 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChen Chen
CalFAT: Calibrated Federated Adversarial Training with Label Skewness
May 30, 2022
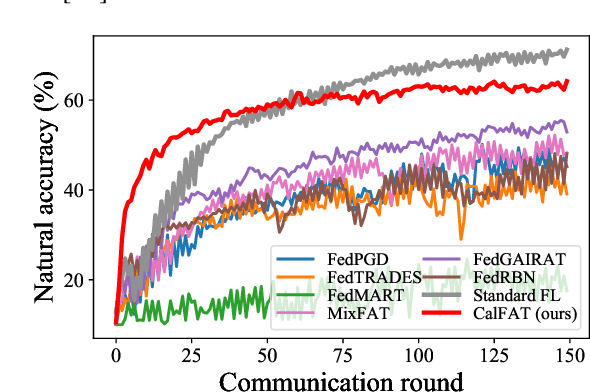

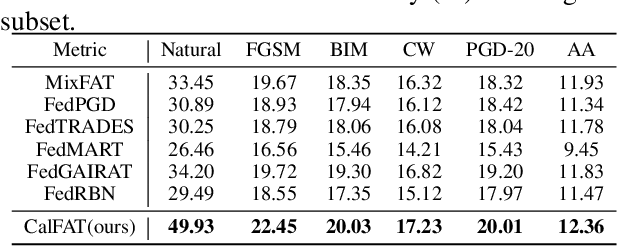
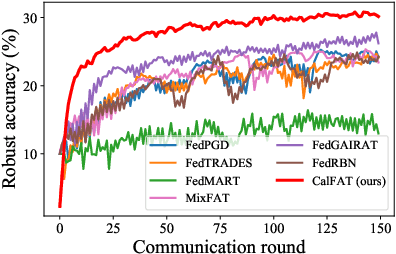
Recent studies have shown that, like traditional machine learning, federated learning (FL) is also vulnerable to adversarial attacks. To improve the adversarial robustness of FL, few federated adversarial training (FAT) methods have been proposed to apply adversarial training locally before global aggregation. Although these methods demonstrate promising results on independent identically distributed (IID) data, they suffer from training instability issues on non-IID data with label skewness, resulting in much degraded natural accuracy. This tends to hinder the application of FAT in real-world applications where the label distribution across the clients is often skewed. In this paper, we study the problem of FAT under label skewness, and firstly reveal one root cause of the training instability and natural accuracy degradation issues: skewed labels lead to non-identical class probabilities and heterogeneous local models. We then propose a Calibrated FAT (CalFAT) approach to tackle the instability issue by calibrating the logits adaptively to balance the classes. We show both theoretically and empirically that the optimization of CalFAT leads to homogeneous local models across the clients and much improved convergence rate and final performance.
QEKD: Query-Efficient and Data-Free Knowledge Distillation from Black-box Models
May 23, 2022
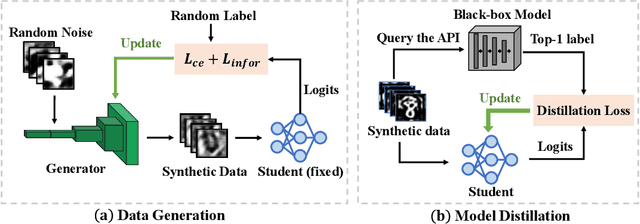
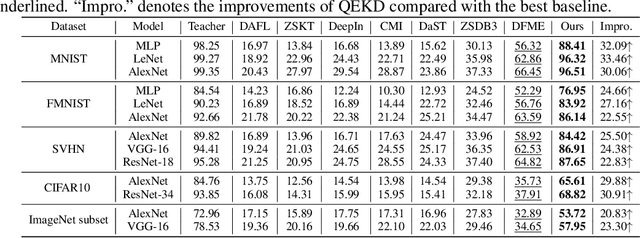
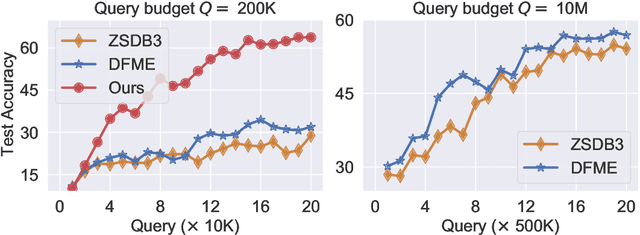
Knowledge distillation (KD) is a typical method for training a lightweight student model with the help of a well-trained teacher model. However, most KD methods require access to either the teacher's training dataset or model parameter, which is unrealistic. To tackle this problem, recent works study KD under data-free and black-box settings. Nevertheless, these works require a large number of queries to the teacher model, which involves significant monetary and computational costs. To this end, we propose a novel method called Query Efficient Knowledge Distillation (QEKD), which aims to query-efficiently learn from black-box model APIs to train a good student without any real data. In detail, QEKD trains the student model in two stages: data generation and model distillation. Note that QEKD does not require any query in the data generation stage and queries the teacher only once for each sample in the distillation stage. Extensive experiments on various real-world datasets show the effectiveness of the proposed QEKD. For instance, QEKD can improve the performance of the best baseline method (DFME) by 5.83 on CIFAR10 dataset with only 0.02x the query budget of DFME.
Rethinking Reinforcement Learning based Logic Synthesis
May 16, 2022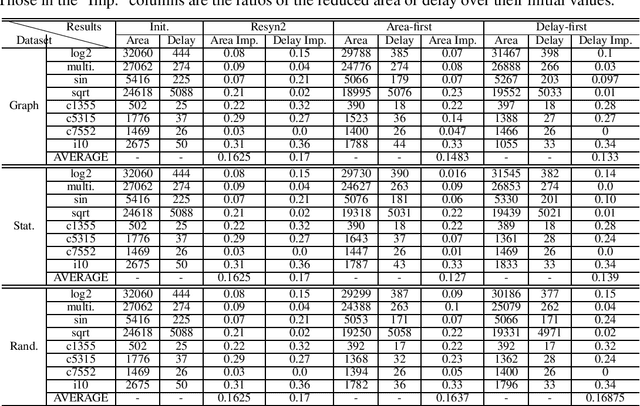
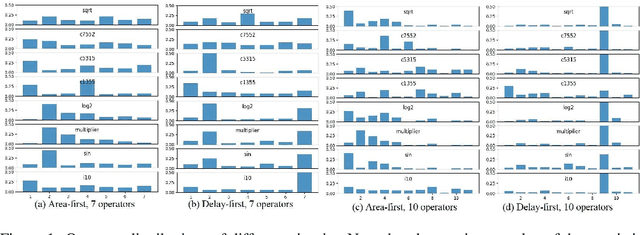

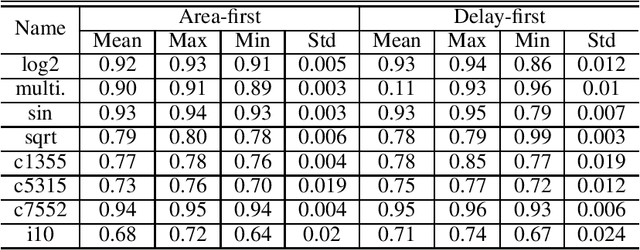
Recently, reinforcement learning has been used to address logic synthesis by formulating the operator sequence optimization problem as a Markov decision process. However, through extensive experiments, we find out that the learned policy makes decisions independent from the circuit features (i.e., states) and yields an operator sequence that is permutation invariant to some extent in terms of operators. Based on these findings, we develop a new RL-based method that can automatically recognize critical operators and generate common operator sequences generalizable to unseen circuits. Our algorithm is verified on both the EPFL benchmark, a private dataset and a circuit at industrial scale. Experimental results demonstrate that it achieves a good balance among delay, area and runtime, and is practical for industrial usage.
FAITH: Few-Shot Graph Classification with Hierarchical Task Graphs
May 07, 2022
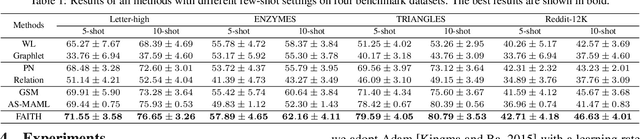
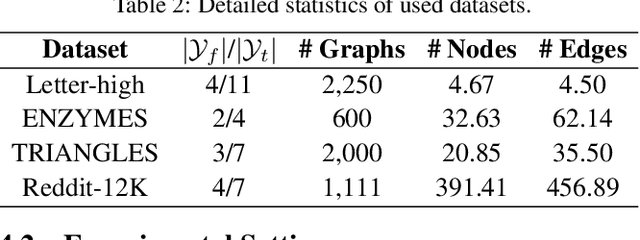
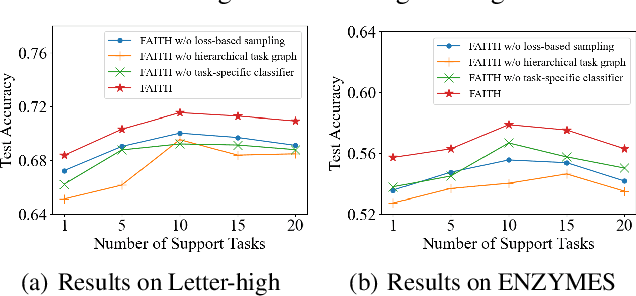
Few-shot graph classification aims at predicting classes for graphs, given limited labeled graphs for each class. To tackle the bottleneck of label scarcity, recent works propose to incorporate few-shot learning frameworks for fast adaptations to graph classes with limited labeled graphs. Specifically, these works propose to accumulate meta-knowledge across diverse meta-training tasks, and then generalize such meta-knowledge to the target task with a disjoint label set. However, existing methods generally ignore task correlations among meta-training tasks while treating them independently. Nevertheless, such task correlations can advance the model generalization to the target task for better classification performance. On the other hand, it remains non-trivial to utilize task correlations due to the complex components in a large number of meta-training tasks. To deal with this, we propose a novel few-shot learning framework FAITH that captures task correlations via constructing a hierarchical task graph at different granularities. Then we further design a loss-based sampling strategy to select tasks with more correlated classes. Moreover, a task-specific classifier is proposed to utilize the learned task correlations for few-shot classification. Extensive experiments on four prevalent few-shot graph classification datasets demonstrate the superiority of FAITH over other state-of-the-art baselines.
Fairness in Graph Mining: A Survey
Apr 21, 2022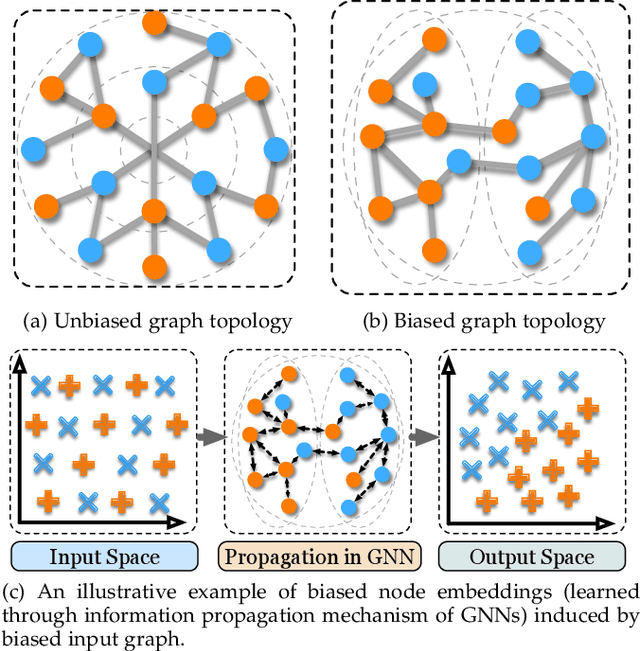
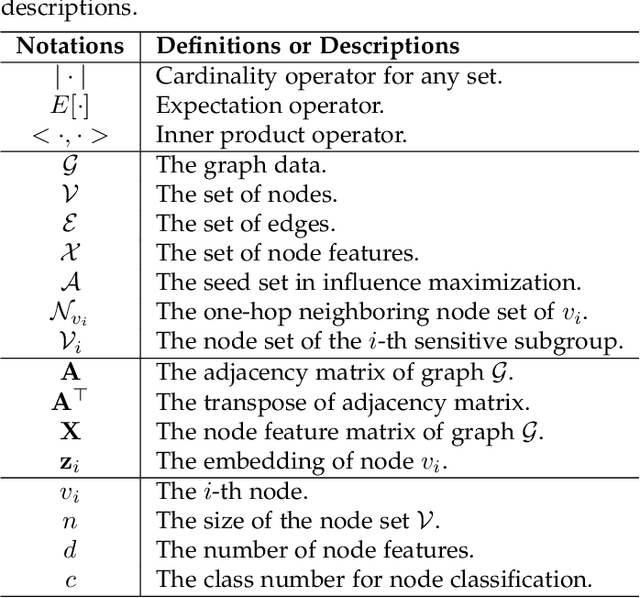
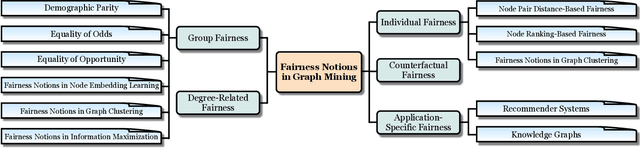
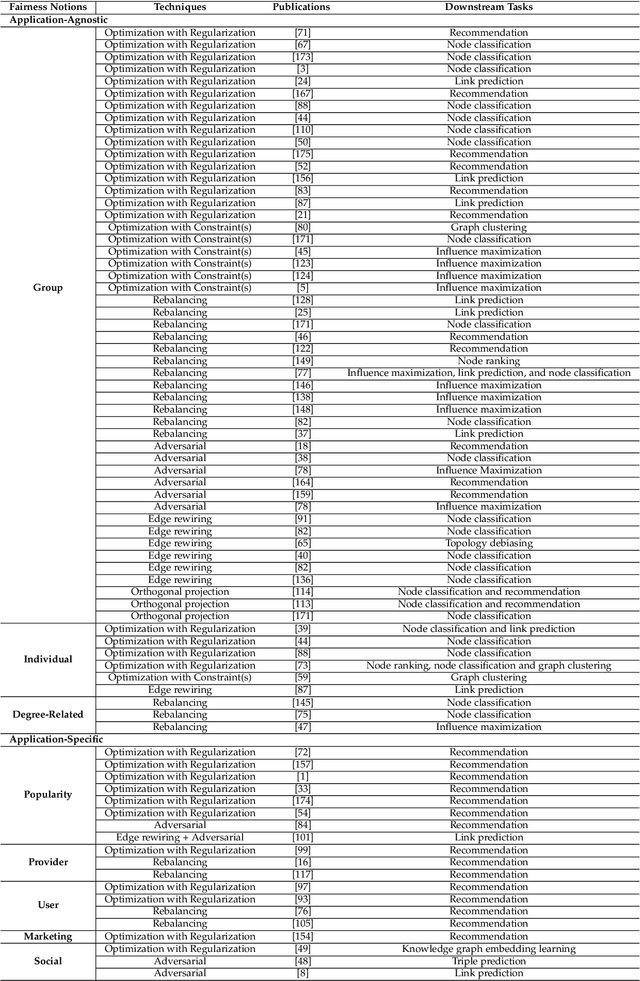
Graph mining algorithms have been playing a significant role in myriad fields over the years. However, despite their promising performance on various graph analytical tasks, most of these algorithms lack fairness considerations. As a consequence, they could lead to discrimination towards certain populations when exploited in human-centered applications. Recently, algorithmic fairness has been extensively studied in graph-based applications. In contrast to algorithmic fairness on independent and identically distributed (i.i.d.) data, fairness in graph mining has exclusive backgrounds, taxonomies, and fulfilling techniques. In this survey, we provide a comprehensive and up-to-date introduction of existing literature under the context of fair graph mining. Specifically, we propose a novel taxonomy of fairness notions on graphs, which sheds light on their connections and differences. We further present an organized summary of existing techniques that promote fairness in graph mining. Finally, we summarize the widely used datasets in this emerging research field and provide insights on current research challenges and open questions, aiming at encouraging cross-breeding ideas and further advances.
Self-critical Sequence Training for Automatic Speech Recognition
Apr 13, 2022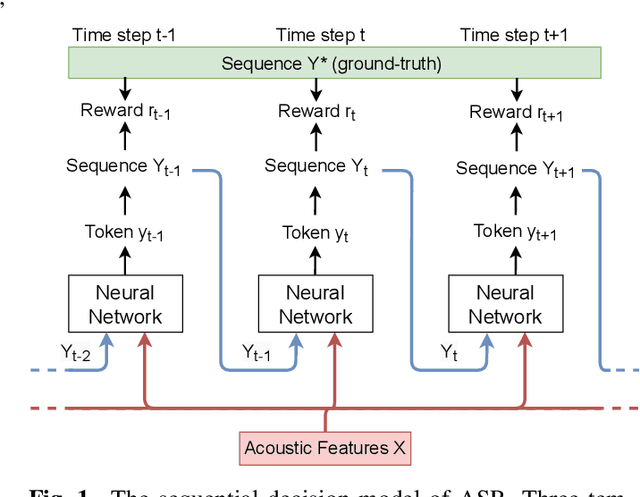
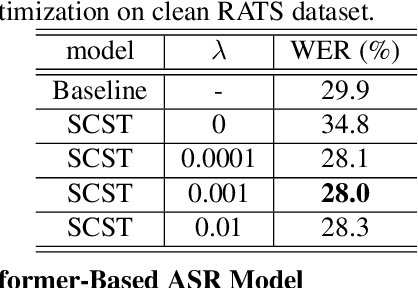
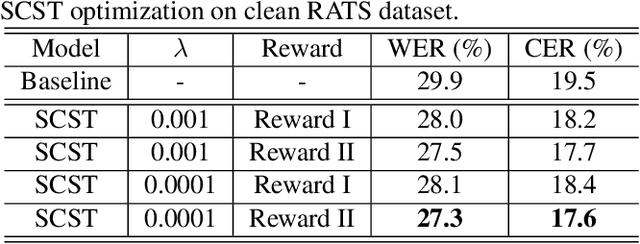
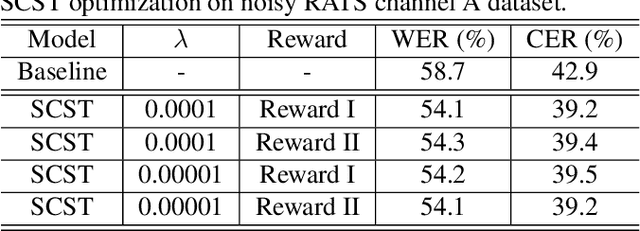
Although automatic speech recognition (ASR) task has gained remarkable success by sequence-to-sequence models, there are two main mismatches between its training and testing that might lead to performance degradation: 1) The typically used cross-entropy criterion aims to maximize log-likelihood of the training data, while the performance is evaluated by word error rate (WER), not log-likelihood; 2) The teacher-forcing method leads to the dependence on ground truth during training, which means that model has never been exposed to its own prediction before testing. In this paper, we propose an optimization method called self-critical sequence training (SCST) to make the training procedure much closer to the testing phase. As a reinforcement learning (RL) based method, SCST utilizes a customized reward function to associate the training criterion and WER. Furthermore, it removes the reliance on teacher-forcing and harmonizes the model with respect to its inference procedure. We conducted experiments on both clean and noisy speech datasets, and the results show that the proposed SCST respectively achieves 8.7% and 7.8% relative improvements over the baseline in terms of WER.
Interactive Audio-text Representation for Automated Audio Captioning with Contrastive Learning
Apr 12, 2022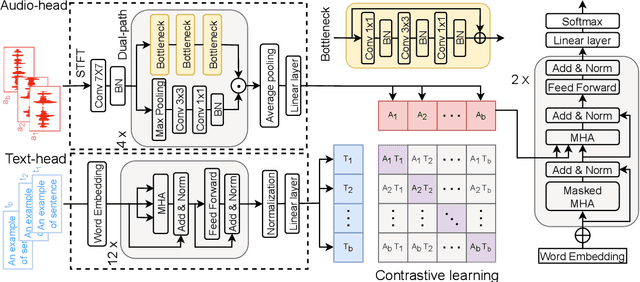

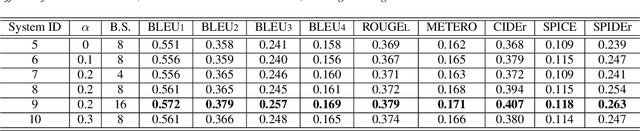
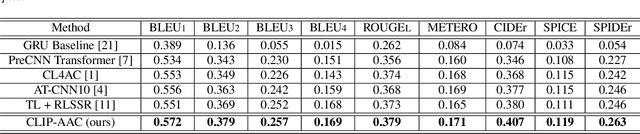
Automated Audio captioning (AAC) is a cross-modal task that generates natural language to describe the content of input audio. Most prior works usually extract single-modality acoustic features and are therefore sub-optimal for the cross-modal decoding task. In this work, we propose a novel AAC system called CLIP-AAC to learn interactive cross-modality representation with both acoustic and textual information. Specifically, the proposed CLIP-AAC introduces an audio-head and a text-head in the pre-trained encoder to extract audio-text information. Furthermore, we also apply contrastive learning to narrow the domain difference by learning the correspondence between the audio signal and its paired captions. Experimental results show that the proposed CLIP-AAC approach surpasses the best baseline by a significant margin on the Clotho dataset in terms of NLP evaluation metrics. The ablation study indicates that both the pre-trained model and contrastive learning contribute to the performance gain of the AAC model.
Multimodal Transformer for Nursing Activity Recognition
Apr 09, 2022
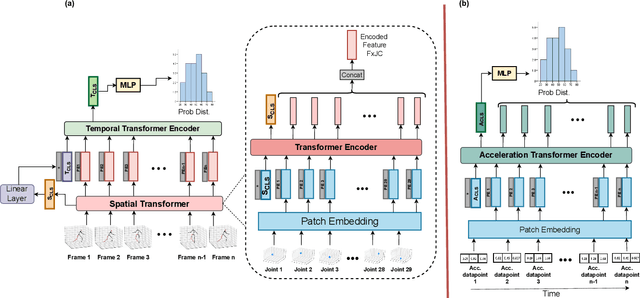
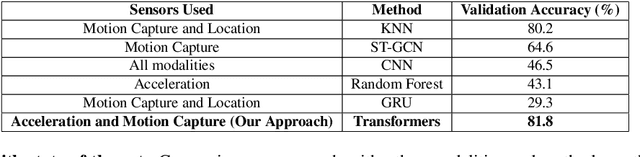
In an aging population, elderly patient safety is a primary concern at hospitals and nursing homes, which demands for increased nurse care. By performing nurse activity recognition, we can not only make sure that all patients get an equal desired care, but it can also free nurses from manual documentation of activities they perform, leading to a fair and safe place of care for the elderly. In this work, we present a multimodal transformer-based network, which extracts features from skeletal joints and acceleration data, and fuses them to perform nurse activity recognition. Our method achieves state-of-the-art performance of 81.8% accuracy on the benchmark dataset available for nurse activity recognition from the Nurse Care Activity Recognition Challenge. We perform ablation studies to show that our fusion model is better than single modality transformer variants (using only acceleration or skeleton joints data). Our solution also outperforms state-of-the-art ST-GCN, GRU and other classical hand-crafted-feature-based classifier solutions by a margin of 1.6%, on the NCRC dataset. Code is available at \url{https://github.com/Momilijaz96/MMT_for_NCRC}.
Attention guided global enhancement and local refinement network for semantic segmentation
Apr 09, 2022
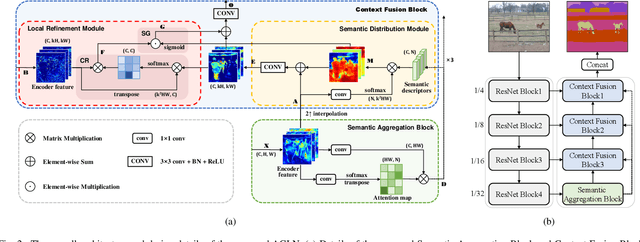
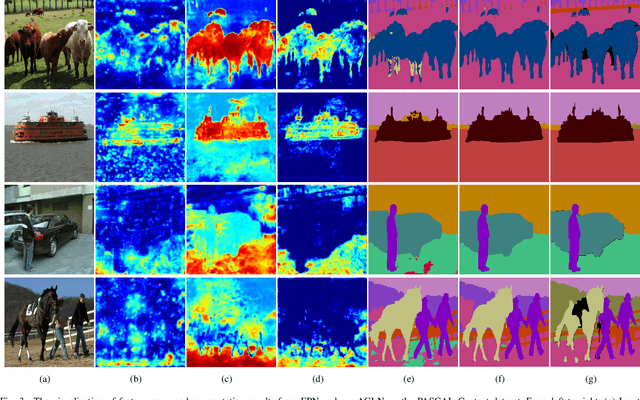
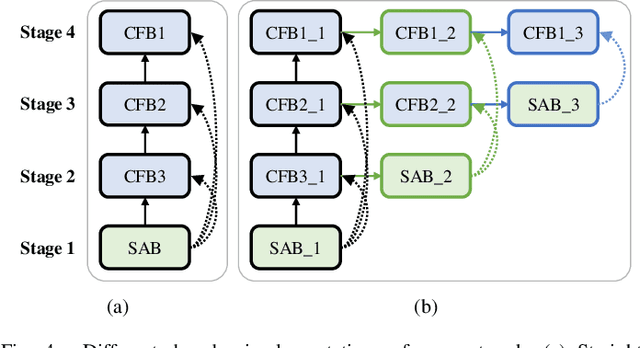
The encoder-decoder architecture is widely used as a lightweight semantic segmentation network. However, it struggles with a limited performance compared to a well-designed Dilated-FCN model for two major problems. First, commonly used upsampling methods in the decoder such as interpolation and deconvolution suffer from a local receptive field, unable to encode global contexts. Second, low-level features may bring noises to the network decoder through skip connections for the inadequacy of semantic concepts in early encoder layers. To tackle these challenges, a Global Enhancement Method is proposed to aggregate global information from high-level feature maps and adaptively distribute them to different decoder layers, alleviating the shortage of global contexts in the upsampling process. Besides, a Local Refinement Module is developed by utilizing the decoder features as the semantic guidance to refine the noisy encoder features before the fusion of these two (the decoder features and the encoder features). Then, the two methods are integrated into a Context Fusion Block, and based on that, a novel Attention guided Global enhancement and Local refinement Network (AGLN) is elaborately designed. Extensive experiments on PASCAL Context, ADE20K, and PASCAL VOC 2012 datasets have demonstrated the effectiveness of the proposed approach. In particular, with a vanilla ResNet-101 backbone, AGLN achieves the state-of-the-art result (56.23% mean IoU) on the PASCAL Context dataset. The code is available at https://github.com/zhasen1996/AGLN.