 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward INT4 Fixed-Point Training via Exploring Quantization Error for Gradients
Jul 17, 2024Network quantization generally converts full-precision weights and/or activations into low-bit fixed-point values in order to accelerate an inference process. Recent approaches to network quantization further discretize the gradients into low-bit fixed-point values, enabling an efficient training. They typically set a quantization interval using a min-max range of the gradients or adjust the interval such that the quantization error for entire gradients is minimized. In this paper, we analyze the quantization error of gradients for the low-bit fixed-point training, and show that lowering the error for large-magnitude gradients boosts the quantization performance significantly. Based on this, we derive an upper bound of quantization error for the large gradients in terms of the quantization interval, and obtain an optimal condition for the interval minimizing the quantization error for large gradients. We also introduce an interval update algorithm that adjusts the quantization interval adaptively to maintain a small quantization error for large gradients. Experimental results demonstrate the effectiveness of our quantization method for various combinations of network architectures and bit-widths on various tasks, including image classification, object detection, and super-resolution.
FYI: Flip Your Images for Dataset Distillation
Jul 11, 2024



Dataset distillation synthesizes a small set of images from a large-scale real dataset such that synthetic and real images share similar behavioral properties (e.g, distributions of gradients or features) during a training process. Through extensive analyses on current methods and real datasets, together with empirical observations, we provide in this paper two important things to share for dataset distillation. First, object parts that appear on one side of a real image are highly likely to appear on the opposite side of another image within a dataset, which we call the bilateral equivalence. Second, the bilateral equivalence enforces synthetic images to duplicate discriminative parts of objects on both the left and right sides of the images, limiting the recognition of subtle differences between objects. To address this problem, we introduce a surprisingly simple yet effective technique for dataset distillation, dubbed FYI, that enables distilling rich semantics of real images into synthetic ones. To this end, FYI embeds a horizontal flipping technique into distillation processes, mitigating the influence of the bilateral equivalence, while capturing more details of objects. Experiments on CIFAR-10/100, Tiny-ImageNet, and ImageNet demonstrate that FYI can be seamlessly integrated into several state-of-the-art methods, without modifying training objectives and network architectures, and it improves the performance remarkably.
Transition Rate Scheduling for Quantization-Aware Training
Apr 30, 2024Quantization-aware training (QAT) simulates a quantization process during training to lower bit-precision of weights/activations. It learns quantized weights indirectly by updating latent weights, i.e., full-precision inputs to a quantizer, using gradient-based optimizers. We claim that coupling a user-defined learning rate (LR) with these optimizers is sub-optimal for QAT. Quantized weights transit discrete levels of a quantizer, only if corresponding latent weights pass transition points, where the quantizer changes discrete states. This suggests that the changes of quantized weights are affected by both the LR for latent weights and their distributions. It is thus difficult to control the degree of changes for quantized weights by scheduling the LR manually. We conjecture that the degree of parameter changes in QAT is related to the number of quantized weights transiting discrete levels. Based on this, we introduce a transition rate (TR) scheduling technique that controls the number of transitions of quantized weights explicitly. Instead of scheduling a LR for latent weights, we schedule a target TR of quantized weights, and update the latent weights with a novel transition-adaptive LR (TALR), enabling considering the degree of changes for the quantized weights during QAT. Experimental results demonstrate the effectiveness of our approach on standard benchmarks.
Instance-Aware Group Quantization for Vision Transformers
Apr 01, 2024Post-training quantization (PTQ) is an efficient model compression technique that quantizes a pretrained full-precision model using only a small calibration set of unlabeled samples without retraining. PTQ methods for convolutional neural networks (CNNs) provide quantization results comparable to full-precision counterparts. Directly applying them to vision transformers (ViTs), however, incurs severe performance degradation, mainly due to the differences in architectures between CNNs and ViTs. In particular, the distribution of activations for each channel vary drastically according to input instances, making PTQ methods for CNNs inappropriate for ViTs. To address this, we introduce instance-aware group quantization for ViTs (IGQ-ViT). To this end, we propose to split the channels of activation maps into multiple groups dynamically for each input instance, such that activations within each group share similar statistical properties. We also extend our scheme to quantize softmax attentions across tokens. In addition, the number of groups for each layer is adjusted to minimize the discrepancies between predictions from quantized and full-precision models, under a bit-operation (BOP) constraint. We show extensive experimental results on image classification, object detection, and instance segmentation, with various transformer architectures, demonstrating the effectiveness of our approach.
AZ-NAS: Assembling Zero-Cost Proxies for Network Architecture Search
Mar 28, 2024



Training-free network architecture search (NAS) aims to discover high-performing networks with zero-cost proxies, capturing network characteristics related to the final performance. However, network rankings estimated by previous training-free NAS methods have shown weak correlations with the performance. To address this issue, we propose AZ-NAS, a novel approach that leverages the ensemble of various zero-cost proxies to enhance the correlation between a predicted ranking of networks and the ground truth substantially in terms of the performance. To achieve this, we introduce four novel zero-cost proxies that are complementary to each other, analyzing distinct traits of architectures in the views of expressivity, progressivity, trainability, and complexity. The proxy scores can be obtained simultaneously within a single forward and backward pass, making an overall NAS process highly efficient. In order to integrate the rankings predicted by our proxies effectively, we introduce a non-linear ranking aggregation method that highlights the networks highly-ranked consistently across all the proxies. Experimental results conclusively demonstrate the efficacy and efficiency of AZ-NAS, outperforming state-of-the-art methods on standard benchmarks, all while maintaining a reasonable runtime cost.
ACLS: Adaptive and Conditional Label Smoothing for Network Calibration
Aug 24, 2023



We address the problem of network calibration adjusting miscalibrated confidences of deep neural networks. Many approaches to network calibration adopt a regularization-based method that exploits a regularization term to smooth the miscalibrated confidences. Although these approaches have shown the effectiveness on calibrating the networks, there is still a lack of understanding on the underlying principles of regularization in terms of network calibration. We present in this paper an in-depth analysis of existing regularization-based methods, providing a better understanding on how they affect to network calibration. Specifically, we have observed that 1) the regularization-based methods can be interpreted as variants of label smoothing, and 2) they do not always behave desirably. Based on the analysis, we introduce a novel loss function, dubbed ACLS, that unifies the merits of existing regularization methods, while avoiding the limitations. We show extensive experimental results for image classification and semantic segmentation on standard benchmarks, including CIFAR10, Tiny-ImageNet, ImageNet, and PASCAL VOC, demonstrating the effectiveness of our loss function.
RankMixup: Ranking-Based Mixup Training for Network Calibration
Aug 23, 2023



Network calibration aims to accurately estimate the level of confidences, which is particularly important for employing deep neural networks in real-world systems. Recent approaches leverage mixup to calibrate the network's predictions during training. However, they do not consider the problem that mixtures of labels in mixup may not accurately represent the actual distribution of augmented samples. In this paper, we present RankMixup, a novel mixup-based framework alleviating the problem of the mixture of labels for network calibration. To this end, we propose to use an ordinal ranking relationship between raw and mixup-augmented samples as an alternative supervisory signal to the label mixtures for network calibration. We hypothesize that the network should estimate a higher level of confidence for the raw samples than the augmented ones (Fig.1). To implement this idea, we introduce a mixup-based ranking loss (MRL) that encourages lower confidences for augmented samples compared to raw ones, maintaining the ranking relationship. We also propose to leverage the ranking relationship among multiple mixup-augmented samples to further improve the calibration capability. Augmented samples with larger mixing coefficients are expected to have higher confidences and vice versa (Fig.1). That is, the order of confidences should be aligned with that of mixing coefficients. To this end, we introduce a novel loss, M-NDCG, in order to reduce the number of misaligned pairs of the coefficients and confidences. Extensive experimental results on standard benchmarks for network calibration demonstrate the effectiveness of RankMixup.
Camera-Driven Representation Learning for Unsupervised Domain Adaptive Person Re-identification
Aug 23, 2023



We present a novel unsupervised domain adaption method for person re-identification (reID) that generalizes a model trained on a labeled source domain to an unlabeled target domain. We introduce a camera-driven curriculum learning (CaCL) framework that leverages camera labels of person images to transfer knowledge from source to target domains progressively. To this end, we divide target domain dataset into multiple subsets based on the camera labels, and initially train our model with a single subset (i.e., images captured by a single camera). We then gradually exploit more subsets for training, according to a curriculum sequence obtained with a camera-driven scheduling rule. The scheduler considers maximum mean discrepancies (MMD) between each subset and the source domain dataset, such that the subset closer to the source domain is exploited earlier within the curriculum. For each curriculum sequence, we generate pseudo labels of person images in a target domain to train a reID model in a supervised way. We have observed that the pseudo labels are highly biased toward cameras, suggesting that person images obtained from the same camera are likely to have the same pseudo labels, even for different IDs. To address the camera bias problem, we also introduce a camera-diversity (CD) loss encouraging person images of the same pseudo label, but captured across various cameras, to involve more for discriminative feature learning, providing person representations robust to inter-camera variations. Experimental results on standard benchmarks, including real-to-real and synthetic-to-real scenarios, demonstrate the effectiveness of our framework.
ALIFE: Adaptive Logit Regularizer and Feature Replay for Incremental Semantic Segmentation
Oct 13, 2022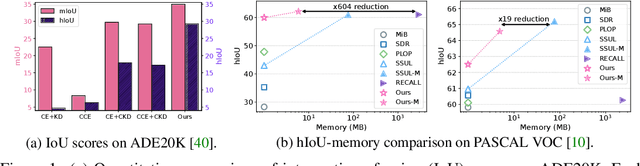
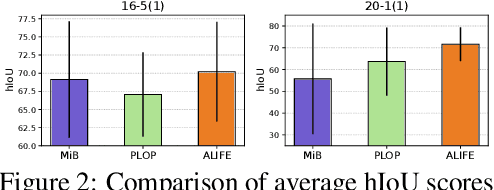
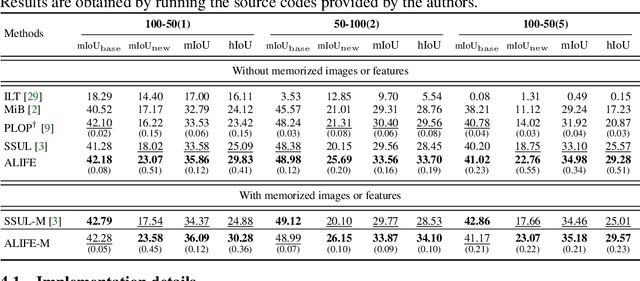
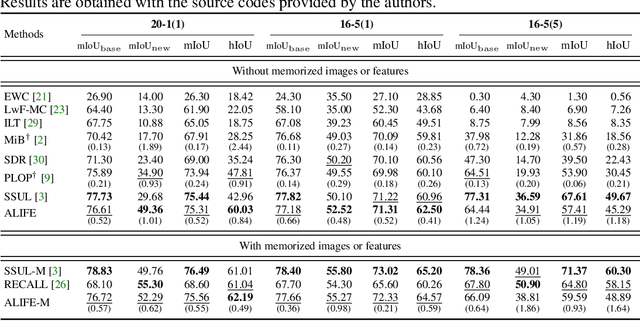
We address the problem of incremental semantic segmentation (ISS) recognizing novel object/stuff categories continually without forgetting previous ones that have been learned. The catastrophic forgetting problem is particularly severe in ISS, since pixel-level ground-truth labels are available only for the novel categories at training time. To address the problem, regularization-based methods exploit probability calibration techniques to learn semantic information from unlabeled pixels. While such techniques are effective, there is still a lack of theoretical understanding of them. Replay-based methods propose to memorize a small set of images for previous categories. They achieve state-of-the-art performance at the cost of large memory footprint. We propose in this paper a novel ISS method, dubbed ALIFE, that provides a better compromise between accuracy and efficiency. To this end, we first show an in-depth analysis on the calibration techniques to better understand the effects on ISS. Based on this, we then introduce an adaptive logit regularizer (ALI) that enables our model to better learn new categories, while retaining knowledge for previous ones. We also present a feature replay scheme that memorizes features, instead of images directly, in order to reduce memory requirements significantly. Since a feature extractor is changed continually, memorized features should also be updated at every incremental stage. To handle this, we introduce category-specific rotation matrices updating the features for each category separately. We demonstrate the effectiveness of our approach with extensive experiments on standard ISS benchmarks, and show that our method achieves a better trade-off in terms of accuracy and efficiency.
Decomposed Knowledge Distillation for Class-Incremental Semantic Segmentation
Oct 12, 2022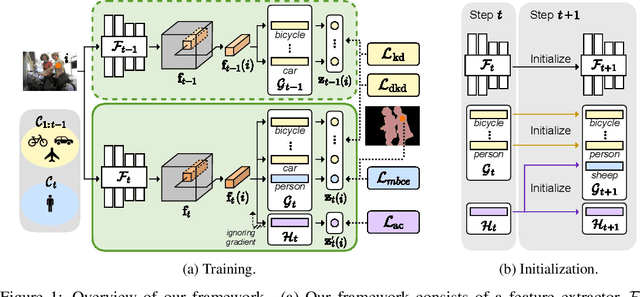
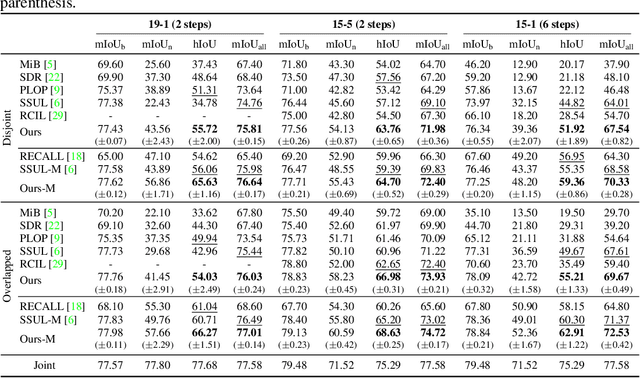
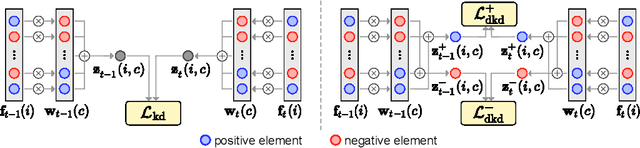
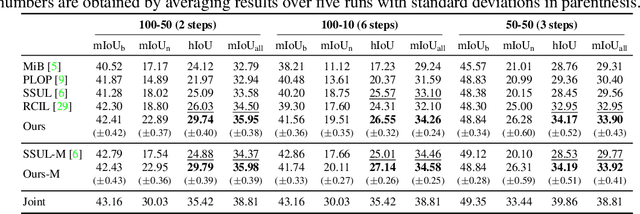
Class-incremental semantic segmentation (CISS) labels each pixel of an image with a corresponding object/stuff class continually. To this end, it is crucial to learn novel classes incrementally without forgetting previously learned knowledge. Current CISS methods typically use a knowledge distillation (KD) technique for preserving classifier logits, or freeze a feature extractor, to avoid the forgetting problem. The strong constraints, however, prevent learning discriminative features for novel classes. We introduce a CISS framework that alleviates the forgetting problem and facilitates learning novel classes effectively. We have found that a logit can be decomposed into two terms. They quantify how likely an input belongs to a particular class or not, providing a clue for a reasoning process of a model. The KD technique, in this context, preserves the sum of two terms (i.e., a class logit), suggesting that each could be changed and thus the KD does not imitate the reasoning process. To impose constraints on each term explicitly, we propose a new decomposed knowledge distillation (DKD) technique, improving the rigidity of a model and addressing the forgetting problem more effectively. We also introduce a novel initialization method to train new classifiers for novel classes. In CISS, the number of negative training samples for novel classes is not sufficient to discriminate old classes. To mitigate this, we propose to transfer knowledge of negatives to the classifiers successively using an auxiliary classifier, boosting the performance significantly. Experimental results on standard CISS benchmarks demonstrate the effectiveness of our framework.