outperforms its supervised counterpart, and compares favorably to previous work on standard benchmarks in self-supervised video representation learning.
TrackFormer: Multi-Object Tracking with Transformers
Jan 07, 2021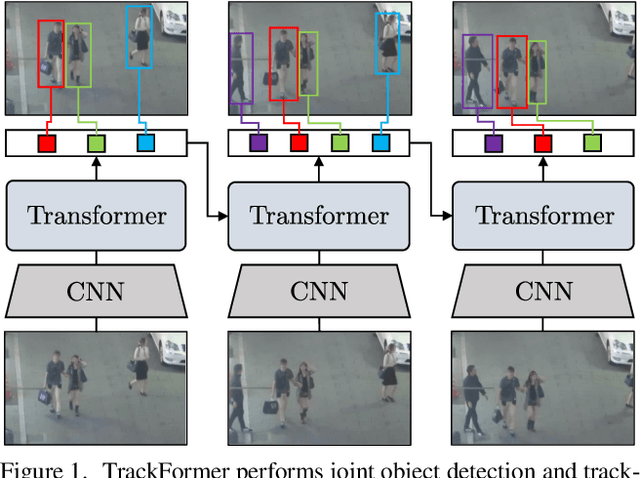
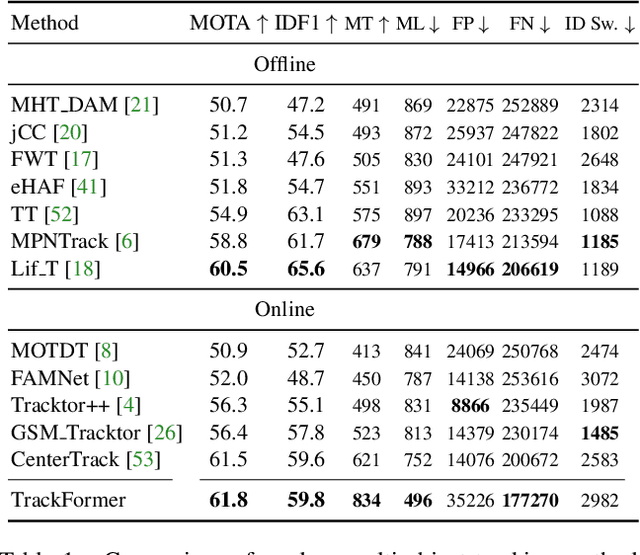
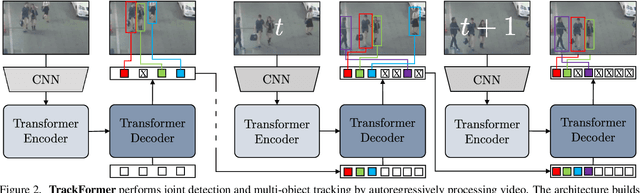
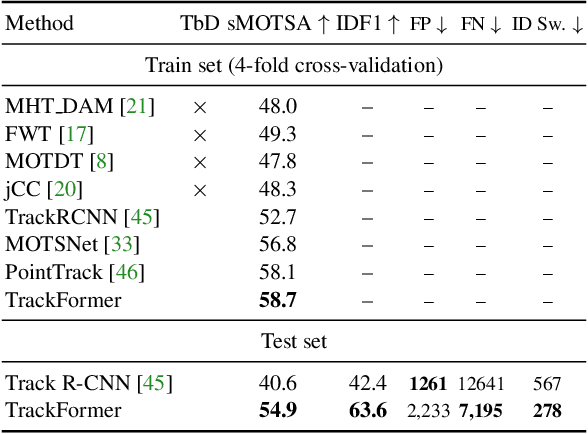
We present TrackFormer, an end-to-end multi-object tracking and segmentation model based on an encoder-decoder Transformer architecture. Our approach introduces track query embeddings which follow objects through a video sequence in an autoregressive fashion. New track queries are spawned by the DETR object detector and embed the position of their corresponding object over time. The Transformer decoder adjusts track query embeddings from frame to frame, thereby following the changing object positions. TrackFormer achieves a seamless data association between frames in a new tracking-by-attention paradigm by self- and encoder-decoder attention mechanisms which simultaneously reason about location, occlusion, and object identity. TrackFormer yields state-of-the-art performance on the tasks of multi-object tracking (MOT17) and segmentation (MOTS20). We hope our unified way of performing detection and tracking will foster future research in multi-object tracking and video understanding. Code will be made publicly available.
X3D: Expanding Architectures for Efficient Video Recognition
Apr 09, 2020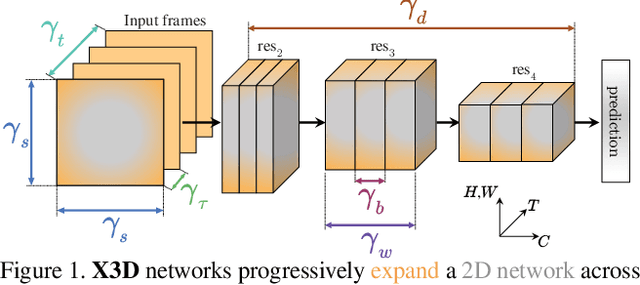

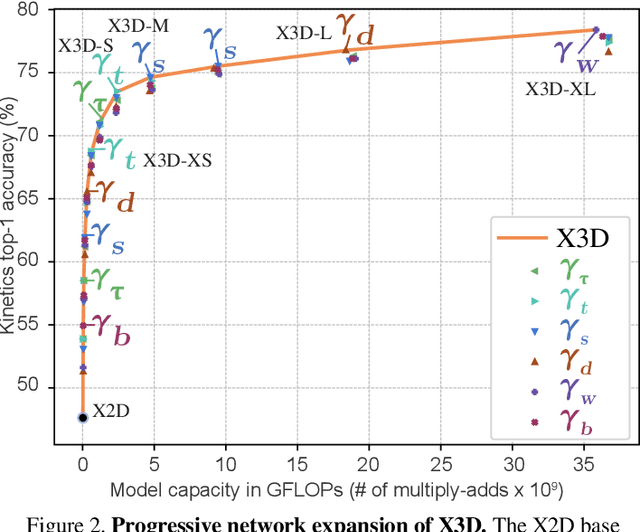
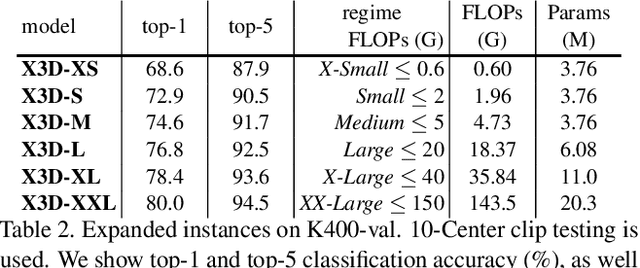
This paper presents X3D, a family of efficient video networks that progressively expand a tiny 2D image classification architecture along multiple network axes, in space, time, width and depth. Inspired by feature selection methods in machine learning, a simple stepwise network expansion approach is employed that expands a single axis in each step, such that good accuracy to complexity trade-off is achieved. To expand X3D to a specific target complexity, we perform progressive forward expansion followed by backward contraction. X3D achieves state-of-the-art performance while requiring 4.8x and 5.5x fewer multiply-adds and parameters for similar accuracy as previous work. Our most surprising finding is that networks with high spatiotemporal resolution can perform well, while being extremely light in terms of network width and parameters. We report competitive accuracy at unprecedented efficiency on video classification and detection benchmarks. Code will be available at: https://github.com/facebookresearch/SlowFast
Feature Pyramid Grids
Apr 07, 2020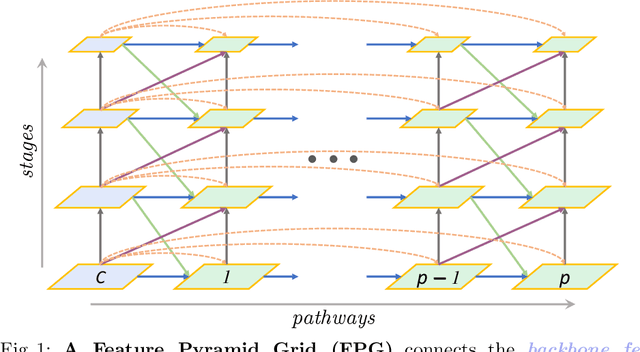
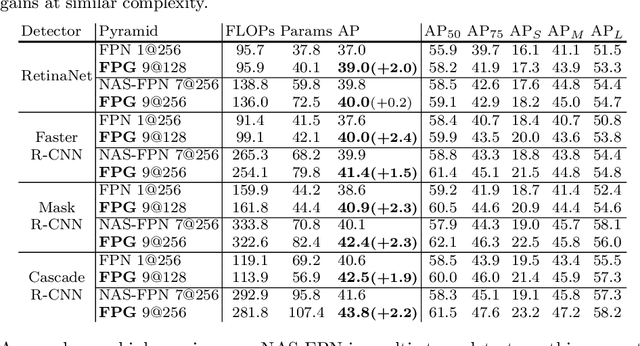
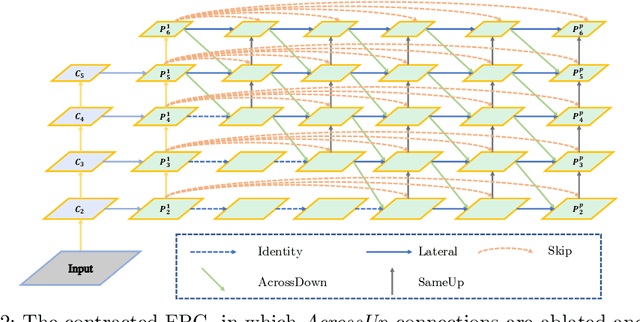
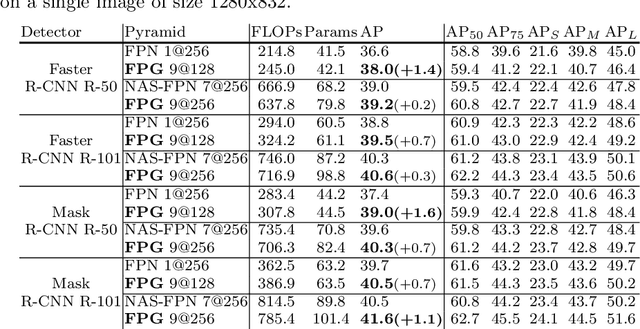
Feature pyramid networks have been widely adopted in the object detection literature to improve feature representations for better handling of variations in scale. In this paper, we present Feature Pyramid Grids (FPG), a deep multi-pathway feature pyramid, that represents the feature scale-space as a regular grid of parallel bottom-up pathways which are fused by multi-directional lateral connections. FPG can improve single-pathway feature pyramid networks by significantly increasing its performance at similar computation cost, highlighting importance of deep pyramid representations. In addition to its general and uniform structure, over complicated structures that have been found with neural architecture search, it also compares favorably against such approaches without relying on search. We hope that FPG with its uniform and effective nature can serve as a strong component for future work in object recognition.
Audiovisual SlowFast Networks for Video Recognition
Jan 23, 2020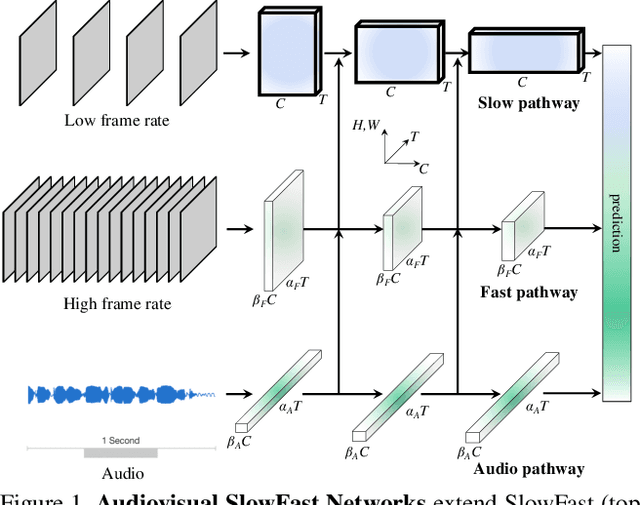
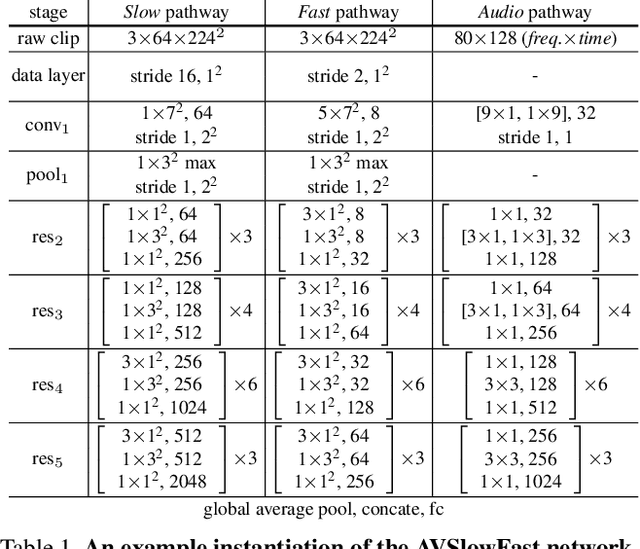
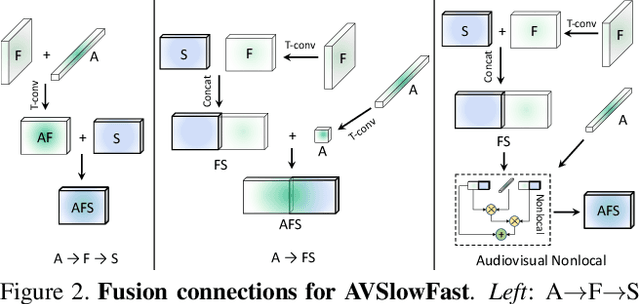
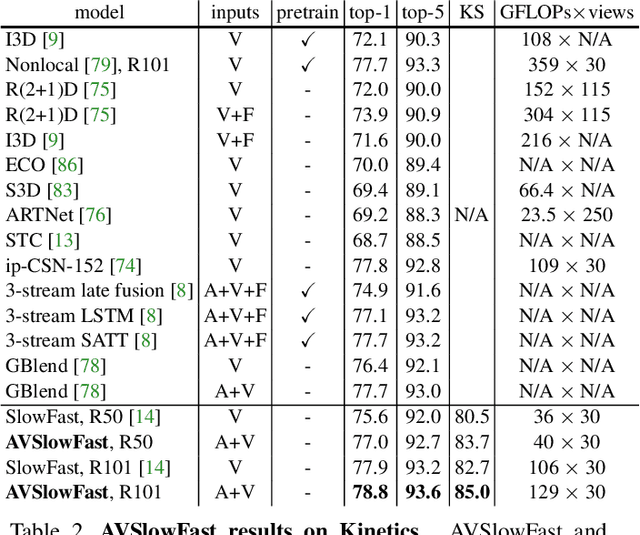
We present Audiovisual SlowFast Networks, an architecture for integrated audiovisual perception. AVSlowFast extends SlowFast Networks with a Faster Audio pathway that is deeply integrated with its visual counterparts. We fuse audio and visual features at multiple layers, enabling audio to contribute to the formation of hierarchical audiovisual concepts. To overcome training difficulties that arise from different learning dynamics for audio and visual modalities, we employ DropPathway that randomly drops the Audio pathway during training as a simple and effective regularization technique. Inspired by prior studies in neuroscience, we perform hierarchical audiovisual synchronization and show that it leads to better audiovisual features. We report state-of-the-art results on four video action classification and detection datasets, perform detailed ablation studies, and show the generalization of AVSlowFast to self-supervised tasks, where it improves over prior work. Code will be made available at: https://github.com/facebookresearch/SlowFast.