 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChen Zhao
Large Language Models Help Humans Verify Truthfulness -- Except When They Are Convincingly Wrong
Oct 19, 2023
Large Language Models (LLMs) are increasingly used for accessing information on the web. Their truthfulness and factuality are thus of great interest. To help users make the right decisions about the information they're getting, LLMs should not only provide but also help users fact-check information. In this paper, we conduct experiments with 80 crowdworkers in total to compare language models with search engines (information retrieval systems) at facilitating fact-checking by human users. We prompt LLMs to validate a given claim and provide corresponding explanations. Users reading LLM explanations are significantly more efficient than using search engines with similar accuracy. However, they tend to over-rely the LLMs when the explanation is wrong. To reduce over-reliance on LLMs, we ask LLMs to provide contrastive information - explain both why the claim is true and false, and then we present both sides of the explanation to users. This contrastive explanation mitigates users' over-reliance on LLMs, but cannot significantly outperform search engines. However, showing both search engine results and LLM explanations offers no complementary benefits as compared to search engines alone. Taken together, natural language explanations by LLMs may not be a reliable replacement for reading the retrieved passages yet, especially in high-stakes settings where over-relying on wrong AI explanations could lead to critical consequences.
Multi-View Variational Autoencoder for Missing Value Imputation in Untargeted Metabolomics
Oct 12, 2023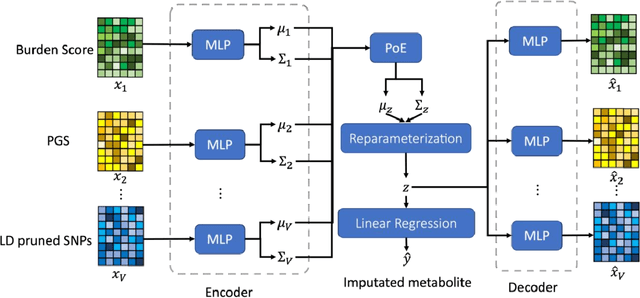
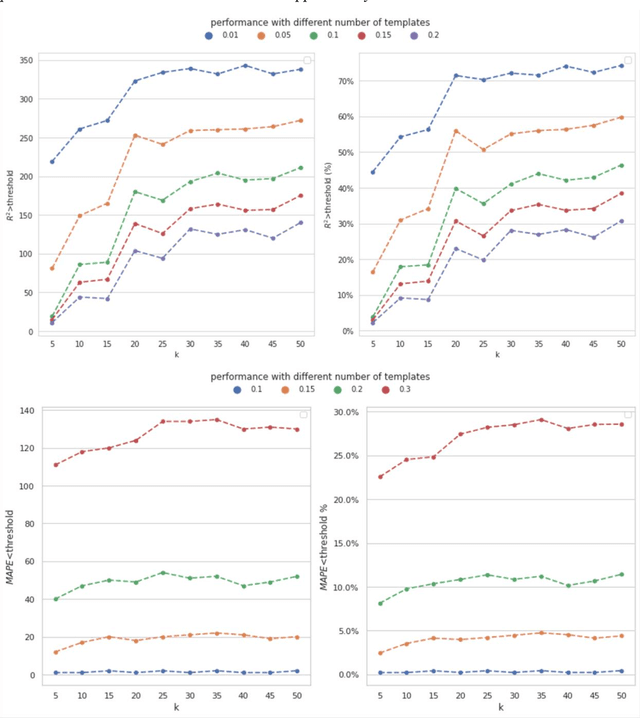
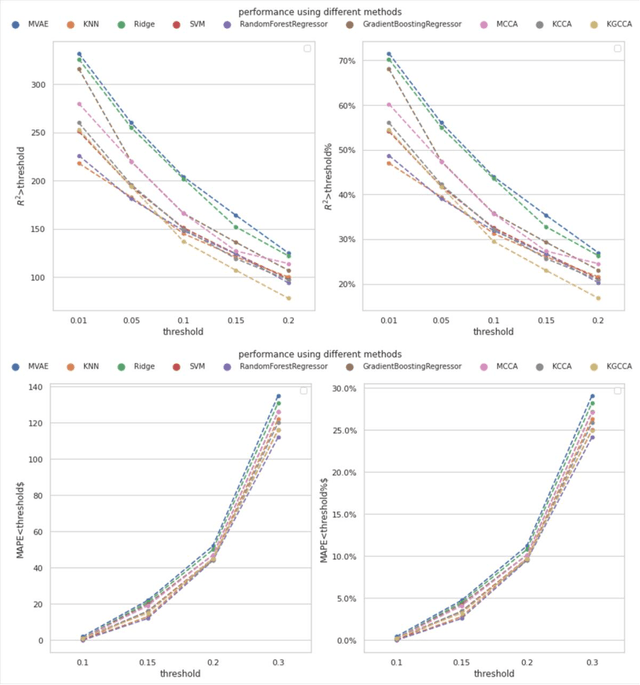
Background: Missing data is a common challenge in mass spectrometry-based metabolomics, which can lead to biased and incomplete analyses. The integration of whole-genome sequencing (WGS) data with metabolomics data has emerged as a promising approach to enhance the accuracy of data imputation in metabolomics studies. Method: In this study, we propose a novel method that leverages the information from WGS data and reference metabolites to impute unknown metabolites. Our approach utilizes a multi-view variational autoencoder to jointly model the burden score, polygenetic risk score (PGS), and linkage disequilibrium (LD) pruned single nucleotide polymorphisms (SNPs) for feature extraction and missing metabolomics data imputation. By learning the latent representations of both omics data, our method can effectively impute missing metabolomics values based on genomic information. Results: We evaluate the performance of our method on empirical metabolomics datasets with missing values and demonstrate its superiority compared to conventional imputation techniques. Using 35 template metabolites derived burden scores, PGS and LD-pruned SNPs, the proposed methods achieved r2-scores > 0.01 for 71.55% of metabolites. Conclusion: The integration of WGS data in metabolomics imputation not only improves data completeness but also enhances downstream analyses, paving the way for more comprehensive and accurate investigations of metabolic pathways and disease associations. Our findings offer valuable insights into the potential benefits of utilizing WGS data for metabolomics data imputation and underscore the importance of leveraging multi-modal data integration in precision medicine research.
3D-Aware Hypothesis & Verification for Generalizable Relative Object Pose Estimation
Oct 05, 2023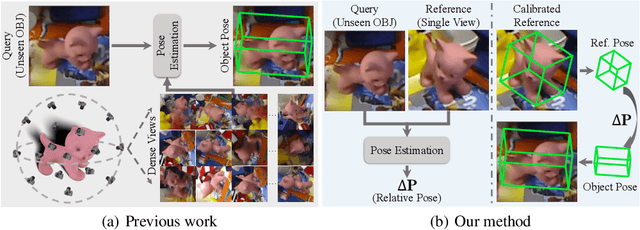

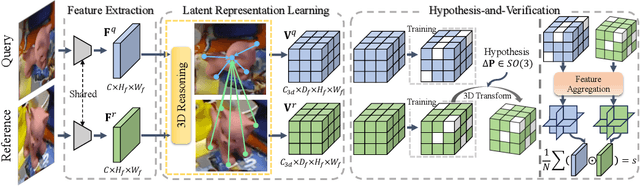

Prior methods that tackle the problem of generalizable object pose estimation highly rely on having dense views of the unseen object. By contrast, we address the scenario where only a single reference view of the object is available. Our goal then is to estimate the relative object pose between this reference view and a query image that depicts the object in a different pose. In this scenario, robust generalization is imperative due to the presence of unseen objects during testing and the large-scale object pose variation between the reference and the query. To this end, we present a new hypothesis-and-verification framework, in which we generate and evaluate multiple pose hypotheses, ultimately selecting the most reliable one as the relative object pose. To measure reliability, we introduce a 3D-aware verification that explicitly applies 3D transformations to the 3D object representations learned from the two input images. Our comprehensive experiments on the Objaverse, LINEMOD, and CO3D datasets evidence the superior accuracy of our approach in relative pose estimation and its robustness in large-scale pose variations, when dealing with unseen objects.
Pursuing Counterfactual Fairness via Sequential Autoencoder Across Domains
Sep 22, 2023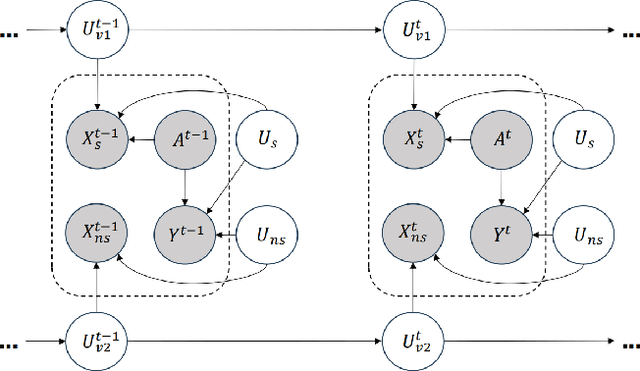
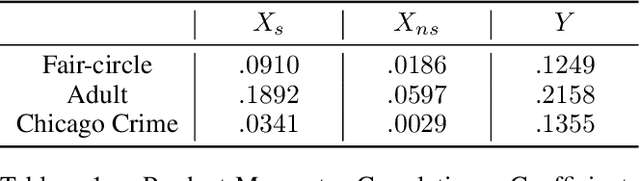
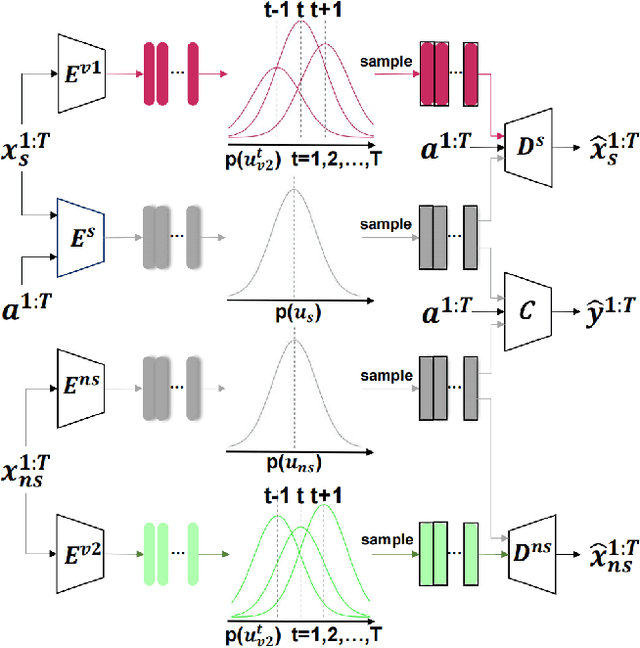
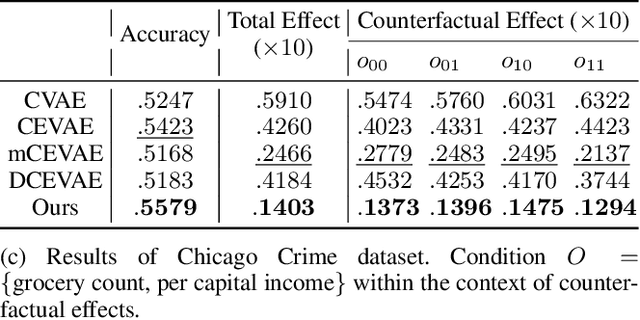
Recognizing the prevalence of domain shift as a common challenge in machine learning, various domain generalization (DG) techniques have been developed to enhance the performance of machine learning systems when dealing with out-of-distribution (OOD) data. Furthermore, in real-world scenarios, data distributions can gradually change across a sequence of sequential domains. While current methodologies primarily focus on improving model effectiveness within these new domains, they often overlook fairness issues throughout the learning process. In response, we introduce an innovative framework called Counterfactual Fairness-Aware Domain Generalization with Sequential Autoencoder (CDSAE). This approach effectively separates environmental information and sensitive attributes from the embedded representation of classification features. This concurrent separation not only greatly improves model generalization across diverse and unfamiliar domains but also effectively addresses challenges related to unfair classification. Our strategy is rooted in the principles of causal inference to tackle these dual issues. To examine the intricate relationship between semantic information, sensitive attributes, and environmental cues, we systematically categorize exogenous uncertainty factors into four latent variables: 1) semantic information influenced by sensitive attributes, 2) semantic information unaffected by sensitive attributes, 3) environmental cues influenced by sensitive attributes, and 4) environmental cues unaffected by sensitive attributes. By incorporating fairness regularization, we exclusively employ semantic information for classification purposes. Empirical validation on synthetic and real-world datasets substantiates the effectiveness of our approach, demonstrating improved accuracy levels while ensuring the preservation of fairness in the evolving landscape of continuous domains.
A new method of modeling the multi-stage decision-making process of CRT using machine learning with uncertainty quantification
Sep 19, 2023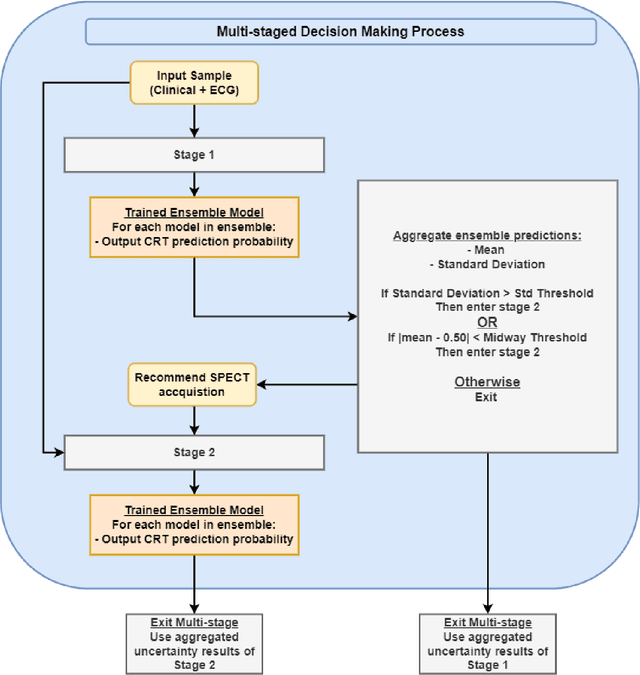
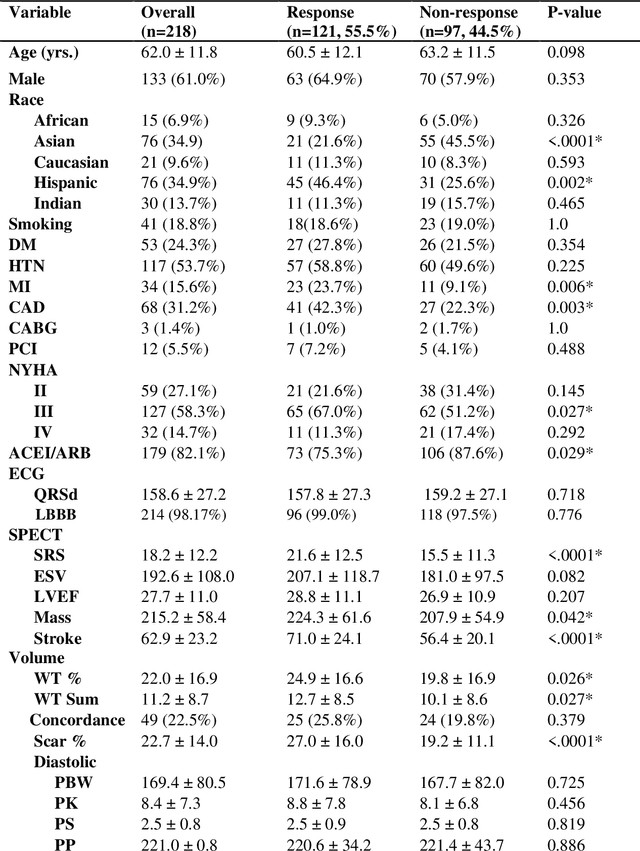
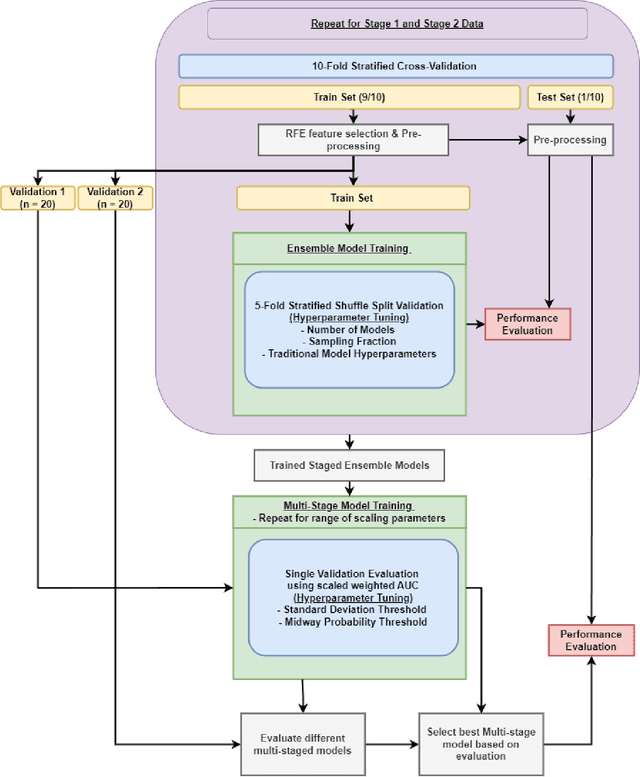
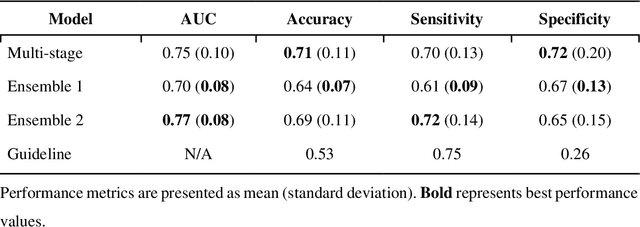
Aims. The purpose of this study is to create a multi-stage machine learning model to predict cardiac resynchronization therapy (CRT) response for heart failure (HF) patients. This model exploits uncertainty quantification to recommend additional collection of single-photon emission computed tomography myocardial perfusion imaging (SPECT MPI) variables if baseline clinical variables and features from electrocardiogram (ECG) are not sufficient. Methods. 218 patients who underwent rest-gated SPECT MPI were enrolled in this study. CRT response was defined as an increase in left ventricular ejection fraction (LVEF) > 5% at a 6 month follow-up. A multi-stage ML model was created by combining two ensemble models. Results. The response rate for CRT was 55.5% (n = 121) with overall male gender 61.0% (n = 133), an average age of 62.0, and LVEF of 27.7. The multi-stage model performed similarly to Ensemble 2 (which utilized the additional SPECT data) with AUC of 0.75 vs. 0.77, accuracy of 0.71 vs. 0.69, sensitivity of 0.70 vs. 0.72, and specificity 0.72 vs. 0.65, respectively. However, the multi-stage model only required SPECT MPI data for 52.7% of the patients across all folds. Conclusions. By using rule-based logic stemming from uncertainty quantification, the multi-stage model was able to reduce the need for additional SPECT MPI data acquisition without sacrificing performance.
Towards Effective Semantic OOD Detection in Unseen Domains: A Domain Generalization Perspective
Sep 18, 2023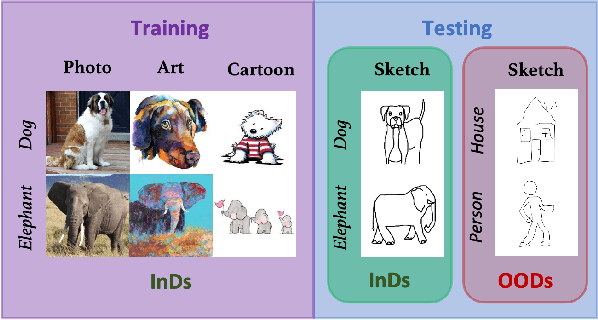

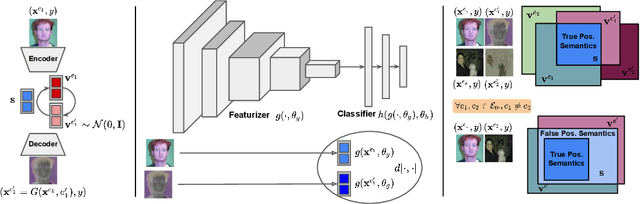
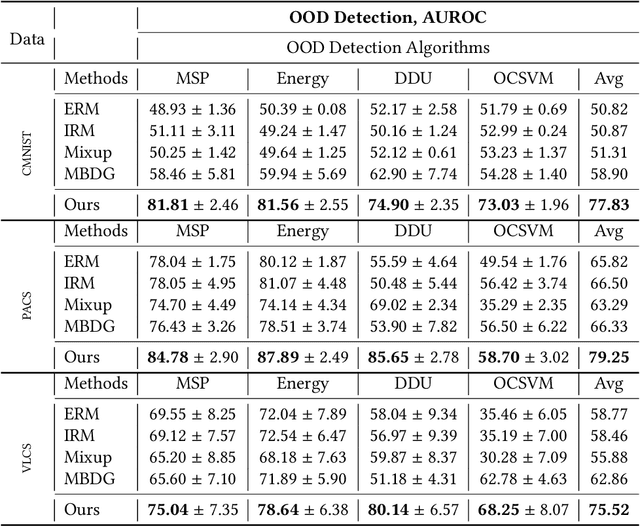
Two prevalent types of distributional shifts in machine learning are the covariate shift (as observed across different domains) and the semantic shift (as seen across different classes). Traditional OOD detection techniques typically address only one of these shifts. However, real-world testing environments often present a combination of both covariate and semantic shifts. In this study, we introduce a novel problem, semantic OOD detection across domains, which simultaneously addresses both distributional shifts. To this end, we introduce two regularization strategies: domain generalization regularization, which ensures semantic invariance across domains to counteract the covariate shift, and OOD detection regularization, designed to enhance OOD detection capabilities against the semantic shift through energy bounding. Through rigorous testing on three standard domain generalization benchmarks, our proposed framework showcases its superiority over conventional domain generalization approaches in terms of OOD detection performance. Moreover, it holds its ground by maintaining comparable InD classification accuracy.
Toward Sufficient Spatial-Frequency Interaction for Gradient-aware Underwater Image Enhancement
Sep 08, 2023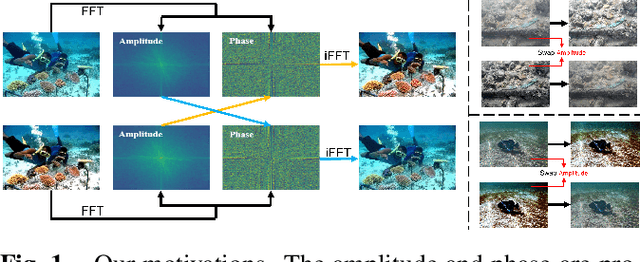
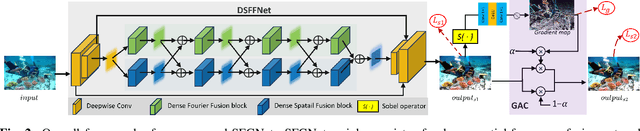
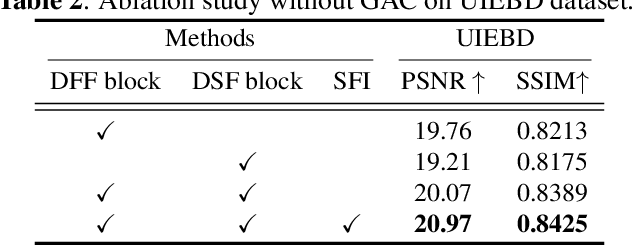
Underwater images suffer from complex and diverse degradation, which inevitably affects the performance of underwater visual tasks. However, most existing learning-based Underwater image enhancement (UIE) methods mainly restore such degradations in the spatial domain, and rarely pay attention to the fourier frequency information. In this paper, we develop a novel UIE framework based on spatial-frequency interaction and gradient maps, namely SFGNet, which consists of two stages. Specifically, in the first stage, we propose a dense spatial-frequency fusion network (DSFFNet), mainly including our designed dense fourier fusion block and dense spatial fusion block, achieving sufficient spatial-frequency interaction by cross connections between these two blocks. In the second stage, we propose a gradient-aware corrector (GAC) to further enhance perceptual details and geometric structures of images by gradient map. Experimental results on two real-world underwater image datasets show that our approach can successfully enhance underwater images, and achieves competitive performance in visual quality improvement.
Adaptation Speed Analysis for Fairness-aware Causal Models
Aug 31, 2023For example, in machine translation tasks, to achieve bidirectional translation between two languages, the source corpus is often used as the target corpus, which involves the training of two models with opposite directions. The question of which one can adapt most quickly to a domain shift is of significant importance in many fields. Specifically, consider an original distribution p that changes due to an unknown intervention, resulting in a modified distribution p*. In aligning p with p*, several factors can affect the adaptation rate, including the causal dependencies between variables in p. In real-life scenarios, however, we have to consider the fairness of the training process, and it is particularly crucial to involve a sensitive variable (bias) present between a cause and an effect variable. To explore this scenario, we examine a simple structural causal model (SCM) with a cause-bias-effect structure, where variable A acts as a sensitive variable between cause (X) and effect (Y). The two models, respectively, exhibit consistent and contrary cause-effect directions in the cause-bias-effect SCM. After conducting unknown interventions on variables within the SCM, we can simulate some kinds of domain shifts for analysis. We then compare the adaptation speeds of two models across four shift scenarios. Additionally, we prove the connection between the adaptation speeds of the two models across all interventions.
Transformer Compression via Subspace Projection
Aug 31, 2023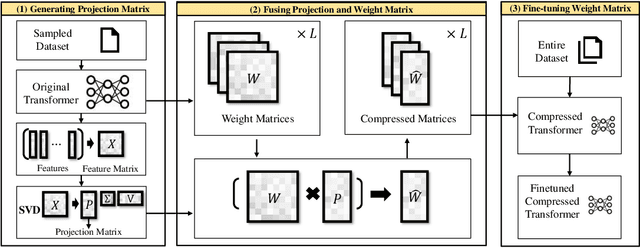
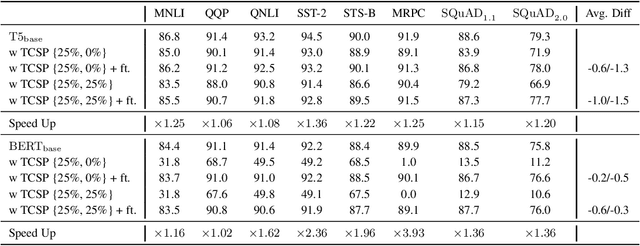


We propose TCSP, a novel method for compressing a transformer model by focusing on reducing the hidden size of the model. By projecting the whole transform model into a subspace, we enable matrix operations between the weight matrices in the model and features in a reduced-dimensional space, leading to significant reductions in model parameters and computing resources. To establish this subspace, we decompose the feature matrix, derived from different layers of sampled data instances, into a projection matrix. For evaluation, TCSP is applied to compress T5 and BERT models on the GLUE and SQuAD benchmarks. Experimental results demonstrate that TCSP achieves a compression ratio of 44\% with at most 1.6\% degradation in accuracy, surpassing or matching prior compression methods. Furthermore, TCSP exhibits compatibility with other methods targeting filter and attention head size compression.