 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Based Hierarchical Clustering
Jan 16, 2013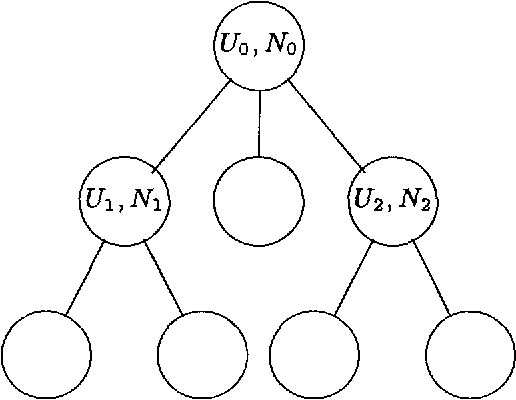
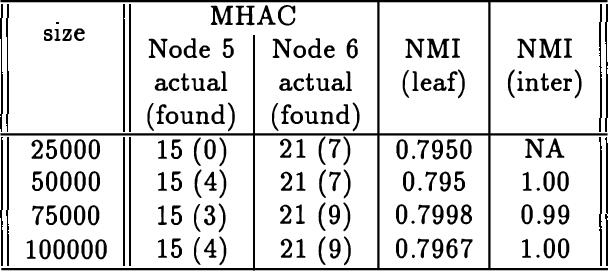
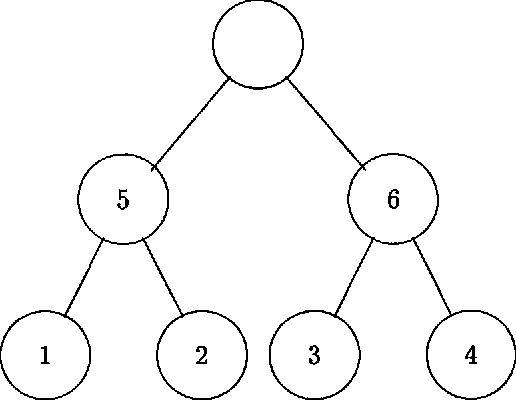
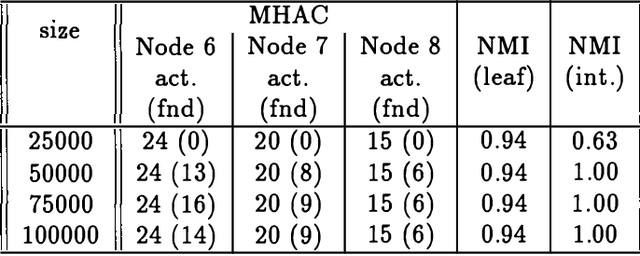
We present an approach to model-based hierarchical clustering by formulating an objective function based on a Bayesian analysis. This model organizes the data into a cluster hierarchy while specifying a complex feature-set partitioning that is a key component of our model. Features can have either a unique distribution in every cluster or a common distribution over some (or even all) of the clusters. The cluster subsets over which these features have such a common distribution correspond to the nodes (clusters) of the tree representing the hierarchy. We apply this general model to the problem of document clustering for which we use a multinomial likelihood function and Dirichlet priors. Our algorithm consists of a two-stage process wherein we first perform a flat clustering followed by a modified hierarchical agglomerative merging process that includes determining the features that will have common distributions over the merged clusters. The regularization induced by using the marginal likelihood automatically determines the optimal model structure including number of clusters, the depth of the tree and the subset of features to be modeled as having a common distribution at each node. We present experimental results on both synthetic data and a real document collection.
An Information-Theoretic External Cluster-Validity Measure
Dec 12, 2012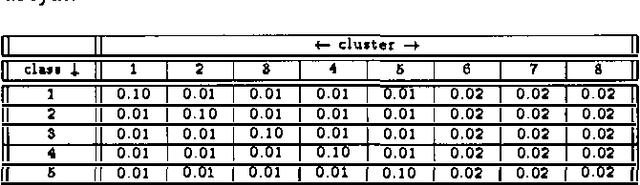
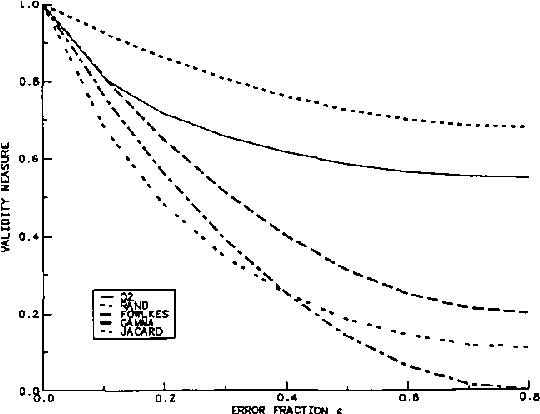
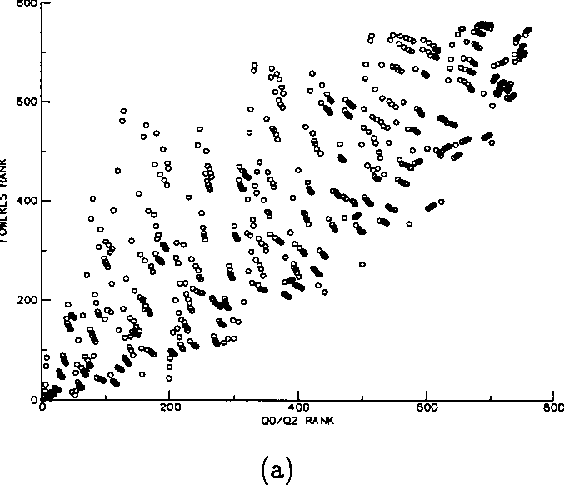
In this paper we propose a measure of clustering quality or accuracy that is appropriate in situations where it is desirable to evaluate a clustering algorithm by somehow comparing the clusters it produces with ``ground truth' consisting of classes assigned to the patterns by manual means or some other means in whose veracity there is confidence. Such measures are refered to as ``external'. Our measure also has the characteristic of allowing clusterings with different numbers of clusters to be compared in a quantitative and principled way. Our evaluation scheme quantitatively measures how useful the cluster labels of the patterns are as predictors of their class labels. In cases where all clusterings to be compared have the same number of clusters, the measure is equivalent to the mutual information between the cluster labels and the class labels. In cases where the numbers of clusters are different, however, it computes the reduction in the number of bits that would be required to encode (compress) the class labels if both the encoder and decoder have free acccess to the cluster labels. To achieve this encoding the estimated conditional probabilities of the class labels given the cluster labels must also be encoded. These estimated probabilities can be seen as a model for the class labels and their associated code length as a model cost.