 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning, Social Intelligence and the Turing Test - why an "out-of-the-box" Turing Machine will not pass the Turing Test
Mar 15, 2012The Turing Test (TT) checks for human intelligence, rather than any putative general intelligence. It involves repeated interaction requiring learning in the form of adaption to the human conversation partner. It is a macro-level post-hoc test in contrast to the definition of a Turing Machine (TM), which is a prior micro-level definition. This raises the question of whether learning is just another computational process, i.e. can be implemented as a TM. Here we argue that learning or adaption is fundamentally different from computation, though it does involve processes that can be seen as computations. To illustrate this difference we compare (a) designing a TM and (b) learning a TM, defining them for the purpose of the argument. We show that there is a well-defined sequence of problems which are not effectively designable but are learnable, in the form of the bounded halting problem. Some characteristics of human intelligence are reviewed including it's: interactive nature, learning abilities, imitative tendencies, linguistic ability and context-dependency. A story that explains some of these is the Social Intelligence Hypothesis. If this is broadly correct, this points to the necessity of a considerable period of acculturation (social learning in context) if an artificial intelligence is to pass the TT. Whilst it is always possible to 'compile' the results of learning into a TM, this would not be a designed TM and would not be able to continually adapt (pass future TTs). We conclude three things, namely that: a purely "designed" TM will never pass the TT; that there is no such thing as a general intelligence since it necessary involves learning; and that learning/adaption and computation should be clearly distinguished.
* 10 pages, invited talk at Turing Centenary Conference CiE 2012, special session on "The Turing Test and Thinking Machines"
Are Minds Computable?
Oct 13, 2011This essay explores the limits of Turing machines concerning the modeling of minds and suggests alternatives to go beyond those limits.
Complex Networks
Apr 29, 2011Introduction to the Special Issue on Complex Networks, Artificial Life journal.
* 7 pages, in press
Polyethism in a colony of artificial ants
Apr 15, 2011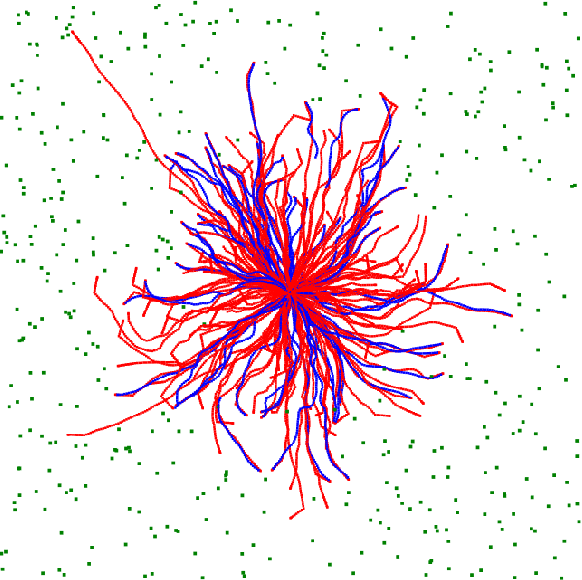
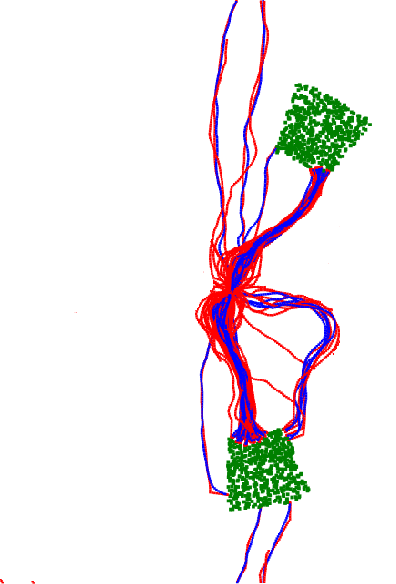
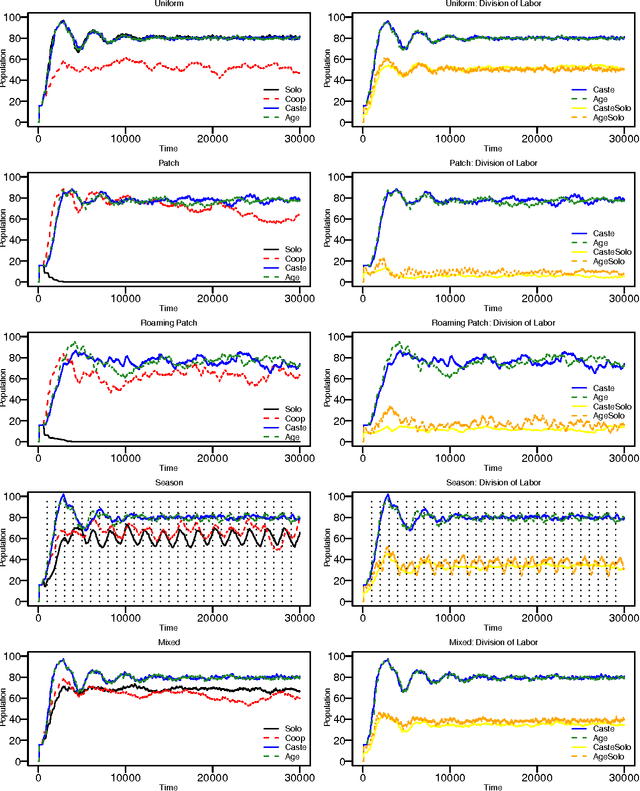
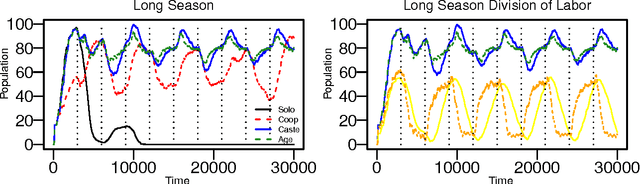
We explore self-organizing strategies for role assignment in a foraging task carried out by a colony of artificial agents. Our strategies are inspired by various mechanisms of division of labor (polyethism) observed in eusocial insects like ants, termites, or bees. Specifically we instantiate models of caste polyethism and age or temporal polyethism to evaluated the benefits to foraging in a dynamic environment. Our experiment is directly related to the exploration/exploitation trade of in machine learning.
* 8 pages, 4 figures, submitted to ECAL 11
Self-organizing traffic lights at multiple-street intersections
Apr 14, 2011
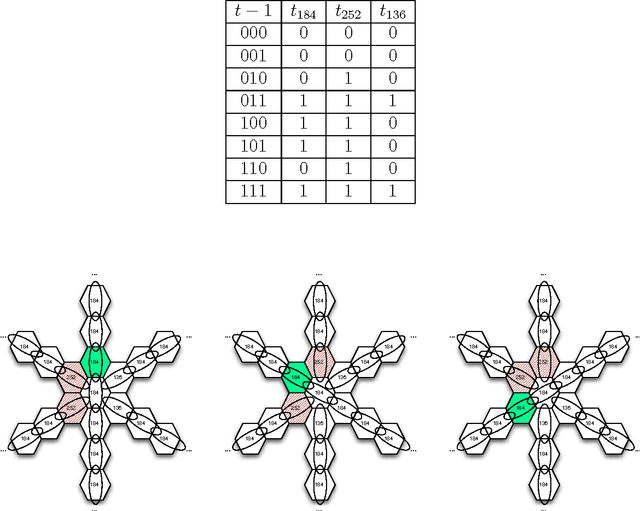
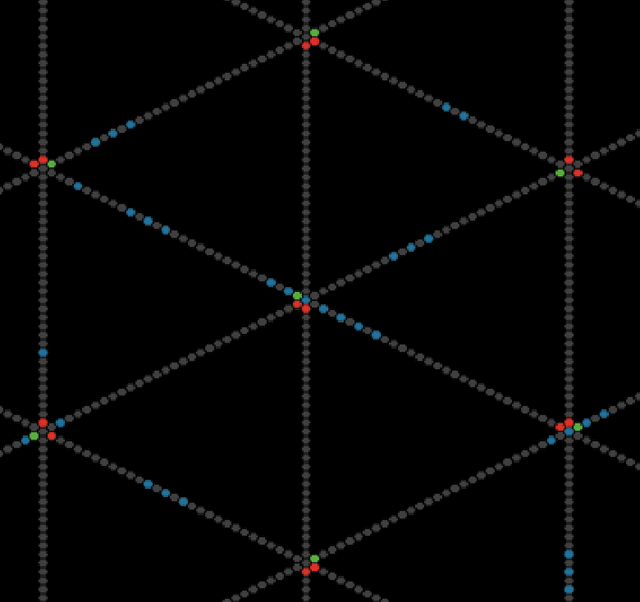
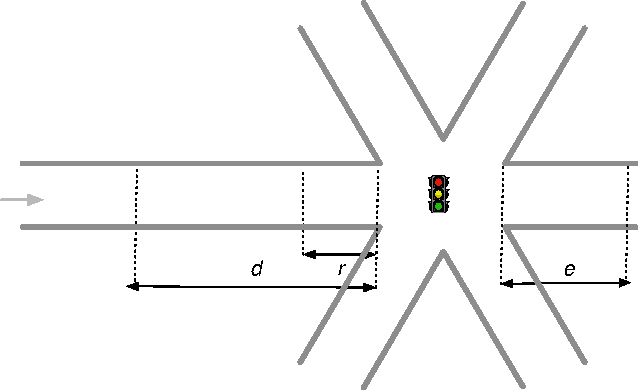
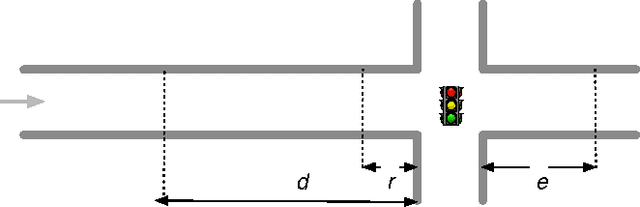
Summary: Traffic light coordination is a complex problem. In this paper, we extend previous work on an abstract model of city traffic to allow for multiple street intersections. We test a self-organizing method in our model, showing that it is close to theoretical optima and superior to a traditional method of traffic light coordination. Abstract: The elementary cellular automaton following rule 184 can mimic particles flowing in one direction at a constant speed. This automaton can therefore model highway traffic. In a recent paper, we have incorporated intersections regulated by traffic lights to this model using exclusively elementary cellular automata. In such a paper, however, we only explored a rectangular grid. We now extend our model to more complex scenarios employing an hexagonal grid. This extension shows first that our model can readily incorporate multiple-way intersections and hence simulate complex scenarios. In addition, the current extension allows us to study and evaluate the behavior of two different kinds of traffic light controller for a grid of six-way streets allowing for either two or three street intersections: a traffic light that tries to adapt to the amount of traffic (which results in self-organizing traffic lights) and a system of synchronized traffic lights with coordinated rigid periods (sometimes called the "green wave" method). We observe a tradeoff between system capacity and topological complexity. The green wave method is unable to cope with the complexity of a higher-capacity scenario, while the self-organizing method is scalable, adapting to the complexity of a scenario and exploiting its maximum capacity. Additionally, in this paper we propose a benchmark, independent of methods and models, to measure the performance of a traffic light controller comparing it against a theoretical optimum.
The World as Evolving Information
Oct 13, 2010This paper discusses the benefits of describing the world as information, especially in the study of the evolution of life and cognition. Traditional studies encounter problems because it is difficult to describe life and cognition in terms of matter and energy, since their laws are valid only at the physical scale. However, if matter and energy, as well as life and cognition, are described in terms of information, evolution can be described consistently as information becoming more complex. The paper presents eight tentative laws of information, valid at multiple scales, which are generalizations of Darwinian, cybernetic, thermodynamic, psychological, philosophical, and complexity principles. These are further used to discuss the notions of life, cognition and their evolution.
* 16 pages. Extended version, three more laws of information, two classifications, and discussion added. To be published (soon) in International Conference on Complex Systems 2007 Proceedings
Computing Networks: A General Framework to Contrast Neural and Swarm Cognitions
Jul 26, 2010


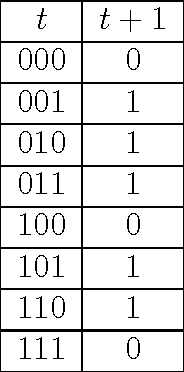
This paper presents the Computing Networks (CNs) framework. CNs are used to generalize neural and swarm architectures. Artificial neural networks, ant colony optimization, particle swarm optimization, and realistic biological models are used as examples of instantiations of CNs. The description of these architectures as CNs allows their comparison. Their differences and similarities allow the identification of properties that enable neural and swarm architectures to perform complex computations and exhibit complex cognitive abilities. In this context, the most relevant characteristics of CNs are the existence multiple dynamical and functional scales. The relationship between multiple dynamical and functional scales with adaptation, cognition (of brains and swarms) and computation is discussed.
* 18 pages, 5 figures
Modeling self-organizing traffic lights with elementary cellular automata
Jul 10, 2009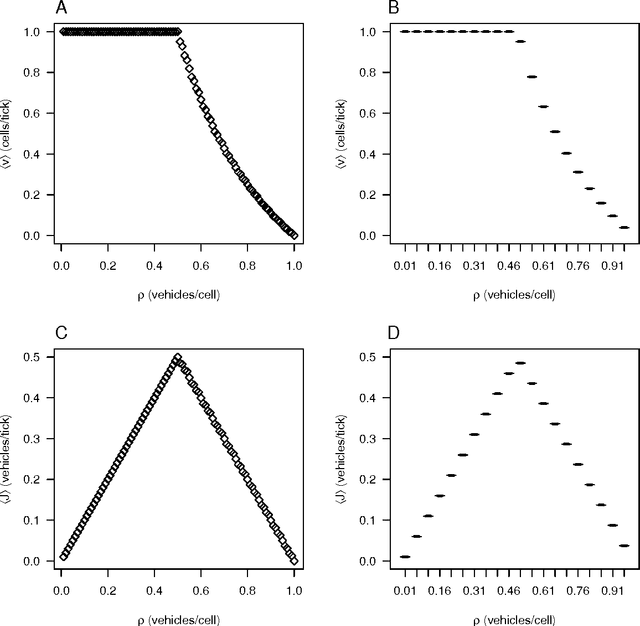

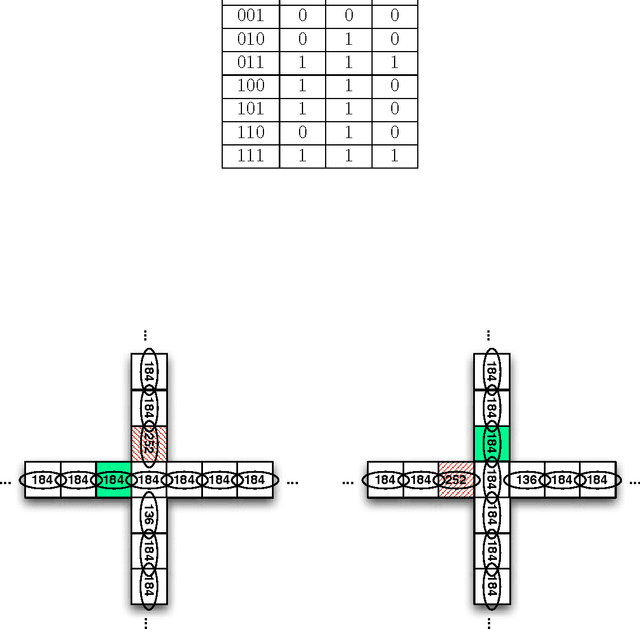
There have been several highway traffic models proposed based on cellular automata. The simplest one is elementary cellular automaton rule 184. We extend this model to city traffic with cellular automata coupled at intersections using only rules 184, 252, and 136. The simplicity of the model offers a clear understanding of the main properties of city traffic and its phase transitions. We use the proposed model to compare two methods for coordinating traffic lights: a green-wave method that tries to optimize phases according to expected flows and a self-organizing method that adapts to the current traffic conditions. The self-organizing method delivers considerable improvements over the green-wave method. For low densities, the self-organizing method promotes the formation and coordination of platoons that flow freely in four directions, i.e. with a maximum velocity and no stops. For medium densities, the method allows a constant usage of the intersections, exploiting their maximum flux capacity. For high densities, the method prevents gridlocks and promotes the formation and coordination of "free-spaces" that flow in the opposite direction of traffic.
* 33 pages, 11 Figures, 3 Tables
What Does Artificial Life Tell Us About Death?
Jun 15, 2009Short philosophical essay
* 5 pages
Using RDF to Model the Structure and Process of Systems
Oct 15, 2007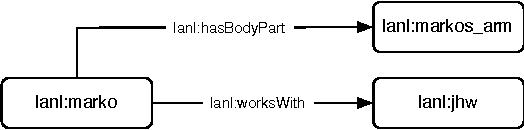
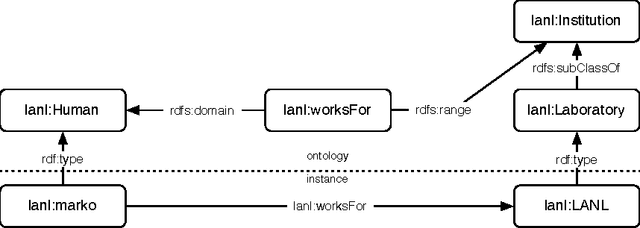
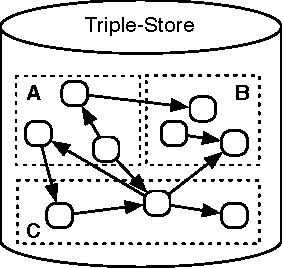
Many systems can be described in terms of networks of discrete elements and their various relationships to one another. A semantic network, or multi-relational network, is a directed labeled graph consisting of a heterogeneous set of entities connected by a heterogeneous set of relationships. Semantic networks serve as a promising general-purpose modeling substrate for complex systems. Various standardized formats and tools are now available to support practical, large-scale semantic network models. First, the Resource Description Framework (RDF) offers a standardized semantic network data model that can be further formalized by ontology modeling languages such as RDF Schema (RDFS) and the Web Ontology Language (OWL). Second, the recent introduction of highly performant triple-stores (i.e. semantic network databases) allows semantic network models on the order of $10^9$ edges to be efficiently stored and manipulated. RDF and its related technologies are currently used extensively in the domains of computer science, digital library science, and the biological sciences. This article will provide an introduction to RDF/RDFS/OWL and an examination of its suitability to model discrete element complex systems.
* International Conference on Complex Systems, Boston MA, October 2007