 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBernard Ghanem
Online Distillation with Continual Learning for Cyclic Domain Shifts
Apr 03, 2023
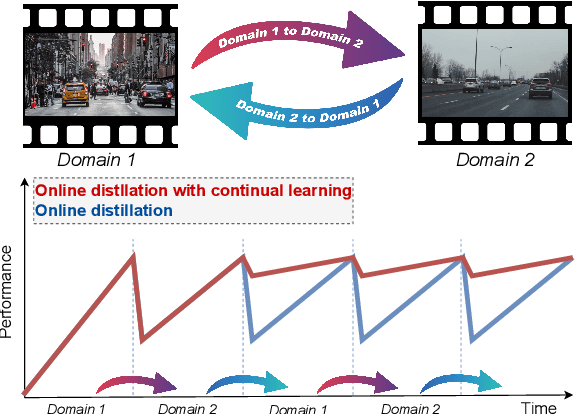
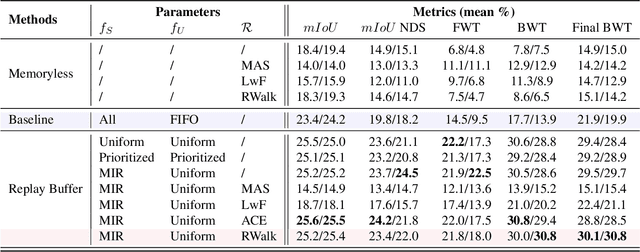
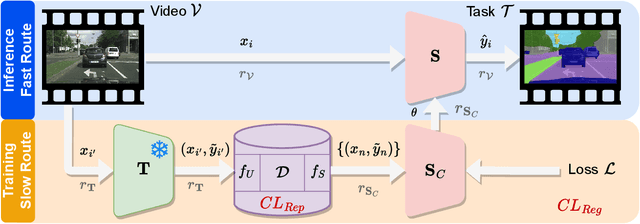
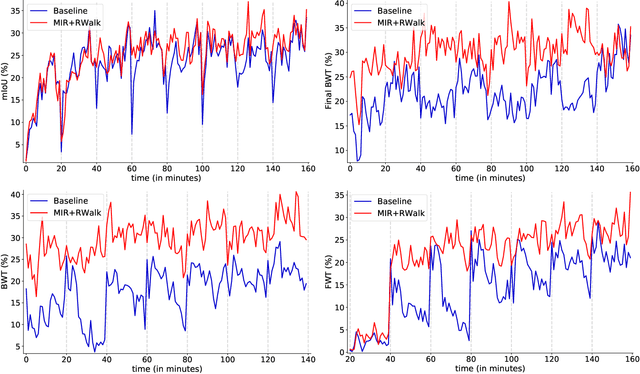
In recent years, online distillation has emerged as a powerful technique for adapting real-time deep neural networks on the fly using a slow, but accurate teacher model. However, a major challenge in online distillation is catastrophic forgetting when the domain shifts, which occurs when the student model is updated with data from the new domain and forgets previously learned knowledge. In this paper, we propose a solution to this issue by leveraging the power of continual learning methods to reduce the impact of domain shifts. Specifically, we integrate several state-of-the-art continual learning methods in the context of online distillation and demonstrate their effectiveness in reducing catastrophic forgetting. Furthermore, we provide a detailed analysis of our proposed solution in the case of cyclic domain shifts. Our experimental results demonstrate the efficacy of our approach in improving the robustness and accuracy of online distillation, with potential applications in domains such as video surveillance or autonomous driving. Overall, our work represents an important step forward in the field of online distillation and continual learning, with the potential to significantly impact real-world applications.
CAMEL: Communicative Agents for "Mind" Exploration of Large Scale Language Model Society
Mar 31, 2023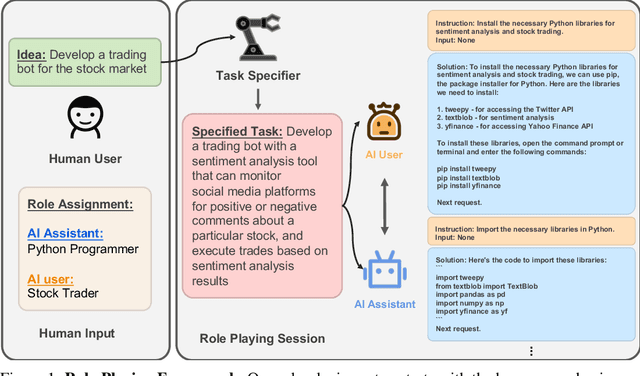


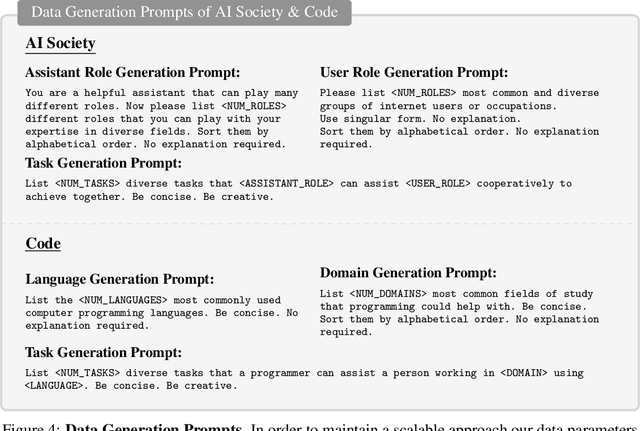
The rapid advancement of conversational and chat-based language models has led to remarkable progress in complex task-solving. However, their success heavily relies on human input to guide the conversation, which can be challenging and time-consuming. This paper explores the potential of building scalable techniques to facilitate autonomous cooperation among communicative agents and provide insight into their "cognitive" processes. To address the challenges of achieving autonomous cooperation, we propose a novel communicative agent framework named role-playing. Our approach involves using inception prompting to guide chat agents toward task completion while maintaining consistency with human intentions. We showcase how role-playing can be used to generate conversational data for studying the behaviors and capabilities of chat agents, providing a valuable resource for investigating conversational language models. Our contributions include introducing a novel communicative agent framework, offering a scalable approach for studying the cooperative behaviors and capabilities of multi-agent systems, and open-sourcing our library to support research on communicative agents and beyond. The GitHub repository of this project is made publicly available on: https://github.com/lightaime/camel.
Don't FREAK Out: A Frequency-Inspired Approach to Detecting Backdoor Poisoned Samples in DNNs
Mar 23, 2023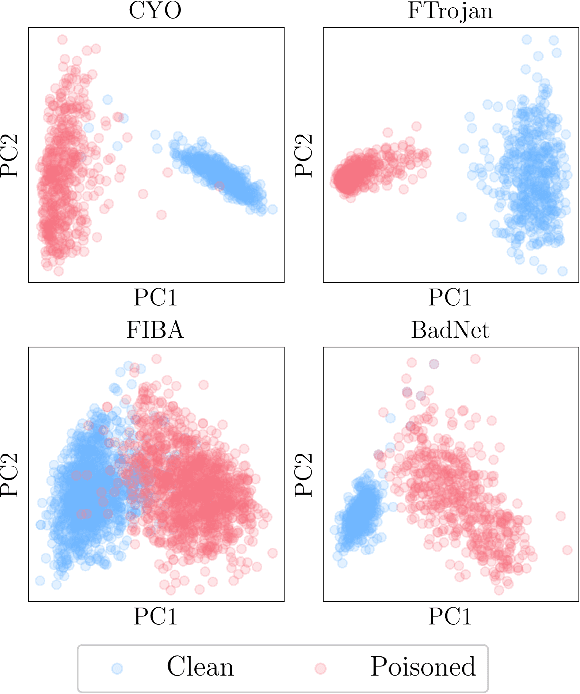


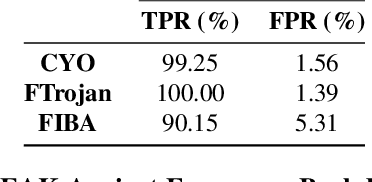
In this paper we investigate the frequency sensitivity of Deep Neural Networks (DNNs) when presented with clean samples versus poisoned samples. Our analysis shows significant disparities in frequency sensitivity between these two types of samples. Building on these findings, we propose FREAK, a frequency-based poisoned sample detection algorithm that is simple yet effective. Our experimental results demonstrate the efficacy of FREAK not only against frequency backdoor attacks but also against some spatial attacks. Our work is just the first step in leveraging these insights. We believe that our analysis and proposed defense mechanism will provide a foundation for future research and development of backdoor defenses.
Computationally Budgeted Continual Learning: What Does Matter?
Mar 20, 2023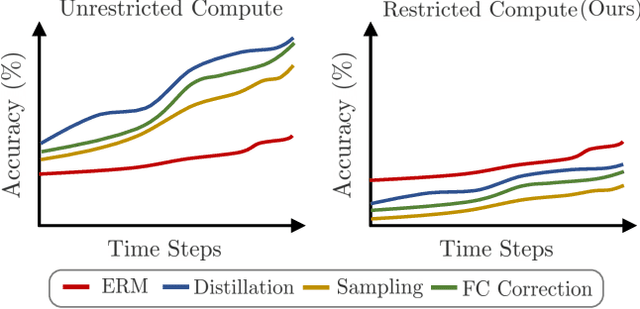
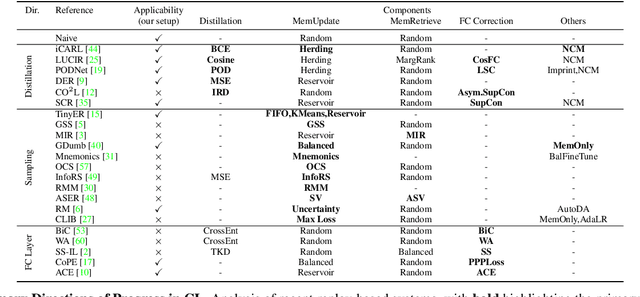
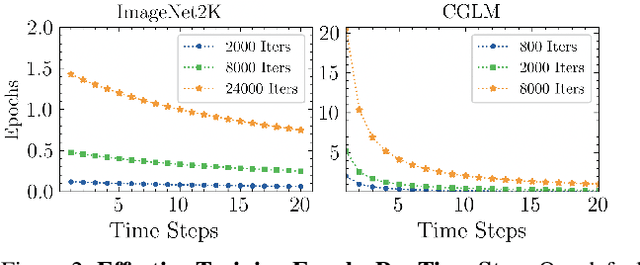
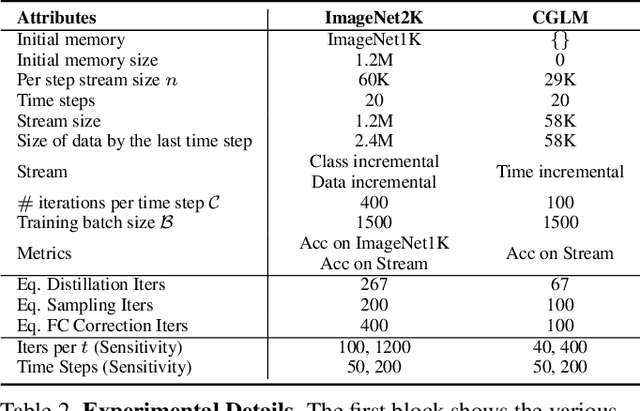
Continual Learning (CL) aims to sequentially train models on streams of incoming data that vary in distribution by preserving previous knowledge while adapting to new data. Current CL literature focuses on restricted access to previously seen data, while imposing no constraints on the computational budget for training. This is unreasonable for applications in-the-wild, where systems are primarily constrained by computational and time budgets, not storage. We revisit this problem with a large-scale benchmark and analyze the performance of traditional CL approaches in a compute-constrained setting, where effective memory samples used in training can be implicitly restricted as a consequence of limited computation. We conduct experiments evaluating various CL sampling strategies, distillation losses, and partial fine-tuning on two large-scale datasets, namely ImageNet2K and Continual Google Landmarks V2 in data incremental, class incremental, and time incremental settings. Through extensive experiments amounting to a total of over 1500 GPU-hours, we find that, under compute-constrained setting, traditional CL approaches, with no exception, fail to outperform a simple minimal baseline that samples uniformly from memory. Our conclusions are consistent in a different number of stream time steps, e.g., 20 to 200, and under several computational budgets. This suggests that most existing CL methods are particularly too computationally expensive for realistic budgeted deployment. Code for this project is available at: https://github.com/drimpossible/BudgetCL.
A Unified Continual Learning Framework with General Parameter-Efficient Tuning
Mar 17, 2023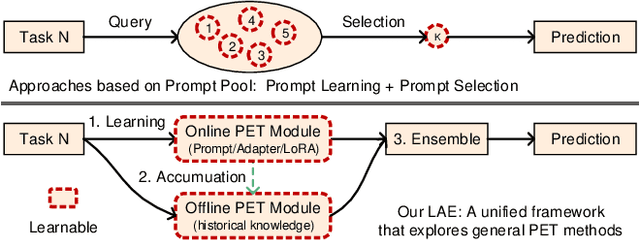
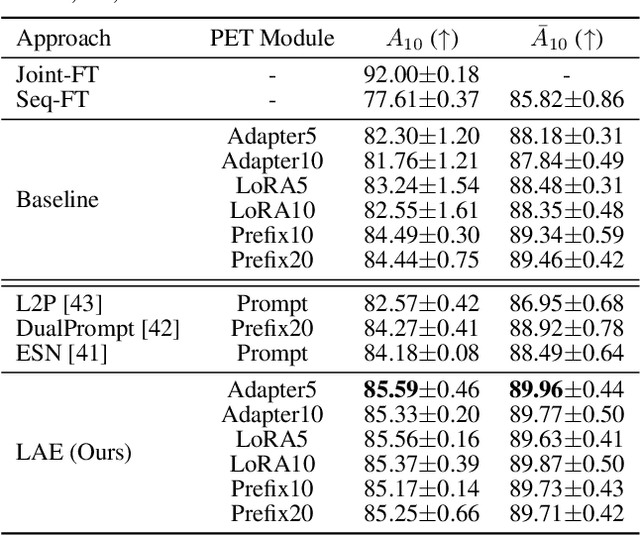
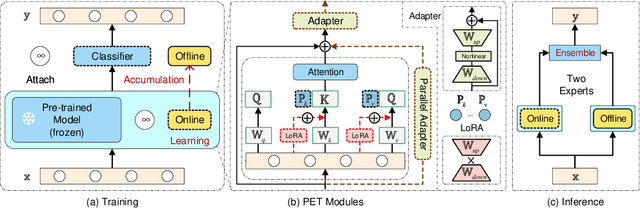
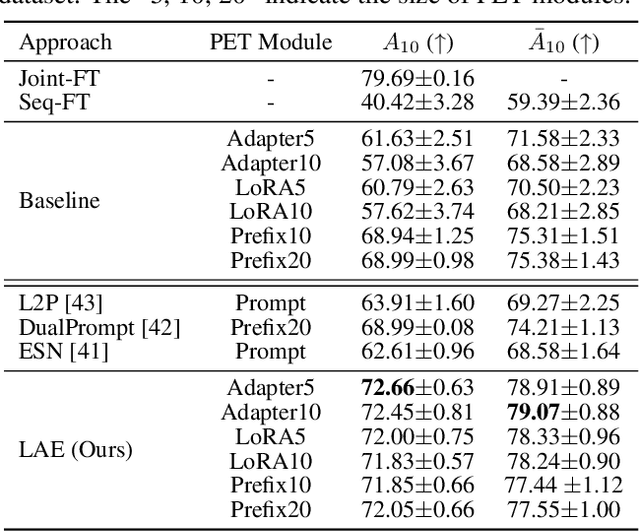
The "pre-training $\rightarrow$ downstream adaptation" presents both new opportunities and challenges for Continual Learning (CL). Although the recent state-of-the-art in CL is achieved through Parameter-Efficient-Tuning (PET) adaptation paradigm, only prompt has been explored, limiting its application to Transformers only. In this paper, we position prompting as one instantiation of PET, and propose a unified CL framework with general PET, dubbed as Learning-Accumulation-Ensemble (LAE). PET, e.g., using Adapter, LoRA, or Prefix, can adapt a pre-trained model to downstream tasks with fewer parameters and resources. Given a PET method, our LAE framework incorporates it for CL with three novel designs. 1) Learning: the pre-trained model adapts to the new task by tuning an online PET module, along with our adaptation speed calibration to align different PET modules, 2) Accumulation: the task-specific knowledge learned by the online PET module is accumulated into an offline PET module through momentum update, 3) Ensemble: During inference, we respectively construct two experts with online/offline PET modules (which are favored by the novel/historical tasks) for prediction ensemble. We show that LAE is compatible with a battery of PET methods and gains strong CL capability. For example, LAE with Adaptor PET surpasses the prior state-of-the-art by 1.3% and 3.6% in last-incremental accuracy on CIFAR100 and ImageNet-R datasets, respectively.
FreeDoM: Training-Free Energy-Guided Conditional Diffusion Model
Mar 17, 2023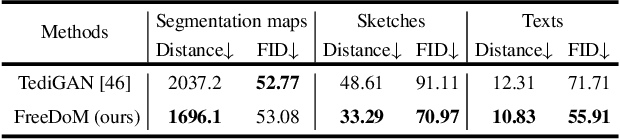



Recently, conditional diffusion models have gained popularity in numerous applications due to their exceptional generation ability. However, many existing methods are training-required. They need to train a time-dependent classifier or a condition-dependent score estimator, which increases the cost of constructing conditional diffusion models and is inconvenient to transfer across different conditions. Some current works aim to overcome this limitation by proposing training-free solutions, but most can only be applied to a specific category of tasks and not to more general conditions. In this work, we propose a training-Free conditional Diffusion Model (FreeDoM) used for various conditions. Specifically, we leverage off-the-shelf pre-trained networks, such as a face detection model, to construct time-independent energy functions, which guide the generation process without requiring training. Furthermore, because the construction of the energy function is very flexible and adaptable to various conditions, our proposed FreeDoM has a broader range of applications than existing training-free methods. FreeDoM is advantageous in its simplicity, effectiveness, and low cost. Experiments demonstrate that FreeDoM is effective for various conditions and suitable for diffusion models of diverse data domains, including image and latent code domains.
Re-ReND: Real-time Rendering of NeRFs across Devices
Mar 15, 2023
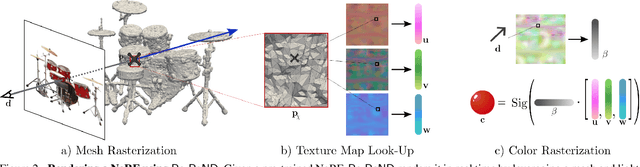
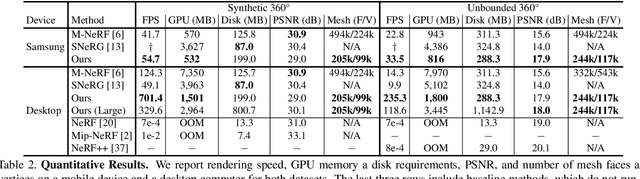
This paper proposes a novel approach for rendering a pre-trained Neural Radiance Field (NeRF) in real-time on resource-constrained devices. We introduce Re-ReND, a method enabling Real-time Rendering of NeRFs across Devices. Re-ReND is designed to achieve real-time performance by converting the NeRF into a representation that can be efficiently processed by standard graphics pipelines. The proposed method distills the NeRF by extracting the learned density into a mesh, while the learned color information is factorized into a set of matrices that represent the scene's light field. Factorization implies the field is queried via inexpensive MLP-free matrix multiplications, while using a light field allows rendering a pixel by querying the field a single time-as opposed to hundreds of queries when employing a radiance field. Since the proposed representation can be implemented using a fragment shader, it can be directly integrated with standard rasterization frameworks. Our flexible implementation can render a NeRF in real-time with low memory requirements and on a wide range of resource-constrained devices, including mobiles and AR/VR headsets. Notably, we find that Re-ReND can achieve over a 2.6-fold increase in rendering speed versus the state-of-the-art without perceptible losses in quality.
Improving GAN Training via Feature Space Shrinkage
Mar 02, 2023
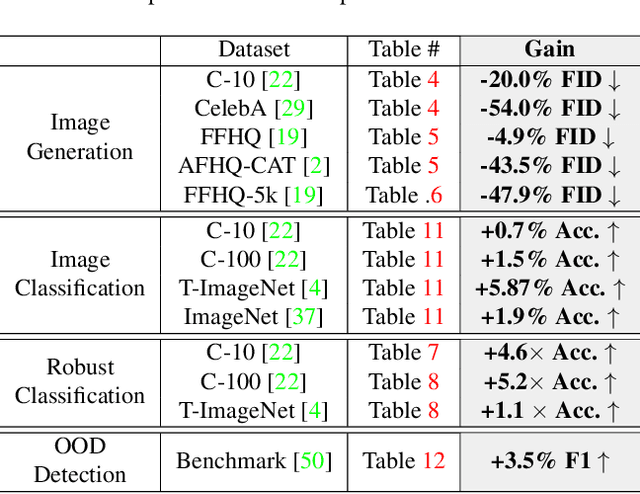
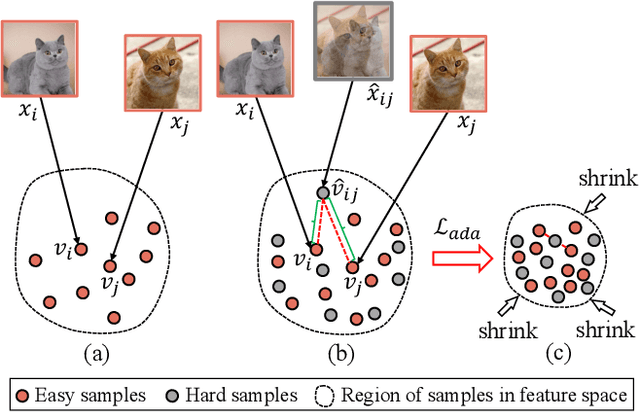

Due to the outstanding capability for data generation, Generative Adversarial Networks (GANs) have attracted considerable attention in unsupervised learning. However, training GANs is difficult, since the training distribution is dynamic for the discriminator, leading to unstable image representation. In this paper, we address the problem of training GANs from a novel perspective, \emph{i.e.,} robust image classification. Motivated by studies on robust image representation, we propose a simple yet effective module, namely AdaptiveMix, for GANs, which shrinks the regions of training data in the image representation space of the discriminator. Considering it is intractable to directly bound feature space, we propose to construct hard samples and narrow down the feature distance between hard and easy samples. The hard samples are constructed by mixing a pair of training images. We evaluate the effectiveness of our AdaptiveMix with widely-used and state-of-the-art GAN architectures. The evaluation results demonstrate that our AdaptiveMix can facilitate the training of GANs and effectively improve the image quality of generated samples. We also show that our AdaptiveMix can be further applied to image classification and Out-Of-Distribution (OOD) detection tasks, by equipping it with state-of-the-art methods. Extensive experiments on seven publicly available datasets show that our method effectively boosts the performance of baselines. The code is publicly available at https://github.com/WentianZhang-ML/AdaptiveMix.
Localizing Moments in Long Video Via Multimodal Guidance
Feb 26, 2023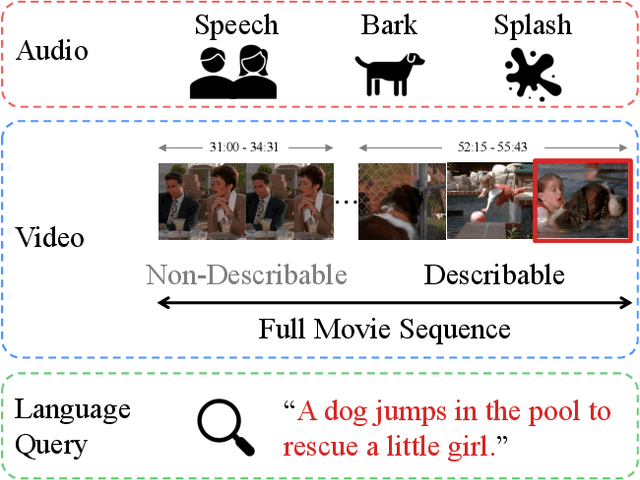
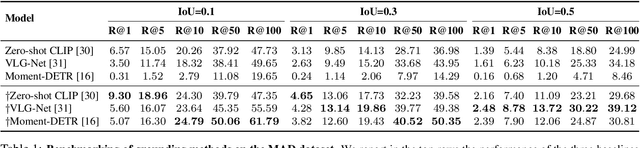

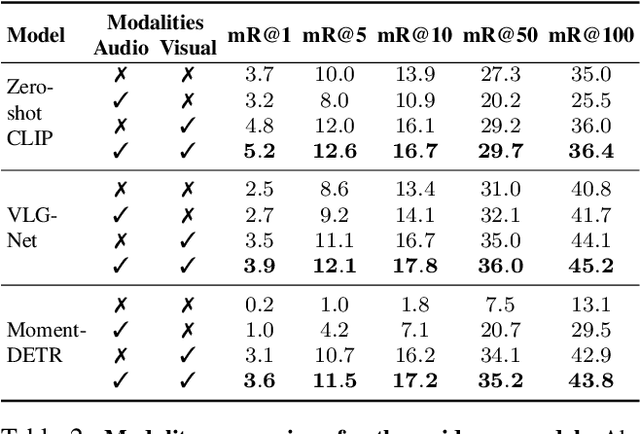
The recent introduction of the large-scale long-form MAD dataset for language grounding in videos has enabled researchers to investigate the performance of current state-of-the-art methods in the long-form setup, with unexpected findings. In fact, current grounding methods alone fail at tackling this challenging task and setup due to their inability to process long video sequences. In this work, we propose an effective way to circumvent the long-form burden by introducing a new component to grounding pipelines: a Guidance model. The purpose of the Guidance model is to efficiently remove irrelevant video segments from the search space of grounding methods by coarsely aligning the sentence to chunks of the movies and then applying legacy grounding methods where high correlation is found. We term these video segments as non-describable moments. This two-stage approach reveals to be effective in boosting the performance of several different grounding baselines on the challenging MAD dataset, achieving new state-of-the-art performance.
Real-Time Evaluation in Online Continual Learning: A New Paradigm
Feb 02, 2023
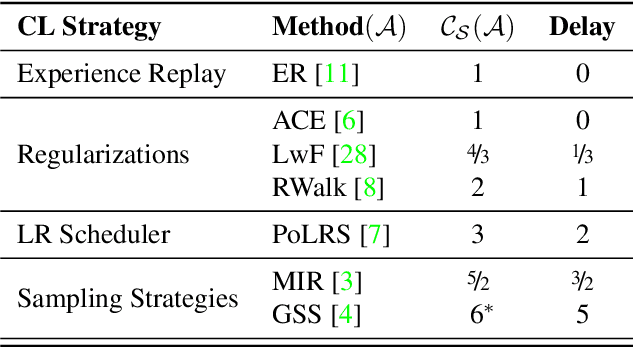
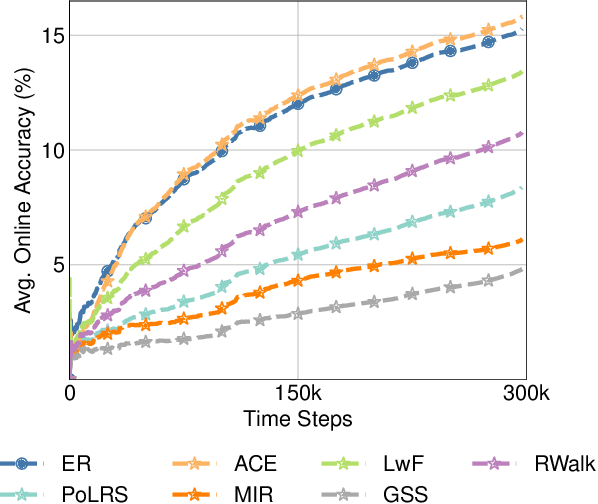
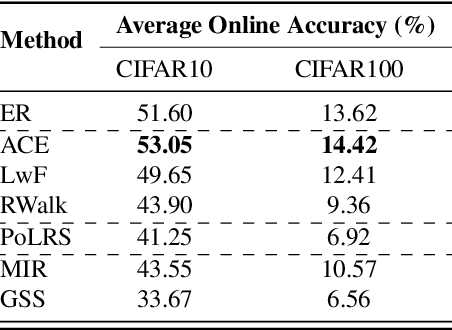
Current evaluations of Continual Learning (CL) methods typically assume that there is no constraint on training time and computation. This is an unrealistic assumption for any real-world setting, which motivates us to propose: a practical real-time evaluation of continual learning, in which the stream does not wait for the model to complete training before revealing the next data for predictions. To do this, we evaluate current CL methods with respect to their computational costs. We hypothesize that under this new evaluation paradigm, computationally demanding CL approaches may perform poorly on streams with a varying distribution. We conduct extensive experiments on CLOC, a large-scale dataset containing 39 million time-stamped images with geolocation labels. We show that a simple baseline outperforms state-of-the-art CL methods under this evaluation, questioning the applicability of existing methods in realistic settings. In addition, we explore various CL components commonly used in the literature, including memory sampling strategies and regularization approaches. We find that all considered methods fail to be competitive against our simple baseline. This surprisingly suggests that the majority of existing CL literature is tailored to a specific class of streams that is not practical. We hope that the evaluation we provide will be the first step towards a paradigm shift to consider the computational cost in the development of online continual learning methods.