 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascadeML: An Automatic Neural Network Architecture Evolution and Training Algorithm for Multi-label Classification
Apr 23, 2019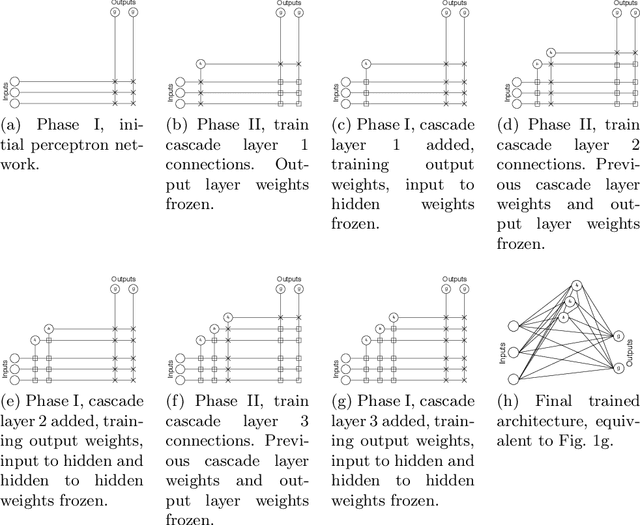
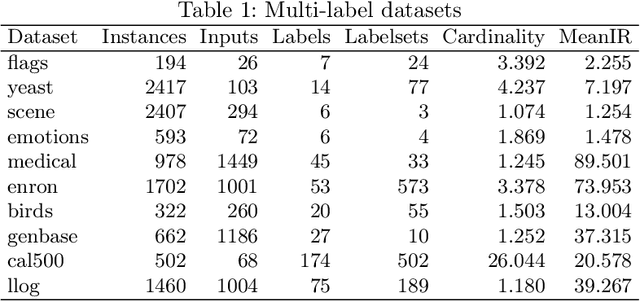

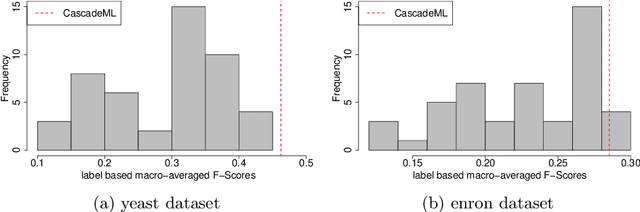
Multi-label classification is an approach which allows a datapoint to be labelled with more than one class at the same time. A common but trivial approach is to train individual binary classifiers per label, but the performance can be improved by considering associations within the labels. Like with any machine learning algorithm, hyperparameter tuning is important to train a good multi-label classifier model. The task of selecting the best hyperparameter settings for an algorithm is an optimisation problem. Very limited work has been done on automatic hyperparameter tuning and AutoML in the multi-label domain. This paper attempts to fill this gap by proposing a neural network algorithm, CascadeML, to train multi-label neural network based on cascade neural networks. This method requires minimal or no hyperparameter tuning and also considers pairwise label associations. The cascade algorithm grows the network architecture incrementally in a two phase process as it learns the weights using adaptive first order gradient algorithm, therefore omitting the requirement of preselecting the number of hidden layers, nodes and the learning rate. The method was tested on 10 multi-label datasets and compared with other multi-label classification algorithms. Results show that CascadeML performs very well without hyperparameter tuning.
A Categorisation of Post-hoc Explanations for Predictive Models
Apr 04, 2019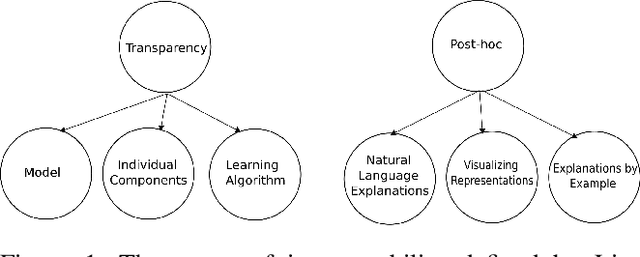
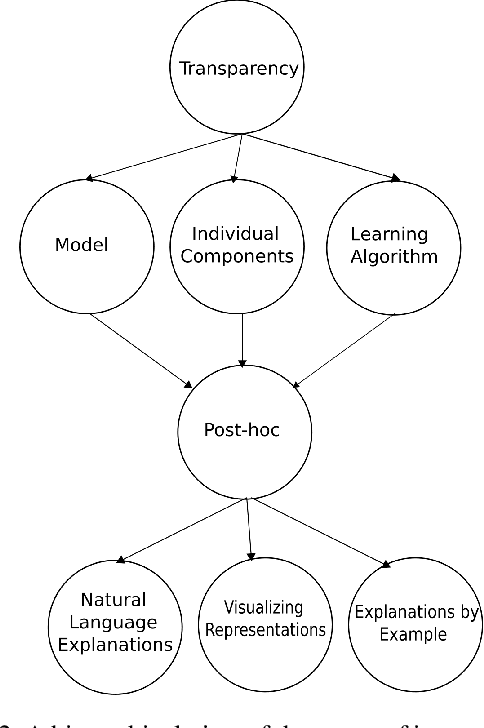
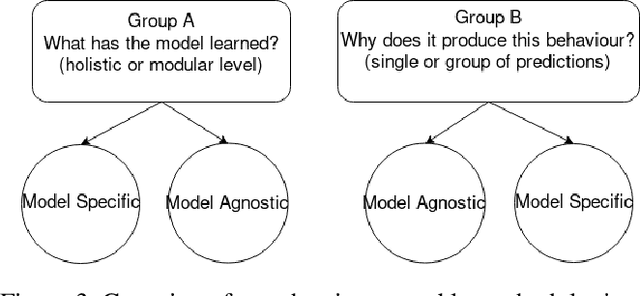
The ubiquity of machine learning based predictive models in modern society naturally leads people to ask how trustworthy those models are? In predictive modeling, it is quite common to induce a trade-off between accuracy and interpretability. For instance, doctors would like to know how effective some treatment will be for a patient or why the model suggested a particular medication for a patient exhibiting those symptoms? We acknowledge that the necessity for interpretability is a consequence of an incomplete formalisation of the problem, or more precisely of multiple meanings adhered to a particular concept. For certain problems, it is not enough to get the answer (what), the model also has to provide an explanation of how it came to that conclusion (why), because a correct prediction, only partially solves the original problem. In this article we extend existing categorisation of techniques to aid model interpretability and test this categorisation.
Kalman Filter-based Heuristic Ensemble : A New Perspective on Multi-class Ensemble Classification Using Kalman Filters
Sep 29, 2018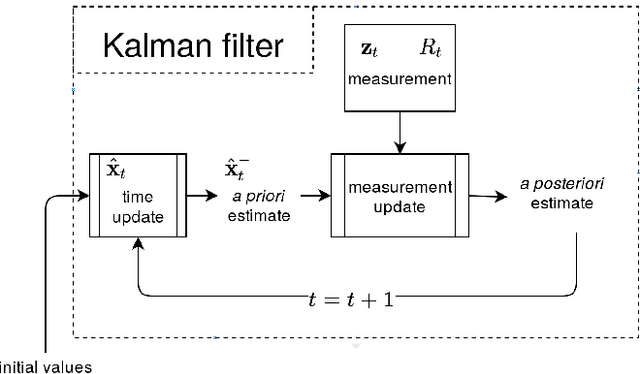
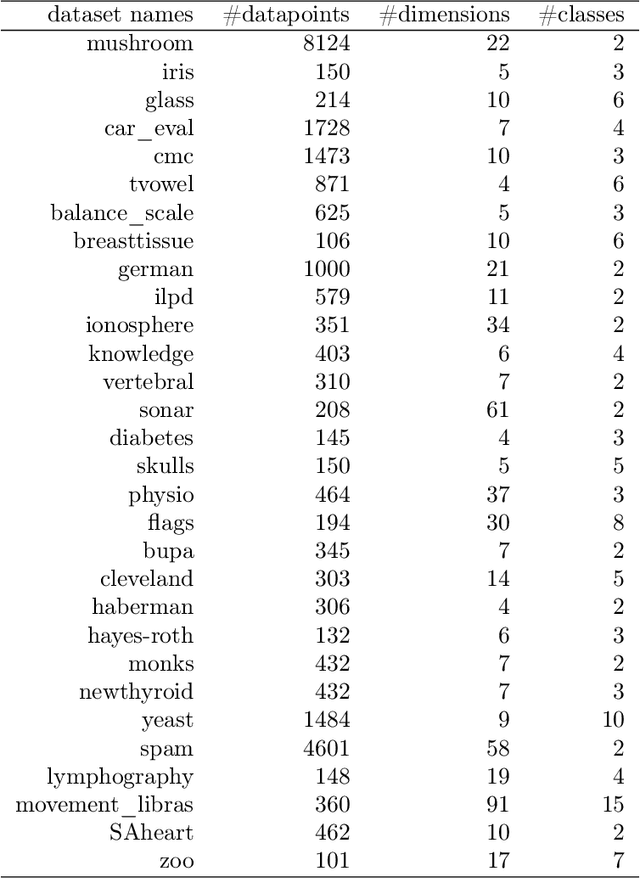
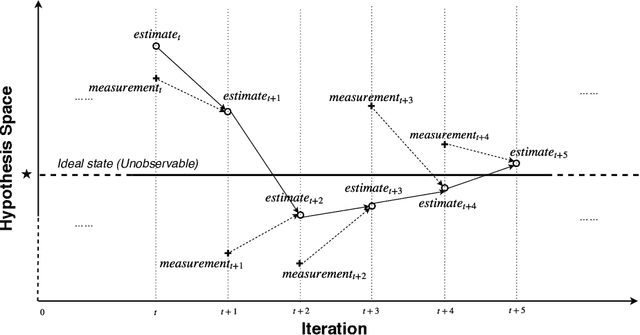
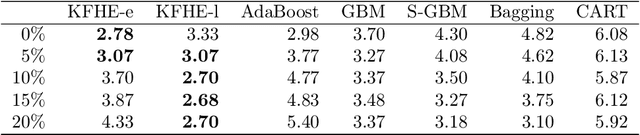
A classifier ensemble is a combination of multiple diverse classifier models whose outputs are aggregated into a single prediction. Ensembles have been repeatedly shown to perform better than single classifier models, however, existing approaches trade off performance and robustness to class label noise. The objective of this paper is to first introduce a new perspective on multi-class ensemble classification by considering the training of the ensemble as a state estimation problem. The new perspective considers the final ensemble classifier model as a static state, which can be estimated using a Kalman filter that combines noisy estimates made by individual classifier models. A new algorithm based on this perspective, Kalman Filter-based Heuristic Ensemble (KFHE), is also presented in this paper which shows the practical applicability of the new perspective. Experiments performed on 30 real-life datasets, comparing KFHE with state-of-the-art multi-class ensemble classification algorithms uncover the potential and effectiveness of the proposed new perspective and algorithm. KFHE is shown to be significantly better or at least as good as the state-of-the-art algorithms for datasets both with and without class label noise.
Deep learning at the shallow end: Malware classification for non-domain experts
Jul 22, 2018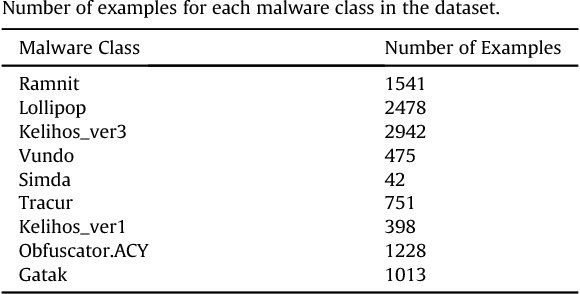
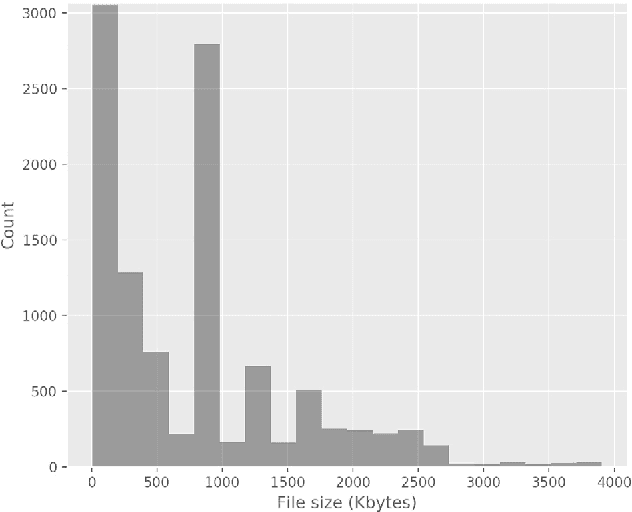

Current malware detection and classification approaches generally rely on time consuming and knowledge intensive processes to extract patterns (signatures) and behaviors from malware, which are then used for identification. Moreover, these signatures are often limited to local, contiguous sequences within the data whilst ignoring their context in relation to each other and throughout the malware file as a whole. We present a Deep Learning based malware classification approach that requires no expert domain knowledge and is based on a purely data driven approach for complex pattern and feature identification.
Stability of Topic Modeling via Matrix Factorization
Sep 09, 2017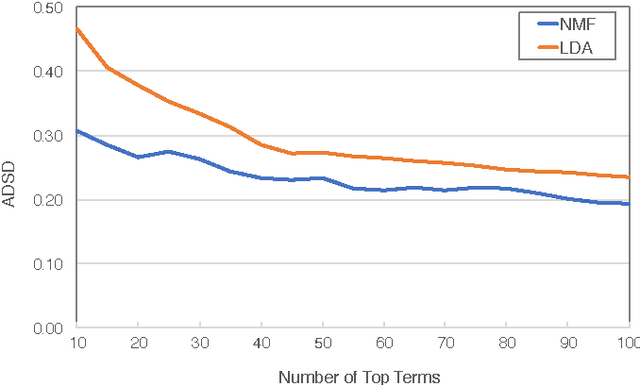

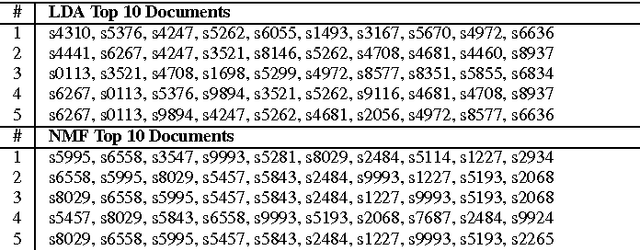
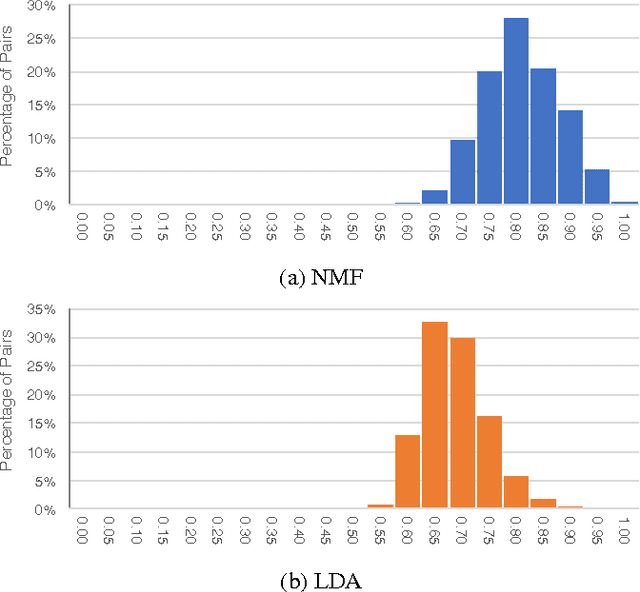
Topic models can provide us with an insight into the underlying latent structure of a large corpus of documents. A range of methods have been proposed in the literature, including probabilistic topic models and techniques based on matrix factorization. However, in both cases, standard implementations rely on stochastic elements in their initialization phase, which can potentially lead to different results being generated on the same corpus when using the same parameter values. This corresponds to the concept of "instability" which has previously been studied in the context of $k$-means clustering. In many applications of topic modeling, this problem of instability is not considered and topic models are treated as being definitive, even though the results may change considerably if the initialization process is altered. In this paper we demonstrate the inherent instability of popular topic modeling approaches, using a number of new measures to assess stability. To address this issue in the context of matrix factorization for topic modeling, we propose the use of ensemble learning strategies. Based on experiments performed on annotated text corpora, we show that a K-Fold ensemble strategy, combining both ensembles and structured initialization, can significantly reduce instability, while simultaneously yielding more accurate topic models.