 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChen Liang
UniTS: A Universal Time Series Analysis Framework with Self-supervised Representation Learning
Mar 24, 2023

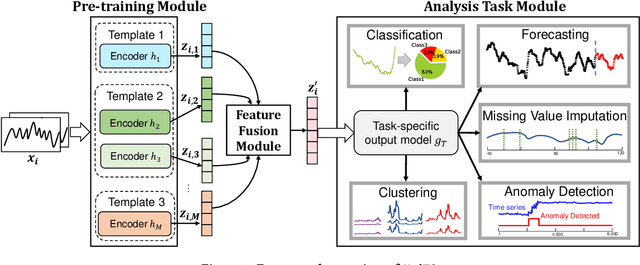
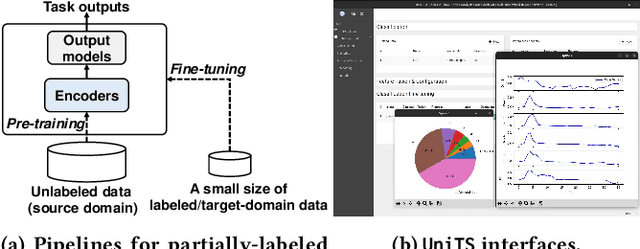
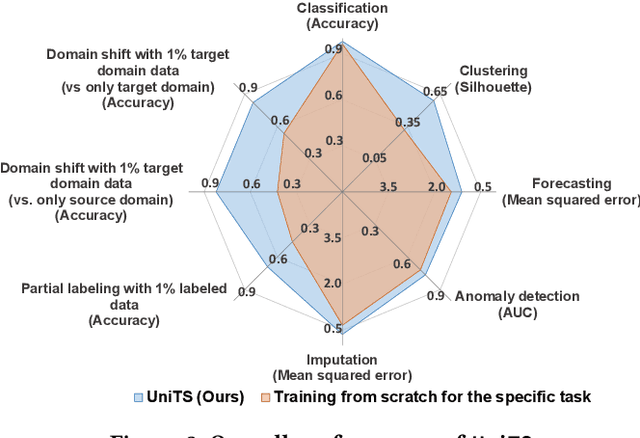
Machine learning has emerged as a powerful tool for time series analysis. Existing methods are usually customized for different analysis tasks and face challenges in tackling practical problems such as partial labeling and domain shift. To achieve universal analysis and address the aforementioned problems, we develop UniTS, a novel framework that incorporates self-supervised representation learning (or pre-training). The components of UniTS are designed using sklearn-like APIs to allow flexible extensions. We demonstrate how users can easily perform an analysis task using the user-friendly GUIs, and show the superior performance of UniTS over the traditional task-specific methods without self-supervised pre-training on five mainstream tasks and two practical settings.
DR-Label: Improving GNN Models for Catalysis Systems by Label Deconstruction and Reconstruction
Mar 06, 2023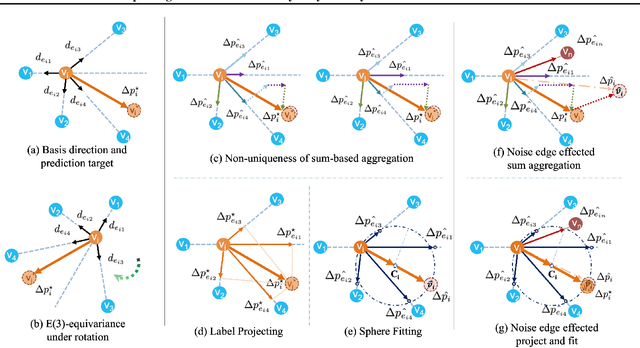
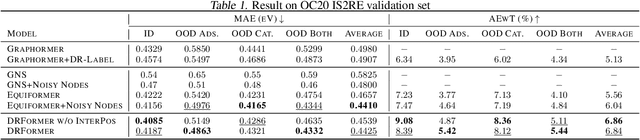
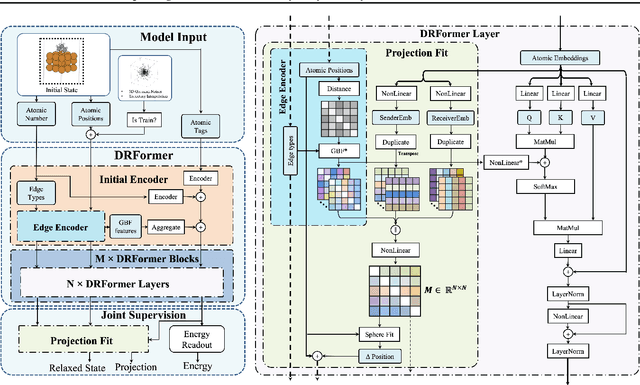
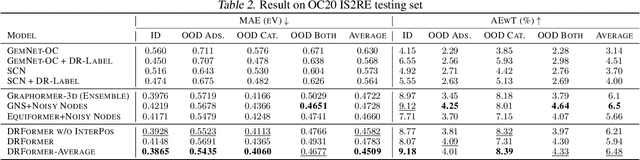
Attaining the equilibrium state of a catalyst-adsorbate system is key to fundamentally assessing its effective properties, such as adsorption energy. Machine learning methods with finer supervision strategies have been applied to boost and guide the relaxation process of an atomic system and better predict its properties at the equilibrium state. In this paper, we present a novel graph neural network (GNN) supervision and prediction strategy DR-Label. The method enhances the supervision signal, reduces the multiplicity of solutions in edge representation, and encourages the model to provide node predictions that are graph structural variation robust. DR-Label first Deconstructs finer-grained equilibrium state information to the model by projecting the node-level supervision signal to each edge. Reversely, the model Reconstructs a more robust equilibrium state prediction by transforming edge-level predictions to node-level with a sphere-fitting algorithm. The DR-Label strategy was applied to three radically distinct models, each of which displayed consistent performance enhancements. Based on the DR-Label strategy, we further proposed DRFormer, which achieved a new state-of-the-art performance on the Open Catalyst 2020 (OC20) dataset and the Cu-based single-atom-alloyed CO adsorption (SAA) dataset. We expect that our work will highlight crucial steps for the development of a more accurate model in equilibrium state property prediction of a catalysis system.
HomoDistil: Homotopic Task-Agnostic Distillation of Pre-trained Transformers
Feb 19, 2023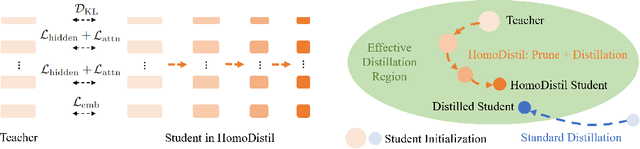

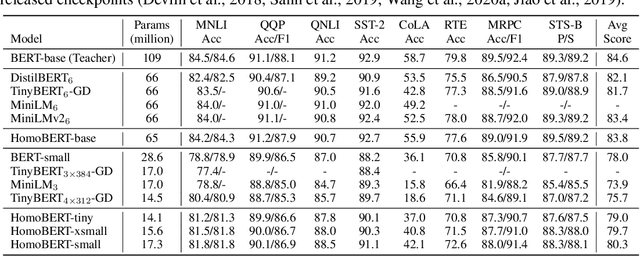
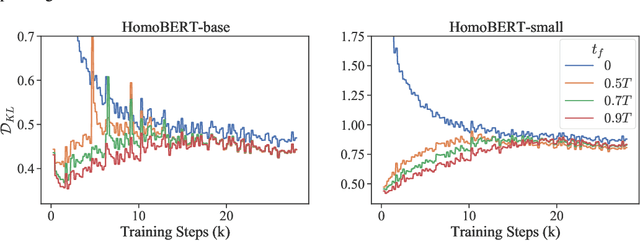
Knowledge distillation has been shown to be a powerful model compression approach to facilitate the deployment of pre-trained language models in practice. This paper focuses on task-agnostic distillation. It produces a compact pre-trained model that can be easily fine-tuned on various tasks with small computational costs and memory footprints. Despite the practical benefits, task-agnostic distillation is challenging. Since the teacher model has a significantly larger capacity and stronger representation power than the student model, it is very difficult for the student to produce predictions that match the teacher's over a massive amount of open-domain training data. Such a large prediction discrepancy often diminishes the benefits of knowledge distillation. To address this challenge, we propose Homotopic Distillation (HomoDistil), a novel task-agnostic distillation approach equipped with iterative pruning. Specifically, we initialize the student model from the teacher model, and iteratively prune the student's neurons until the target width is reached. Such an approach maintains a small discrepancy between the teacher's and student's predictions throughout the distillation process, which ensures the effectiveness of knowledge transfer. Extensive experiments demonstrate that HomoDistil achieves significant improvements on existing baselines.
Symbolic Discovery of Optimization Algorithms
Feb 17, 2023
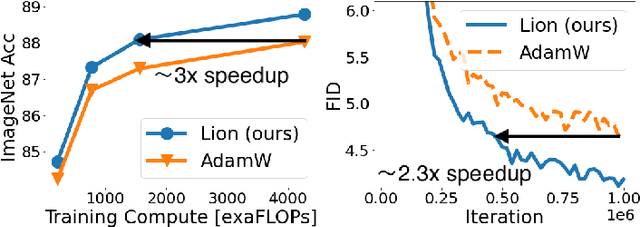
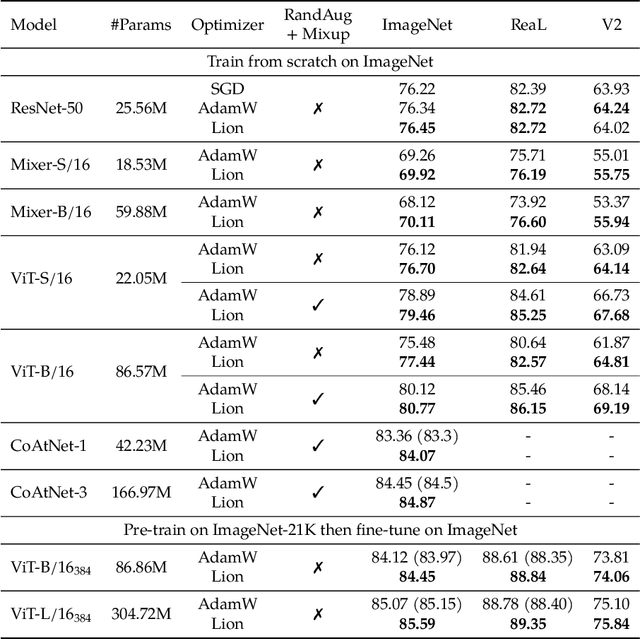
We present a method to formulate algorithm discovery as program search, and apply it to discover optimization algorithms for deep neural network training. We leverage efficient search techniques to explore an infinite and sparse program space. To bridge the large generalization gap between proxy and target tasks, we also introduce program selection and simplification strategies. Our method discovers a simple and effective optimization algorithm, $\textbf{Lion}$ ($\textit{Evo$\textbf{L}$ved S$\textbf{i}$gn M$\textbf{o}$me$\textbf{n}$tum}$). It is more memory-efficient than Adam as it only keeps track of the momentum. Different from adaptive optimizers, its update has the same magnitude for each parameter calculated through the sign operation. We compare Lion with widely used optimizers, such as Adam and Adafactor, for training a variety of models on different tasks. On image classification, Lion boosts the accuracy of ViT by up to 2% on ImageNet and saves up to 5x the pre-training compute on JFT. On vision-language contrastive learning, we achieve 88.3% $\textit{zero-shot}$ and 91.1% $\textit{fine-tuning}$ accuracy on ImageNet, surpassing the previous best results by 2% and 0.1%, respectively. On diffusion models, Lion outperforms Adam by achieving a better FID score and reducing the training compute by up to 2.3x. For autoregressive, masked language modeling, and fine-tuning, Lion exhibits a similar or better performance compared to Adam. Our analysis of Lion reveals that its performance gain grows with the training batch size. It also requires a smaller learning rate than Adam due to the larger norm of the update produced by the sign function. Additionally, we examine the limitations of Lion and identify scenarios where its improvements are small or not statistically significant. The implementation of Lion is publicly available.
Unified Functional Hashing in Automatic Machine Learning
Feb 10, 2023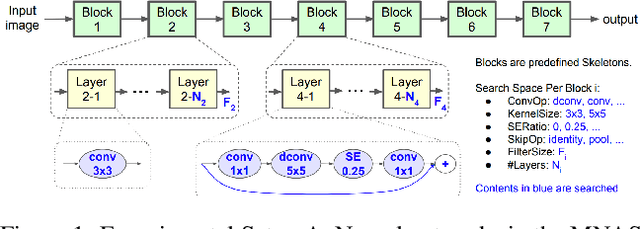

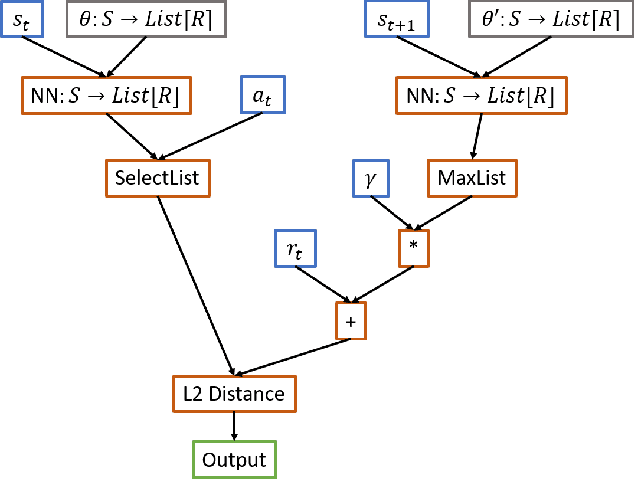
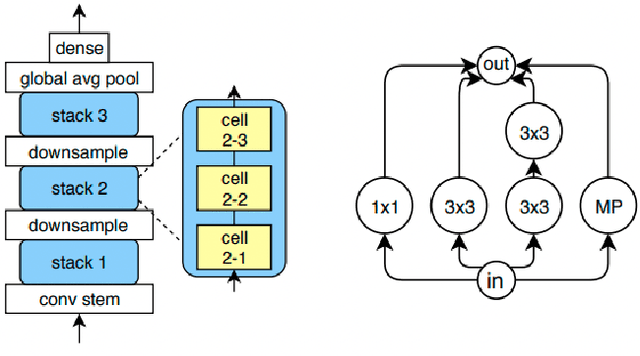
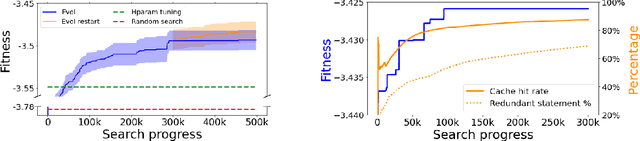
The field of Automatic Machine Learning (AutoML) has recently attained impressive results, including the discovery of state-of-the-art machine learning solutions, such as neural image classifiers. This is often done by applying an evolutionary search method, which samples multiple candidate solutions from a large space and evaluates the quality of each candidate through a long training process. As a result, the search tends to be slow. In this paper, we show that large efficiency gains can be obtained by employing a fast unified functional hash, especially through the functional equivalence caching technique, which we also present. The central idea is to detect by hashing when the search method produces equivalent candidates, which occurs very frequently, and this way avoid their costly re-evaluation. Our hash is "functional" in that it identifies equivalent candidates even if they were represented or coded differently, and it is "unified" in that the same algorithm can hash arbitrary representations; e.g. compute graphs, imperative code, or lambda functions. As evidence, we show dramatic improvements on multiple AutoML domains, including neural architecture search and algorithm discovery. Finally, we consider the effect of hash collisions, evaluation noise, and search distribution through empirical analysis. Altogether, we hope this paper may serve as a guide to hashing techniques in AutoML.
Less is More: Task-aware Layer-wise Distillation for Language Model Compression
Oct 05, 2022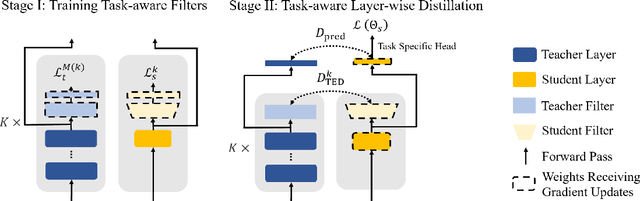
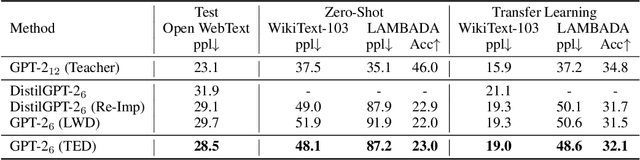
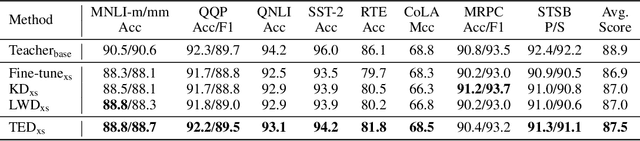
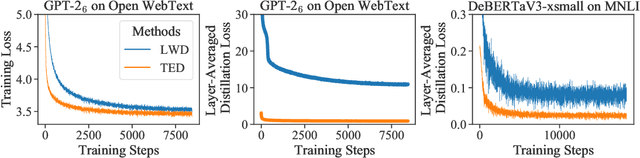
Layer-wise distillation is a powerful tool to compress large models (i.e. teacher models) into small ones (i.e., student models). The student distills knowledge from the teacher by mimicking the hidden representations of the teacher at every intermediate layer. However, layer-wise distillation is difficult. Since the student has a smaller model capacity than the teacher, it is often under-fitted. Furthermore, the hidden representations of the teacher contain redundant information that the student does not necessarily need for the target task's learning. To address these challenges, we propose a novel Task-aware layEr-wise Distillation (TED). TED designs task-aware filters to align the hidden representations of the student and the teacher at each layer. The filters select the knowledge that is useful for the target task from the hidden representations. As such, TED reduces the knowledge gap between the two models and helps the student to fit better on the target task. We evaluate TED in two scenarios: continual pre-training and fine-tuning. TED demonstrates significant and consistent improvements over existing distillation methods in both scenarios.
GMMSeg: Gaussian Mixture based Generative Semantic Segmentation Models
Oct 05, 2022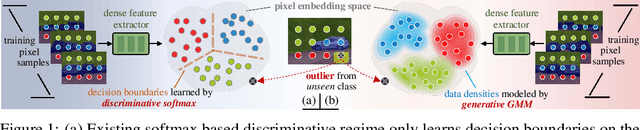
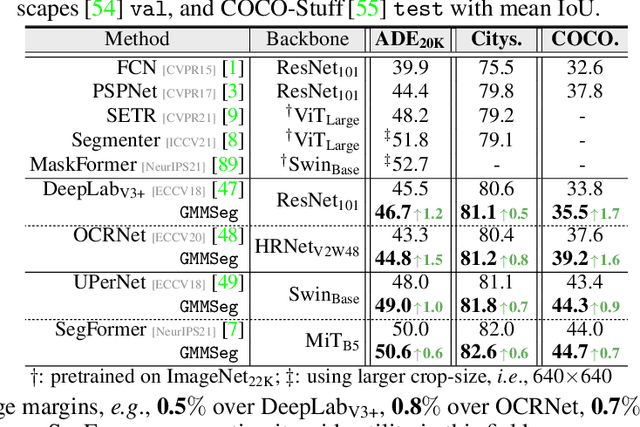

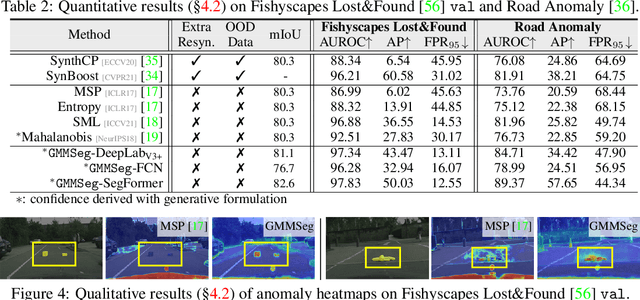
Prevalent semantic segmentation solutions are, in essence, a dense discriminative classifier of p(class|pixel feature). Though straightforward, this de facto paradigm neglects the underlying data distribution p(pixel feature|class), and struggles to identify out-of-distribution data. Going beyond this, we propose GMMSeg, a new family of segmentation models that rely on a dense generative classifier for the joint distribution p(pixel feature,class). For each class, GMMSeg builds Gaussian Mixture Models (GMMs) via Expectation-Maximization (EM), so as to capture class-conditional densities. Meanwhile, the deep dense representation is end-to-end trained in a discriminative manner, i.e., maximizing p(class|pixel feature). This endows GMMSeg with the strengths of both generative and discriminative models. With a variety of segmentation architectures and backbones, GMMSeg outperforms the discriminative counterparts on three closed-set datasets. More impressively, without any modification, GMMSeg even performs well on open-world datasets. We believe this work brings fundamental insights into the related fields.
Multi-Task Mixture Density Graph Neural Networks for Predicting Cu-based Single-Atom Alloy Catalysts for CO2 Reduction Reaction
Sep 15, 2022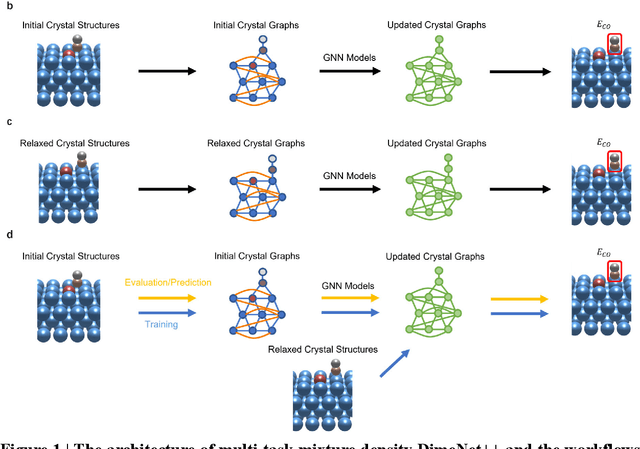
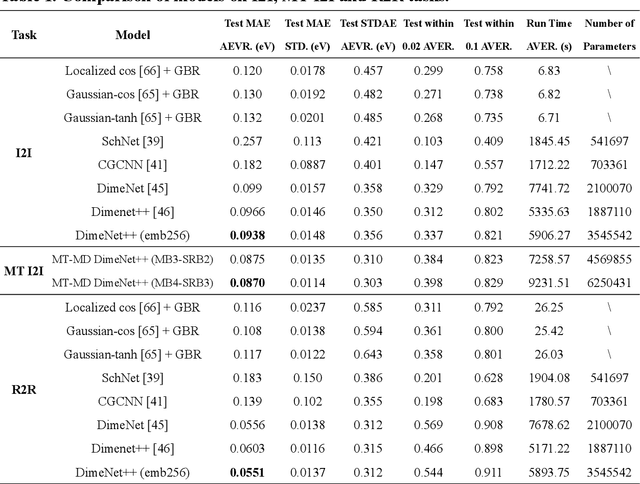
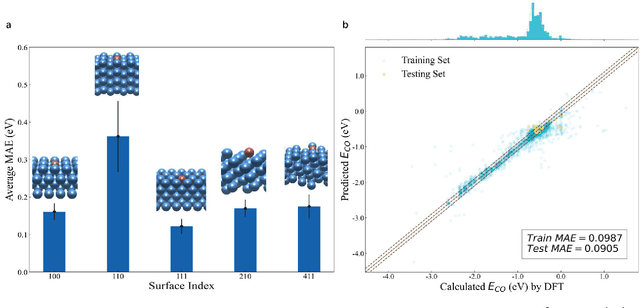

Graph neural networks (GNNs) have drawn more and more attention from material scientists and demonstrated a high capacity to establish connections between the structure and properties. However, with only unrelaxed structures provided as input, few GNN models can predict the thermodynamic properties of relaxed configurations with an acceptable level of error. In this work, we develop a multi-task (MT) architecture based on DimeNet++ and mixture density networks to improve the performance of such task. Taking CO adsorption on Cu-based single-atom alloy catalysts as an illustration, we show that our method can reliably estimate CO adsorption energy with a mean absolute error of 0.087 eV from the initial CO adsorption structures without costly first-principles calculations. Further, compared to other state-of-the-art GNN methods, our model exhibits improved generalization ability when predicting catalytic performance of out-of-domain configurations, built with either unseen substrate surfaces or doping species. We show that the proposed MT GNN strategy can facilitate catalyst discovery.
PLATON: Pruning Large Transformer Models with Upper Confidence Bound of Weight Importance
Jun 25, 2022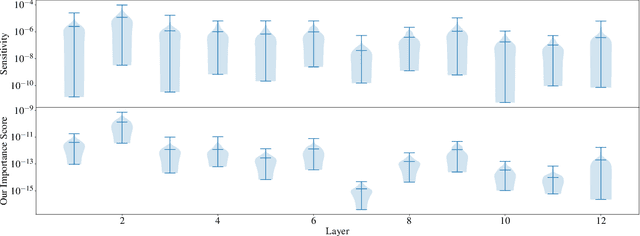
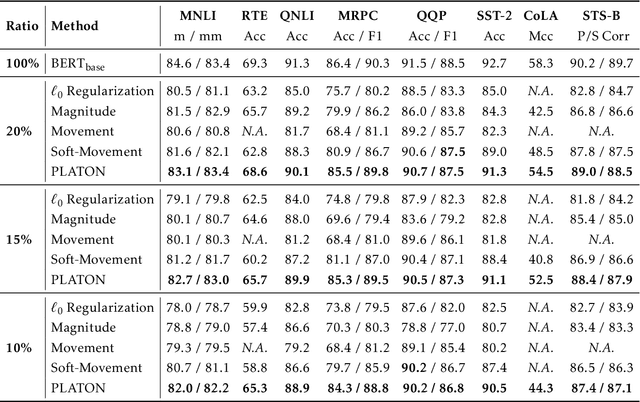
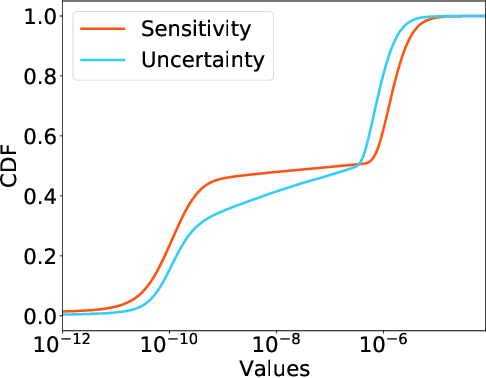
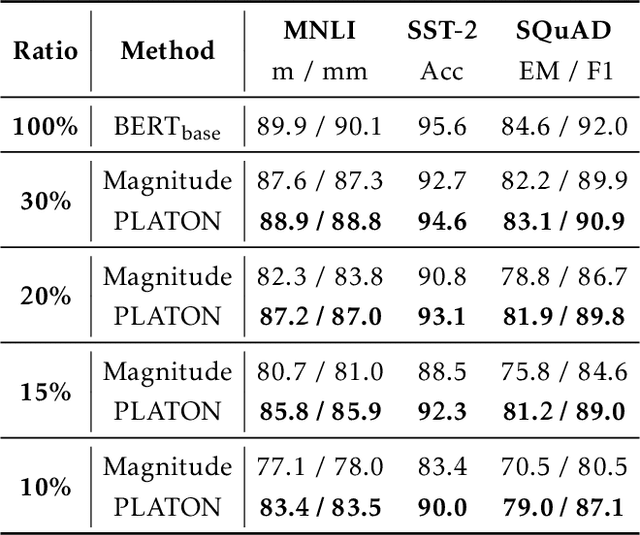
Large Transformer-based models have exhibited superior performance in various natural language processing and computer vision tasks. However, these models contain enormous amounts of parameters, which restrict their deployment to real-world applications. To reduce the model size, researchers prune these models based on the weights' importance scores. However, such scores are usually estimated on mini-batches during training, which incurs large variability/uncertainty due to mini-batch sampling and complicated training dynamics. As a result, some crucial weights could be pruned by commonly used pruning methods because of such uncertainty, which makes training unstable and hurts generalization. To resolve this issue, we propose PLATON, which captures the uncertainty of importance scores by upper confidence bound (UCB) of importance estimation. In particular, for the weights with low importance scores but high uncertainty, PLATON tends to retain them and explores their capacity. We conduct extensive experiments with several Transformer-based models on natural language understanding, question answering and image classification to validate the effectiveness of PLATON. Results demonstrate that PLATON manifests notable improvement under different sparsity levels. Our code is publicly available at https://github.com/QingruZhang/PLATON.
MoEBERT: from BERT to Mixture-of-Experts via Importance-Guided Adaptation
Apr 28, 2022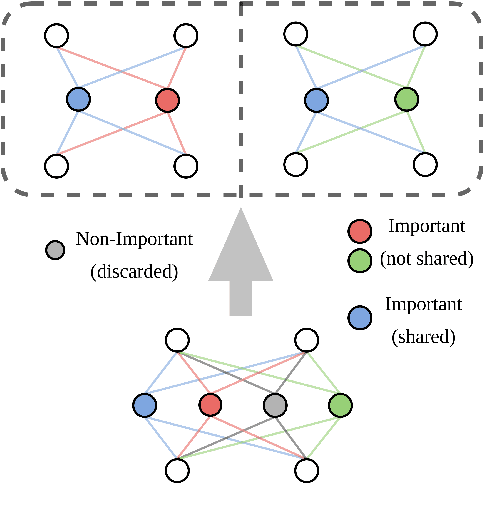
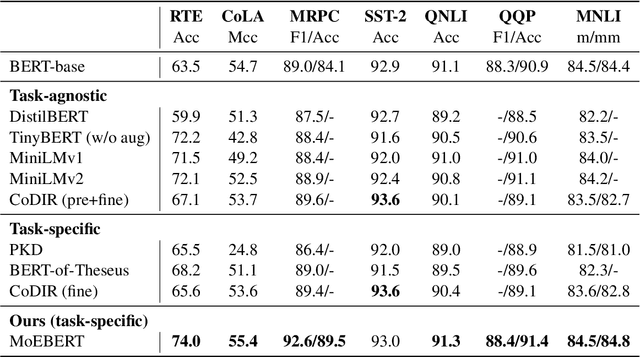
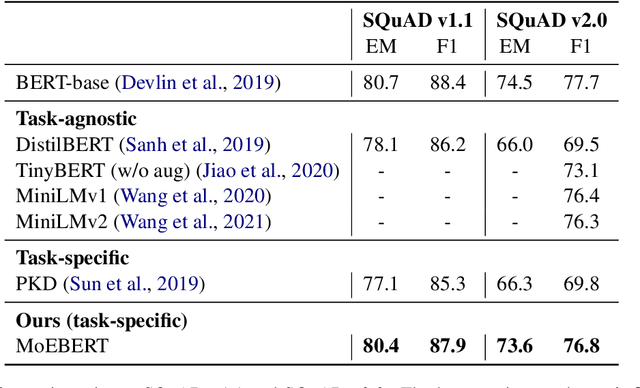
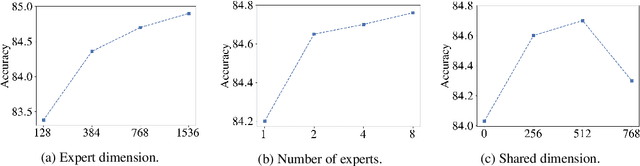
Pre-trained language models have demonstrated superior performance in various natural language processing tasks. However, these models usually contain hundreds of millions of parameters, which limits their practicality because of latency requirements in real-world applications. Existing methods train small compressed models via knowledge distillation. However, performance of these small models drops significantly compared with the pre-trained models due to their reduced model capacity. We propose MoEBERT, which uses a Mixture-of-Experts structure to increase model capacity and inference speed. We initialize MoEBERT by adapting the feed-forward neural networks in a pre-trained model into multiple experts. As such, representation power of the pre-trained model is largely retained. During inference, only one of the experts is activated, such that speed can be improved. We also propose a layer-wise distillation method to train MoEBERT. We validate the efficiency and effectiveness of MoEBERT on natural language understanding and question answering tasks. Results show that the proposed method outperforms existing task-specific distillation algorithms. For example, our method outperforms previous approaches by over 2% on the MNLI (mismatched) dataset. Our code is publicly available at https://github.com/SimiaoZuo/MoEBERT.