 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent Features for Rich Natural Language Understanding
Apr 21, 2021
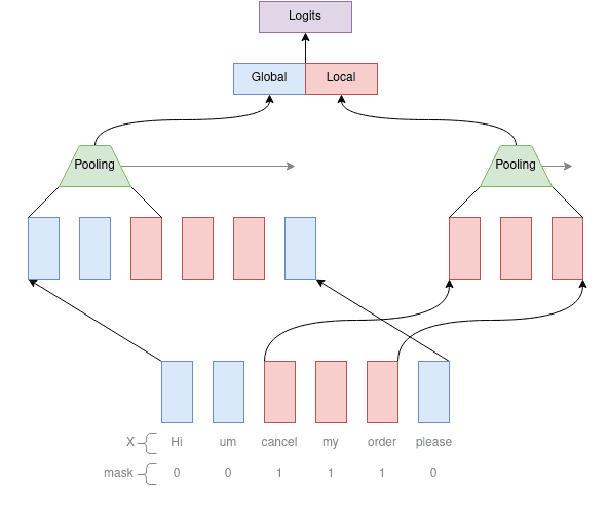

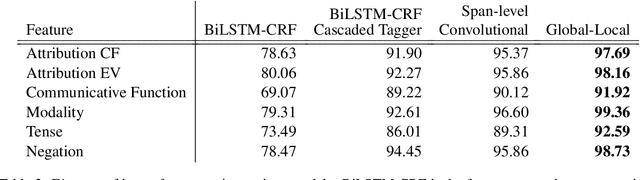
Complex natural language understanding modules in dialog systems have a richer understanding of user utterances, and thus are critical in providing a better user experience. However, these models are often created from scratch, for specific clients and use cases, and require the annotation of large datasets. This encourages the sharing of annotated data across multiple clients. To facilitate this we introduce the idea of intent features: domain and topic agnostic properties of intents that can be learned from the syntactic cues only, and hence can be shared. We introduce a new neural network architecture, the Global-Local model, that shows significant improvement over strong baselines for identifying these features in a deployed, multi-intent natural language understanding module, and, more generally, in a classification setting where a part of an utterance has to be classified utilizing the whole context.
The Power of Scale for Parameter-Efficient Prompt Tuning
Apr 18, 2021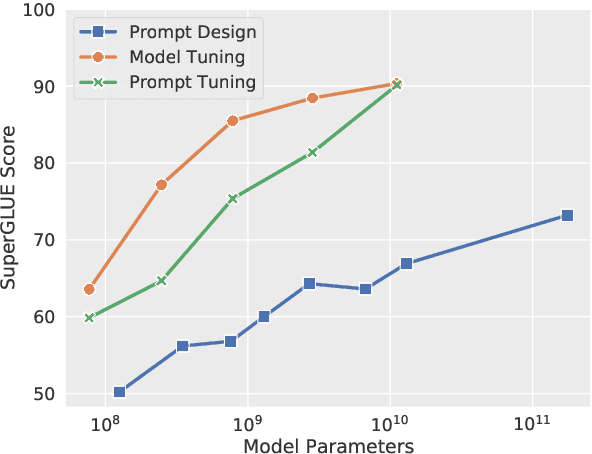
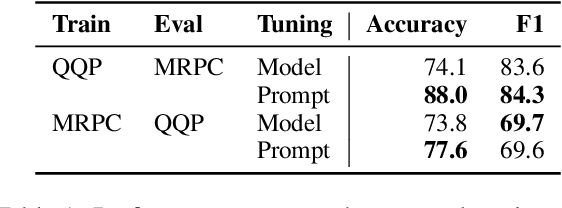
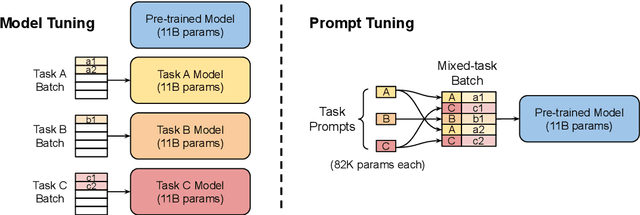
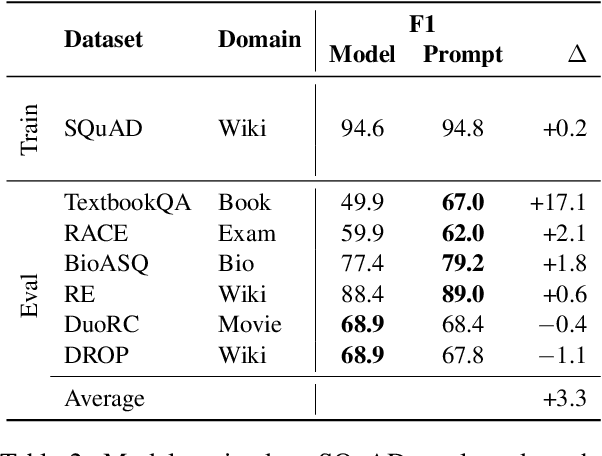
In this work, we explore "prompt tuning", a simple yet effective mechanism for learning "soft prompts" to condition frozen language models to perform specific downstream tasks. Unlike the discrete text prompts used by GPT-3, soft prompts are learned through backpropagation and can be tuned to incorporate signal from any number of labeled examples. Our end-to-end learned approach outperforms GPT-3's "few-shot" learning by a large margin. More remarkably, through ablations on model size using T5, we show that prompt tuning becomes more competitive with scale: as models exceed billions of parameters, our method "closes the gap" and matches the strong performance of model tuning (where all model weights are tuned). This finding is especially relevant in that large models are costly to share and serve, and the ability to reuse one frozen model for multiple downstream tasks can ease this burden. Our method can be seen as a simplification of the recently proposed "prefix tuning" of Li and Liang (2021), and we provide a comparison to this and other similar approaches. Finally, we show that conditioning a frozen model with soft prompts confers benefits in robustness to domain transfer, as compared to full model tuning.
iobes: A Library for Span-Level Processing
Oct 09, 2020
Many tasks in natural language processing, such as named entity recognition and slot-filling, involve identifying and labeling specific spans of text. In order to leverage common models, these tasks are often recast as sequence labeling tasks. Each token is given a label and these labels are prefixed with special tokens such as B- or I-. After a model assigns labels to each token, these prefixes are used to group the tokens into spans. Properly parsing these annotations is critical for producing fair and comparable metrics; however, despite its importance, there is not an easy-to-use, standardized, programmatically integratable library to help work with span labeling. To remedy this, we introduce our open-source library, iobes. iobes is used for parsing, converting, and processing spans represented as token level decisions.
Leader: Prefixing a Length for Faster Word Vector Serialization
Oct 09, 2020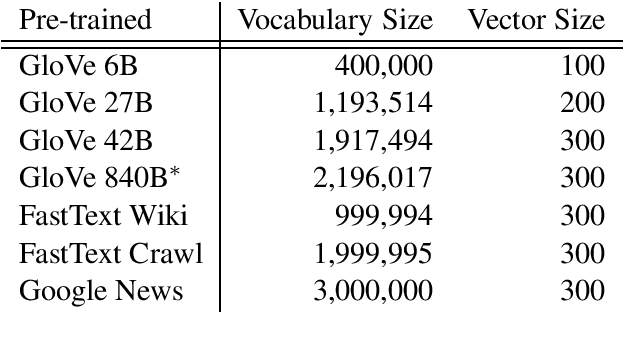

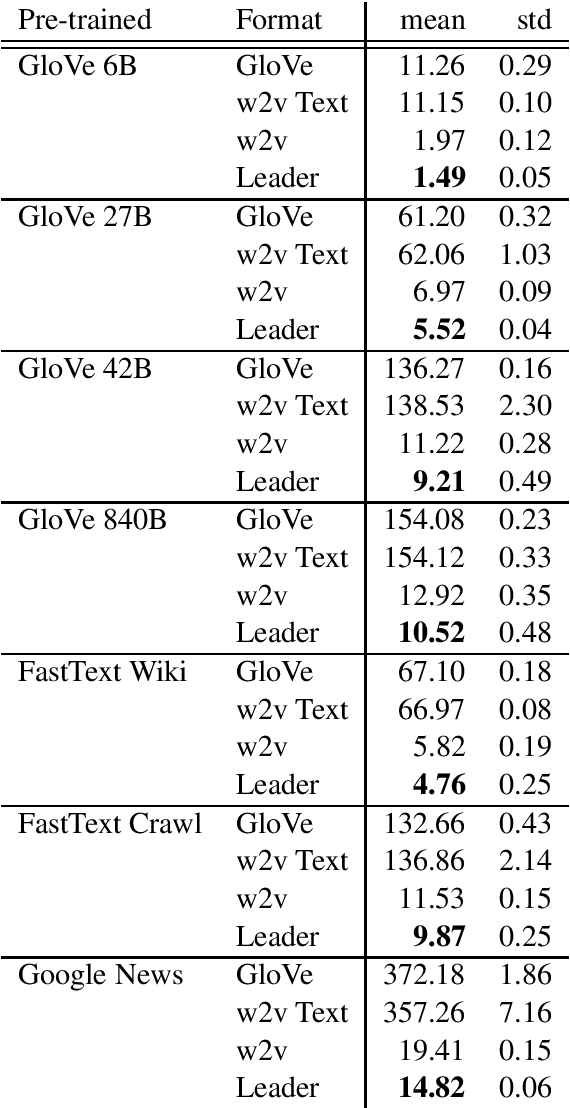
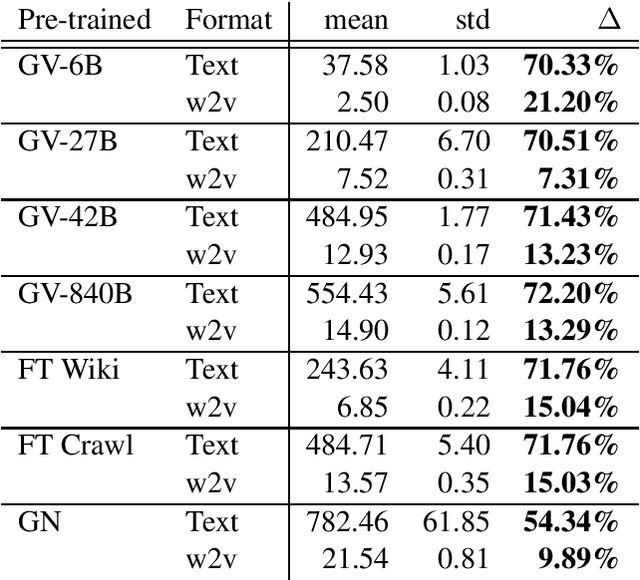
Two competing file formats have become the de facto standards for distributing pre-trained word embeddings. Both are named after the most popular pre-trained embeddings that are distributed in that format. The GloVe format is an entirely text based format that suffers from huge file sizes and slow reads, and the word2vec format is a smaller binary format that mixes a textual representation of words with a binary representation of the vectors themselves. Both formats have problems that we solve with a new format we call the Leader format. We include a word length prefix for faster reads while maintaining the smaller file size a binary format offers. We also created a minimalist library to facilitate the reading and writing of various word vector formats, as well as tools for converting pre-trained embeddings to our new Leader format.
Multiple Word Embeddings for Increased Diversity of Representation
Oct 09, 2020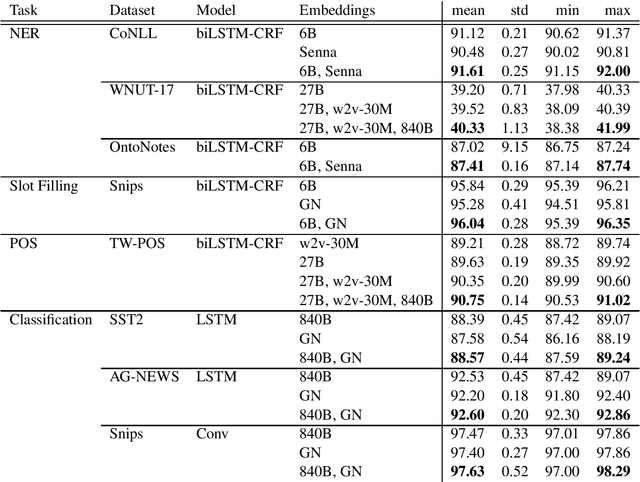

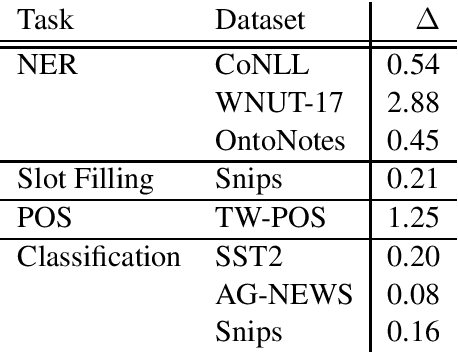
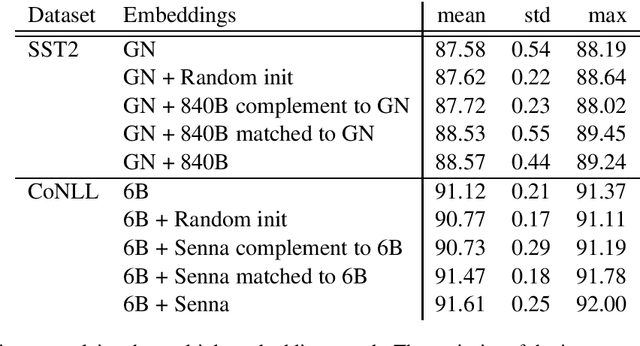
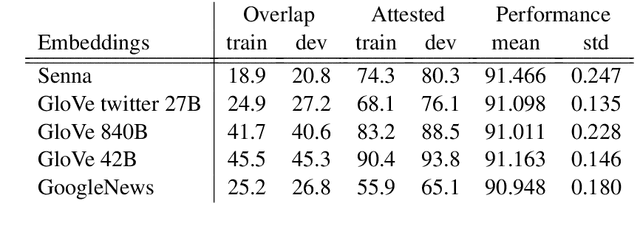
Most state-of-the-art models in natural language processing (NLP) are neural models built on top of large, pre-trained, contextual language models that generate representations of words in context and are fine-tuned for the task at hand. The improvements afforded by these "contextual embeddings" come with a high computational cost. In this work, we explore a simple technique that substantially and consistently improves performance over a strong baseline with negligible increase in run time. We concatenate multiple pre-trained embeddings to strengthen our representation of words. We show that this concatenation technique works across many tasks, datasets, and model types. We analyze aspects of pre-trained embedding similarity and vocabulary coverage and find that the representational diversity between different pre-trained embeddings is the driving force of why this technique works. We provide open source implementations of our models in both TensorFlow and PyTorch.
Constrained Decoding for Computationally Efficient Named Entity Recognition Taggers
Oct 09, 2020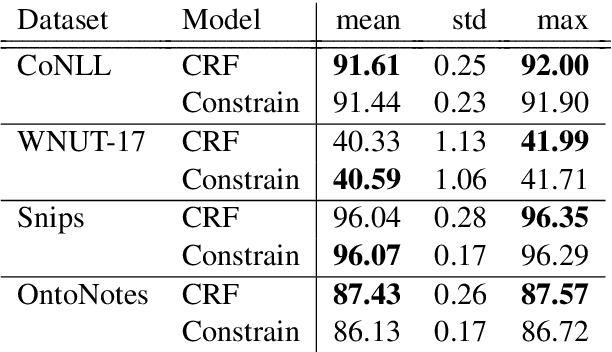
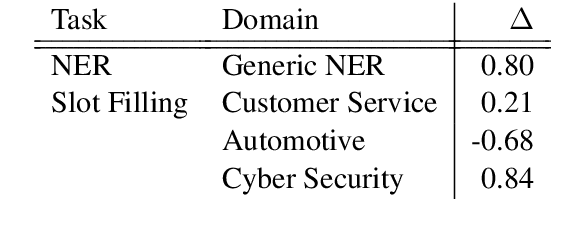

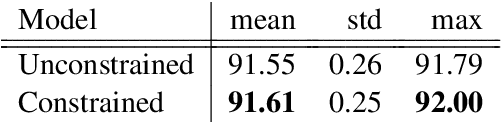
Current state-of-the-art models for named entity recognition (NER) are neural models with a conditional random field (CRF) as the final layer. Entities are represented as per-token labels with a special structure in order to decode them into spans. Current work eschews prior knowledge of how the span encoding scheme works and relies on the CRF learning which transitions are illegal and which are not to facilitate global coherence. We find that by constraining the output to suppress illegal transitions we can train a tagger with a cross-entropy loss twice as fast as a CRF with differences in F1 that are statistically insignificant, effectively eliminating the need for a CRF. We analyze the dynamics of tag co-occurrence to explain when these constraints are most effective and provide open source implementations of our tagger in both PyTorch and TensorFlow.
Computationally Efficient NER Taggers with Combined Embeddings and Constrained Decoding
Jan 05, 2020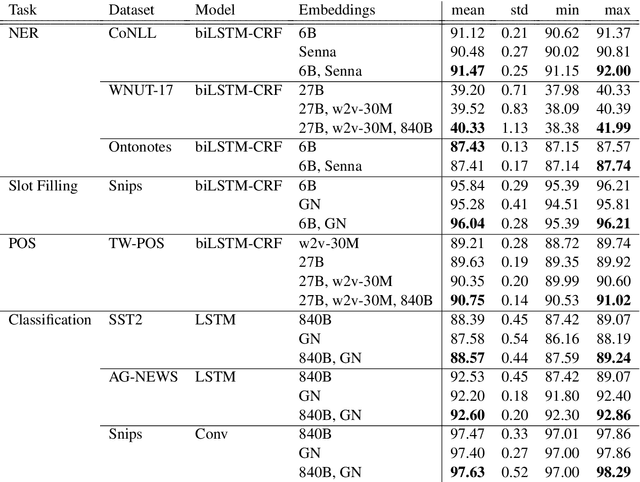
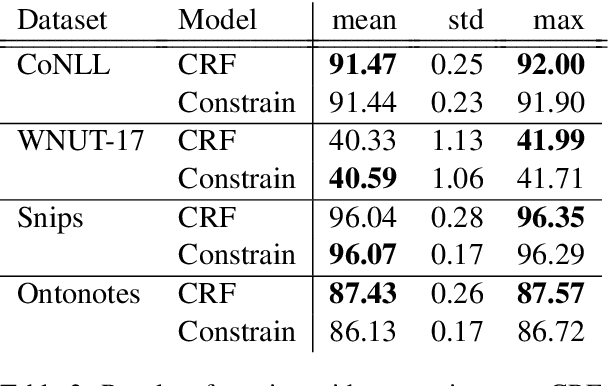
Current State-of-the-Art models in Named Entity Recognition (NER) are neural models with a Conditional Random Field (CRF) as the final network layer, and pre-trained "contextual embeddings". The CRF layer is used to facilitate global coherence between labels, and the contextual embeddings provide a better representation of words in context. However, both of these improvements come at a high computational cost. In this work, we explore two simple techniques that substantially improve NER performance over a strong baseline with negligible cost. First, we use multiple pre-trained embeddings as word representations via concatenation. Second, we constrain the tagger, trained using a cross-entropy loss, during decoding to eliminate illegal transitions. While training a tagger on CoNLL 2003 we find a $786$\% speed-up over a contextual embeddings-based tagger without sacrificing strong performance. We also show that the concatenation technique works across multiple tasks and datasets. We analyze aspects of similarity and coverage between pre-trained embeddings and the dynamics of tag co-occurrence to explain why these techniques work. We provide an open source implementation of our tagger using these techniques in three popular deep learning frameworks --- TensorFlow, Pytorch, and DyNet.
An Effective Label Noise Model for DNN Text Classification
Mar 18, 2019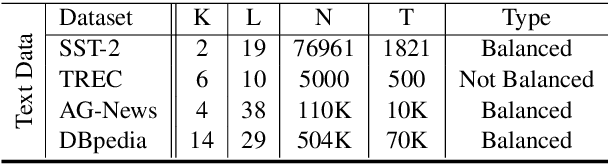
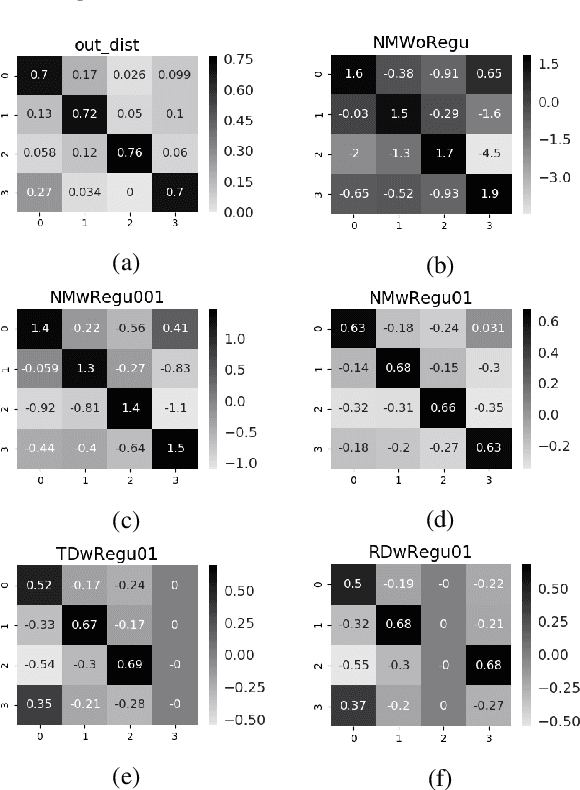
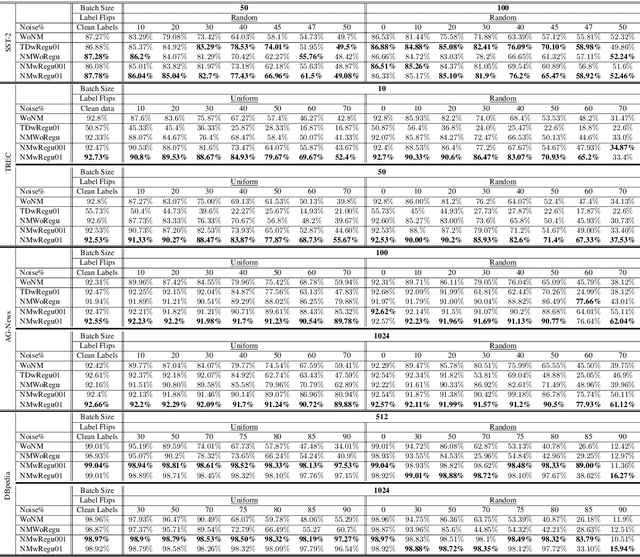
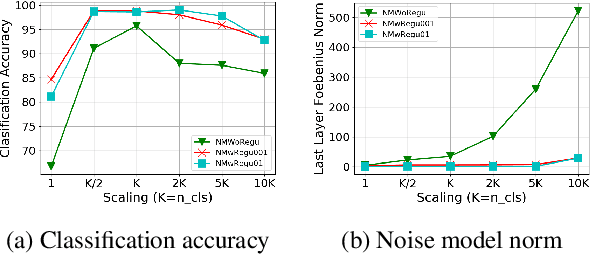
Because large, human-annotated datasets suffer from labeling errors, it is crucial to be able to train deep neural networks in the presence of label noise. While training image classification models with label noise have received much attention, training text classification models have not. In this paper, we propose an approach to training deep networks that is robust to label noise. This approach introduces a non-linear processing layer (noise model) that models the statistics of the label noise into a convolutional neural network (CNN) architecture. The noise model and the CNN weights are learned jointly from noisy training data, which prevents the model from overfitting to erroneous labels. Through extensive experiments on several text classification datasets, we show that this approach enables the CNN to learn better sentence representations and is robust even to extreme label noise. We find that proper initialization and regularization of this noise model is critical. Further, by contrast to results focusing on large batch sizes for mitigating label noise for image classification, we find that altering the batch size does not have much effect on classification performance.