 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCamera-Driven Representation Learning for Unsupervised Domain Adaptive Person Re-identification
Aug 23, 2023



We present a novel unsupervised domain adaption method for person re-identification (reID) that generalizes a model trained on a labeled source domain to an unlabeled target domain. We introduce a camera-driven curriculum learning (CaCL) framework that leverages camera labels of person images to transfer knowledge from source to target domains progressively. To this end, we divide target domain dataset into multiple subsets based on the camera labels, and initially train our model with a single subset (i.e., images captured by a single camera). We then gradually exploit more subsets for training, according to a curriculum sequence obtained with a camera-driven scheduling rule. The scheduler considers maximum mean discrepancies (MMD) between each subset and the source domain dataset, such that the subset closer to the source domain is exploited earlier within the curriculum. For each curriculum sequence, we generate pseudo labels of person images in a target domain to train a reID model in a supervised way. We have observed that the pseudo labels are highly biased toward cameras, suggesting that person images obtained from the same camera are likely to have the same pseudo labels, even for different IDs. To address the camera bias problem, we also introduce a camera-diversity (CD) loss encouraging person images of the same pseudo label, but captured across various cameras, to involve more for discriminative feature learning, providing person representations robust to inter-camera variations. Experimental results on standard benchmarks, including real-to-real and synthetic-to-real scenarios, demonstrate the effectiveness of our framework.
ALIFE: Adaptive Logit Regularizer and Feature Replay for Incremental Semantic Segmentation
Oct 13, 2022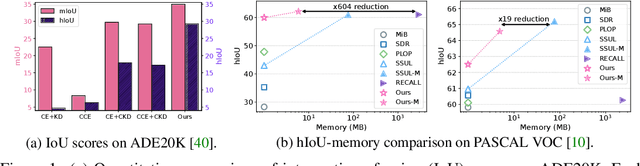
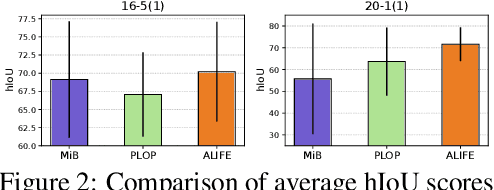
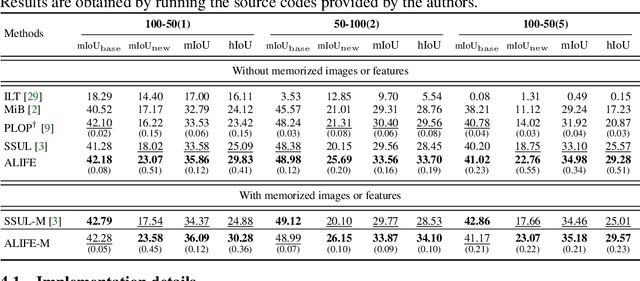
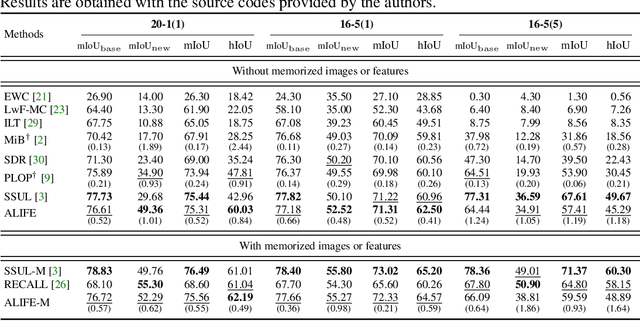
We address the problem of incremental semantic segmentation (ISS) recognizing novel object/stuff categories continually without forgetting previous ones that have been learned. The catastrophic forgetting problem is particularly severe in ISS, since pixel-level ground-truth labels are available only for the novel categories at training time. To address the problem, regularization-based methods exploit probability calibration techniques to learn semantic information from unlabeled pixels. While such techniques are effective, there is still a lack of theoretical understanding of them. Replay-based methods propose to memorize a small set of images for previous categories. They achieve state-of-the-art performance at the cost of large memory footprint. We propose in this paper a novel ISS method, dubbed ALIFE, that provides a better compromise between accuracy and efficiency. To this end, we first show an in-depth analysis on the calibration techniques to better understand the effects on ISS. Based on this, we then introduce an adaptive logit regularizer (ALI) that enables our model to better learn new categories, while retaining knowledge for previous ones. We also present a feature replay scheme that memorizes features, instead of images directly, in order to reduce memory requirements significantly. Since a feature extractor is changed continually, memorized features should also be updated at every incremental stage. To handle this, we introduce category-specific rotation matrices updating the features for each category separately. We demonstrate the effectiveness of our approach with extensive experiments on standard ISS benchmarks, and show that our method achieves a better trade-off in terms of accuracy and efficiency.
Decomposed Knowledge Distillation for Class-Incremental Semantic Segmentation
Oct 12, 2022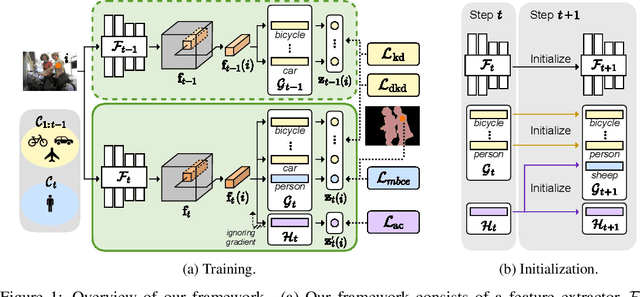
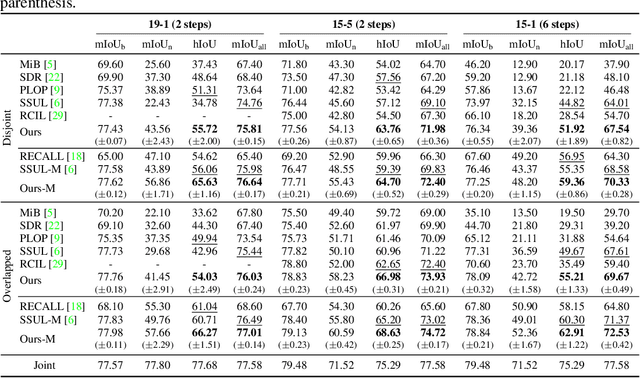
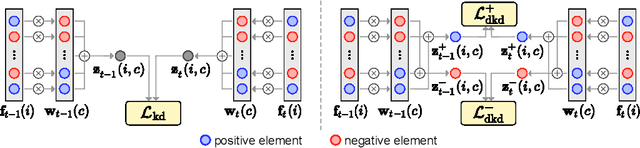
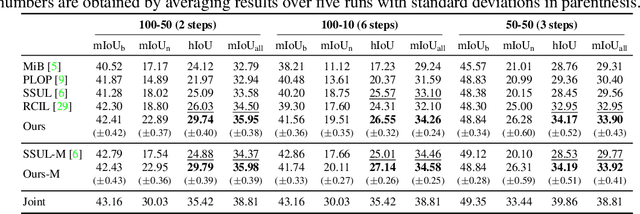
Class-incremental semantic segmentation (CISS) labels each pixel of an image with a corresponding object/stuff class continually. To this end, it is crucial to learn novel classes incrementally without forgetting previously learned knowledge. Current CISS methods typically use a knowledge distillation (KD) technique for preserving classifier logits, or freeze a feature extractor, to avoid the forgetting problem. The strong constraints, however, prevent learning discriminative features for novel classes. We introduce a CISS framework that alleviates the forgetting problem and facilitates learning novel classes effectively. We have found that a logit can be decomposed into two terms. They quantify how likely an input belongs to a particular class or not, providing a clue for a reasoning process of a model. The KD technique, in this context, preserves the sum of two terms (i.e., a class logit), suggesting that each could be changed and thus the KD does not imitate the reasoning process. To impose constraints on each term explicitly, we propose a new decomposed knowledge distillation (DKD) technique, improving the rigidity of a model and addressing the forgetting problem more effectively. We also introduce a novel initialization method to train new classifiers for novel classes. In CISS, the number of negative training samples for novel classes is not sufficient to discriminate old classes. To mitigate this, we propose to transfer knowledge of negatives to the classifiers successively using an auxiliary classifier, boosting the performance significantly. Experimental results on standard CISS benchmarks demonstrate the effectiveness of our framework.
Bi-directional Contrastive Learning for Domain Adaptive Semantic Segmentation
Jul 22, 2022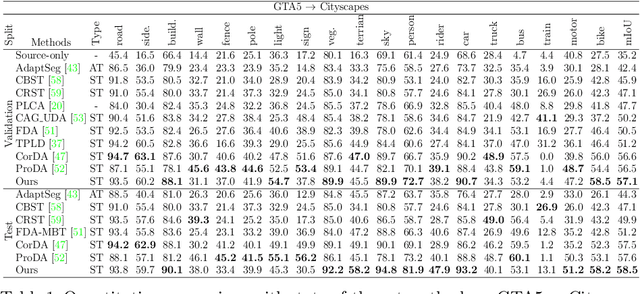
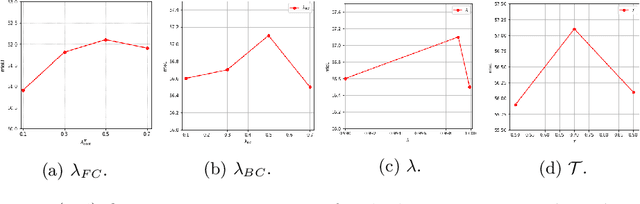
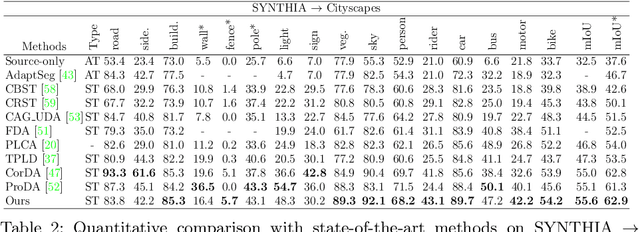
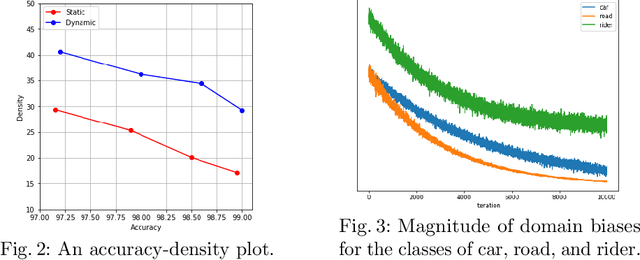
We present a novel unsupervised domain adaptation method for semantic segmentation that generalizes a model trained with source images and corresponding ground-truth labels to a target domain. A key to domain adaptive semantic segmentation is to learn domain-invariant and discriminative features without target ground-truth labels. To this end, we propose a bi-directional pixel-prototype contrastive learning framework that minimizes intra-class variations of features for the same object class, while maximizing inter-class variations for different ones, regardless of domains. Specifically, our framework aligns pixel-level features and a prototype of the same object class in target and source images (i.e., positive pairs), respectively, sets them apart for different classes (i.e., negative pairs), and performs the alignment and separation processes toward the other direction with pixel-level features in the source image and a prototype in the target image. The cross-domain matching encourages domain-invariant feature representations, while the bidirectional pixel-prototype correspondences aggregate features for the same object class, providing discriminative features. To establish training pairs for contrastive learning, we propose to generate dynamic pseudo labels of target images using a non-parametric label transfer, that is, pixel-prototype correspondences across different domains. We also present a calibration method compensating class-wise domain biases of prototypes gradually during training.
OIMNet++: Prototypical Normalization and Localization-aware Learning for Person Search
Jul 21, 2022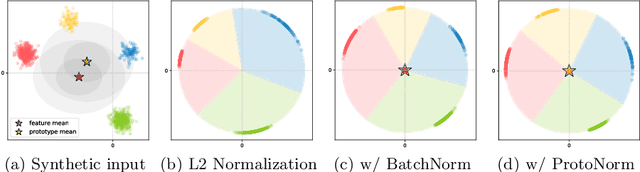
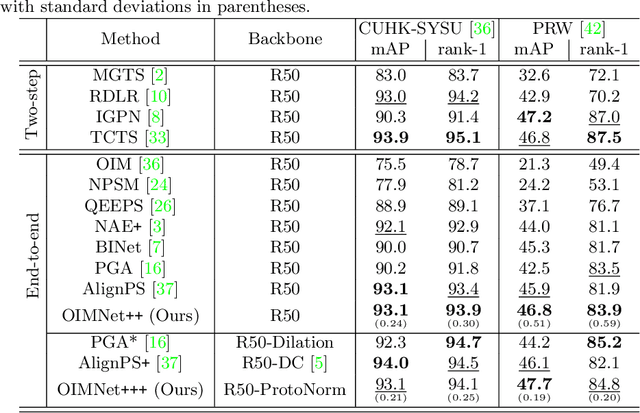
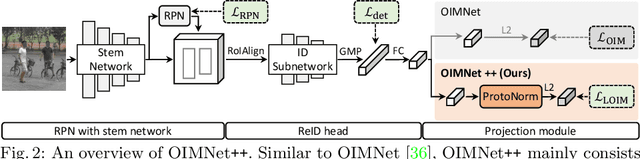
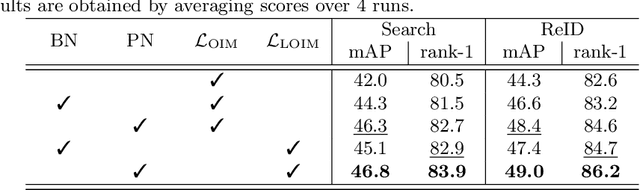
We address the task of person search, that is, localizing and re-identifying query persons from a set of raw scene images. Recent approaches are typically built upon OIMNet, a pioneer work on person search, that learns joint person representations for performing both detection and person re-identification (reID) tasks. To obtain the representations, they extract features from pedestrian proposals, and then project them on a unit hypersphere with L2 normalization. These methods also incorporate all positive proposals, that sufficiently overlap with the ground truth, equally to learn person representations for reID. We have found that 1) the L2 normalization without considering feature distributions degenerates the discriminative power of person representations, and 2) positive proposals often also depict background clutter and person overlaps, which could encode noisy features to person representations. In this paper, we introduce OIMNet++ that addresses the aforementioned limitations. To this end, we introduce a novel normalization layer, dubbed ProtoNorm, that calibrates features from pedestrian proposals, while considering a long-tail distribution of person IDs, enabling L2 normalized person representations to be discriminative. We also propose a localization-aware feature learning scheme that encourages better-aligned proposals to contribute more in learning discriminative representations. Experimental results and analysis on standard person search benchmarks demonstrate the effectiveness of OIMNet++.
Video-based Person Re-identification with Spatial and Temporal Memory Networks
Aug 20, 2021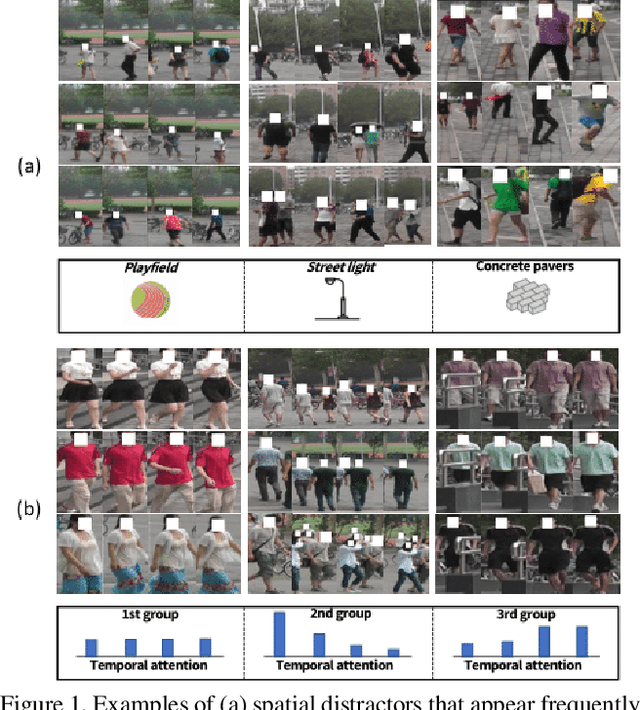
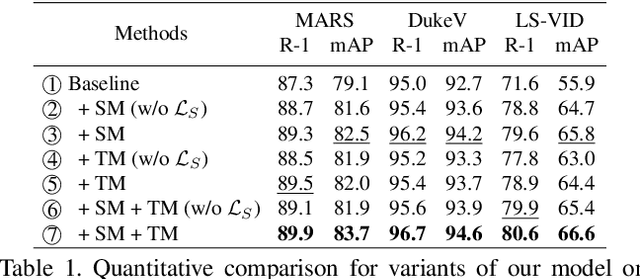
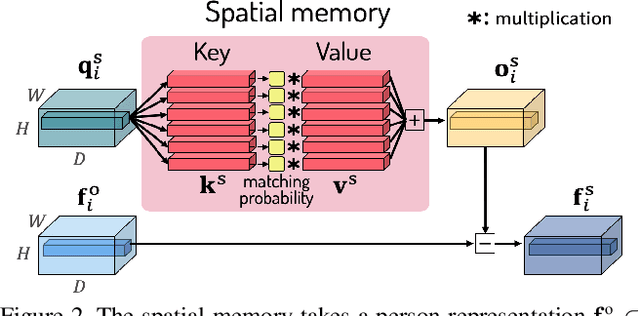
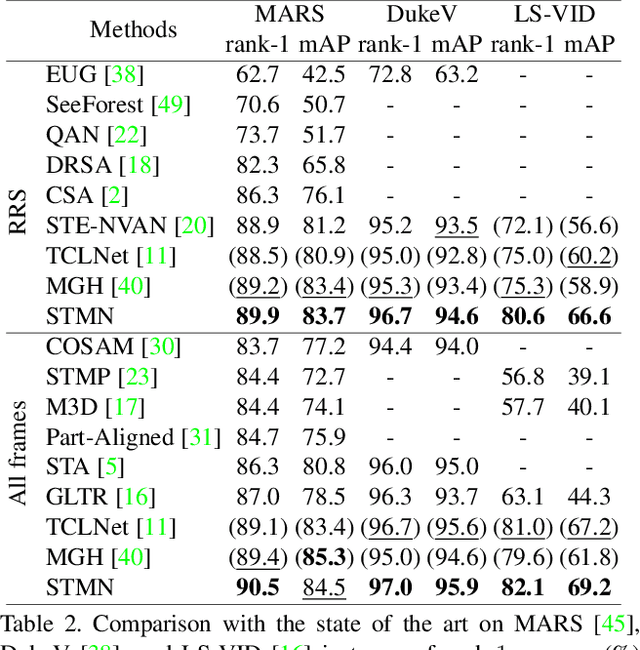
Video-based person re-identification (reID) aims to retrieve person videos with the same identity as a query person across multiple cameras. Spatial and temporal distractors in person videos, such as background clutter and partial occlusions over frames, respectively, make this task much more challenging than image-based person reID. We observe that spatial distractors appear consistently in a particular location, and temporal distractors show several patterns, e.g., partial occlusions occur in the first few frames, where such patterns provide informative cues for predicting which frames to focus on (i.e., temporal attentions). Based on this, we introduce a novel Spatial and Temporal Memory Networks (STMN). The spatial memory stores features for spatial distractors that frequently emerge across video frames, while the temporal memory saves attentions which are optimized for typical temporal patterns in person videos. We leverage the spatial and temporal memories to refine frame-level person representations and to aggregate the refined frame-level features into a sequence-level person representation, respectively, effectively handling spatial and temporal distractors in person videos. We also introduce a memory spread loss preventing our model from addressing particular items only in the memories. Experimental results on standard benchmarks, including MARS, DukeMTMC-VideoReID, and LS-VID, demonstrate the effectiveness of our method.
Learning by Aligning: Visible-Infrared Person Re-identification using Cross-Modal Correspondences
Aug 17, 2021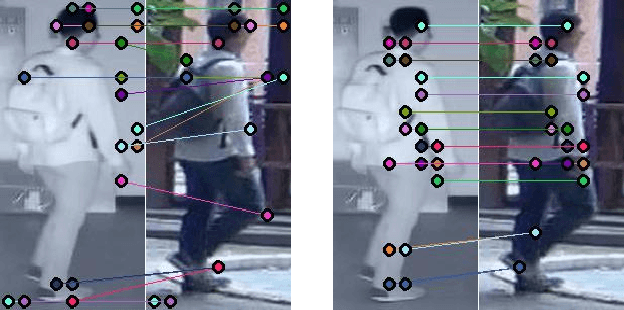
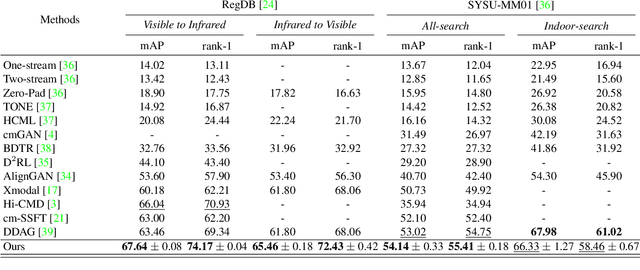
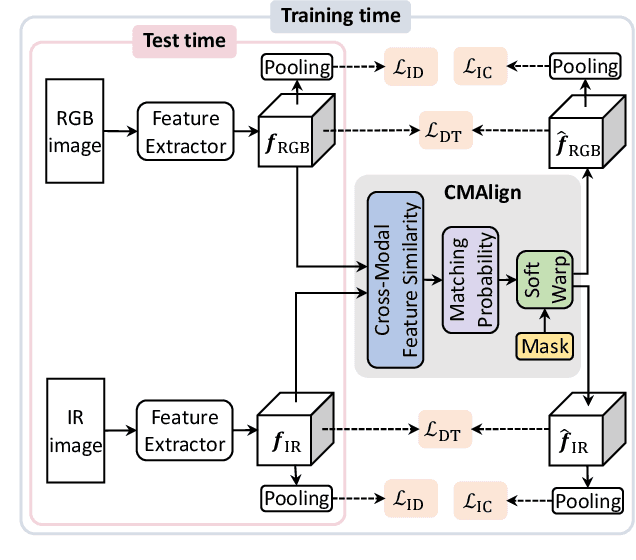
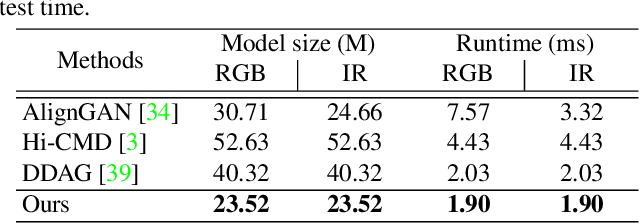
We address the problem of visible-infrared person re-identification (VI-reID), that is, retrieving a set of person images, captured by visible or infrared cameras, in a cross-modal setting. Two main challenges in VI-reID are intra-class variations across person images, and cross-modal discrepancies between visible and infrared images. Assuming that the person images are roughly aligned, previous approaches attempt to learn coarse image- or rigid part-level person representations that are discriminative and generalizable across different modalities. However, the person images, typically cropped by off-the-shelf object detectors, are not necessarily well-aligned, which distract discriminative person representation learning. In this paper, we introduce a novel feature learning framework that addresses these problems in a unified way. To this end, we propose to exploit dense correspondences between cross-modal person images. This allows to address the cross-modal discrepancies in a pixel-level, suppressing modality-related features from person representations more effectively. This also encourages pixel-wise associations between cross-modal local features, further facilitating discriminative feature learning for VI-reID. Extensive experiments and analyses on standard VI-reID benchmarks demonstrate the effectiveness of our approach, which significantly outperforms the state of the art.
Distance-aware Quantization
Aug 16, 2021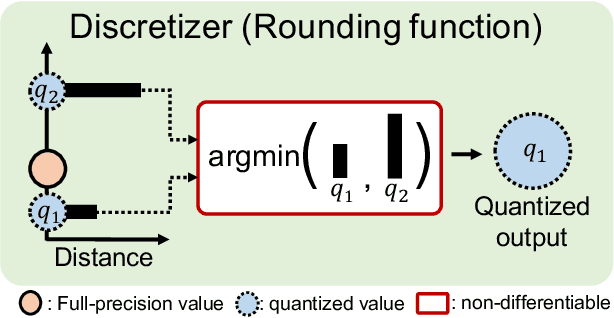
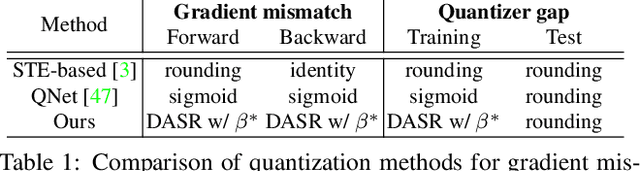
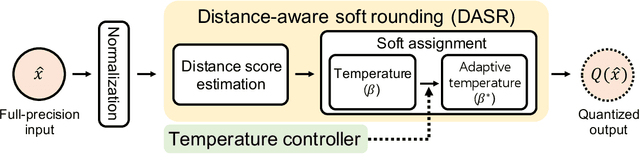

We address the problem of network quantization, that is, reducing bit-widths of weights and/or activations to lighten network architectures. Quantization methods use a rounding function to map full-precision values to the nearest quantized ones, but this operation is not differentiable. There are mainly two approaches to training quantized networks with gradient-based optimizers. First, a straight-through estimator (STE) replaces the zero derivative of the rounding with that of an identity function, which causes a gradient mismatch problem. Second, soft quantizers approximate the rounding with continuous functions at training time, and exploit the rounding for quantization at test time. This alleviates the gradient mismatch, but causes a quantizer gap problem. We alleviate both problems in a unified framework. To this end, we introduce a novel quantizer, dubbed a distance-aware quantizer (DAQ), that mainly consists of a distance-aware soft rounding (DASR) and a temperature controller. To alleviate the gradient mismatch problem, DASR approximates the discrete rounding with the kernel soft argmax, which is based on our insight that the quantization can be formulated as a distance-based assignment problem between full-precision values and quantized ones. The controller adjusts the temperature parameter in DASR adaptively according to the input, addressing the quantizer gap problem. Experimental results on standard benchmarks show that DAQ outperforms the state of the art significantly for various bit-widths without bells and whistles.
Exploiting a Joint Embedding Space for Generalized Zero-Shot Semantic Segmentation
Aug 14, 2021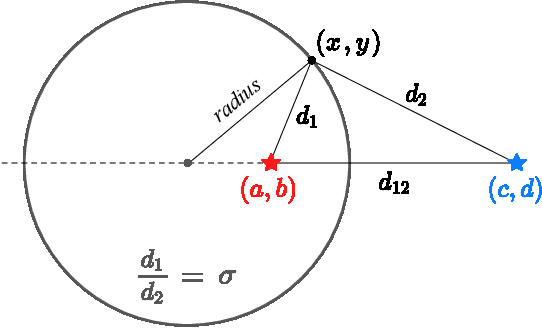

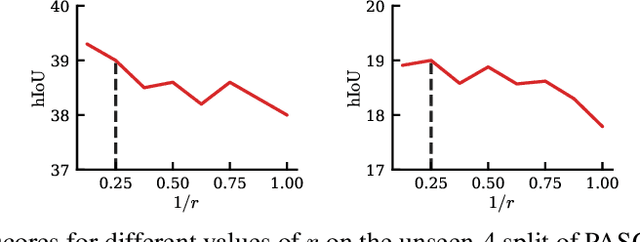

We address the problem of generalized zero-shot semantic segmentation (GZS3) predicting pixel-wise semantic labels for seen and unseen classes. Most GZS3 methods adopt a generative approach that synthesizes visual features of unseen classes from corresponding semantic ones (e.g., word2vec) to train novel classifiers for both seen and unseen classes. Although generative methods show decent performance, they have two limitations: (1) the visual features are biased towards seen classes; (2) the classifier should be retrained whenever novel unseen classes appear. We propose a discriminative approach to address these limitations in a unified framework. To this end, we leverage visual and semantic encoders to learn a joint embedding space, where the semantic encoder transforms semantic features to semantic prototypes that act as centers for visual features of corresponding classes. Specifically, we introduce boundary-aware regression (BAR) and semantic consistency (SC) losses to learn discriminative features. Our approach to exploiting the joint embedding space, together with BAR and SC terms, alleviates the seen bias problem. At test time, we avoid the retraining process by exploiting semantic prototypes as a nearest-neighbor (NN) classifier. To further alleviate the bias problem, we also propose an inference technique, dubbed Apollonius calibration (AC), that modulates the decision boundary of the NN classifier to the Apollonius circle adaptively. Experimental results demonstrate the effectiveness of our framework, achieving a new state of the art on standard benchmarks.
Background-Aware Pooling and Noise-Aware Loss for Weakly-Supervised Semantic Segmentation
Apr 02, 2021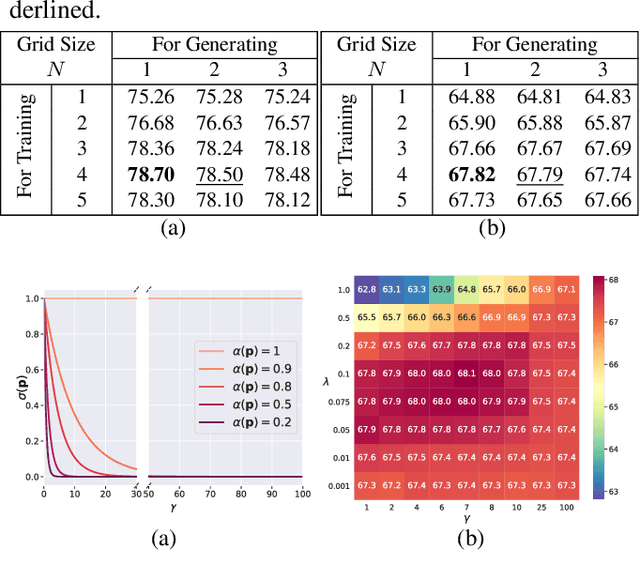

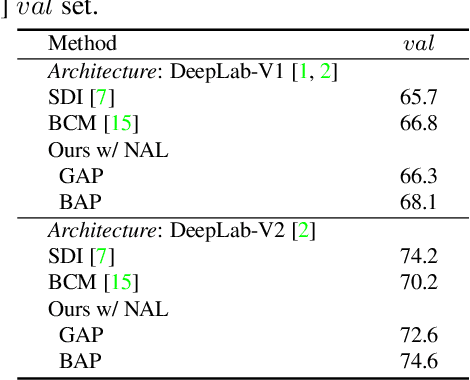

We address the problem of weakly-supervised semantic segmentation (WSSS) using bounding box annotations. Although object bounding boxes are good indicators to segment corresponding objects, they do not specify object boundaries, making it hard to train convolutional neural networks (CNNs) for semantic segmentation. We find that background regions are perceptually consistent in part within an image, and this can be leveraged to discriminate foreground and background regions inside object bounding boxes. To implement this idea, we propose a novel pooling method, dubbed background-aware pooling (BAP), that focuses more on aggregating foreground features inside the bounding boxes using attention maps. This allows to extract high-quality pseudo segmentation labels to train CNNs for semantic segmentation, but the labels still contain noise especially at object boundaries. To address this problem, we also introduce a noise-aware loss (NAL) that makes the networks less susceptible to incorrect labels. Experimental results demonstrate that learning with our pseudo labels already outperforms state-of-the-art weakly- and semi-supervised methods on the PASCAL VOC 2012 dataset, and the NAL further boosts the performance.