 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgument-Based Comparative Question Answering Evaluation Benchmark
Feb 20, 2025



In this paper, we aim to solve the problems standing in the way of automatic comparative question answering. To this end, we propose an evaluation framework to assess the quality of comparative question answering summaries. We formulate 15 criteria for assessing comparative answers created using manual annotation and annotation from 6 large language models and two comparative question asnwering datasets. We perform our tests using several LLMs and manual annotation under different settings and demonstrate the constituency of both evaluations. Our results demonstrate that the Llama-3 70B Instruct model demonstrates the best results for summary evaluation, while GPT-4 is the best for answering comparative questions. All used data, code, and evaluation results are publicly available\footnote{\url{https://anonymous.4open.science/r/cqa-evaluation-benchmark-4561/README.md}}.
GIMMICK -- Globally Inclusive Multimodal Multitask Cultural Knowledge Benchmarking
Feb 19, 2025



Large Vision-Language Models (LVLMs) have recently gained attention due to their distinctive performance and broad applicability. While it has been previously shown that their efficacy in usage scenarios involving non-Western contexts falls short, existing studies are limited in scope, covering just a narrow range of cultures, focusing exclusively on a small number of cultural aspects, or evaluating a limited selection of models on a single task only. Towards globally inclusive LVLM research, we introduce GIMMICK, an extensive multimodal benchmark designed to assess a broad spectrum of cultural knowledge across 144 countries representing six global macro-regions. GIMMICK comprises six tasks built upon three new datasets that span 728 unique cultural events or facets on which we evaluated 20 LVLMs and 11 LLMs, including five proprietary and 26 open-weight models of all sizes. We systematically examine (1) regional cultural biases, (2) the influence of model size, (3) input modalities, and (4) external cues. Our analyses reveal strong biases toward Western cultures across models and tasks and highlight strong correlations between model size and performance, as well as the effectiveness of multimodal input and external geographic cues. We further find that models have more knowledge of tangible than intangible aspects (e.g., food vs. rituals) and that they excel in recognizing broad cultural origins but struggle with a more nuanced understanding.
MVL-SIB: A Massively Multilingual Vision-Language Benchmark for Cross-Modal Topical Matching
Feb 18, 2025Existing multilingual vision-language (VL) benchmarks often only cover a handful of languages. Consequently, evaluations of large vision-language models (LVLMs) predominantly target high-resource languages, underscoring the need for evaluation data for low-resource languages. To address this limitation, we introduce MVL-SIB, a massively multilingual vision-language benchmark that evaluates both cross-modal and text-only topical matching across 205 languages -- over 100 more than the most multilingual existing VL benchmarks encompass. We then benchmark a range of of open-weight LVLMs together with GPT-4o(-mini) on MVL-SIB. Our results reveal that LVLMs struggle in cross-modal topic matching in lower-resource languages, performing no better than chance on languages like N'Koo. Our analysis further reveals that VL support in LVLMs declines disproportionately relative to textual support for lower-resource languages, as evidenced by comparison of cross-modal and text-only topical matching performance. We further observe that open-weight LVLMs do not benefit from representing a topic with more than one image, suggesting that these models are not yet fully effective at handling multi-image tasks. By correlating performance on MVL-SIB with other multilingual VL benchmarks, we highlight that MVL-SIB serves as a comprehensive probe of multilingual VL understanding in LVLMs.
Centurio: On Drivers of Multilingual Ability of Large Vision-Language Model
Jan 09, 2025



Most Large Vision-Language Models (LVLMs) to date are trained predominantly on English data, which makes them struggle to understand non-English input and fail to generate output in the desired target language. Existing efforts mitigate these issues by adding multilingual training data, but do so in a largely ad-hoc manner, lacking insight into how different training mixes tip the scale for different groups of languages. In this work, we present a comprehensive investigation into the training strategies for massively multilingual LVLMs. First, we conduct a series of multi-stage experiments spanning 13 downstream vision-language tasks and 43 languages, systematically examining: (1) the number of training languages that can be included without degrading English performance and (2) optimal language distributions of pre-training as well as (3) instruction-tuning data. Further, we (4) investigate how to improve multilingual text-in-image understanding, and introduce a new benchmark for the task. Surprisingly, our analysis reveals that one can (i) include as many as 100 training languages simultaneously (ii) with as little as 25-50\% of non-English data, to greatly improve multilingual performance while retaining strong English performance. We further find that (iii) including non-English OCR data in pre-training and instruction-tuning is paramount for improving multilingual text-in-image understanding. Finally, we put all our findings together and train Centurio, a 100-language LVLM, offering state-of-the-art performance in an evaluation covering 14 tasks and 56 languages.
CogSteer: Cognition-Inspired Selective Layer Intervention for Efficient Semantic Steering in Large Language Models
Oct 23, 2024



Despite their impressive capabilities, large language models (LLMs) often lack interpretability and can generate toxic content. While using LLMs as foundation models and applying semantic steering methods are widely practiced, we believe that efficient methods should be based on a thorough understanding of LLM behavior. To this end, we propose using eye movement measures to interpret LLM behavior across layers. We find that LLMs exhibit patterns similar to human gaze across layers and different layers function differently. Inspired by these findings, we introduce a heuristic steering layer selection and apply it to layer intervention methods via fine-tuning and inference. Using language toxification and detoxification as test beds, we demonstrate that our proposed CogSteer methods achieve better results in terms of toxicity scores while efficiently saving 97% of the computational resources and 60% of the training time. Our model-agnostic approach can be adopted into various LLMs, contributing to their interpretability and promoting trustworthiness for safe deployment.
Large Language Models Are Overparameterized Text Encoders
Oct 18, 2024



Large language models (LLMs) demonstrate strong performance as text embedding models when finetuned with supervised contrastive training. However, their large size balloons inference time and memory requirements. In this paper, we show that by pruning the last $p\%$ layers of an LLM before supervised training for only 1000 steps, we can achieve a proportional reduction in memory and inference time. We evaluate four different state-of-the-art LLMs on text embedding tasks and find that our method can prune up to 30\% of layers with negligible impact on performance and up to 80\% with only a modest drop. With only three lines of code, our method is easily implemented in any pipeline for transforming LLMs to text encoders. We also propose $\text{L}^3 \text{Prune}$, a novel layer-pruning strategy based on the model's initial loss that provides two optimal pruning configurations: a large variant with negligible performance loss and a small variant for resource-constrained settings. On average, the large variant prunes 21\% of the parameters with a $-0.3$ performance drop, and the small variant only suffers from a $-5.1$ decrease while pruning 74\% of the model. We consider these results strong evidence that LLMs are overparameterized for text embedding tasks, and can be easily pruned.
Demarked: A Strategy for Enhanced Abusive Speech Moderation through Counterspeech, Detoxification, and Message Management
Jun 27, 2024
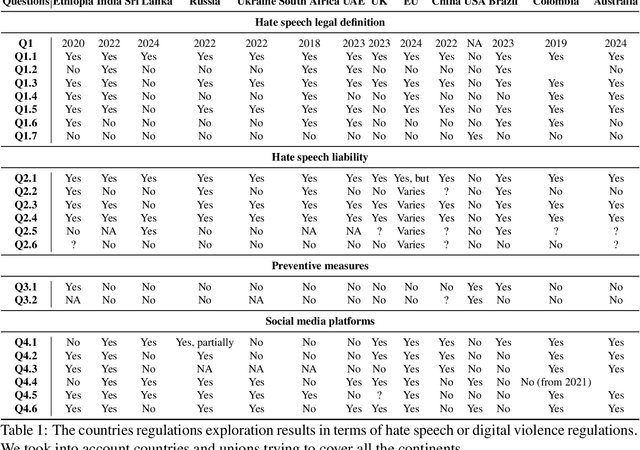
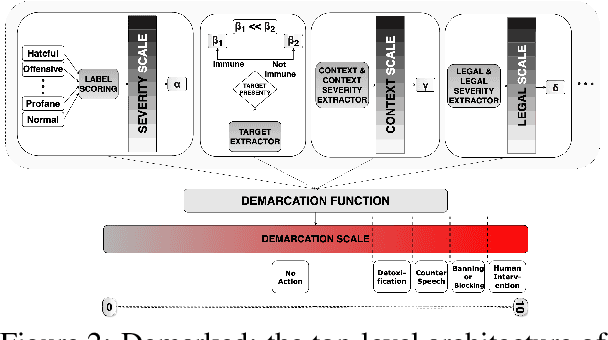

Despite regulations imposed by nations and social media platforms, such as recent EU regulations targeting digital violence, abusive content persists as a significant challenge. Existing approaches primarily rely on binary solutions, such as outright blocking or banning, yet fail to address the complex nature of abusive speech. In this work, we propose a more comprehensive approach called Demarcation scoring abusive speech based on four aspect -- (i) severity scale; (ii) presence of a target; (iii) context scale; (iv) legal scale -- and suggesting more options of actions like detoxification, counter speech generation, blocking, or, as a final measure, human intervention. Through a thorough analysis of abusive speech regulations across diverse jurisdictions, platforms, and research papers we highlight the gap in preventing measures and advocate for tailored proactive steps to combat its multifaceted manifestations. Our work aims to inform future strategies for effectively addressing abusive speech online.
Low-Resource Machine Translation through the Lens of Personalized Federated Learning
Jun 18, 2024



We present a new approach based on the Personalized Federated Learning algorithm MeritFed that can be applied to Natural Language Tasks with heterogeneous data. We evaluate it on the Low-Resource Machine Translation task, using the dataset from the Large-Scale Multilingual Machine Translation Shared Task (Small Track #2) and the subset of Sami languages from the multilingual benchmark for Finno-Ugric languages. In addition to its effectiveness, MeritFed is also highly interpretable, as it can be applied to track the impact of each language used for training. Our analysis reveals that target dataset size affects weight distribution across auxiliary languages, that unrelated languages do not interfere with the training, and auxiliary optimizer parameters have minimal impact. Our approach is easy to apply with a few lines of code, and we provide scripts for reproducing the experiments at https://github.com/VityaVitalich/MeritFed
Dataset of Quotation Attribution in German News Articles
Apr 25, 2024



Extracting who says what to whom is a crucial part in analyzing human communication in today's abundance of data such as online news articles. Yet, the lack of annotated data for this task in German news articles severely limits the quality and usability of possible systems. To remedy this, we present a new, freely available, creative-commons-licensed dataset for quotation attribution in German news articles based on WIKINEWS. The dataset provides curated, high-quality annotations across 1000 documents (250,000 tokens) in a fine-grained annotation schema enabling various downstream uses for the dataset. The annotations not only specify who said what but also how, in which context, to whom and define the type of quotation. We specify our annotation schema, describe the creation of the dataset and provide a quantitative analysis. Further, we describe suitable evaluation metrics, apply two existing systems for quotation attribution, discuss their results to evaluate the utility of our dataset and outline use cases of our dataset in downstream tasks.
Exploring Boundaries and Intensities in Offensive and Hate Speech: Unveiling the Complex Spectrum of Social Media Discourse
Apr 18, 2024



The prevalence of digital media and evolving sociopolitical dynamics have significantly amplified the dissemination of hateful content. Existing studies mainly focus on classifying texts into binary categories, often overlooking the continuous spectrum of offensiveness and hatefulness inherent in the text. In this research, we present an extensive benchmark dataset for Amharic, comprising 8,258 tweets annotated for three distinct tasks: category classification, identification of hate targets, and rating offensiveness and hatefulness intensities. Our study highlights that a considerable majority of tweets belong to the less offensive and less hate intensity levels, underscoring the need for early interventions by stakeholders. The prevalence of ethnic and political hatred targets, with significant overlaps in our dataset, emphasizes the complex relationships within Ethiopia's sociopolitical landscape. We build classification and regression models and investigate the efficacy of models in handling these tasks. Our results reveal that hate and offensive speech can not be addressed by a simplistic binary classification, instead manifesting as variables across a continuous range of values. The Afro-XLMR-large model exhibits the best performances achieving F1-scores of 75.30%, 70.59%, and 29.42% for the category, target, and regression tasks, respectively. The 80.22% correlation coefficient of the Afro-XLMR-large model indicates strong alignments.