 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrian Kingsbury
Distributed Deep Learning Strategies For Automatic Speech Recognition
Apr 10, 2019
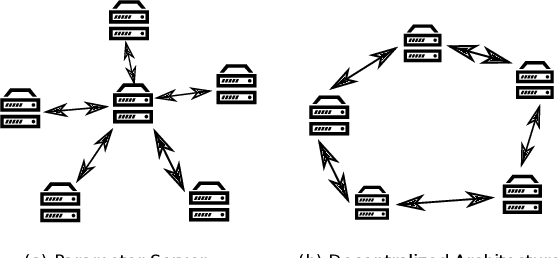
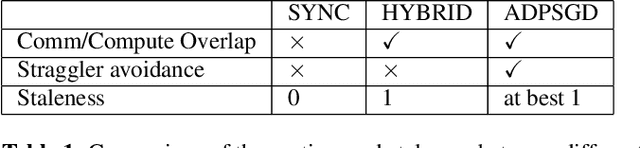
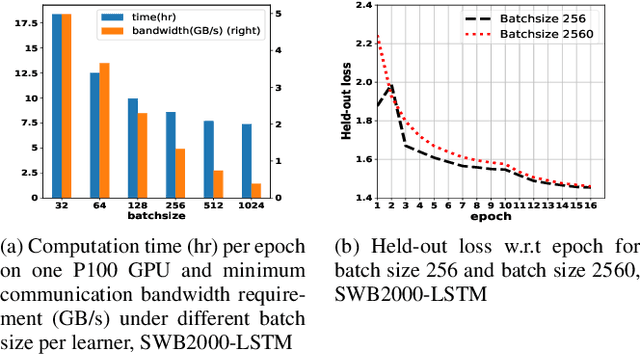
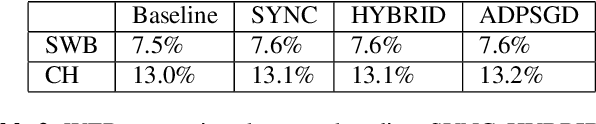
In this paper, we propose and investigate a variety of distributed deep learning strategies for automatic speech recognition (ASR) and evaluate them with a state-of-the-art Long short-term memory (LSTM) acoustic model on the 2000-hour Switchboard (SWB2000), which is one of the most widely used datasets for ASR performance benchmark. We first investigate what are the proper hyper-parameters (e.g., learning rate) to enable the training with sufficiently large batch size without impairing the model accuracy. We then implement various distributed strategies, including Synchronous (SYNC), Asynchronous Decentralized Parallel SGD (ADPSGD) and the hybrid of the two HYBRID, to study their runtime/accuracy trade-off. We show that we can train the LSTM model using ADPSGD in 14 hours with 16 NVIDIA P100 GPUs to reach a 7.6% WER on the Hub5- 2000 Switchboard (SWB) test set and a 13.1% WER on the CallHome (CH) test set. Furthermore, we can train the model using HYBRID in 11.5 hours with 32 NVIDIA V100 GPUs without loss in accuracy.
Understanding Unequal Gender Classification Accuracy from Face Images
Nov 30, 2018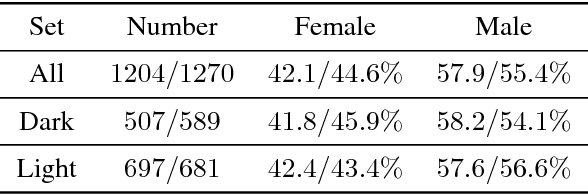
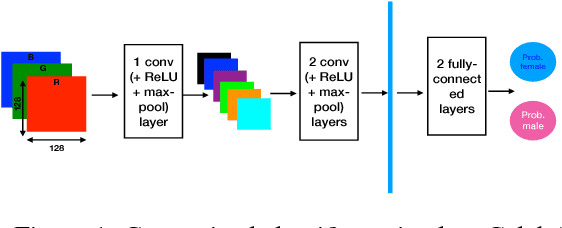
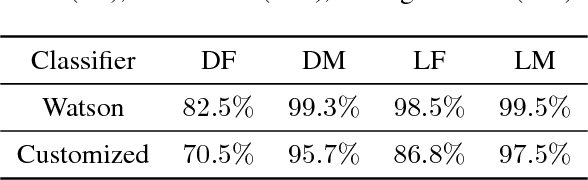
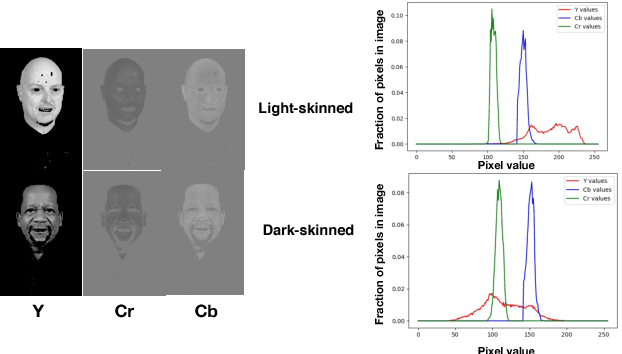
Recent work shows unequal performance of commercial face classification services in the gender classification task across intersectional groups defined by skin type and gender. Accuracy on dark-skinned females is significantly worse than on any other group. In this paper, we conduct several analyses to try to uncover the reason for this gap. The main finding, perhaps surprisingly, is that skin type is not the driver. This conclusion is reached via stability experiments that vary an image's skin type via color-theoretic methods, namely luminance mode-shift and optimal transport. A second suspect, hair length, is also shown not to be the driver via experiments on face images cropped to exclude the hair. Finally, using contrastive post-hoc explanation techniques for neural networks, we bring forth evidence suggesting that differences in lip, eye and cheek structure across ethnicity lead to the differences. Further, lip and eye makeup are seen as strong predictors for a female face, which is a troubling propagation of a gender stereotype.
Beyond Backprop: Online Alternating Minimization with Auxiliary Variables
Oct 24, 2018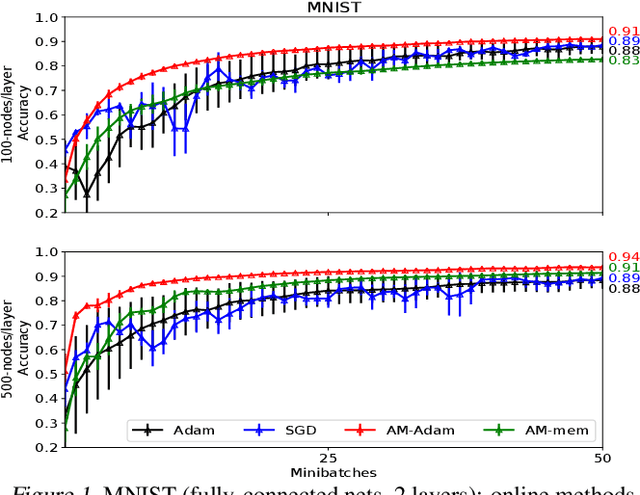
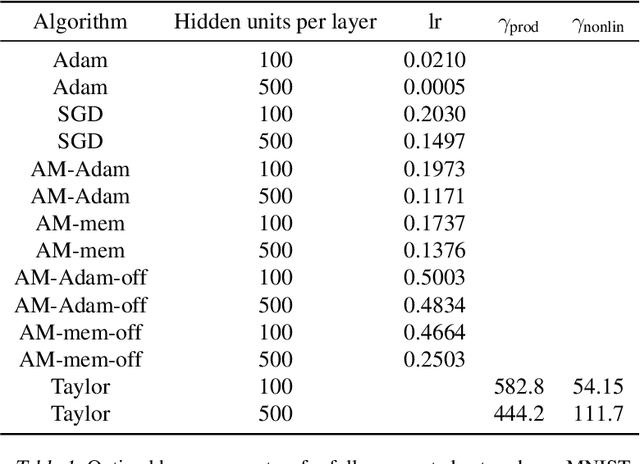
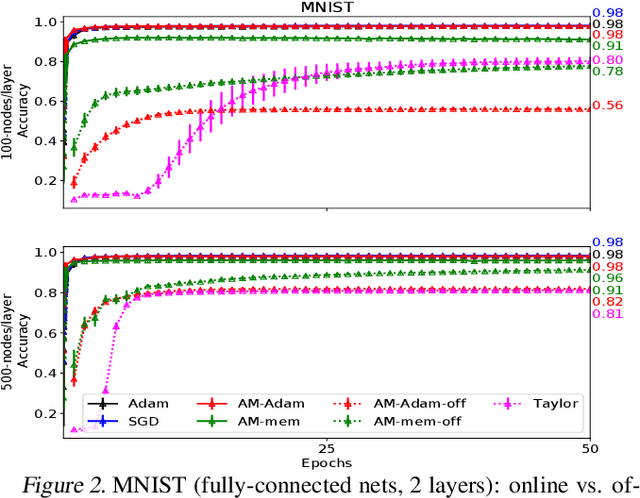
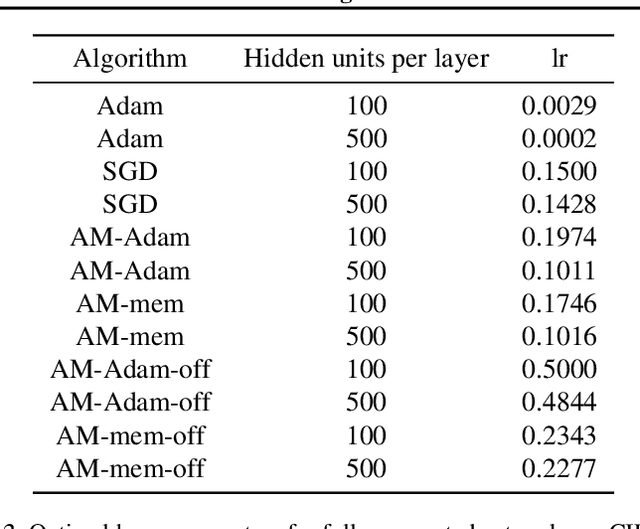
We propose a novel online alternating minimization (AltMin) algorithm for training deep neural networks, provide theoretical convergence guarantees and demonstrate its advantages on several classification tasks as compared both to standard backpropagation with stochastic gradient descent (backprop-SGD) and to offline alternating minimization. The key difference from backpropagation is an explicit optimization over hidden activations, which eliminates gradient chain computation in backprop, and breaks the weight training problem into independent, local optimization subproblems; this allows to avoid vanishing gradient issues, simplify handling non-differentiable nonlinearities, and perform parallel weight updates across the layers. Moreover, parallel local synaptic weight optimization with explicit activation propagation is a step closer to a more biologically plausible learning model than backpropagation, whose biological implausibility has been frequently criticized. Finally, the online nature of our approach allows to handle very large datasets, as well as continual, lifelong learning, which is our key contribution on top of recently proposed offline alternating minimization schemes (e.g., (Carreira-Perpinan andWang 2014), (Taylor et al. 2016)).
Estimating Information Flow in Neural Networks
Oct 16, 2018
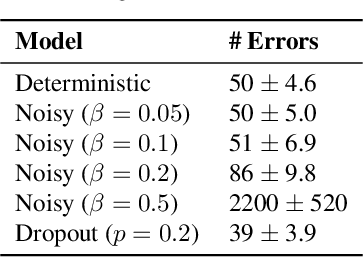
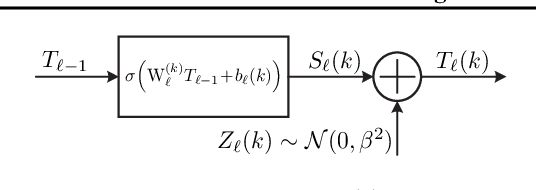
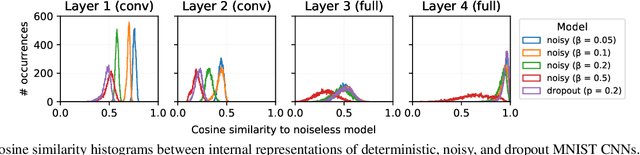
We study the flow of information and the evolution of internal representations during deep neural network (DNN) training, aiming to demystify the compression aspect of the information bottleneck theory. The theory suggests that DNN training comprises a rapid fitting phase followed by a slower compression phase, in which the mutual information $I(X;T)$ between the input $X$ and internal representations $T$ decreases. Several papers observe compression of estimated mutual information on different DNN models, but the true $I(X;T)$ over these networks is provably either constant (discrete $X$) or infinite (continuous $X$). This work explains the discrepancy between theory and experiments, and clarifies what was actually measured by these past works. To this end, we introduce an auxiliary (noisy) DNN framework for which $I(X;T)$ is a meaningful quantity that depends on the network's parameters. This noisy framework is shown to be a good proxy for the original (deterministic) DNN both in terms of performance and the learned representations. We then develop a rigorous estimator for $I(X;T)$ in noisy DNNs and observe compression in various models. By relating $I(X;T)$ in the noisy DNN to an information-theoretic communication problem, we show that compression is driven by the progressive clustering of hidden representations of inputs from the same class. Several methods to directly monitor clustering of hidden representations, both in noisy and deterministic DNNs, are used to show that meaningful clusters form in the $T$ space. Finally, we return to the estimator of $I(X;T)$ employed in past works, and demonstrate that while it fails to capture the true (vacuous) mutual information, it does serve as a measure for clustering. This clarifies the past observations of compression and isolates the geometric clustering of hidden representations as the true phenomenon of interest.
Building competitive direct acoustics-to-word models for English conversational speech recognition
Dec 08, 2017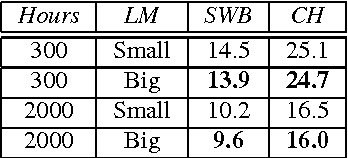
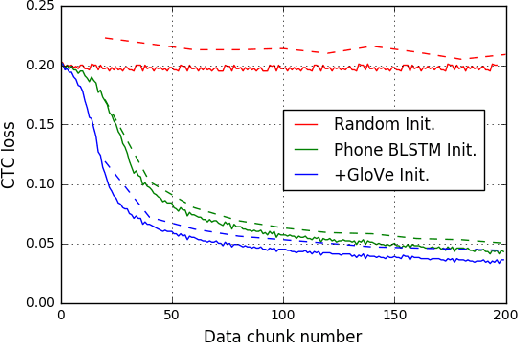
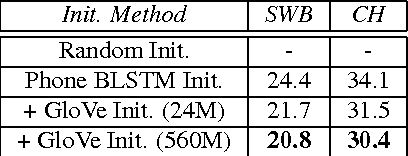
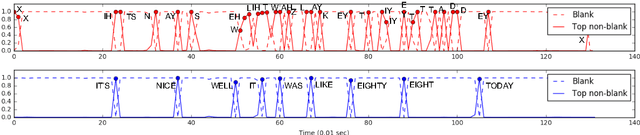
Direct acoustics-to-word (A2W) models in the end-to-end paradigm have received increasing attention compared to conventional sub-word based automatic speech recognition models using phones, characters, or context-dependent hidden Markov model states. This is because A2W models recognize words from speech without any decoder, pronunciation lexicon, or externally-trained language model, making training and decoding with such models simple. Prior work has shown that A2W models require orders of magnitude more training data in order to perform comparably to conventional models. Our work also showed this accuracy gap when using the English Switchboard-Fisher data set. This paper describes a recipe to train an A2W model that closes this gap and is at-par with state-of-the-art sub-word based models. We achieve a word error rate of 8.8%/13.9% on the Hub5-2000 Switchboard/CallHome test sets without any decoder or language model. We find that model initialization, training data order, and regularization have the most impact on the A2W model performance. Next, we present a joint word-character A2W model that learns to first spell the word and then recognize it. This model provides a rich output to the user instead of simple word hypotheses, making it especially useful in the case of words unseen or rarely-seen during training.
End-to-End ASR-free Keyword Search from Speech
Jan 13, 2017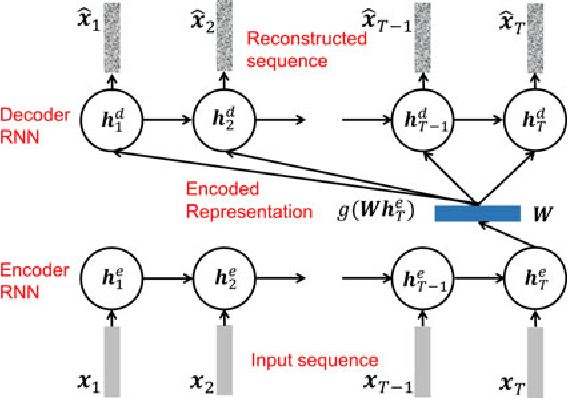
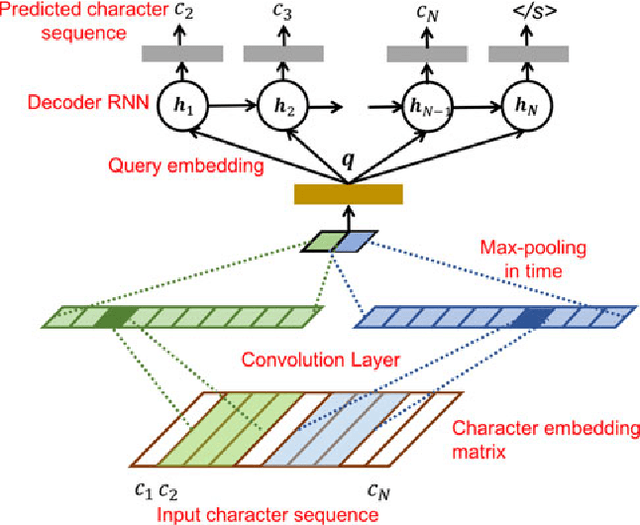
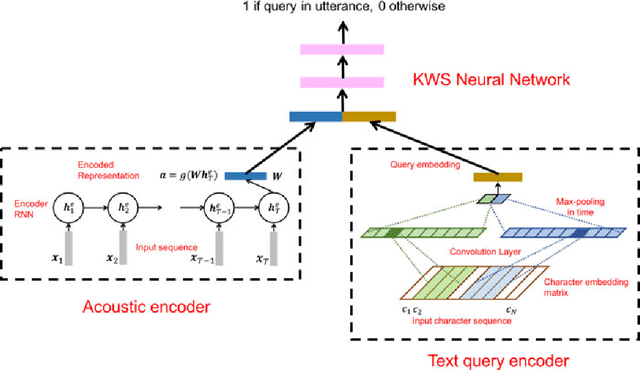
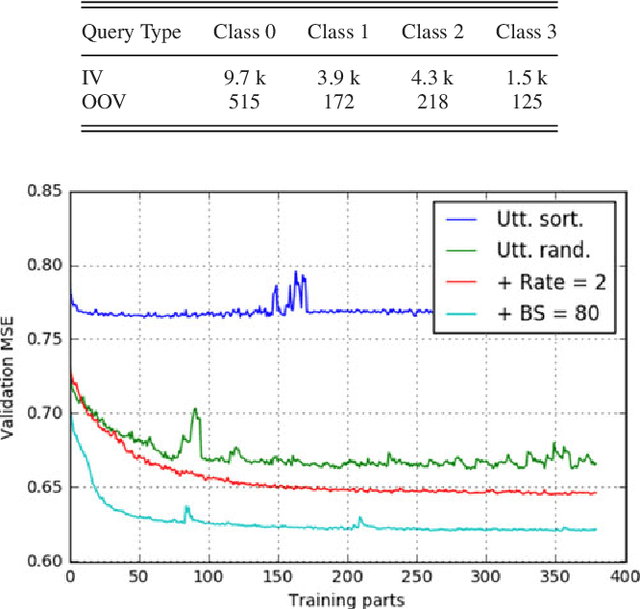
End-to-end (E2E) systems have achieved competitive results compared to conventional hybrid hidden Markov model (HMM)-deep neural network based automatic speech recognition (ASR) systems. Such E2E systems are attractive due to the lack of dependence on alignments between input acoustic and output grapheme or HMM state sequence during training. This paper explores the design of an ASR-free end-to-end system for text query-based keyword search (KWS) from speech trained with minimal supervision. Our E2E KWS system consists of three sub-systems. The first sub-system is a recurrent neural network (RNN)-based acoustic auto-encoder trained to reconstruct the audio through a finite-dimensional representation. The second sub-system is a character-level RNN language model using embeddings learned from a convolutional neural network. Since the acoustic and text query embeddings occupy different representation spaces, they are input to a third feed-forward neural network that predicts whether the query occurs in the acoustic utterance or not. This E2E ASR-free KWS system performs respectably despite lacking a conventional ASR system and trains much faster.
Kernel Approximation Methods for Speech Recognition
Jan 13, 2017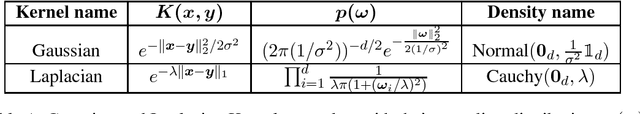
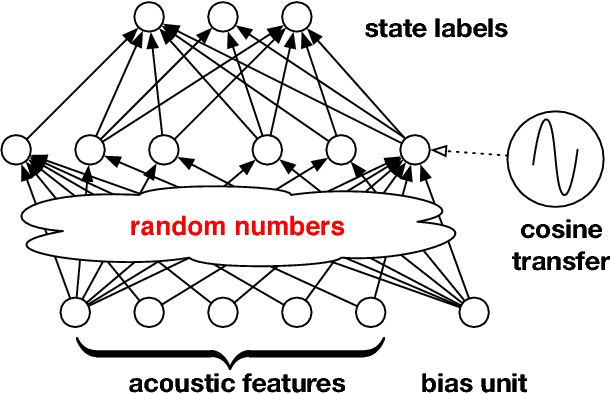
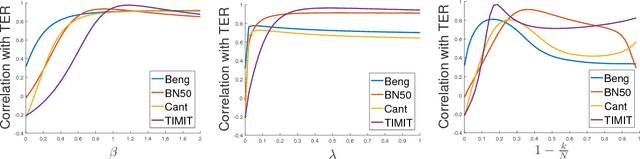

We study large-scale kernel methods for acoustic modeling in speech recognition and compare their performance to deep neural networks (DNNs). We perform experiments on four speech recognition datasets, including the TIMIT and Broadcast News benchmark tasks, and compare these two types of models on frame-level performance metrics (accuracy, cross-entropy), as well as on recognition metrics (word/character error rate). In order to scale kernel methods to these large datasets, we use the random Fourier feature method of Rahimi and Recht (2007). We propose two novel techniques for improving the performance of kernel acoustic models. First, in order to reduce the number of random features required by kernel models, we propose a simple but effective method for feature selection. The method is able to explore a large number of non-linear features while maintaining a compact model more efficiently than existing approaches. Second, we present a number of frame-level metrics which correlate very strongly with recognition performance when computed on the heldout set; we take advantage of these correlations by monitoring these metrics during training in order to decide when to stop learning. This technique can noticeably improve the recognition performance of both DNN and kernel models, while narrowing the gap between them. Additionally, we show that the linear bottleneck method of Sainath et al. (2013) improves the performance of our kernel models significantly, in addition to speeding up training and making the models more compact. Together, these three methods dramatically improve the performance of kernel acoustic models, making their performance comparable to DNNs on the tasks we explored.
A Comparison between Deep Neural Nets and Kernel Acoustic Models for Speech Recognition
Mar 18, 2016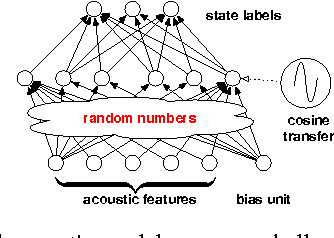


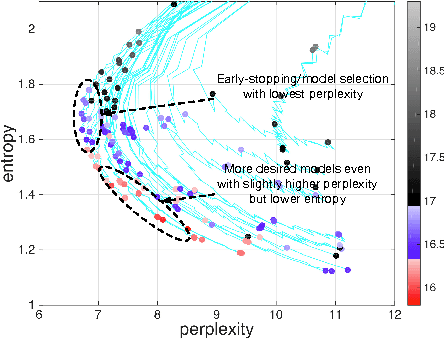
We study large-scale kernel methods for acoustic modeling and compare to DNNs on performance metrics related to both acoustic modeling and recognition. Measuring perplexity and frame-level classification accuracy, kernel-based acoustic models are as effective as their DNN counterparts. However, on token-error-rates DNN models can be significantly better. We have discovered that this might be attributed to DNN's unique strength in reducing both the perplexity and the entropy of the predicted posterior probabilities. Motivated by our findings, we propose a new technique, entropy regularized perplexity, for model selection. This technique can noticeably improve the recognition performance of both types of models, and reduces the gap between them. While effective on Broadcast News, this technique could be also applicable to other tasks.
Very Deep Multilingual Convolutional Neural Networks for LVCSR
Jan 23, 2016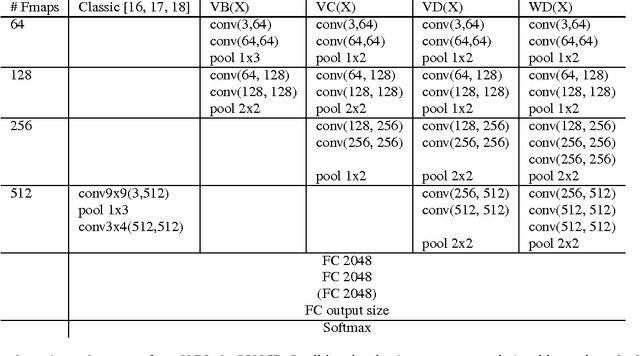
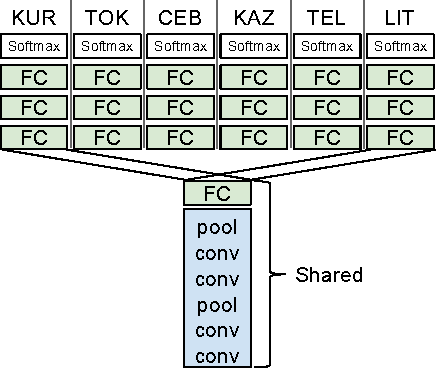
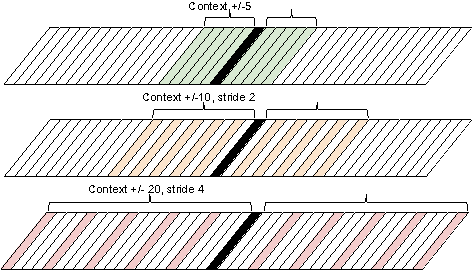
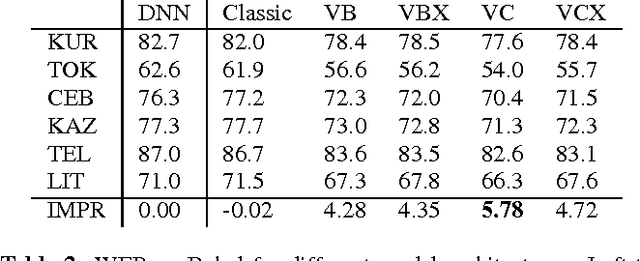
Convolutional neural networks (CNNs) are a standard component of many current state-of-the-art Large Vocabulary Continuous Speech Recognition (LVCSR) systems. However, CNNs in LVCSR have not kept pace with recent advances in other domains where deeper neural networks provide superior performance. In this paper we propose a number of architectural advances in CNNs for LVCSR. First, we introduce a very deep convolutional network architecture with up to 14 weight layers. There are multiple convolutional layers before each pooling layer, with small 3x3 kernels, inspired by the VGG Imagenet 2014 architecture. Then, we introduce multilingual CNNs with multiple untied layers. Finally, we introduce multi-scale input features aimed at exploiting more context at negligible computational cost. We evaluate the improvements first on a Babel task for low resource speech recognition, obtaining an absolute 5.77% WER improvement over the baseline PLP DNN by training our CNN on the combined data of six different languages. We then evaluate the very deep CNNs on the Hub5'00 benchmark (using the 262 hours of SWB-1 training data) achieving a word error rate of 11.8% after cross-entropy training, a 1.4% WER improvement (10.6% relative) over the best published CNN result so far.
How to Scale Up Kernel Methods to Be As Good As Deep Neural Nets
Jun 17, 2015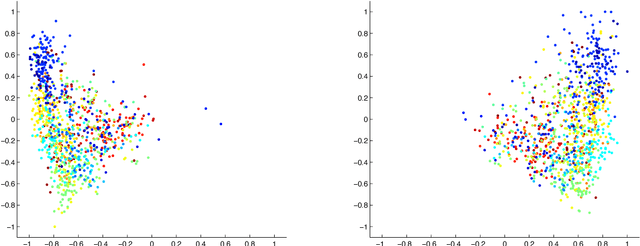
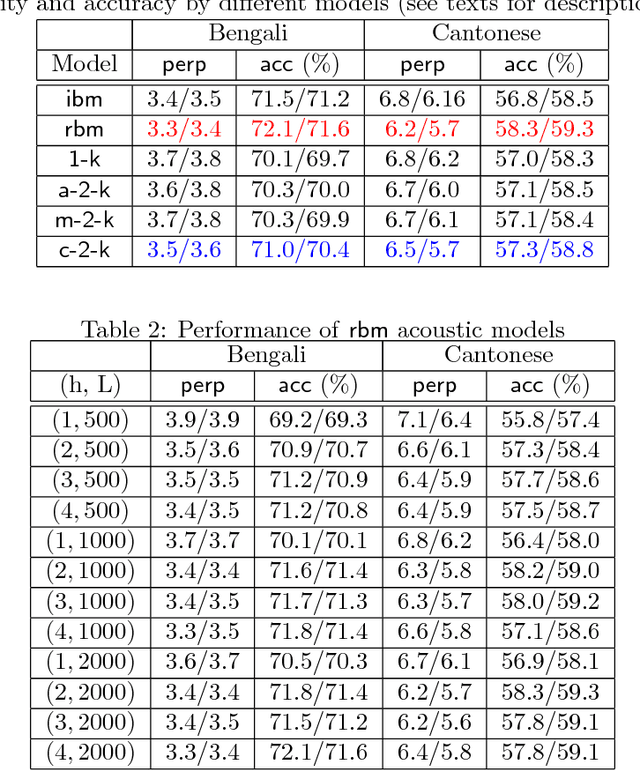
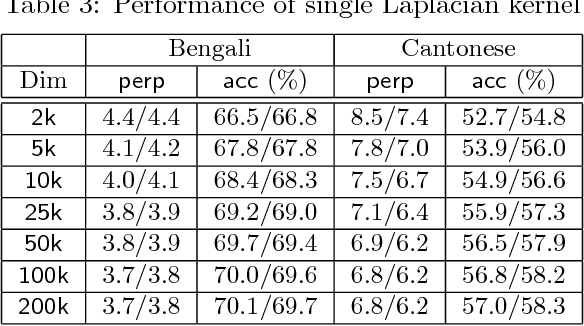
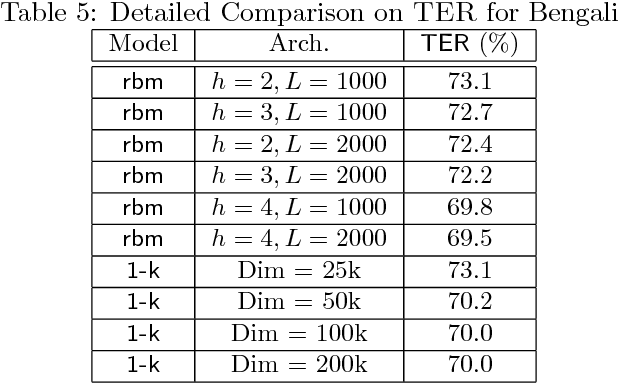
The computational complexity of kernel methods has often been a major barrier for applying them to large-scale learning problems. We argue that this barrier can be effectively overcome. In particular, we develop methods to scale up kernel models to successfully tackle large-scale learning problems that are so far only approachable by deep learning architectures. Based on the seminal work by Rahimi and Recht on approximating kernel functions with features derived from random projections, we advance the state-of-the-art by proposing methods that can efficiently train models with hundreds of millions of parameters, and learn optimal representations from multiple kernels. We conduct extensive empirical studies on problems from image recognition and automatic speech recognition, and show that the performance of our kernel models matches that of well-engineered deep neural nets (DNNs). To the best of our knowledge, this is the first time that a direct comparison between these two methods on large-scale problems is reported. Our kernel methods have several appealing properties: training with convex optimization, cost for training a single model comparable to DNNs, and significantly reduced total cost due to fewer hyperparameters to tune for model selection. Our contrastive study between these two very different but equally competitive models sheds light on fundamental questions such as how to learn good representations.