 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChong-Wah Ngo
Long-term Leap Attention, Short-term Periodic Shift for Video Classification
Jul 12, 2022
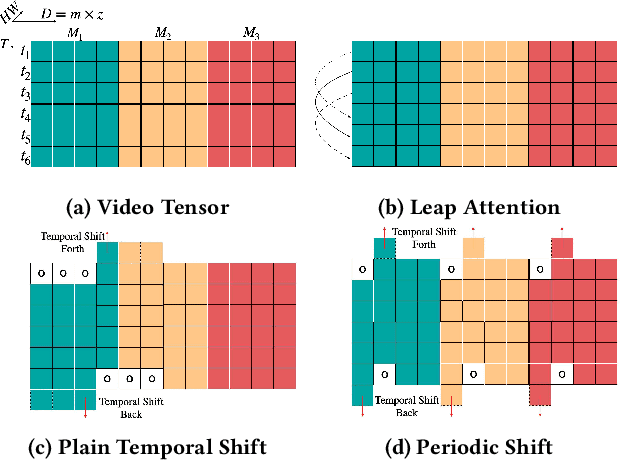
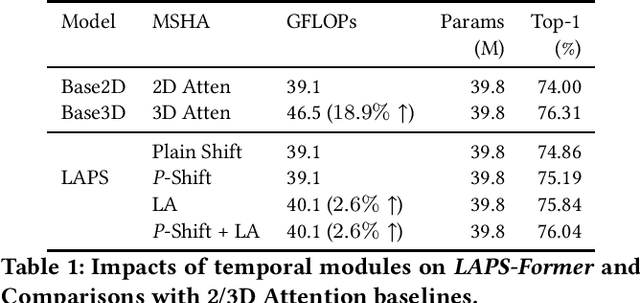
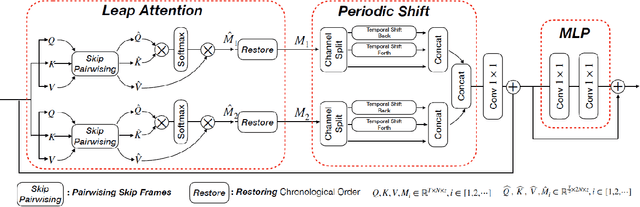

Video transformer naturally incurs a heavier computation burden than a static vision transformer, as the former processes $T$ times longer sequence than the latter under the current attention of quadratic complexity $(T^2N^2)$. The existing works treat the temporal axis as a simple extension of spatial axes, focusing on shortening the spatio-temporal sequence by either generic pooling or local windowing without utilizing temporal redundancy. However, videos naturally contain redundant information between neighboring frames; thereby, we could potentially suppress attention on visually similar frames in a dilated manner. Based on this hypothesis, we propose the LAPS, a long-term ``\textbf{\textit{Leap Attention}}'' (LA), short-term ``\textbf{\textit{Periodic Shift}}'' (\textit{P}-Shift) module for video transformers, with $(2TN^2)$ complexity. Specifically, the ``LA'' groups long-term frames into pairs, then refactors each discrete pair via attention. The ``\textit{P}-Shift'' exchanges features between temporal neighbors to confront the loss of short-term dynamics. By replacing a vanilla 2D attention with the LAPS, we could adapt a static transformer into a video one, with zero extra parameters and neglectable computation overhead ($\sim$2.6\%). Experiments on the standard Kinetics-400 benchmark demonstrate that our LAPS transformer could achieve competitive performances in terms of accuracy, FLOPs, and Params among CNN and transformer SOTAs. We open-source our project in \sloppy \href{https://github.com/VideoNetworks/LAPS-transformer}{\textit{\color{magenta}{https://github.com/VideoNetworks/LAPS-transformer}}} .
Wave-ViT: Unifying Wavelet and Transformers for Visual Representation Learning
Jul 11, 2022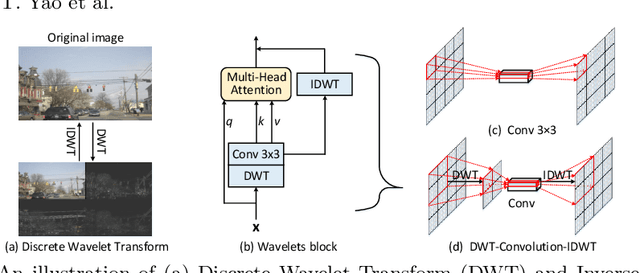
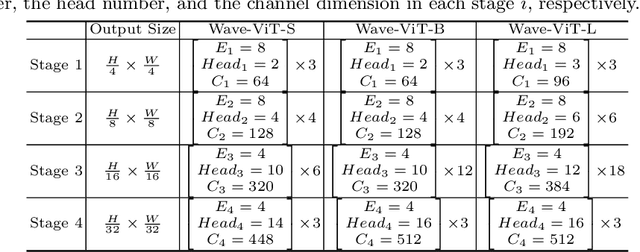
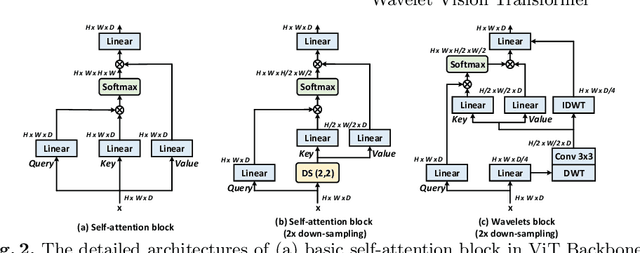
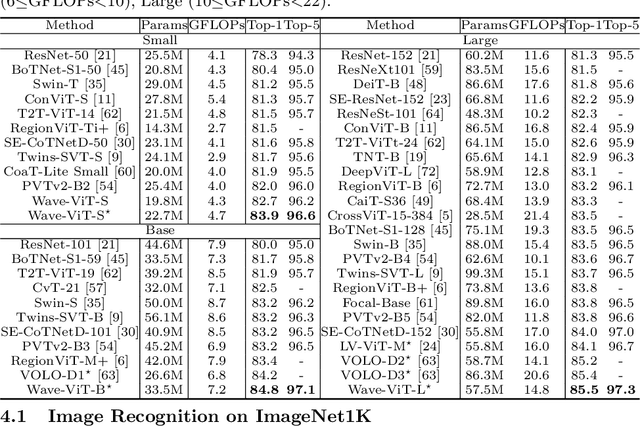
Multi-scale Vision Transformer (ViT) has emerged as a powerful backbone for computer vision tasks, while the self-attention computation in Transformer scales quadratically w.r.t. the input patch number. Thus, existing solutions commonly employ down-sampling operations (e.g., average pooling) over keys/values to dramatically reduce the computational cost. In this work, we argue that such over-aggressive down-sampling design is not invertible and inevitably causes information dropping especially for high-frequency components in objects (e.g., texture details). Motivated by the wavelet theory, we construct a new Wavelet Vision Transformer (\textbf{Wave-ViT}) that formulates the invertible down-sampling with wavelet transforms and self-attention learning in a unified way. This proposal enables self-attention learning with lossless down-sampling over keys/values, facilitating the pursuing of a better efficiency-vs-accuracy trade-off. Furthermore, inverse wavelet transforms are leveraged to strengthen self-attention outputs by aggregating local contexts with enlarged receptive field. We validate the superiority of Wave-ViT through extensive experiments over multiple vision tasks (e.g., image recognition, object detection and instance segmentation). Its performances surpass state-of-the-art ViT backbones with comparable FLOPs. Source code is available at \url{https://github.com/YehLi/ImageNetModel}.
(Un)likelihood Training for Interpretable Embedding
Jul 01, 2022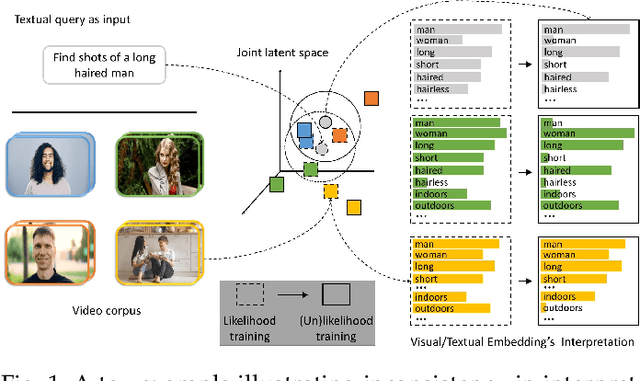
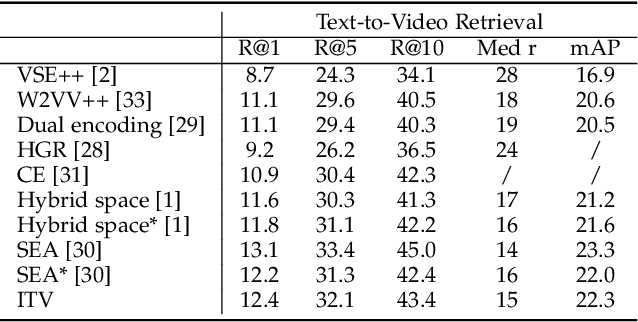
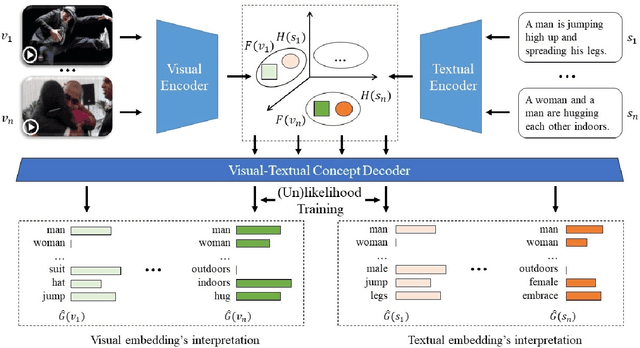
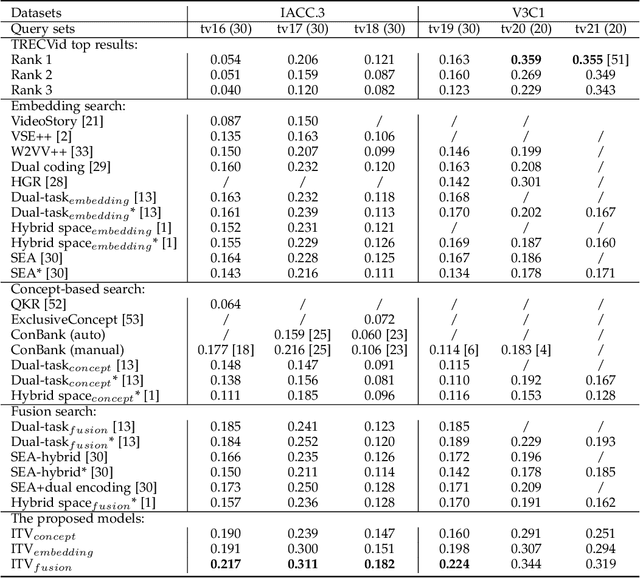
Cross-modal representation learning has become a new normal for bridging the semantic gap between text and visual data. Learning modality agnostic representations in a continuous latent space, however, is often treated as a black-box data-driven training process. It is well-known that the effectiveness of representation learning depends heavily on the quality and scale of training data. For video representation learning, having a complete set of labels that annotate the full spectrum of video content for training is highly difficult if not impossible. These issues, black-box training and dataset bias, make representation learning practically challenging to be deployed for video understanding due to unexplainable and unpredictable results. In this paper, we propose two novel training objectives, likelihood and unlikelihood functions, to unroll semantics behind embeddings while addressing the label sparsity problem in training. The likelihood training aims to interpret semantics of embeddings beyond training labels, while the unlikelihood training leverages prior knowledge for regularization to ensure semantically coherent interpretation. With both training objectives, a new encoder-decoder network, which learns interpretable cross-modal representation, is proposed for ad-hoc video search. Extensive experiments on TRECVid and MSR-VTT datasets show the proposed network outperforms several state-of-the-art retrieval models with a statistically significant performance margin.
MLP-3D: A MLP-like 3D Architecture with Grouped Time Mixing
Jun 13, 2022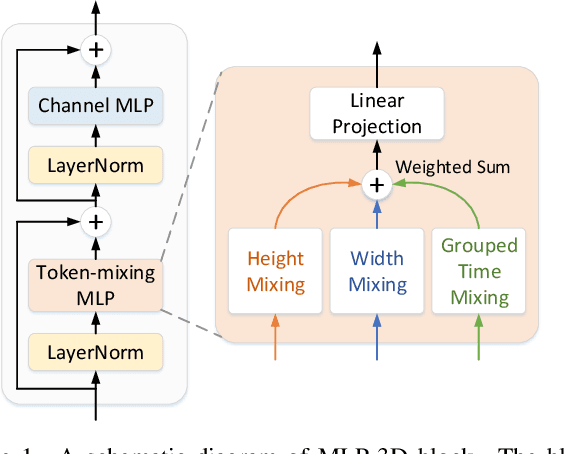
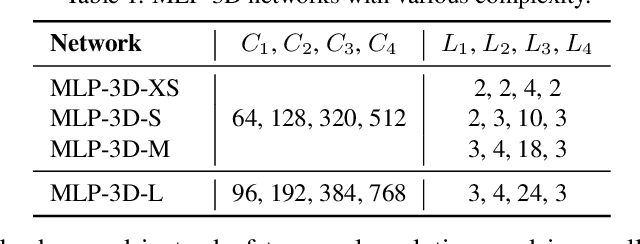

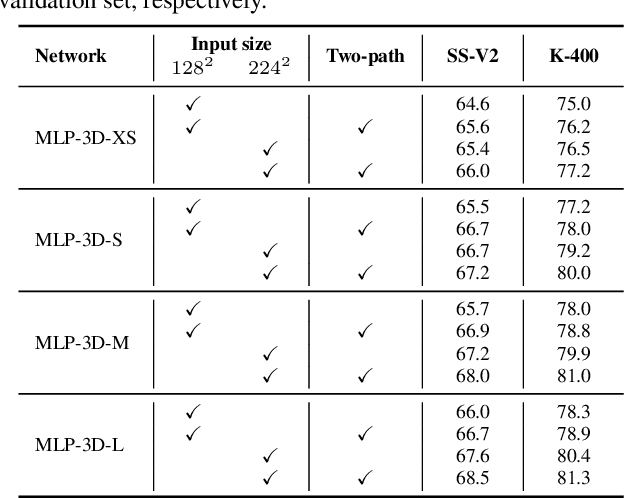
Convolutional Neural Networks (CNNs) have been regarded as the go-to models for visual recognition. More recently, convolution-free networks, based on multi-head self-attention (MSA) or multi-layer perceptrons (MLPs), become more and more popular. Nevertheless, it is not trivial when utilizing these newly-minted networks for video recognition due to the large variations and complexities in video data. In this paper, we present MLP-3D networks, a novel MLP-like 3D architecture for video recognition. Specifically, the architecture consists of MLP-3D blocks, where each block contains one MLP applied across tokens (i.e., token-mixing MLP) and one MLP applied independently to each token (i.e., channel MLP). By deriving the novel grouped time mixing (GTM) operations, we equip the basic token-mixing MLP with the ability of temporal modeling. GTM divides the input tokens into several temporal groups and linearly maps the tokens in each group with the shared projection matrix. Furthermore, we devise several variants of GTM with different grouping strategies, and compose each variant in different blocks of MLP-3D network by greedy architecture search. Without the dependence on convolutions or attention mechanisms, our MLP-3D networks achieves 68.5\%/81.4\% top-1 accuracy on Something-Something V2 and Kinetics-400 datasets, respectively. Despite with fewer computations, the results are comparable to state-of-the-art widely-used 3D CNNs and video transformers. Source code is available at https://github.com/ZhaofanQiu/MLP-3D.
Cross-lingual Adaptation for Recipe Retrieval with Mixup
May 08, 2022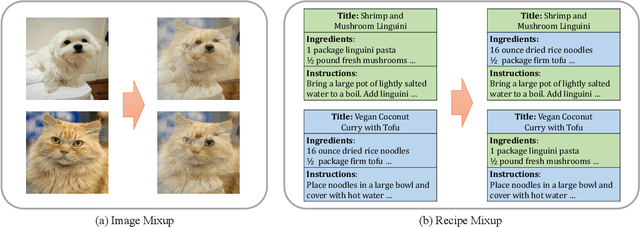
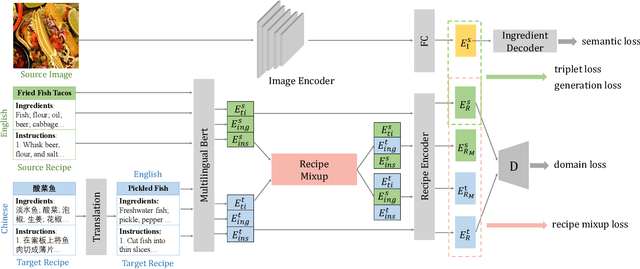
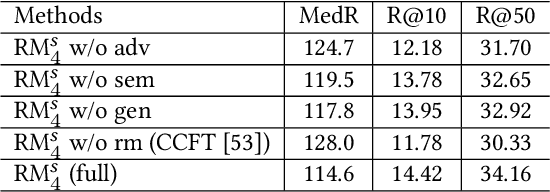
Cross-modal recipe retrieval has attracted research attention in recent years, thanks to the availability of large-scale paired data for training. Nevertheless, obtaining adequate recipe-image pairs covering the majority of cuisines for supervised learning is difficult if not impossible. By transferring knowledge learnt from a data-rich cuisine to a data-scarce cuisine, domain adaptation sheds light on this practical problem. Nevertheless, existing works assume recipes in source and target domains are mostly originated from the same cuisine and written in the same language. This paper studies unsupervised domain adaptation for image-to-recipe retrieval, where recipes in source and target domains are in different languages. Moreover, only recipes are available for training in the target domain. A novel recipe mixup method is proposed to learn transferable embedding features between the two domains. Specifically, recipe mixup produces mixed recipes to form an intermediate domain by discretely exchanging the section(s) between source and target recipes. To bridge the domain gap, recipe mixup loss is proposed to enforce the intermediate domain to locate in the shortest geodesic path between source and target domains in the recipe embedding space. By using Recipe 1M dataset as source domain (English) and Vireo-FoodTransfer dataset as target domain (Chinese), empirical experiments verify the effectiveness of recipe mixup for cross-lingual adaptation in the context of image-to-recipe retrieval.
Adaptive Split-Fusion Transformer
Apr 26, 2022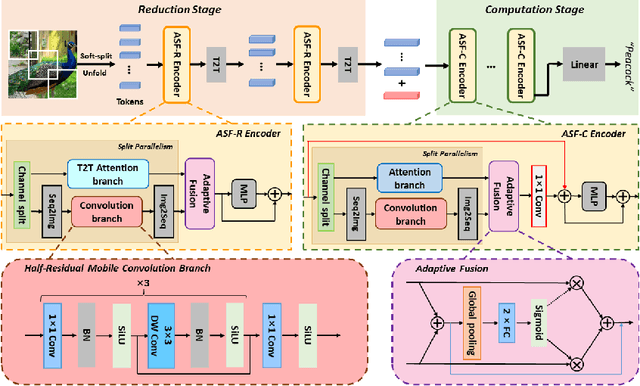

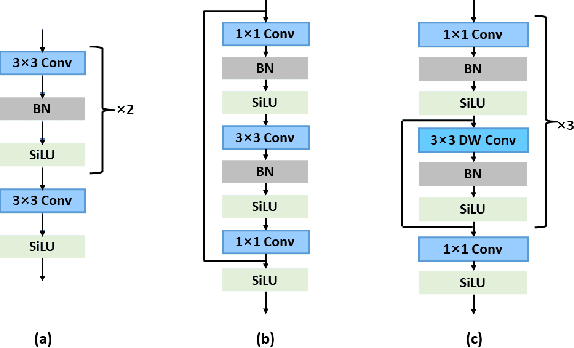

Neural networks for visual content understanding have recently evolved from convolutional ones (CNNs) to transformers. The prior (CNN) relies on small-windowed kernels to capture the regional clues, demonstrating solid local expressiveness. On the contrary, the latter (transformer) establishes long-range global connections between localities for holistic learning. Inspired by this complementary nature, there is a growing interest in designing hybrid models to best utilize each technique. Current hybrids merely replace convolutions as simple approximations of linear projection or juxtapose a convolution branch with attention, without concerning the importance of local/global modeling. To tackle this, we propose a new hybrid named Adaptive Split-Fusion Transformer (ASF-former) to treat convolutional and attention branches differently with adaptive weights. Specifically, an ASF-former encoder equally splits feature channels into half to fit dual-path inputs. Then, the outputs of dual-path are fused with weighting scalars calculated from visual cues. We also design the convolutional path compactly for efficiency concerns. Extensive experiments on standard benchmarks, such as ImageNet-1K, CIFAR-10, and CIFAR-100, show that our ASF-former outperforms its CNN, transformer counterparts, and hybrid pilots in terms of accuracy (83.9% on ImageNet-1K), under similar conditions (12.9G MACs/56.7M Params, without large-scale pre-training). The code is available at: https://github.com/szx503045266/ASF-former.
Group Contextualization for Video Recognition
Mar 18, 2022
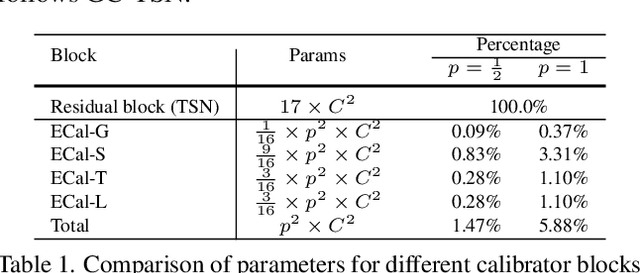
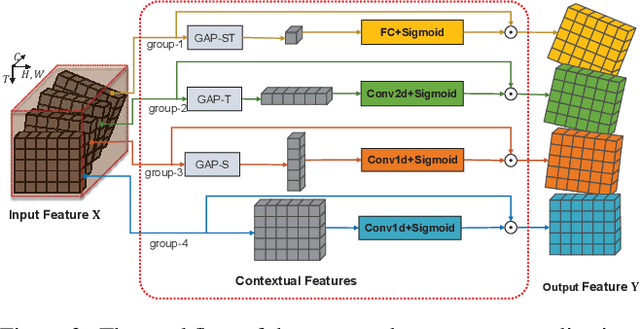
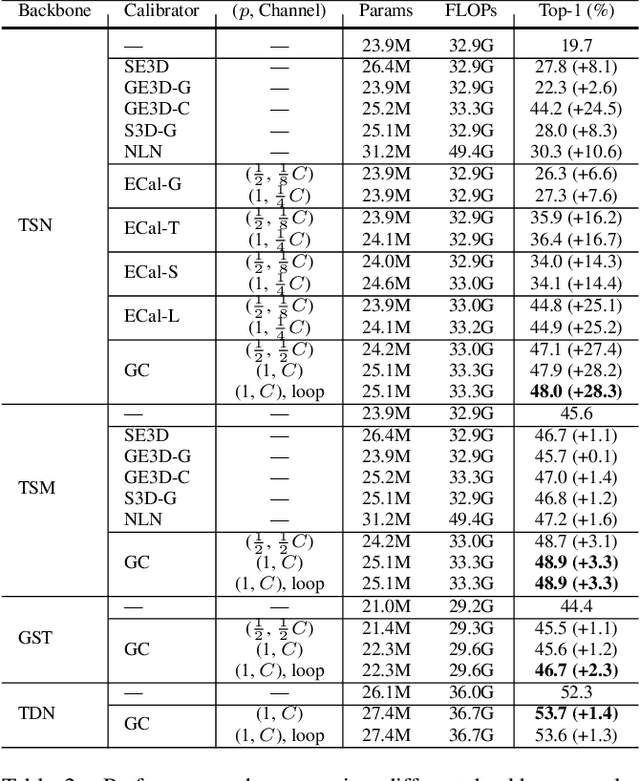
Learning discriminative representation from the complex spatio-temporal dynamic space is essential for video recognition. On top of those stylized spatio-temporal computational units, further refining the learnt feature with axial contexts is demonstrated to be promising in achieving this goal. However, previous works generally focus on utilizing a single kind of contexts to calibrate entire feature channels and could hardly apply to deal with diverse video activities. The problem can be tackled by using pair-wise spatio-temporal attentions to recompute feature response with cross-axis contexts at the expense of heavy computations. In this paper, we propose an efficient feature refinement method that decomposes the feature channels into several groups and separately refines them with different axial contexts in parallel. We refer this lightweight feature calibration as group contextualization (GC). Specifically, we design a family of efficient element-wise calibrators, i.e., ECal-G/S/T/L, where their axial contexts are information dynamics aggregated from other axes either globally or locally, to contextualize feature channel groups. The GC module can be densely plugged into each residual layer of the off-the-shelf video networks. With little computational overhead, consistent improvement is observed when plugging in GC on different networks. By utilizing calibrators to embed feature with four different kinds of contexts in parallel, the learnt representation is expected to be more resilient to diverse types of activities. On videos with rich temporal variations, empirically GC can boost the performance of 2D-CNN (e.g., TSN and TSM) to a level comparable to the state-of-the-art video networks. Code is available at https://github.com/haoyanbin918/Group-Contextualization.
Boosting Video Representation Learning with Multi-Faceted Integration
Jan 11, 2022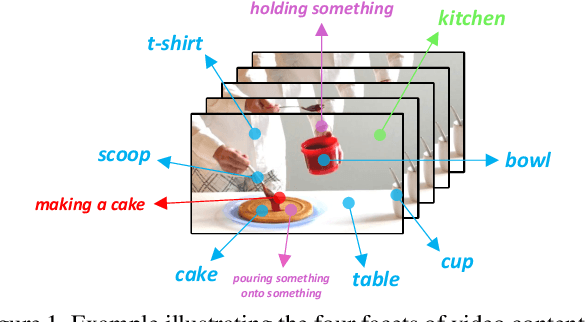
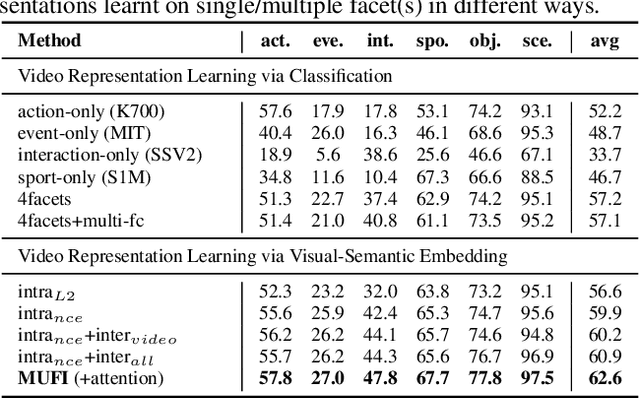
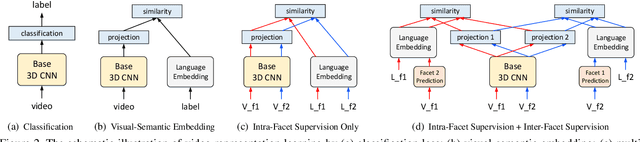
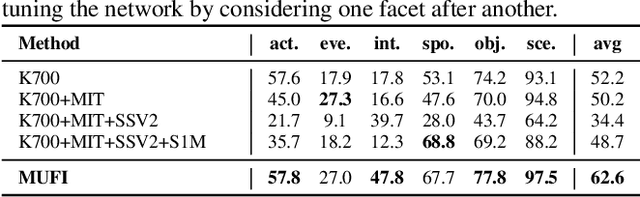
Video content is multifaceted, consisting of objects, scenes, interactions or actions. The existing datasets mostly label only one of the facets for model training, resulting in the video representation that biases to only one facet depending on the training dataset. There is no study yet on how to learn a video representation from multifaceted labels, and whether multifaceted information is helpful for video representation learning. In this paper, we propose a new learning framework, MUlti-Faceted Integration (MUFI), to aggregate facets from different datasets for learning a representation that could reflect the full spectrum of video content. Technically, MUFI formulates the problem as visual-semantic embedding learning, which explicitly maps video representation into a rich semantic embedding space, and jointly optimizes video representation from two perspectives. One is to capitalize on the intra-facet supervision between each video and its own label descriptions, and the second predicts the "semantic representation" of each video from the facets of other datasets as the inter-facet supervision. Extensive experiments demonstrate that learning 3D CNN via our MUFI framework on a union of four large-scale video datasets plus two image datasets leads to superior capability of video representation. The pre-learnt 3D CNN with MUFI also shows clear improvements over other approaches on several downstream video applications. More remarkably, MUFI achieves 98.1%/80.9% on UCF101/HMDB51 for action recognition and 101.5% in terms of CIDEr-D score on MSVD for video captioning.
Condensing a Sequence to One Informative Frame for Video Recognition
Jan 11, 2022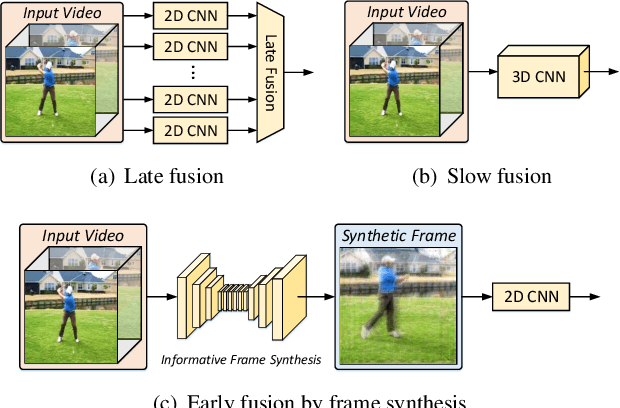
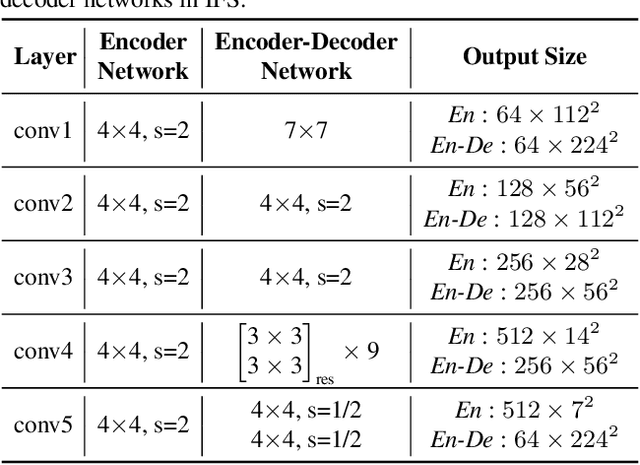
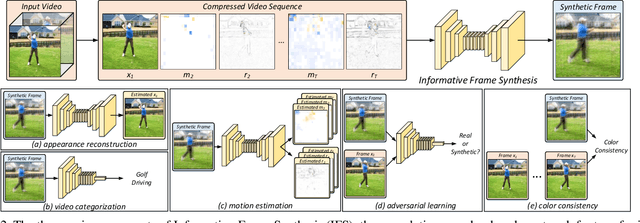
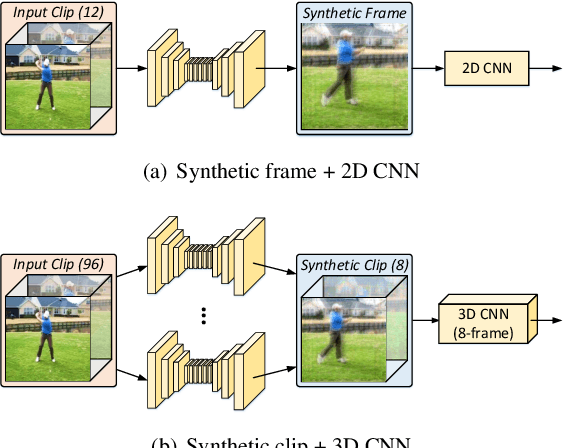
Video is complex due to large variations in motion and rich content in fine-grained visual details. Abstracting useful information from such information-intensive media requires exhaustive computing resources. This paper studies a two-step alternative that first condenses the video sequence to an informative "frame" and then exploits off-the-shelf image recognition system on the synthetic frame. A valid question is how to define "useful information" and then distill it from a video sequence down to one synthetic frame. This paper presents a novel Informative Frame Synthesis (IFS) architecture that incorporates three objective tasks, i.e., appearance reconstruction, video categorization, motion estimation, and two regularizers, i.e., adversarial learning, color consistency. Each task equips the synthetic frame with one ability, while each regularizer enhances its visual quality. With these, by jointly learning the frame synthesis in an end-to-end manner, the generated frame is expected to encapsulate the required spatio-temporal information useful for video analysis. Extensive experiments are conducted on the large-scale Kinetics dataset. When comparing to baseline methods that map video sequence to a single image, IFS shows superior performance. More remarkably, IFS consistently demonstrates evident improvements on image-based 2D networks and clip-based 3D networks, and achieves comparable performance with the state-of-the-art methods with less computational cost.
Optimization Planning for 3D ConvNets
Jan 11, 2022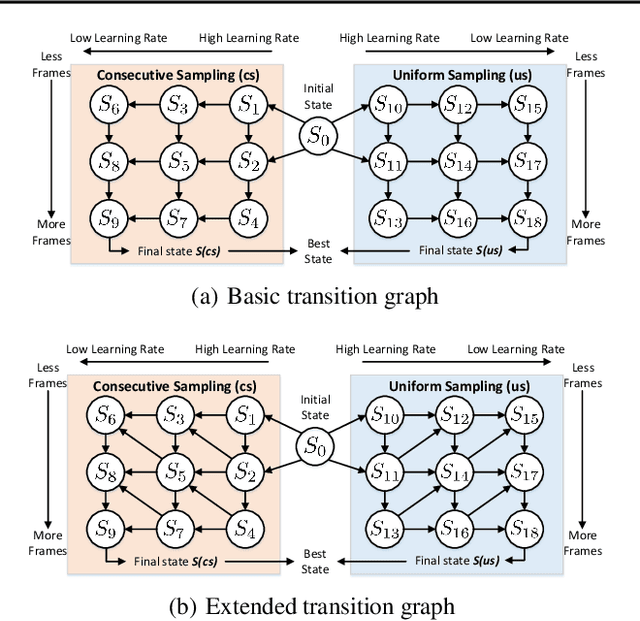

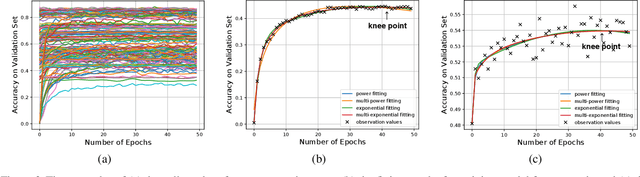
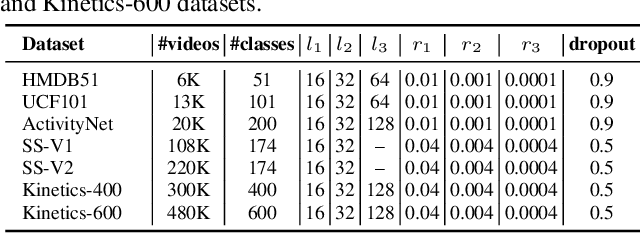
It is not trivial to optimally learn a 3D Convolutional Neural Networks (3D ConvNets) due to high complexity and various options of the training scheme. The most common hand-tuning process starts from learning 3D ConvNets using short video clips and then is followed by learning long-term temporal dependency using lengthy clips, while gradually decaying the learning rate from high to low as training progresses. The fact that such process comes along with several heuristic settings motivates the study to seek an optimal "path" to automate the entire training. In this paper, we decompose the path into a series of training "states" and specify the hyper-parameters, e.g., learning rate and the length of input clips, in each state. The estimation of the knee point on the performance-epoch curve triggers the transition from one state to another. We perform dynamic programming over all the candidate states to plan the optimal permutation of states, i.e., optimization path. Furthermore, we devise a new 3D ConvNets with a unique design of dual-head classifier to improve spatial and temporal discrimination. Extensive experiments on seven public video recognition benchmarks demonstrate the advantages of our proposal. With the optimization planning, our 3D ConvNets achieves superior results when comparing to the state-of-the-art recognition methods. More remarkably, we obtain the top-1 accuracy of 80.5% and 82.7% on Kinetics-400 and Kinetics-600 datasets, respectively. Source code is available at https://github.com/ZhaofanQiu/Optimization-Planning-for-3D-ConvNets.