 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Estimation for Large Displacements and Deformations
Jun 24, 2022
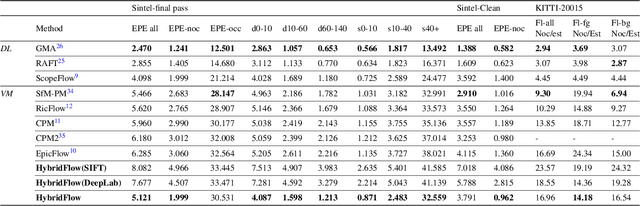


Large displacement optical flow is an integral part of many computer vision tasks. Variational optical flow techniques based on a coarse-to-fine scheme interpolate sparse matches and locally optimize an energy model conditioned on colour, gradient and smoothness, making them sensitive to noise in the sparse matches, deformations, and arbitrarily large displacements. This paper addresses this problem and presents HybridFlow, a variational motion estimation framework for large displacements and deformations. A multi-scale hybrid matching approach is performed on the image pairs. Coarse-scale clusters formed by classifying pixels according to their feature descriptors are matched using the clusters' context descriptors. We apply a multi-scale graph matching on the finer-scale superpixels contained within each matched pair of coarse-scale clusters. Small clusters that cannot be further subdivided are matched using localized feature matching. Together, these initial matches form the flow, which is propagated by an edge-preserving interpolation and variational refinement. Our approach does not require training and is robust to substantial displacements and rigid and non-rigid transformations due to motion in the scene, making it ideal for large-scale imagery such as Wide-Area Motion Imagery (WAMI). More notably, HybridFlow works on directed graphs of arbitrary topology representing perceptual groups, which improves motion estimation in the presence of significant deformations. We demonstrate HybridFlow's superior performance to state-of-the-art variational techniques on two benchmark datasets and report comparable results with state-of-the-art deep-learning-based techniques.
Predicting Human Performance in Vertical Hierarchical Menu Selection in Immersive AR Using Hand-gesture and Head-gaze
Jun 19, 2022
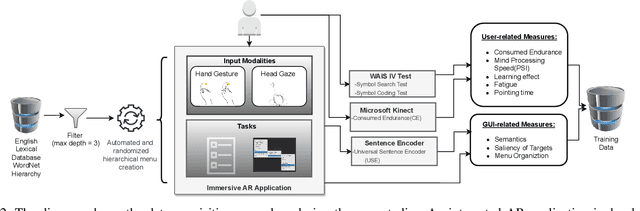

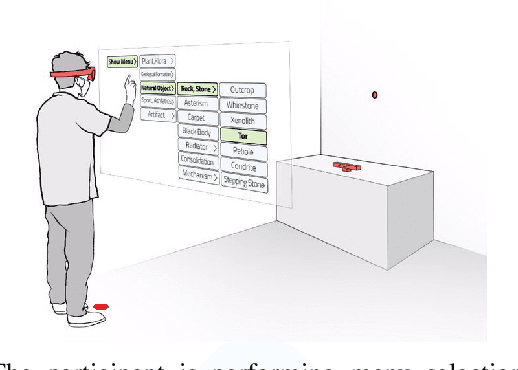
There are currently limited guidelines on designing user interfaces (UI) for immersive augmented reality (AR) applications. Designers must reflect on their experience designing UI for desktop and mobile applications and conjecture how a UI will influence AR users' performance. In this work, we introduce a predictive model for determining users' performance for a target UI without the subsequent involvement of participants in user studies. The model is trained on participants' responses to objective performance measures such as consumed endurance (CE) and pointing time (PT) using hierarchical drop-down menus. Large variability in the depth and context of the menus is ensured by randomly and dynamically creating the hierarchical drop-down menus and associated user tasks from words contained in the lexical database WordNet. Subjective performance bias is reduced by incorporating the users' non-verbal standard performance WAIS-IV during the model training. The semantic information of the menu is encoded using the Universal Sentence Encoder. We present the results of a user study that demonstrates that the proposed predictive model achieves high accuracy in predicting the CE on hierarchical menus of users with various cognitive abilities. To the best of our knowledge, this is the first work on predicting CE in designing UI for immersive AR applications.
Adaptive Memory Management for Video Object Segmentation
Apr 13, 2022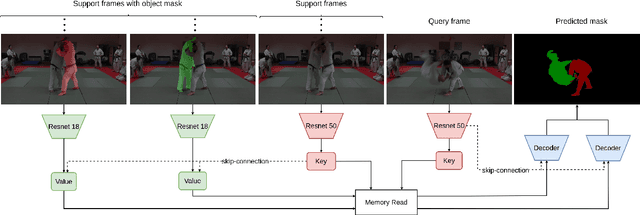
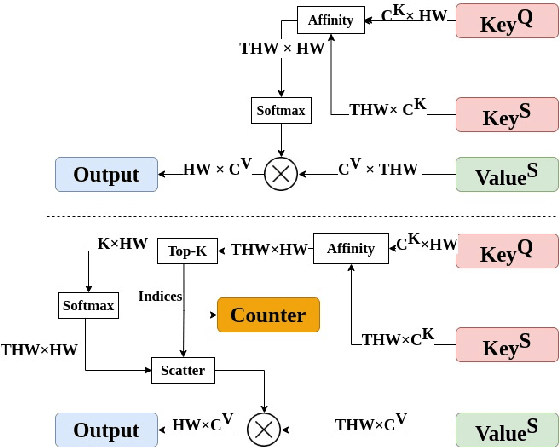
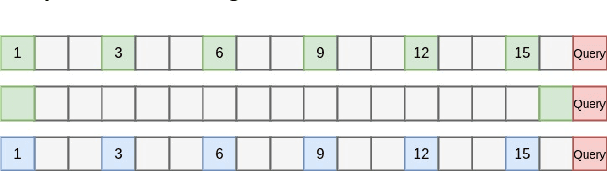

Matching-based networks have achieved state-of-the-art performance for video object segmentation (VOS) tasks by storing every-k frames in an external memory bank for future inference. Storing the intermediate frames' predictions provides the network with richer cues for segmenting an object in the current frame. However, the size of the memory bank gradually increases with the length of the video, which slows down inference speed and makes it impractical to handle arbitrary length videos. This paper proposes an adaptive memory bank strategy for matching-based networks for semi-supervised video object segmentation (VOS) that can handle videos of arbitrary length by discarding obsolete features. Features are indexed based on their importance in the segmentation of the objects in previous frames. Based on the index, we discard unimportant features to accommodate new features. We present our experiments on DAVIS 2016, DAVIS 2017, and Youtube-VOS that demonstrate that our method outperforms state-of-the-art that employ first-and-latest strategy with fixed-sized memory banks and achieves comparable performance to the every-k strategy with increasing-sized memory banks. Furthermore, experiments show that our method increases inference speed by up to 80% over the every-k and 35% over first-and-latest strategies.
Multi-view Gradient Consistency for SVBRDF Estimation of Complex Scenes under Natural Illumination
Feb 25, 2022
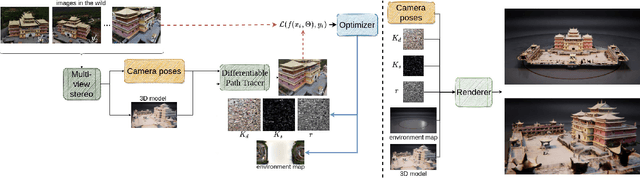


This paper presents a process for estimating the spatially varying surface reflectance of complex scenes observed under natural illumination. In contrast to previous methods, our process is not limited to scenes viewed under controlled lighting conditions but can handle complex indoor and outdoor scenes viewed under arbitrary illumination conditions. An end-to-end process uses a model of the scene's geometry and several images capturing the scene's surfaces from arbitrary viewpoints and under various natural illumination conditions. We develop a differentiable path tracer that leverages least-square conformal mapping for handling multiple disjoint objects appearing in the scene. We follow a two-step optimization process and introduce a multi-view gradient consistency loss which results in up to 30-50% improvement in the image reconstruction loss and can further achieve better disentanglement of the diffuse and specular BRDFs compared to other state-of-the-art. We demonstrate the process in real-world indoor and outdoor scenes from images in the wild and show that we can produce realistic renders consistent with actual images using the estimated reflectance properties. Experiments show that our technique produces realistic results for arbitrary outdoor scenes with complex geometry. The source code is publicly available at: https://gitlab.com/alen.joy/multi-view-gradient-consistency-for-svbrdf-estimation-of-complex-scenes-under-natural-illumination
Predicting Surface Reflectance Properties of Outdoor Scenes Under Unknown Natural Illumination
May 14, 2021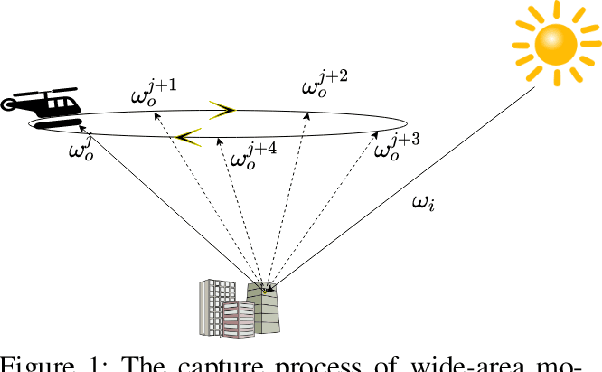
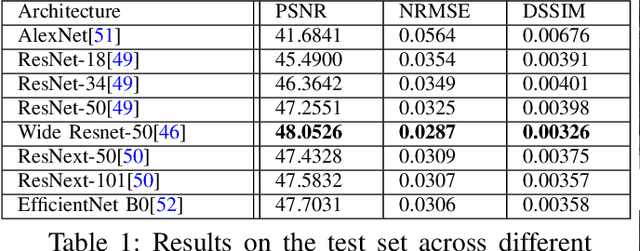
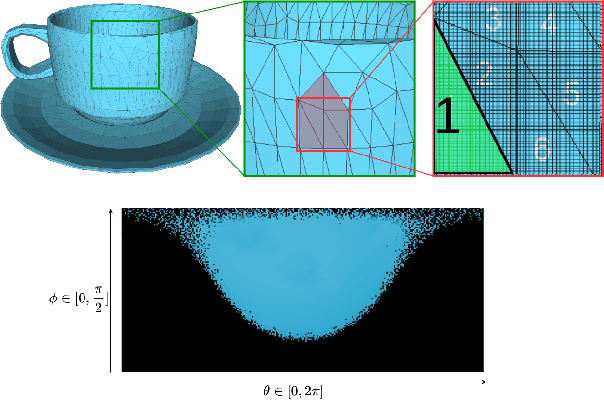

Estimating and modelling the appearance of an object under outdoor illumination conditions is a complex process. Although there have been several studies on illumination estimation and relighting, very few of them focus on estimating the reflectance properties of outdoor objects and scenes. This paper addresses this problem and proposes a complete framework to predict surface reflectance properties of outdoor scenes under unknown natural illumination. Uniquely, we recast the problem into its two constituent components involving the BRDF incoming light and outgoing view directions: (i) surface points' radiance captured in the images, and outgoing view directions are aggregated and encoded into reflectance maps, and (ii) a neural network trained on reflectance maps of renders of a unit sphere under arbitrary light directions infers a low-parameter reflection model representing the reflectance properties at each surface in the scene. Our model is based on a combination of phenomenological and physics-based scattering models and can relight the scenes from novel viewpoints. We present experiments that show that rendering with the predicted reflectance properties results in a visually similar appearance to using textures that cannot otherwise be disentangled from the reflectance properties.
Semantic Segmentation from Remote Sensor Data and the Exploitation of Latent Learning for Classification of Auxiliary Tasks
Dec 19, 2019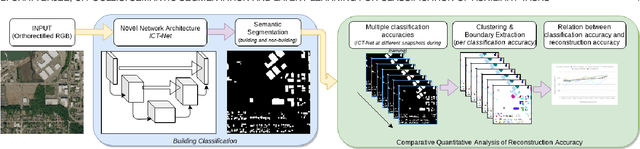
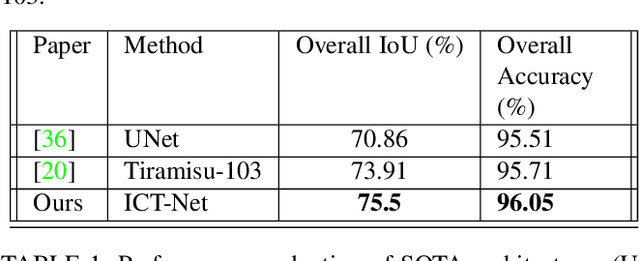
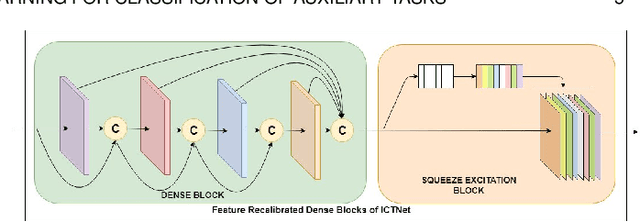
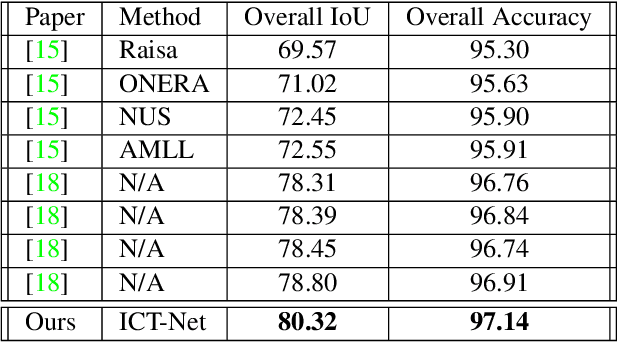
In this paper we address three different aspects of semantic segmentation from remote sensor data using deep neural networks. Firstly, we focus on the semantic segmentation of buildings from remote sensor data and propose ICT-Net. The proposed network has been tested on the INRIA and AIRS benchmark datasets and is shown to outperform all other state of the art by more than 1.5% and 1.8% on the Jaccard index, respectively. Secondly, as the building classification is typically the first step of the reconstruction process, we investigate the relationship of the classification accuracy to the reconstruction accuracy. Finally, we present the simple yet compelling concept of latent learning and the implications it carries within the context of deep learning. We posit that a network trained on a primary task (i.e. building classification) is unintentionally learning about auxiliary tasks (e.g. the classification of road, tree, etc) which are complementary to the primary task. We extensively tested the proposed technique on the ISPRS benchmark dataset which contains multi-label ground truth, and report an average classification accuracy (F1 score) of 54.29% (SD=17.03) for roads, 10.15% (SD=2.54) for cars, 24.11% (SD=5.25) for trees, 42.74% (SD=6.62) for low vegetation, and 18.30% (SD=16.08) for clutter. The source code and supplemental material is publicly available at http://www.theICTlab.org/lp/2019ICT-Net/.
Multi-label Pixelwise Classification for Reconstruction of Large-scale Urban Areas
Jan 23, 2018
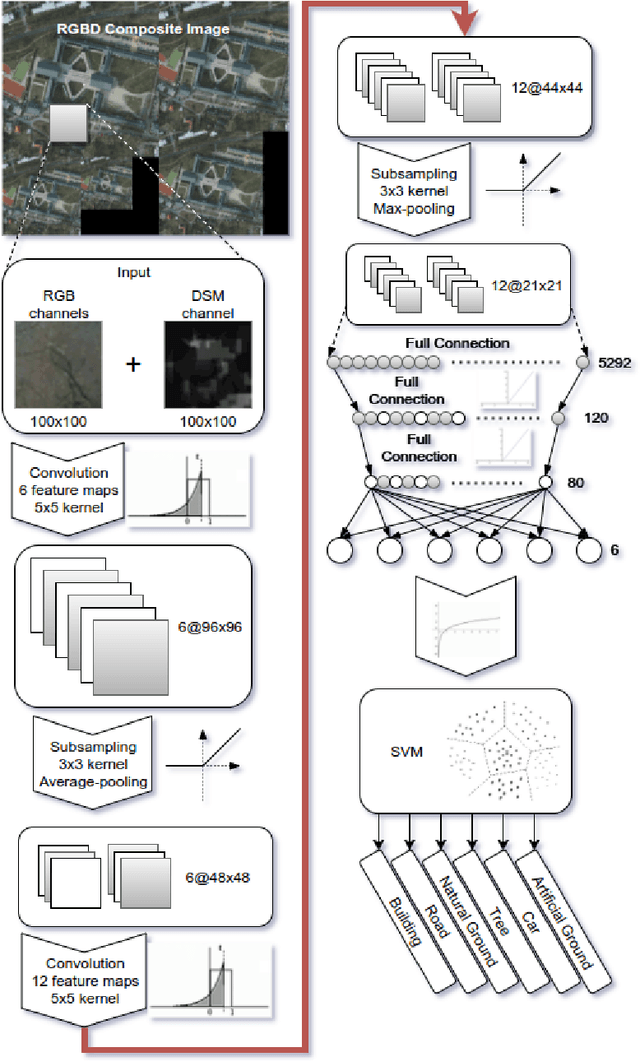

Object classification is one of the many holy grails in computer vision and as such has resulted in a very large number of algorithms being proposed already. Specifically in recent years there has been considerable progress in this area primarily due to the increased efficiency and accessibility of deep learning techniques. In fact, for single-label object classification [i.e. only one object present in the image] the state-of-the-art techniques employ deep neural networks and are reporting very close to human-like performance. There are specialized applications in which single-label object-level classification will not suffice; for example in cases where the image contains multiple intertwined objects of different labels. In this paper, we address the complex problem of multi-label pixelwise classification. We present our distinct solution based on a convolutional neural network (CNN) for performing multi-label pixelwise classification and its application to large-scale urban reconstruction. A supervised learning approach is followed for training a 13-layer CNN using both LiDAR and satellite images. An empirical study has been conducted to determine the hyperparameters which result in the optimal performance of the CNN. Scale invariance is introduced by training the network on five different scales of the input and labeled data. This results in six pixelwise classifications for each different scale. An SVM is then trained to map the six pixelwise classifications into a single-label. Lastly, we refine boundary pixel labels using graph-cuts for maximum a-posteriori (MAP) estimation with Markov Random Field (MRF) priors. The resulting pixelwise classification is then used to accurately extract and reconstruct the buildings in large-scale urban areas. The proposed approach has been extensively tested and the results are reported.
3DUNDERWORLD-SLS: An Open-Source Structured-Light Scanning System for Rapid Geometry Acquisition
Aug 20, 2016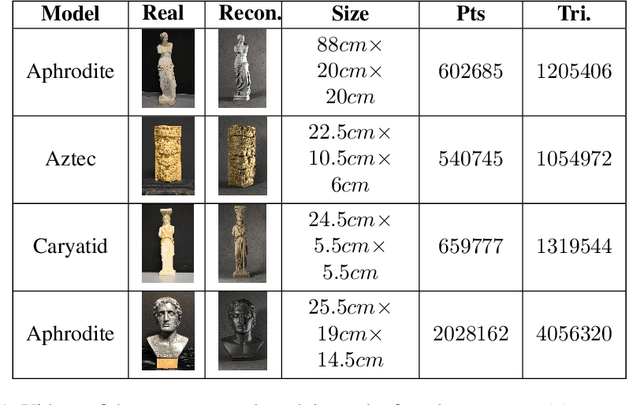

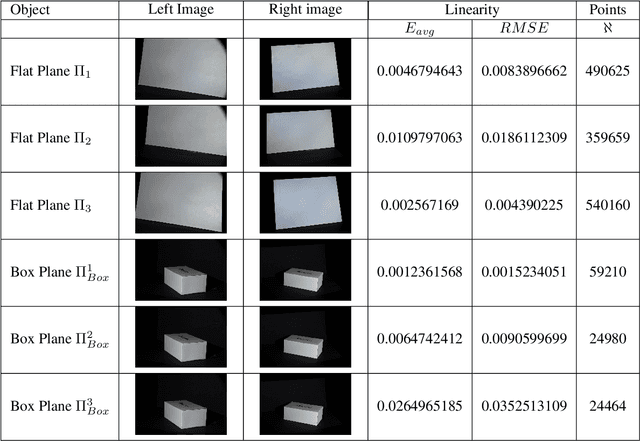
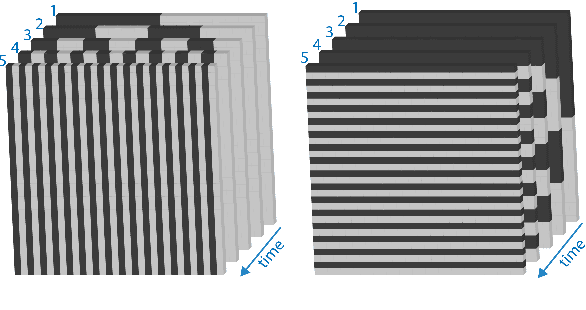
Recently, there has been an increase in the demand of virtual 3D objects representing real-life objects. A plethora of methods and systems have already been proposed for the acquisition of the geometry of real-life objects ranging from those which employ active sensor technology, passive sensor technology or a combination of various techniques. In this paper we present the development of a 3D scanning system which is based on the principle of structured-light, without having particular requirements for specialized equipment. We discuss the intrinsic details and inherent difficulties of structured-light scanning techniques and present our solutions. Finally, we introduce our open-source scanning software system "3DUNDERWORLD-SLS" which implements the proposed techniques both in CPU and GPU. We have performed extensive testing with a wide range of models and report the results. Furthermore, we present a comprehensive evaluation of the system and a comparison with a high-end commercial 3D scanner.