 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Visual Sentiment Concept Matching
Jun 07, 2016
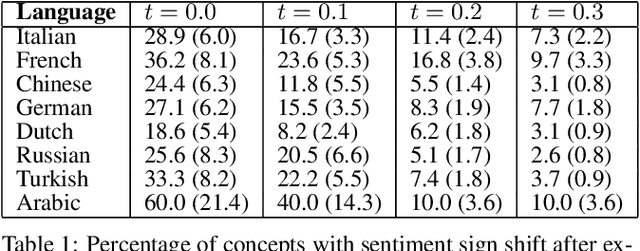
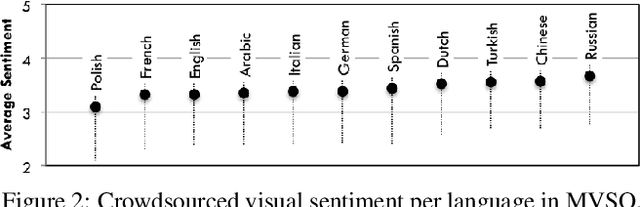
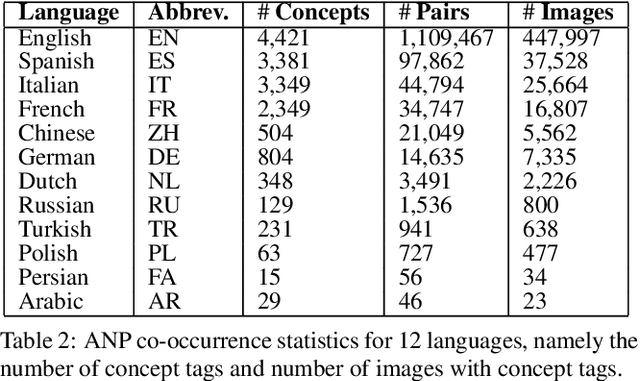
The impact of culture in visual emotion perception has recently captured the attention of multimedia research. In this study, we pro- vide powerful computational linguistics tools to explore, retrieve and browse a dataset of 16K multilingual affective visual concepts and 7.3M Flickr images. First, we design an effective crowdsourc- ing experiment to collect human judgements of sentiment connected to the visual concepts. We then use word embeddings to repre- sent these concepts in a low dimensional vector space, allowing us to expand the meaning around concepts, and thus enabling insight about commonalities and differences among different languages. We compare a variety of concept representations through a novel evaluation task based on the notion of visual semantic relatedness. Based on these representations, we design clustering schemes to group multilingual visual concepts, and evaluate them with novel metrics based on the crowdsourced sentiment annotations as well as visual semantic relatedness. The proposed clustering framework enables us to analyze the full multilingual dataset in-depth and also show an application on a facial data subset, exploring cultural in- sights of portrait-related affective visual concepts.
Going Deeper for Multilingual Visual Sentiment Detection
May 30, 2016
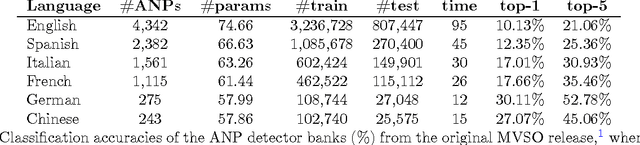
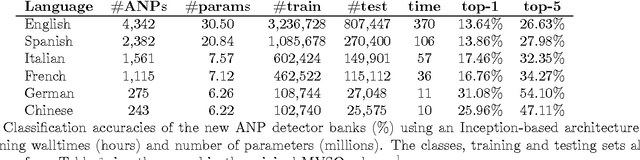
This technical report details several improvements to the visual concept detector banks built on images from the Multilingual Visual Sentiment Ontology (MVSO). The detector banks are trained to detect a total of 9,918 sentiment-biased visual concepts from six major languages: English, Spanish, Italian, French, German and Chinese. In the original MVSO release, adjective-noun pair (ANP) detectors were trained for the six languages using an AlexNet-styled architecture by fine-tuning from DeepSentiBank. Here, through a more extensive set of experiments, parameter tuning, and training runs, we detail and release higher accuracy models for detecting ANPs across six languages from the same image pool and setting as in the original release using a more modern architecture, GoogLeNet, providing comparable or better performance with reduced network parameter cost. In addition, since the image pool in MVSO can be corrupted by user noise from social interactions, we partitioned out a sub-corpus of MVSO images based on tag-restricted queries for higher fidelity labels. We show that as a result of these higher fidelity labels, higher performing AlexNet-styled ANP detectors can be trained using the tag-restricted image subset as compared to the models in full corpus. We release all these newly trained models for public research use along with the list of tag-restricted images from the MVSO dataset.
Visual Affect Around the World: A Large-scale Multilingual Visual Sentiment Ontology
Oct 07, 2015

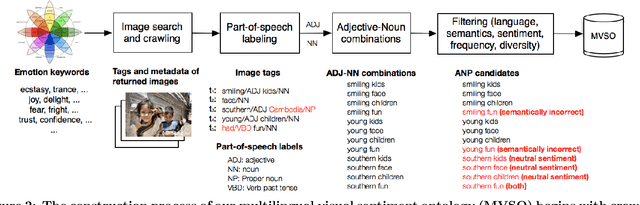
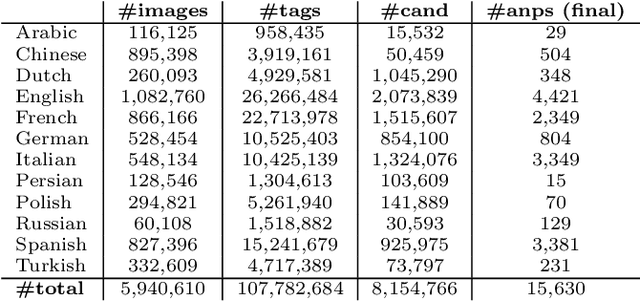
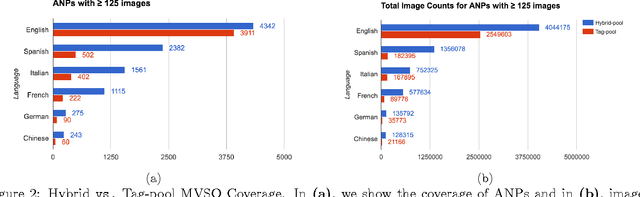
Every culture and language is unique. Our work expressly focuses on the uniqueness of culture and language in relation to human affect, specifically sentiment and emotion semantics, and how they manifest in social multimedia. We develop sets of sentiment- and emotion-polarized visual concepts by adapting semantic structures called adjective-noun pairs, originally introduced by Borth et al. (2013), but in a multilingual context. We propose a new language-dependent method for automatic discovery of these adjective-noun constructs. We show how this pipeline can be applied on a social multimedia platform for the creation of a large-scale multilingual visual sentiment concept ontology (MVSO). Unlike the flat structure in Borth et al. (2013), our unified ontology is organized hierarchically by multilingual clusters of visually detectable nouns and subclusters of emotionally biased versions of these nouns. In addition, we present an image-based prediction task to show how generalizable language-specific models are in a multilingual context. A new, publicly available dataset of >15.6K sentiment-biased visual concepts across 12 languages with language-specific detector banks, >7.36M images and their metadata is also released.
Diving Deep into Sentiment: Understanding Fine-tuned CNNs for Visual Sentiment Prediction
Aug 24, 2015


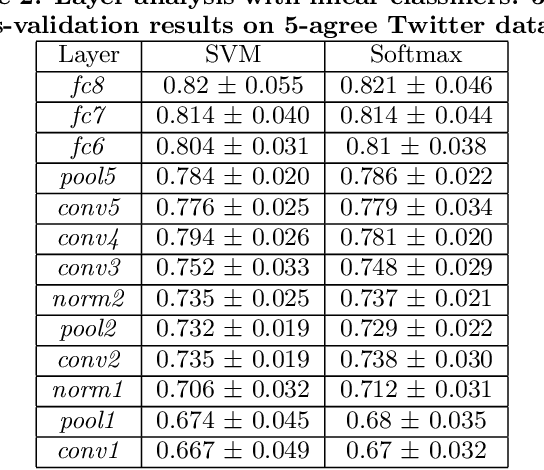
Visual media are powerful means of expressing emotions and sentiments. The constant generation of new content in social networks highlights the need of automated visual sentiment analysis tools. While Convolutional Neural Networks (CNNs) have established a new state-of-the-art in several vision problems, their application to the task of sentiment analysis is mostly unexplored and there are few studies regarding how to design CNNs for this purpose. In this work, we study the suitability of fine-tuning a CNN for visual sentiment prediction as well as explore performance boosting techniques within this deep learning setting. Finally, we provide a deep-dive analysis into a benchmark, state-of-the-art network architecture to gain insight about how to design patterns for CNNs on the task of visual sentiment prediction.