 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChen Change Loy
Video K-Net: A Simple, Strong, and Unified Baseline for Video Segmentation
Apr 10, 2022
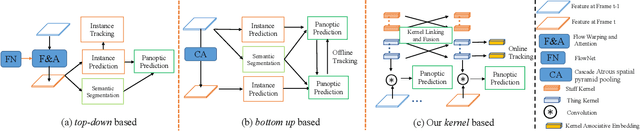

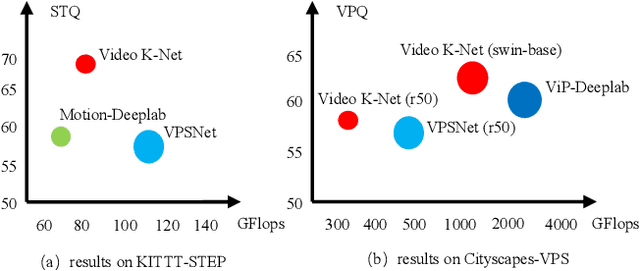
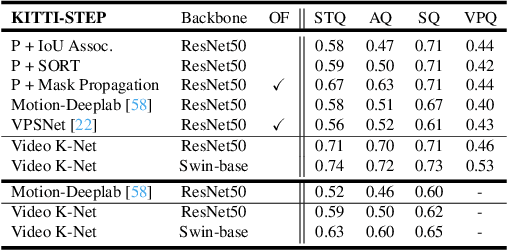
This paper presents Video K-Net, a simple, strong, and unified framework for fully end-to-end video panoptic segmentation. The method is built upon K-Net, a method that unifies image segmentation via a group of learnable kernels. We observe that these learnable kernels from K-Net, which encode object appearances and contexts, can naturally associate identical instances across video frames. Motivated by this observation, Video K-Net learns to simultaneously segment and track "things" and "stuff" in a video with simple kernel-based appearance modeling and cross-temporal kernel interaction. Despite the simplicity, it achieves state-of-the-art video panoptic segmentation results on Citscapes-VPS and KITTI-STEP without bells and whistles. In particular on KITTI-STEP, the simple method can boost almost 12\% relative improvements over previous methods. We also validate its generalization on video semantic segmentation, where we boost various baselines by 2\% on the VSPW dataset. Moreover, we extend K-Net into clip-level video framework for video instance segmentation where we obtain 40.5\% for ResNet50 backbone and 51.5\% mAP for Swin-base on YouTube-2019 validation set. We hope this simple yet effective method can serve as a new flexible baseline in video segmentation. Both code and models are released at https://github.com/lxtGH/Video-K-Net
Unsupervised Image-to-Image Translation with Generative Prior
Apr 07, 2022

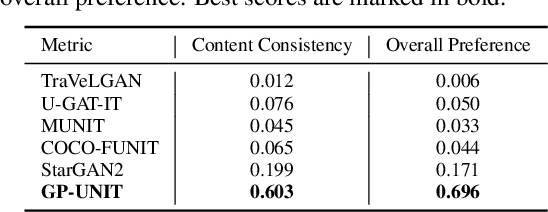

Unsupervised image-to-image translation aims to learn the translation between two visual domains without paired data. Despite the recent progress in image translation models, it remains challenging to build mappings between complex domains with drastic visual discrepancies. In this work, we present a novel framework, Generative Prior-guided UNsupervised Image-to-image Translation (GP-UNIT), to improve the overall quality and applicability of the translation algorithm. Our key insight is to leverage the generative prior from pre-trained class-conditional GANs (e.g., BigGAN) to learn rich content correspondences across various domains. We propose a novel coarse-to-fine scheme: we first distill the generative prior to capture a robust coarse-level content representation that can link objects at an abstract semantic level, based on which fine-level content features are adaptively learned for more accurate multi-level content correspondences. Extensive experiments demonstrate the superiority of our versatile framework over state-of-the-art methods in robust, high-quality and diversified translations, even for challenging and distant domains.
TransEditor: Transformer-Based Dual-Space GAN for Highly Controllable Facial Editing
Mar 31, 2022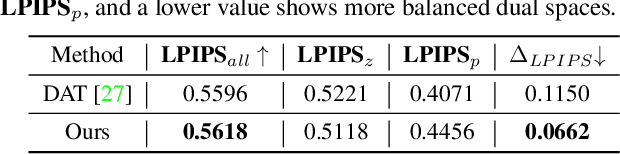
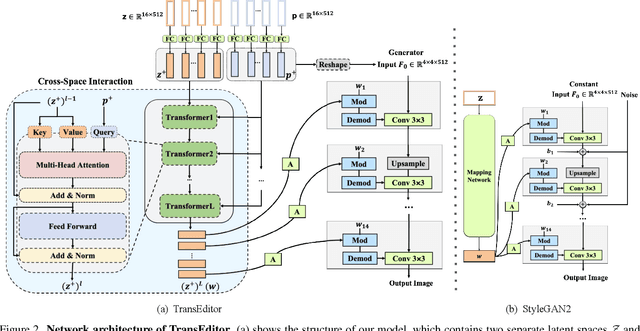

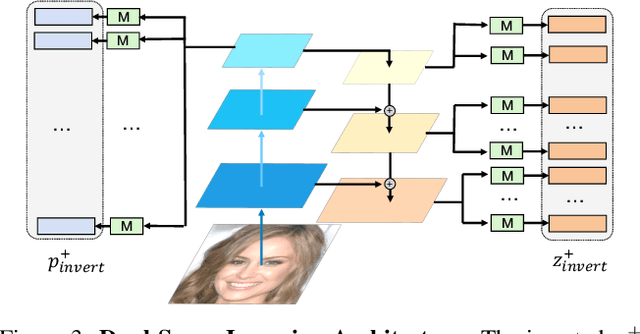
Recent advances like StyleGAN have promoted the growth of controllable facial editing. To address its core challenge of attribute decoupling in a single latent space, attempts have been made to adopt dual-space GAN for better disentanglement of style and content representations. Nonetheless, these methods are still incompetent to obtain plausible editing results with high controllability, especially for complicated attributes. In this study, we highlight the importance of interaction in a dual-space GAN for more controllable editing. We propose TransEditor, a novel Transformer-based framework to enhance such interaction. Besides, we develop a new dual-space editing and inversion strategy to provide additional editing flexibility. Extensive experiments demonstrate the superiority of the proposed framework in image quality and editing capability, suggesting the effectiveness of TransEditor for highly controllable facial editing.
Bailando: 3D Dance Generation by Actor-Critic GPT with Choreographic Memory
Mar 25, 2022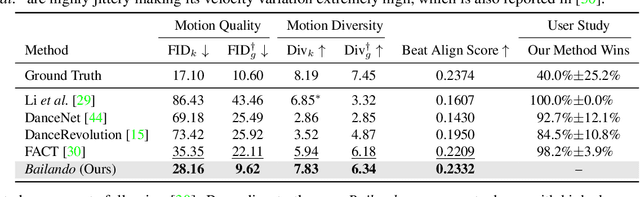
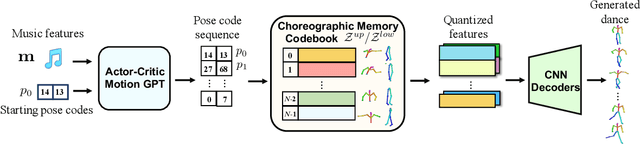
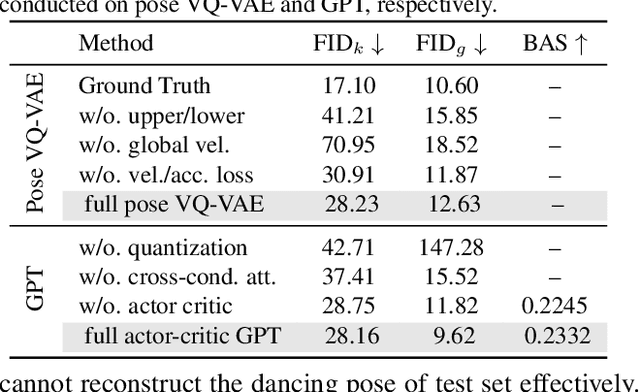
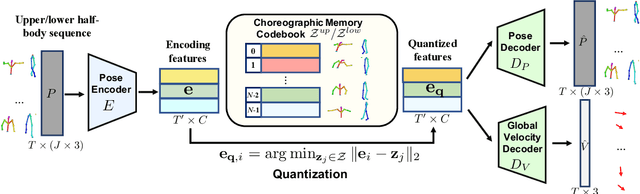
Driving 3D characters to dance following a piece of music is highly challenging due to the spatial constraints applied to poses by choreography norms. In addition, the generated dance sequence also needs to maintain temporal coherency with different music genres. To tackle these challenges, we propose a novel music-to-dance framework, Bailando, with two powerful components: 1) a choreographic memory that learns to summarize meaningful dancing units from 3D pose sequence to a quantized codebook, 2) an actor-critic Generative Pre-trained Transformer (GPT) that composes these units to a fluent dance coherent to the music. With the learned choreographic memory, dance generation is realized on the quantized units that meet high choreography standards, such that the generated dancing sequences are confined within the spatial constraints. To achieve synchronized alignment between diverse motion tempos and music beats, we introduce an actor-critic-based reinforcement learning scheme to the GPT with a newly-designed beat-align reward function. Extensive experiments on the standard benchmark demonstrate that our proposed framework achieves state-of-the-art performance both qualitatively and quantitatively. Notably, the learned choreographic memory is shown to discover human-interpretable dancing-style poses in an unsupervised manner.
Pastiche Master: Exemplar-Based High-Resolution Portrait Style Transfer
Mar 24, 2022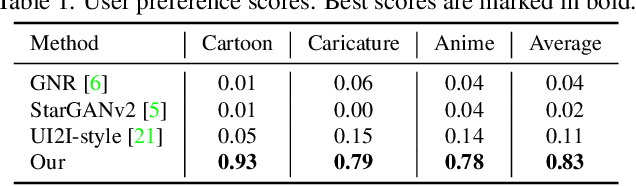
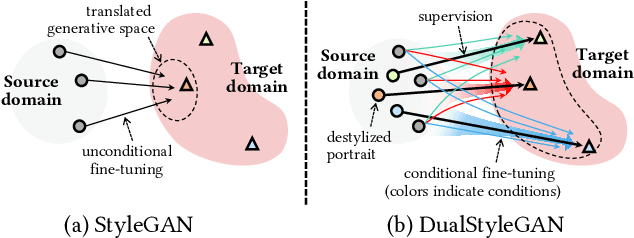
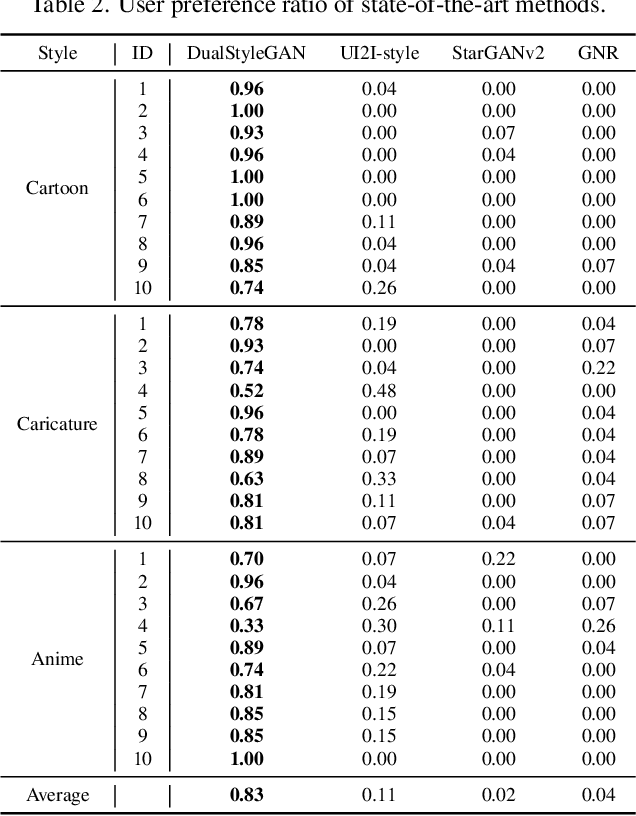

Recent studies on StyleGAN show high performance on artistic portrait generation by transfer learning with limited data. In this paper, we explore more challenging exemplar-based high-resolution portrait style transfer by introducing a novel DualStyleGAN with flexible control of dual styles of the original face domain and the extended artistic portrait domain. Different from StyleGAN, DualStyleGAN provides a natural way of style transfer by characterizing the content and style of a portrait with an intrinsic style path and a new extrinsic style path, respectively. The delicately designed extrinsic style path enables our model to modulate both the color and complex structural styles hierarchically to precisely pastiche the style example. Furthermore, a novel progressive fine-tuning scheme is introduced to smoothly transform the generative space of the model to the target domain, even with the above modifications on the network architecture. Experiments demonstrate the superiority of DualStyleGAN over state-of-the-art methods in high-quality portrait style transfer and flexible style control.
Open-Vocabulary DETR with Conditional Matching
Mar 22, 2022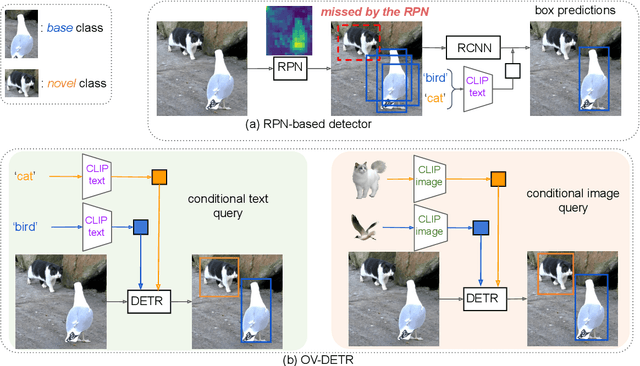
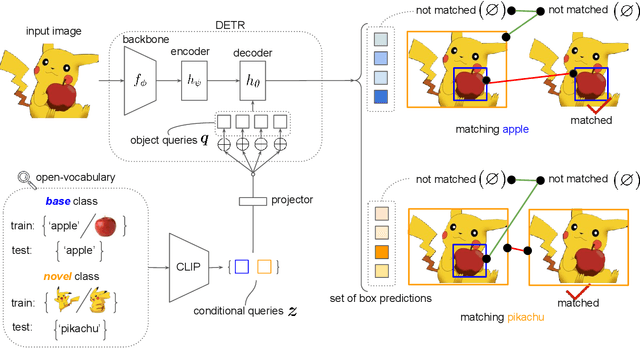
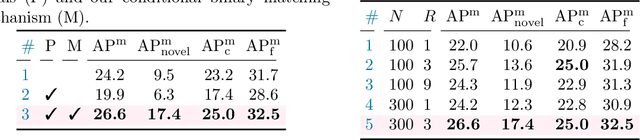
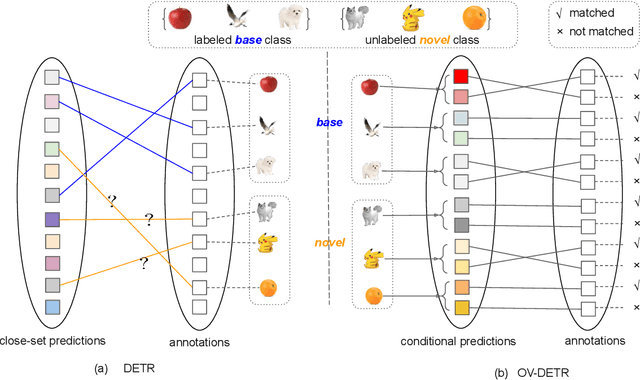
Open-vocabulary object detection, which is concerned with the problem of detecting novel objects guided by natural language, has gained increasing attention from the community. Ideally, we would like to extend an open-vocabulary detector such that it can produce bounding box predictions based on user inputs in form of either natural language or exemplar image. This offers great flexibility and user experience for human-computer interaction. To this end, we propose a novel open-vocabulary detector based on DETR -- hence the name OV-DETR -- which, once trained, can detect any object given its class name or an exemplar image. The biggest challenge of turning DETR into an open-vocabulary detector is that it is impossible to calculate the classification cost matrix of novel classes without access to their labeled images. To overcome this challenge, we formulate the learning objective as a binary matching one between input queries (class name or exemplar image) and the corresponding objects, which learns useful correspondence to generalize to unseen queries during testing. For training, we choose to condition the Transformer decoder on the input embeddings obtained from a pre-trained vision-language model like CLIP, in order to enable matching for both text and image queries. With extensive experiments on LVIS and COCO datasets, we demonstrate that our OV-DETR -- the first end-to-end Transformer-based open-vocabulary detector -- achieves non-trivial improvements over current state of the arts.
Dense Siamese Network
Mar 21, 2022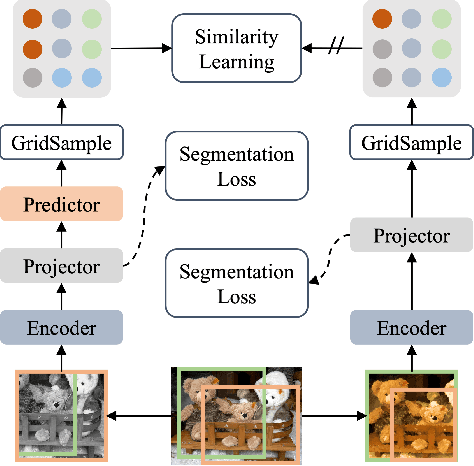
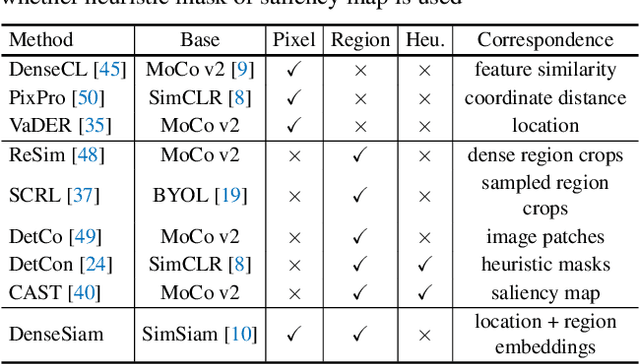
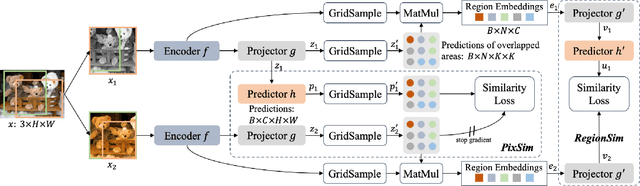
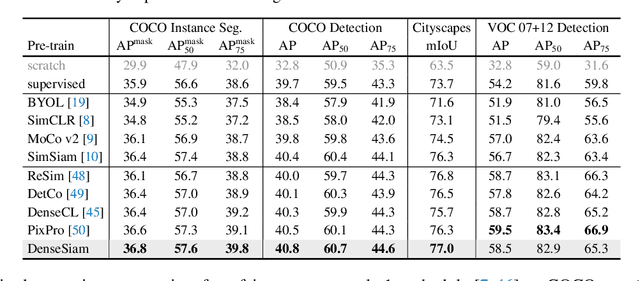
This paper presents Dense Siamese Network (DenseSiam), a simple unsupervised learning framework for dense prediction tasks. It learns visual representations by maximizing the similarity between two views of one image with two types of consistency, i.e., pixel consistency and region consistency. Concretely, DenseSiam first maximizes the pixel level spatial consistency according to the exact location correspondence in the overlapped area. It also extracts a batch of region embeddings that correspond to some sub-regions in the overlapped area to be contrasted for region consistency. In contrast to previous methods that require negative pixel pairs, momentum encoders, or heuristic masks, DenseSiam benefits from the simple Siamese network and optimizes the consistency of different granularities. It also proves that the simple location correspondence and interacted region embeddings are effective enough to learn the similarity. We apply DenseSiam on ImageNet and obtain competitive improvements on various downstream tasks. We also show that only with some extra task-specific losses, the simple framework can directly conduct dense prediction tasks. On an existing unsupervised semantic segmentation benchmark, it surpasses state-of-the-art segmentation methods by 2.1 mIoU with 28% training costs.
Conditional Prompt Learning for Vision-Language Models
Mar 10, 2022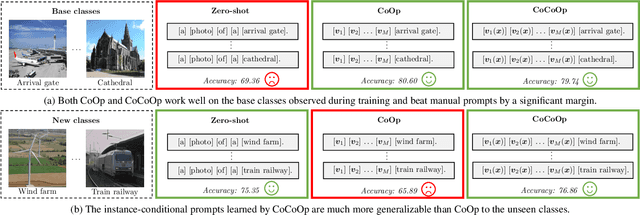
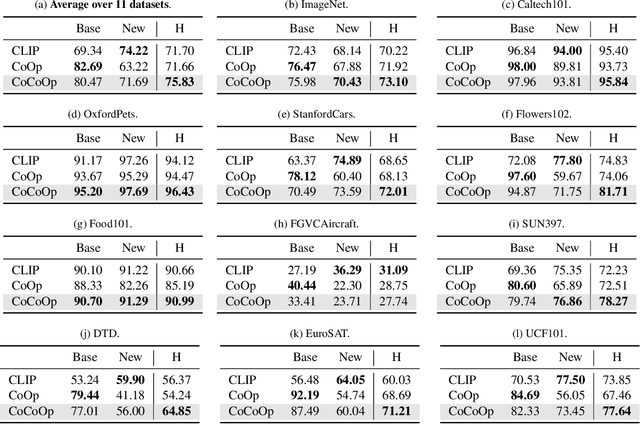
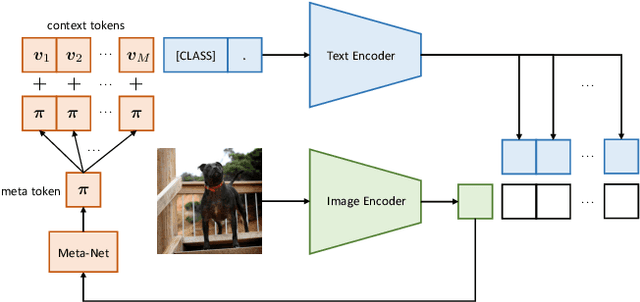
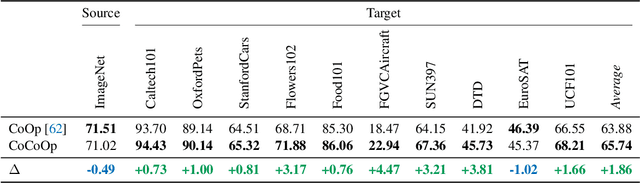
With the rise of powerful pre-trained vision-language models like CLIP, it becomes essential to investigate ways to adapt these models to downstream datasets. A recently proposed method named Context Optimization (CoOp) introduces the concept of prompt learning -- a recent trend in NLP -- to the vision domain for adapting pre-trained vision-language models. Specifically, CoOp turns context words in a prompt into a set of learnable vectors and, with only a few labeled images for learning, can achieve huge improvements over intensively-tuned manual prompts. In our study we identify a critical problem of CoOp: the learned context is not generalizable to wider unseen classes within the same dataset, suggesting that CoOp overfits base classes observed during training. To address the problem, we propose Conditional Context Optimization (CoCoOp), which extends CoOp by further learning a lightweight neural network to generate for each image an input-conditional token (vector). Compared to CoOp's static prompts, our dynamic prompts adapt to each instance and are thus less sensitive to class shift. Extensive experiments show that CoCoOp generalizes much better than CoOp to unseen classes, even showing promising transferability beyond a single dataset; and yields stronger domain generalization performance as well. Code is available at https://github.com/KaiyangZhou/CoOp.
LEDNet: Joint Low-light Enhancement and Deblurring in the Dark
Feb 07, 2022

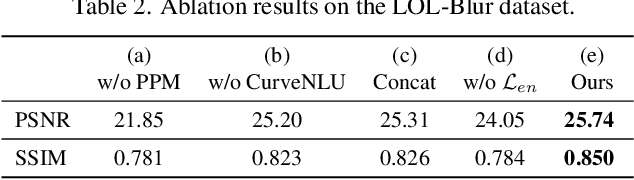
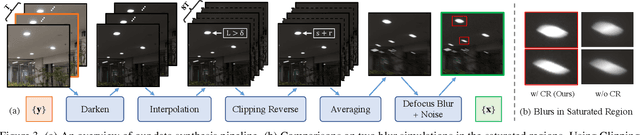
Night photography typically suffers from both low light and blurring issues due to the dim environment and the common use of long exposure. While existing light enhancement and deblurring methods could deal with each problem individually, a cascade of such methods cannot work harmoniously to cope well with joint degradation of visibility and textures. Training an end-to-end network is also infeasible as no paired data is available to characterize the coexistence of low light and blurs. We address the problem by introducing a novel data synthesis pipeline that models realistic low-light blurring degradations. With the pipeline, we present the first large-scale dataset for joint low-light enhancement and deblurring. The dataset, LOL-Blur, contains 12,000 low-blur/normal-sharp pairs with diverse darkness and motion blurs in different scenarios. We further present an effective network, named LEDNet, to perform joint low-light enhancement and deblurring. Our network is unique as it is specially designed to consider the synergy between the two inter-connected tasks. Both the proposed dataset and network provide a foundation for this challenging joint task. Extensive experiments demonstrate the effectiveness of our method on both synthetic and real-world datasets.
MoCaNet: Motion Retargeting in-the-wild via Canonicalization Networks
Dec 21, 2021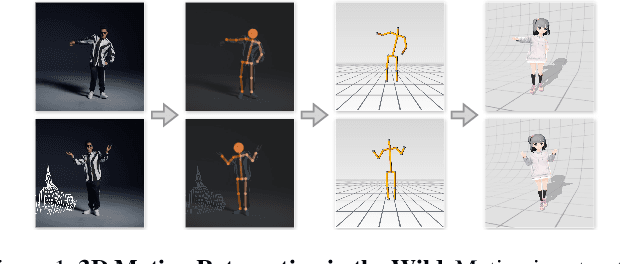

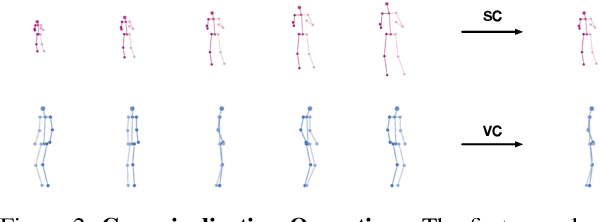

We present a novel framework that brings the 3D motion retargeting task from controlled environments to in-the-wild scenarios. In particular, our method is capable of retargeting body motion from a character in a 2D monocular video to a 3D character without using any motion capture system or 3D reconstruction procedure. It is designed to leverage massive online videos for unsupervised training, needless of 3D annotations or motion-body pairing information. The proposed method is built upon two novel canonicalization operations, structure canonicalization and view canonicalization. Trained with the canonicalization operations and the derived regularizations, our method learns to factorize a skeleton sequence into three independent semantic subspaces, i.e., motion, structure, and view angle. The disentangled representation enables motion retargeting from 2D to 3D with high precision. Our method achieves superior performance on motion transfer benchmarks with large body variations and challenging actions. Notably, the canonicalized skeleton sequence could serve as a disentangled and interpretable representation of human motion that benefits action analysis and motion retrieval.