 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChen Change Loy
TSIT: A Simple and Versatile Framework for Image-to-Image Translation
Jul 25, 2020

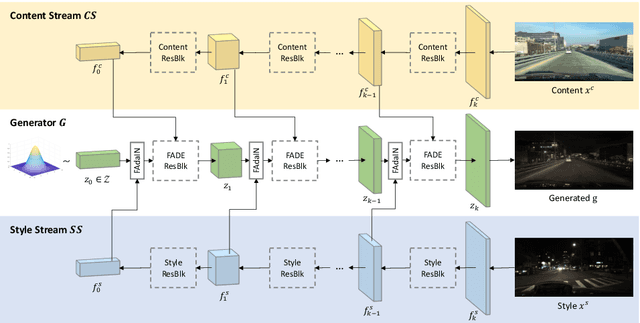
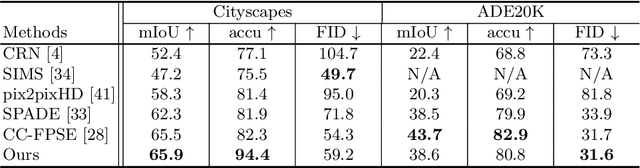
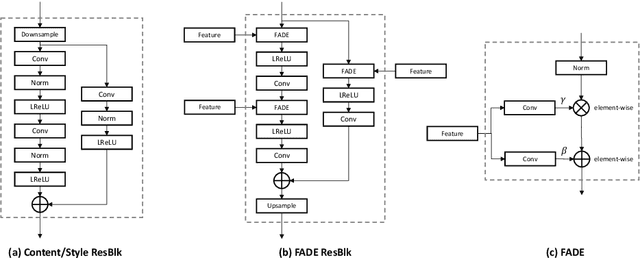
We introduce a simple and versatile framework for image-to-image translation. We unearth the importance of normalization layers, and provide a carefully designed two-stream generative model with newly proposed feature transformations in a coarse-to-fine fashion. This allows multi-scale semantic structure information and style representation to be effectively captured and fused by the network, permitting our method to scale to various tasks in both unsupervised and supervised settings. No additional constraints (e.g., cycle consistency) are needed, contributing to a very clean and simple method. Multi-modal image synthesis with arbitrary style control is made possible. A systematic study compares the proposed method with several state-of-the-art task-specific baselines, verifying its effectiveness in both perceptual quality and quantitative evaluations.
LiteFlowNet3: Resolving Correspondence Ambiguity for More Accurate Optical Flow Estimation
Jul 18, 2020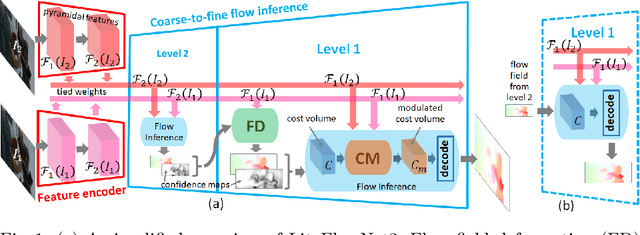
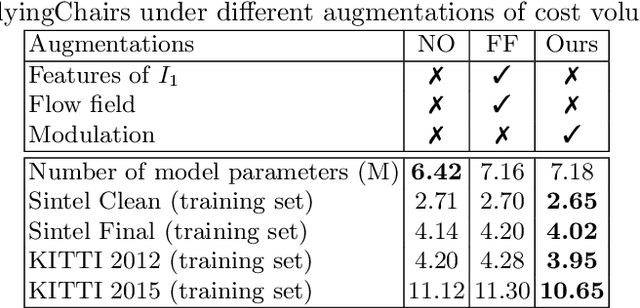
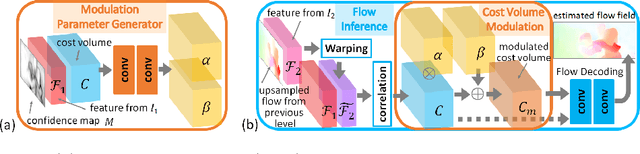
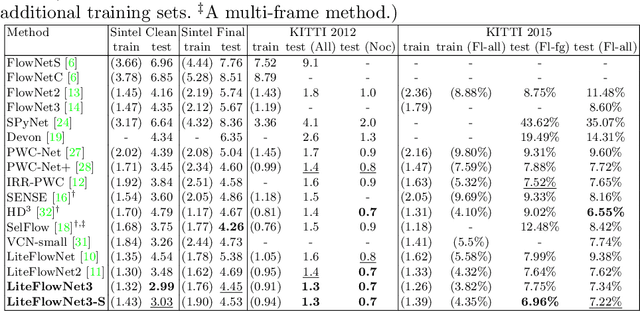
Deep learning approaches have achieved great success in addressing the problem of optical flow estimation. The keys to success lie in the use of cost volume and coarse-to-fine flow inference. However, the matching problem becomes ill-posed when partially occluded or homogeneous regions exist in images. This causes a cost volume to contain outliers and affects the flow decoding from it. Besides, the coarse-to-fine flow inference demands an accurate flow initialization. Ambiguous correspondence yields erroneous flow fields and affects the flow inferences in subsequent levels. In this paper, we introduce LiteFlowNet3, a deep network consisting of two specialized modules, to address the above challenges. (1) We ameliorate the issue of outliers in the cost volume by amending each cost vector through an adaptive modulation prior to the flow decoding. (2) We further improve the flow accuracy by exploring local flow consistency. To this end, each inaccurate optical flow is replaced with an accurate one from a nearby position through a novel warping of the flow field. LiteFlowNet3 not only achieves promising results on public benchmarks but also has a small model size and a fast runtime.
RGB-D Salient Object Detection with Cross-Modality Modulation and Selection
Jul 14, 2020
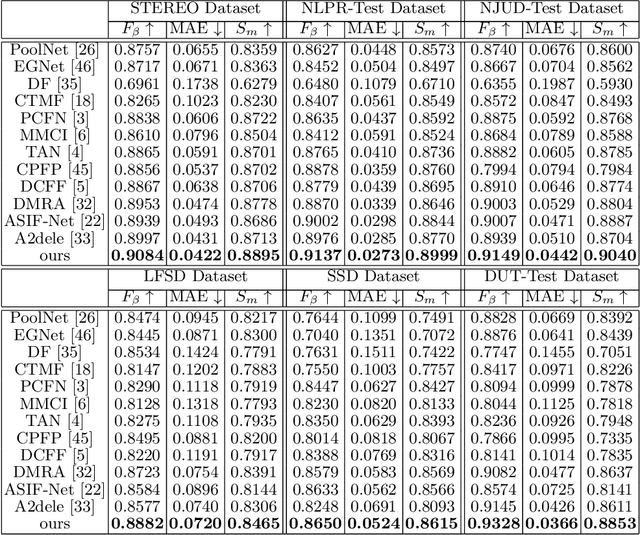
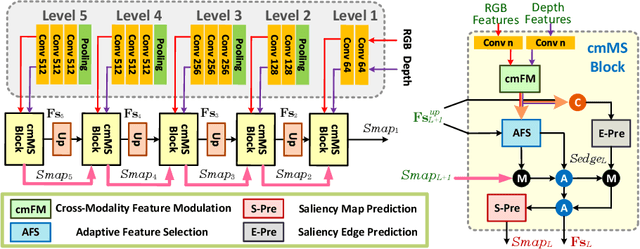
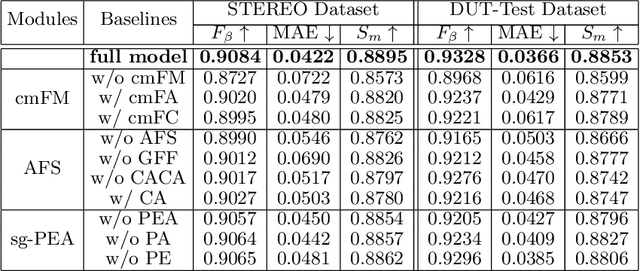
We present an effective method to progressively integrate and refine the cross-modality complementarities for RGB-D salient object detection (SOD). The proposed network mainly solves two challenging issues: 1) how to effectively integrate the complementary information from RGB image and its corresponding depth map, and 2) how to adaptively select more saliency-related features. First, we propose a cross-modality feature modulation (cmFM) module to enhance feature representations by taking the depth features as prior, which models the complementary relations of RGB-D data. Second, we propose an adaptive feature selection (AFS) module to select saliency-related features and suppress the inferior ones. The AFS module exploits multi-modality spatial feature fusion with the self-modality and cross-modality interdependencies of channel features are considered. Third, we employ a saliency-guided position-edge attention (sg-PEA) module to encourage our network to focus more on saliency-related regions. The above modules as a whole, called cmMS block, facilitates the refinement of saliency features in a coarse-to-fine fashion. Coupled with a bottom-up inference, the refined saliency features enable accurate and edge-preserving SOD. Extensive experiments demonstrate that our network outperforms state-of-the-art saliency detectors on six popular RGB-D SOD benchmarks.
Knowledge Distillation Meets Self-Supervision
Jul 13, 2020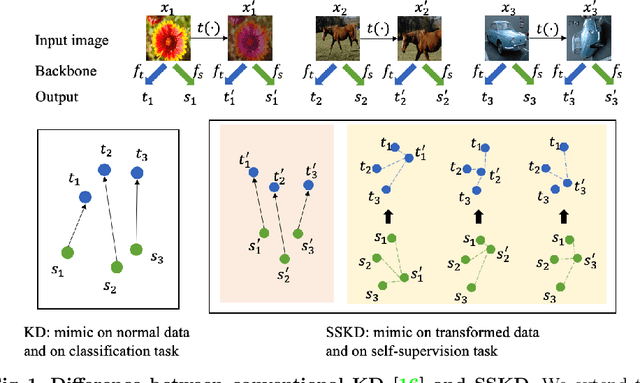

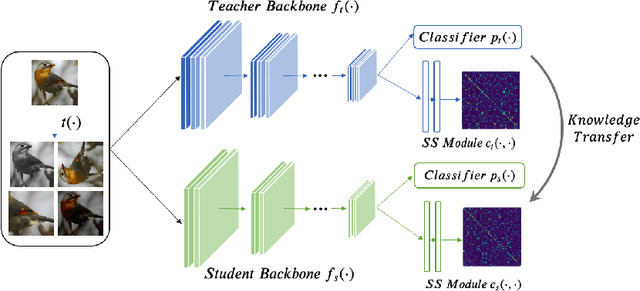

Knowledge distillation, which involves extracting the "dark knowledge" from a teacher network to guide the learning of a student network, has emerged as an important technique for model compression and transfer learning. Unlike previous works that exploit architecture-specific cues such as activation and attention for distillation, here we wish to explore a more general and model-agnostic approach for extracting "richer dark knowledge" from the pre-trained teacher model. We show that the seemingly different self-supervision task can serve as a simple yet powerful solution. For example, when performing contrastive learning between transformed entities, the noisy predictions of the teacher network reflect its intrinsic composition of semantic and pose information. By exploiting the similarity between those self-supervision signals as an auxiliary task, one can effectively transfer the hidden information from the teacher to the student. In this paper, we discuss practical ways to exploit those noisy self-supervision signals with selective transfer for distillation. We further show that self-supervision signals improve conventional distillation with substantial gains under few-shot and noisy-label scenarios. Given the richer knowledge mined from self-supervision, our knowledge distillation approach achieves state-of-the-art performance on standard benchmarks, i.e., CIFAR100 and ImageNet, under both similar-architecture and cross-architecture settings. The advantage is even more pronounced under the cross-architecture setting, where our method outperforms the state of the art CRD by an average of 2.3% in accuracy rate on CIFAR100 across six different teacher-student pairs.
Cross-Scale Internal Graph Neural Network for Image Super-Resolution
Jun 30, 2020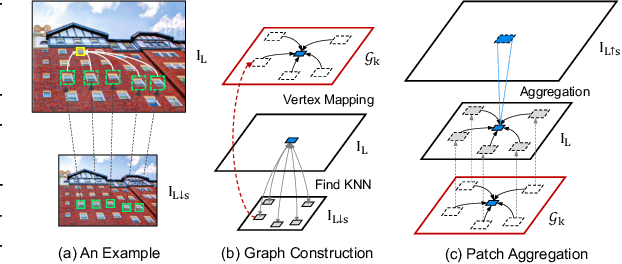
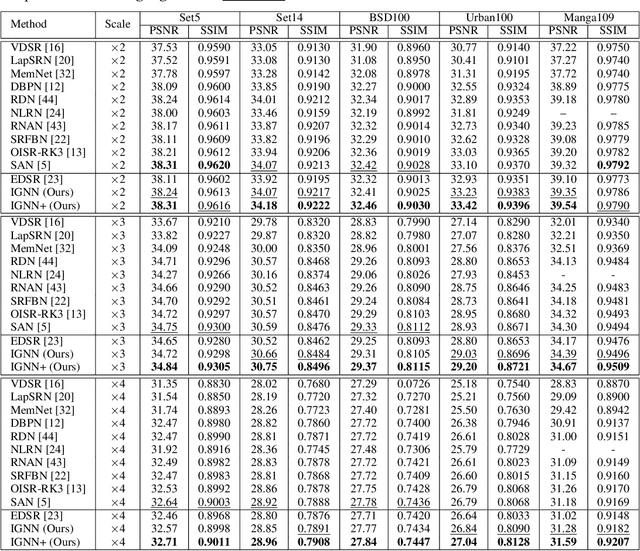
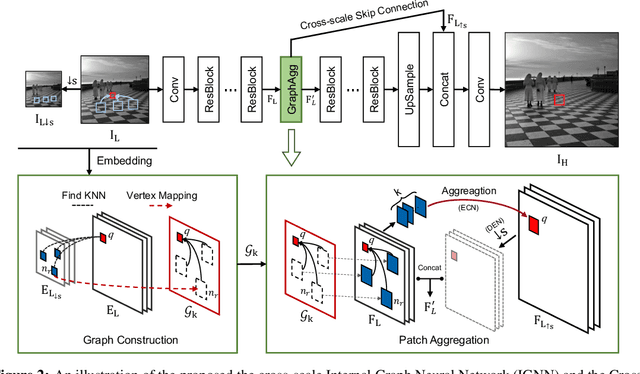

Non-local self-similarity in natural images has been well studied as an effective prior in image restoration. However, for single image super-resolution (SISR), most existing deep non-local methods (e.g., non-local neural networks) only exploit similar patches within the same scale of the low-resolution (LR) input image. Consequently, the restoration is limited to using the same-scale information while neglecting potential high-resolution (HR) cues from other scales. In this paper, we explore the cross-scale patch recurrence property of a natural image, i.e., similar patches tend to recur many times across different scales. This is achieved using a novel cross-scale internal graph neural network (IGNN). Specifically, we dynamically construct a cross-scale graph by searching k-nearest neighboring patches in the downsampled LR image for each query patch in the LR image. We then obtain the corresponding k HR neighboring patches in the LR image and aggregate them adaptively in accordance to the edge label of the constructed graph. In this way, the HR information can be passed from k HR neighboring patches to the LR query patch to help it recover more detailed textures. Besides, these internal image-specific LR/HR exemplars are also significant complements to the external information learned from the training dataset. Extensive experiments demonstrate the effectiveness of IGNN against the state-of-the-art SISR methods including existing non-local networks on standard benchmarks.
Online Deep Clustering for Unsupervised Representation Learning
Jun 18, 2020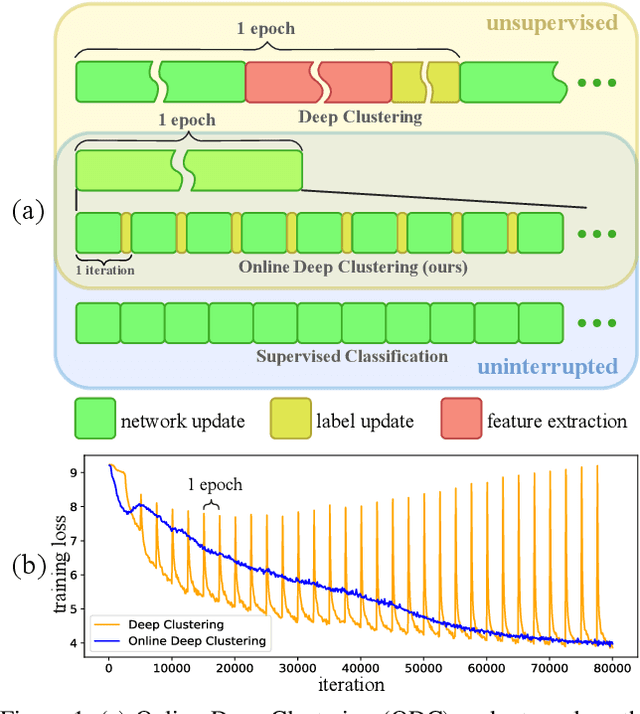
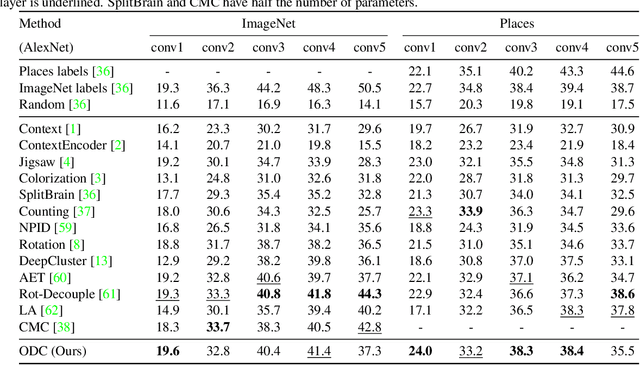
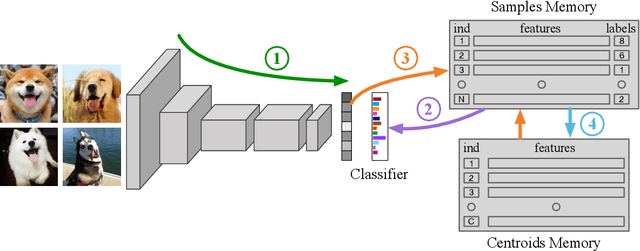
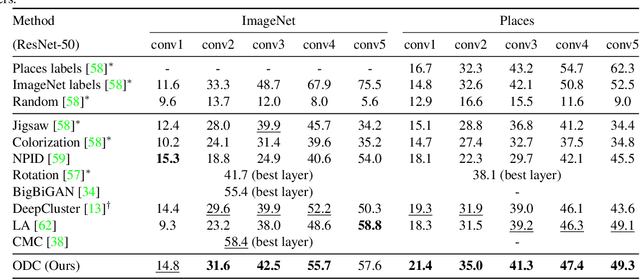
Joint clustering and feature learning methods have shown remarkable performance in unsupervised representation learning. However, the training schedule alternating between feature clustering and network parameters update leads to unstable learning of visual representations. To overcome this challenge, we propose Online Deep Clustering (ODC) that performs clustering and network update simultaneously rather than alternatingly. Our key insight is that the cluster centroids should evolve steadily in keeping the classifier stably updated. Specifically, we design and maintain two dynamic memory modules, i.e., samples memory to store samples labels and features, and centroids memory for centroids evolution. We break down the abrupt global clustering into steady memory update and batch-wise label re-assignment. The process is integrated into network update iterations. In this way, labels and the network evolve shoulder-to-shoulder rather than alternatingly. Extensive experiments demonstrate that ODC stabilizes the training process and boosts the performance effectively. Code: https://github.com/open-mmlab/OpenSelfSup.
Inter-Region Affinity Distillation for Road Marking Segmentation
Apr 11, 2020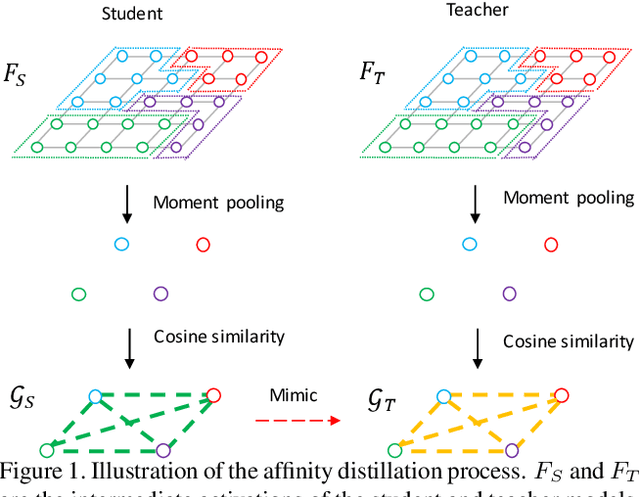
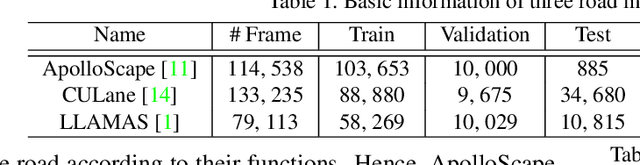
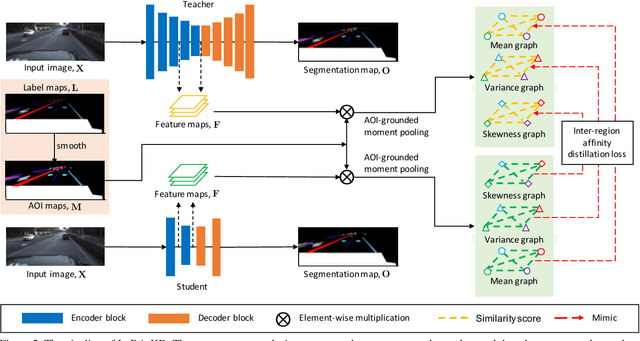
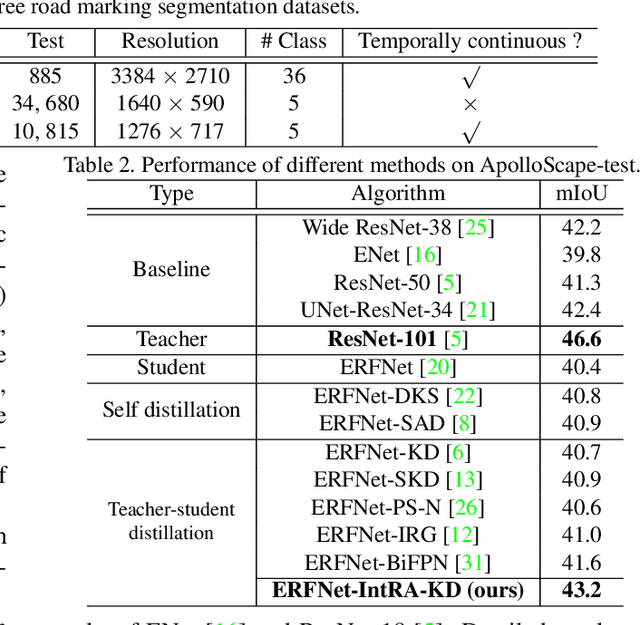
We study the problem of distilling knowledge from a large deep teacher network to a much smaller student network for the task of road marking segmentation. In this work, we explore a novel knowledge distillation (KD) approach that can transfer 'knowledge' on scene structure more effectively from a teacher to a student model. Our method is known as Inter-Region Affinity KD (IntRA-KD). It decomposes a given road scene image into different regions and represents each region as a node in a graph. An inter-region affinity graph is then formed by establishing pairwise relationships between nodes based on their similarity in feature distribution. To learn structural knowledge from the teacher network, the student is required to match the graph generated by the teacher. The proposed method shows promising results on three large-scale road marking segmentation benchmarks, i.e., ApolloScape, CULane and LLAMAS, by taking various lightweight models as students and ResNet-101 as the teacher. IntRA-KD consistently brings higher performance gains on all lightweight models, compared to previous distillation methods. Our code is available at https://github.com/cardwing/Codes-for-IntRA-KD.
Feature Pyramid Grids
Apr 07, 2020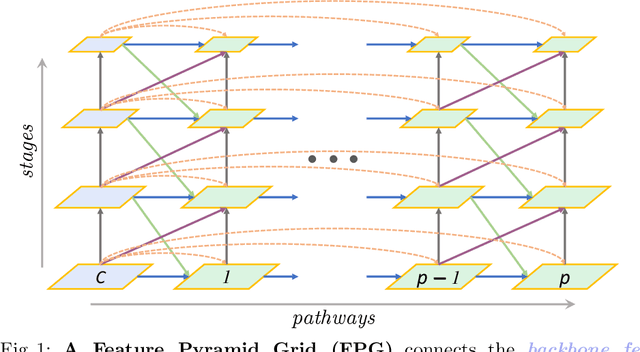
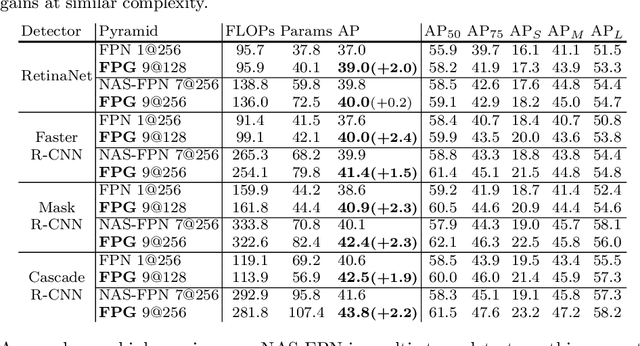
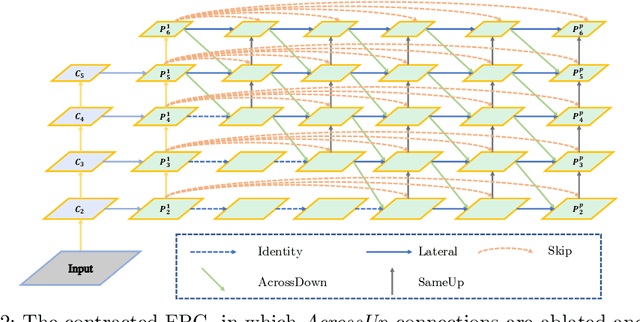
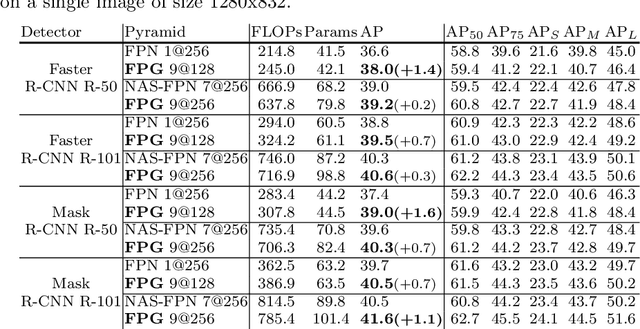
Feature pyramid networks have been widely adopted in the object detection literature to improve feature representations for better handling of variations in scale. In this paper, we present Feature Pyramid Grids (FPG), a deep multi-pathway feature pyramid, that represents the feature scale-space as a regular grid of parallel bottom-up pathways which are fused by multi-directional lateral connections. FPG can improve single-pathway feature pyramid networks by significantly increasing its performance at similar computation cost, highlighting importance of deep pyramid representations. In addition to its general and uniform structure, over complicated structures that have been found with neural architecture search, it also compares favorably against such approaches without relying on search. We hope that FPG with its uniform and effective nature can serve as a strong component for future work in object recognition.