 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBo Zhang
Improving Seq2Seq Grammatical Error Correction via Decoding Interventions
Oct 23, 2023


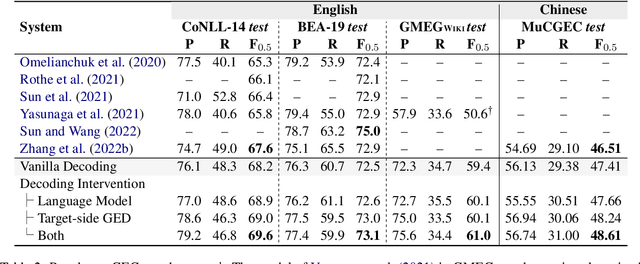
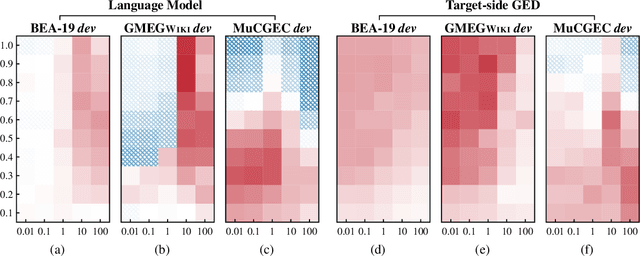
The sequence-to-sequence (Seq2Seq) approach has recently been widely used in grammatical error correction (GEC) and shows promising performance. However, the Seq2Seq GEC approach still suffers from two issues. First, a Seq2Seq GEC model can only be trained on parallel data, which, in GEC task, is often noisy and limited in quantity. Second, the decoder of a Seq2Seq GEC model lacks an explicit awareness of the correctness of the token being generated. In this paper, we propose a unified decoding intervention framework that employs an external critic to assess the appropriateness of the token to be generated incrementally, and then dynamically influence the choice of the next token. We discover and investigate two types of critics: a pre-trained left-to-right language model critic and an incremental target-side grammatical error detector critic. Through extensive experiments on English and Chinese datasets, our framework consistently outperforms strong baselines and achieves results competitive with state-of-the-art methods.
REVO-LION: Evaluating and Refining Vision-Language Instruction Tuning Datasets
Oct 10, 2023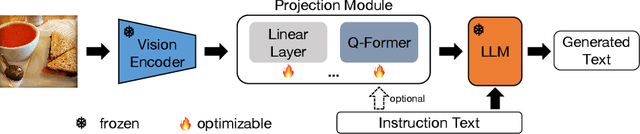
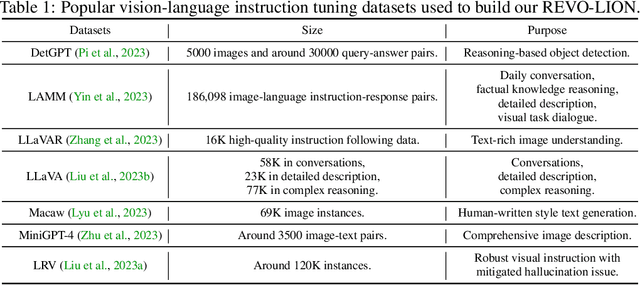


There is an emerging line of research on multimodal instruction tuning, and a line of benchmarks have been proposed for evaluating these models recently. Instead of evaluating the models directly, in this paper we try to evaluate the Vision-Language Instruction-Tuning (VLIT) datasets themselves and further seek the way of building a dataset for developing an all-powerful VLIT model, which we believe could also be of utility for establishing a grounded protocol for benchmarking VLIT models. For effective analysis of VLIT datasets that remains an open question, we propose a tune-cross-evaluation paradigm: tuning on one dataset and evaluating on the others in turn. For each single tune-evaluation experiment set, we define the Meta Quality (MQ) as the mean score measured by a series of caption metrics including BLEU, METEOR, and ROUGE-L to quantify the quality of a certain dataset or a sample. On this basis, to evaluate the comprehensiveness of a dataset, we develop the Dataset Quality (DQ) covering all tune-evaluation sets. To lay the foundation for building a comprehensive dataset and developing an all-powerful model for practical applications, we further define the Sample Quality (SQ) to quantify the all-sided quality of each sample. Extensive experiments validate the rationality of the proposed evaluation paradigm. Based on the holistic evaluation, we build a new dataset, REVO-LION (REfining VisiOn-Language InstructiOn tuNing), by collecting samples with higher SQ from each dataset. With only half of the full data, the model trained on REVO-LION can achieve performance comparable to simply adding all VLIT datasets up. In addition to developing an all-powerful model, REVO-LION also includes an evaluation set, which is expected to serve as a convenient evaluation benchmark for future research.
DreamCom: Finetuning Text-guided Inpainting Model for Image Composition
Sep 27, 2023The goal of image composition is merging a foreground object into a background image to obtain a realistic composite image. Recently, generative composition methods are built on large pretrained diffusion models, due to their unprecedented image generation ability. They train a model on abundant pairs of foregrounds and backgrounds, so that it can be directly applied to a new pair of foreground and background at test time. However, the generated results often lose the foreground details and exhibit noticeable artifacts. In this work, we propose an embarrassingly simple approach named DreamCom inspired by DreamBooth. Specifically, given a few reference images for a subject, we finetune text-guided inpainting diffusion model to associate this subject with a special token and inpaint this subject in the specified bounding box. We also construct a new dataset named MureCom well-tailored for this task.
ReSimAD: Zero-Shot 3D Domain Transfer for Autonomous Driving with Source Reconstruction and Target Simulation
Sep 25, 2023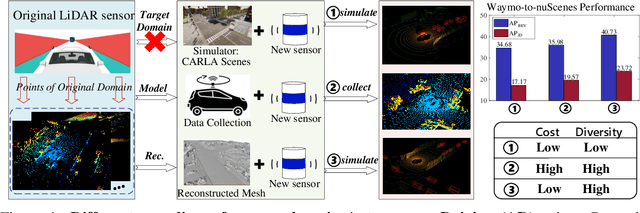
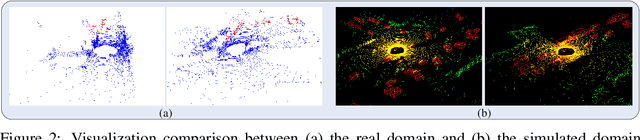
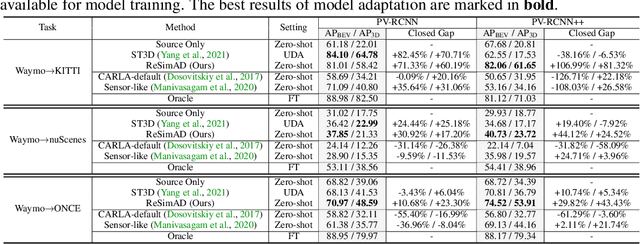
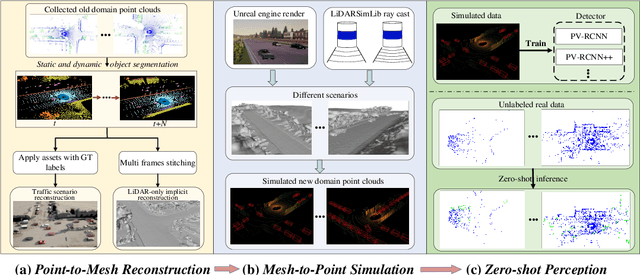
Domain shifts such as sensor type changes and geographical situation variations are prevalent in Autonomous Driving (AD), which poses a challenge since AD model relying on the previous-domain knowledge can be hardly directly deployed to a new domain without additional costs. In this paper, we provide a new perspective and approach of alleviating the domain shifts, by proposing a Reconstruction-Simulation-Perception (ReSimAD) scheme. Specifically, the implicit reconstruction process is based on the knowledge from the previous old domain, aiming to convert the domain-related knowledge into domain-invariant representations, e.g., 3D scene-level meshes. Besides, the point clouds simulation process of multiple new domains is conditioned on the above reconstructed 3D meshes, where the target-domain-like simulation samples can be obtained, thus reducing the cost of collecting and annotating new-domain data for the subsequent perception process. For experiments, we consider different cross-domain situations such as Waymo-to-KITTI, Waymo-to-nuScenes, Waymo-to-ONCE, etc, to verify the zero-shot target-domain perception using ReSimAD. Results demonstrate that our method is beneficial to boost the domain generalization ability, even promising for 3D pre-training.
SPOT: Scalable 3D Pre-training via Occupancy Prediction for Autonomous Driving
Sep 25, 2023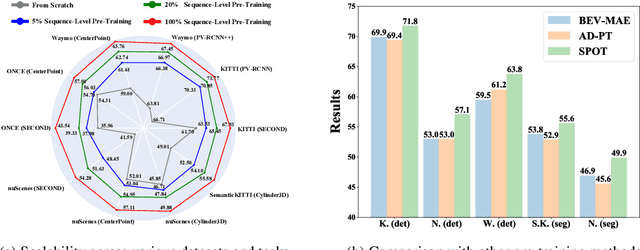
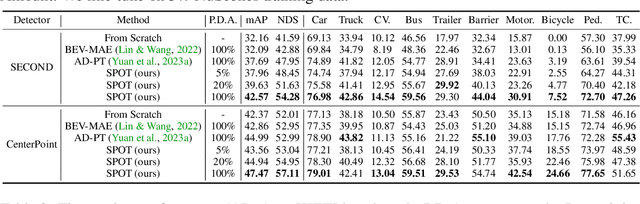
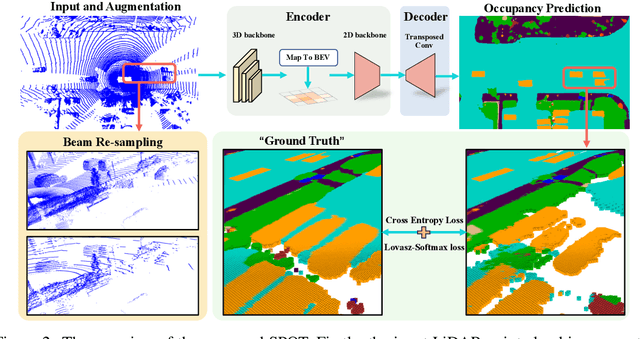
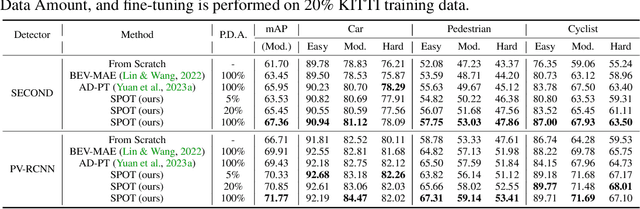
Annotating 3D LiDAR point clouds for perception tasks including 3D object detection and LiDAR semantic segmentation is notoriously time-and-energy-consuming. To alleviate the burden from labeling, it is promising to perform large-scale pre-training and fine-tune the pre-trained backbone on different downstream datasets as well as tasks. In this paper, we propose SPOT, namely Scalable Pre-training via Occupancy prediction for learning Transferable 3D representations, and demonstrate its effectiveness on various public datasets with different downstream tasks under the label-efficiency setting. Our contributions are threefold: (1) Occupancy prediction is shown to be promising for learning general representations, which is demonstrated by extensive experiments on plenty of datasets and tasks. (2) SPOT uses beam re-sampling technique for point cloud augmentation and applies class-balancing strategies to overcome the domain gap brought by various LiDAR sensors and annotation strategies in different datasets. (3) Scalable pre-training is observed, that is, the downstream performance across all the experiments gets better with more pre-training data. We believe that our findings can facilitate understanding of LiDAR point clouds and pave the way for future exploration in LiDAR pre-training. Codes and models will be released.
StructChart: Perception, Structuring, Reasoning for Visual Chart Understanding
Sep 25, 2023
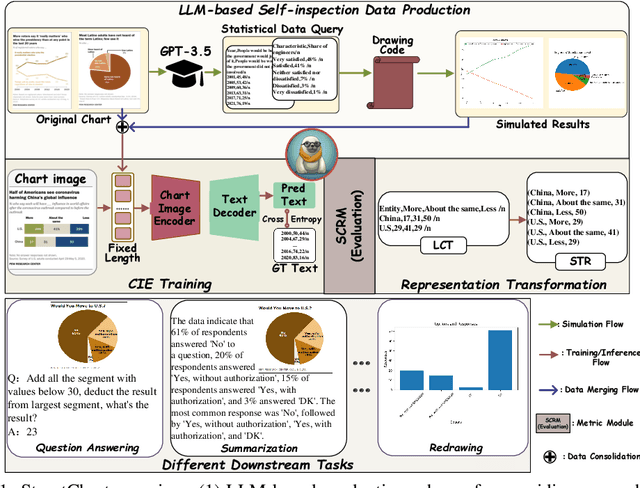
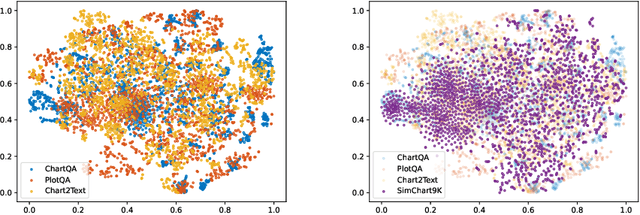
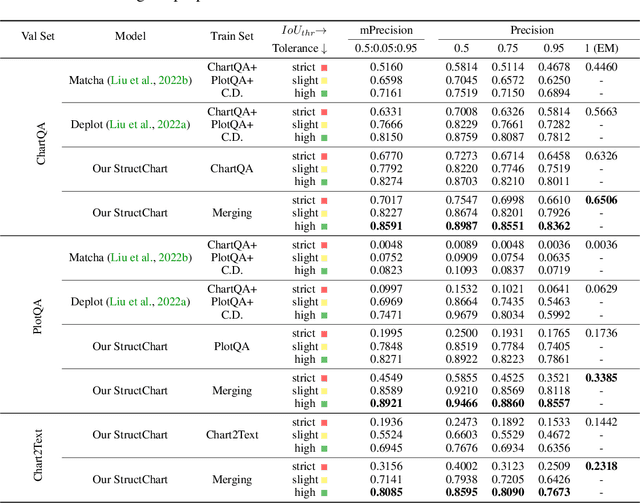
Charts are common in literature across different scientific fields, conveying rich information easily accessible to readers. Current chart-related tasks focus on either chart perception which refers to extracting information from the visual charts, or performing reasoning given the extracted data, e.g. in a tabular form. In this paper, we aim to establish a unified and label-efficient learning paradigm for joint perception and reasoning tasks, which can be generally applicable to different downstream tasks, beyond the question-answering task as specifically studied in peer works. Specifically, StructChart first reformulates the chart information from the popular tubular form (specifically linearized CSV) to the proposed Structured Triplet Representations (STR), which is more friendly for reducing the task gap between chart perception and reasoning due to the employed structured information extraction for charts. We then propose a Structuring Chart-oriented Representation Metric (SCRM) to quantitatively evaluate the performance for the chart perception task. To enrich the dataset for training, we further explore the possibility of leveraging the Large Language Model (LLM), enhancing the chart diversity in terms of both chart visual style and its statistical information. Extensive experiments are conducted on various chart-related tasks, demonstrating the effectiveness and promising potential for a unified chart perception-reasoning paradigm to push the frontier of chart understanding.
Learning Point-wise Abstaining Penalty for Point Cloud Anomaly Detection
Sep 20, 2023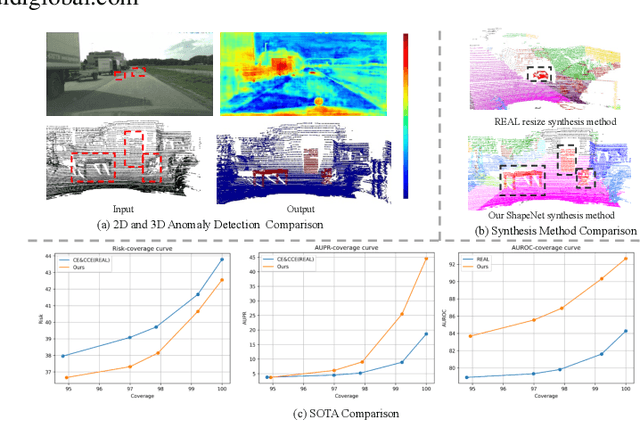

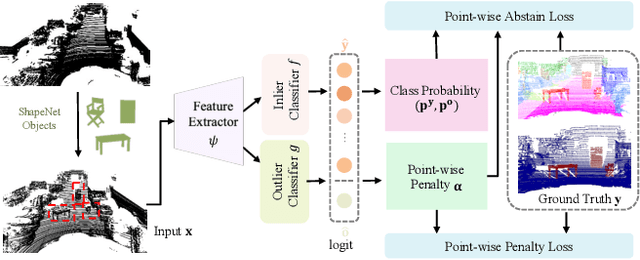
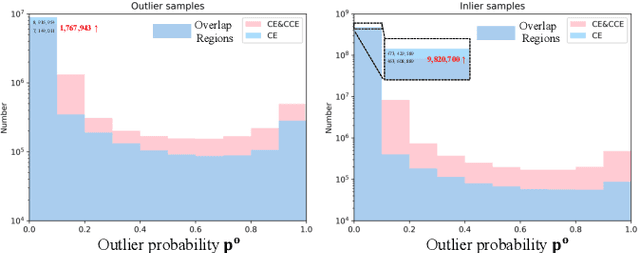
LiDAR-based semantic scene understanding is an important module in the modern autonomous driving perception stack. However, identifying Out-Of-Distribution (OOD) points in a LiDAR point cloud is challenging as point clouds lack semantically rich features when compared with RGB images. We revisit this problem from the perspective of selective classification, which introduces a selective function into the standard closed-set classification setup. Our solution is built upon the basic idea of abstaining from choosing any known categories but learns a point-wise abstaining penalty with a marginbased loss. Synthesizing outliers to approximate unlimited OOD samples is also critical to this idea, so we propose a strong synthesis pipeline that generates outliers originated from various factors: unrealistic object categories, sampling patterns and sizes. We demonstrate that learning different abstaining penalties, apart from point-wise penalty, for different types of (synthesized) outliers can further improve the performance. We benchmark our method on SemanticKITTI and nuScenes and achieve state-of-the-art results. Risk-coverage analysis further reveals intrinsic properties of different methods. Codes and models will be publicly available.
OWL: A Large Language Model for IT Operations
Sep 17, 2023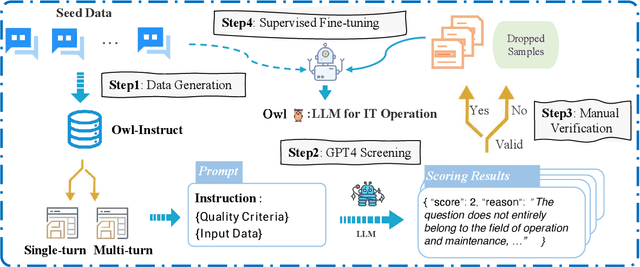



With the rapid development of IT operations, it has become increasingly crucial to efficiently manage and analyze large volumes of data for practical applications. The techniques of Natural Language Processing (NLP) have shown remarkable capabilities for various tasks, including named entity recognition, machine translation and dialogue systems. Recently, Large Language Models (LLMs) have achieved significant improvements across various NLP downstream tasks. However, there is a lack of specialized LLMs for IT operations. In this paper, we introduce the OWL, a large language model trained on our collected OWL-Instruct dataset with a wide range of IT-related information, where the mixture-of-adapter strategy is proposed to improve the parameter-efficient tuning across different domains or tasks. Furthermore, we evaluate the performance of our OWL on the OWL-Bench established by us and open IT-related benchmarks. OWL demonstrates superior performance results on IT tasks, which outperforms existing models by significant margins. Moreover, we hope that the findings of our work will provide more insights to revolutionize the techniques of IT operations with specialized LLMs.